




 本文详细介绍了套接字选项的获取和设置,包括getsockopt和setsockopt函数的用法,以及检查选项支持和获取默认值的方法。讨论了不同类型的套接字选项,如TCP、IPv4、IPv6等,并提供了示例代码来展示如何检查和打印选项的默认值。此外,还提到了套接字状态和fcntl函数的作用。
本文详细介绍了套接字选项的获取和设置,包括getsockopt和setsockopt函数的用法,以及检查选项支持和获取默认值的方法。讨论了不同类型的套接字选项,如TCP、IPv4、IPv6等,并提供了示例代码来展示如何检查和打印选项的默认值。此外,还提到了套接字状态和fcntl函数的作用。
Please indicate the source: http://blog.youkuaiyun.com/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
- Ways to get and set the options that affect a socket:
- The getsockopt and setsockopt functions
- The fcntl function
- The ioctl function
7.2 ‘getsockopt’ and ‘setsockopt’ Functions
- These two functions apply only to sockets.
#include <sys/types.h>
#include <sys/socket.h>
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
Both return: 0 if OK,-1 on error- sockfd must refer to an open socket descriptor.
- level specifies the code in the system that interprets the option: the general socket code or some protocol-specific code(e.g., IPv4, IPv6, TCP, or SCTP).
- optval is a pointer to a variable into which the current value of the option is stored by getsockopt, or from which the new value of the option is fetched by setsockopt.
- optlen: size of optval variable, as a value for setsockopt and as a value-result for getsockopt.

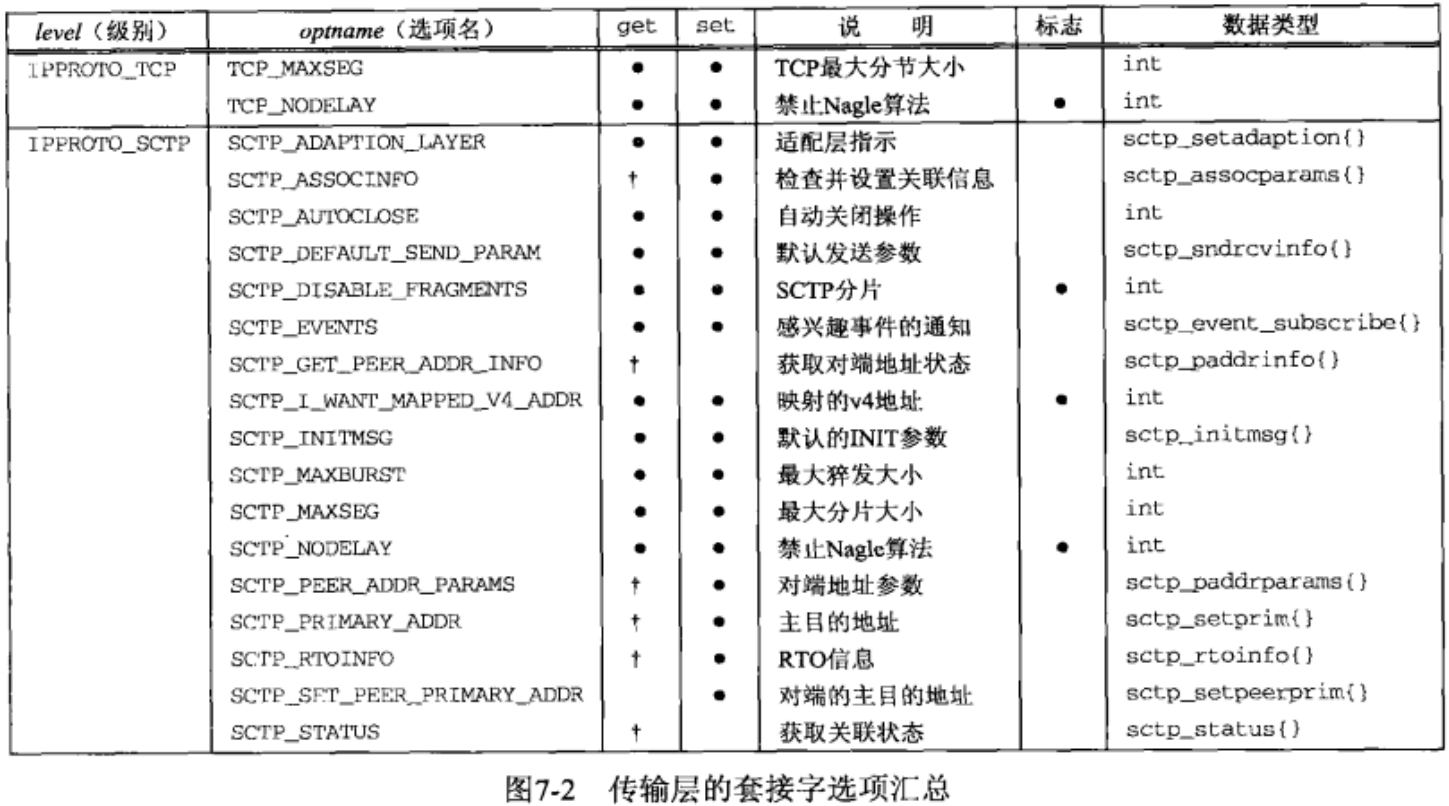
- Figures 7.1 and 7.2 summarize the options that can be queried by getsockopt or set by setsockopt. “Datatype” column shows the datatype of what the optval pointer must point to for each option. We use the notation of two braces to indicate a structure.
- Two basic types of options: binary options that enable or disable a certain feature (flags); options that fetch and return specific values that we can either set or examine(values). “Flag” column specifies if the option is a flag option.
- When calling getsockopt for these flag options, *optval is an integer. The value returned in *optval is zero if the option is disabled, or nonzero if the option is enabled.
- setsockopt requires a nonzero *optval to turn the option on, and a zero value to turn the option off. If the “Flag” column does not contain a “•,” then the option is used to pass a value of the specified datatype between the user process and the system.
7.3 Checking if an Option Is Supported and Obtaining the Default
- We write program to check whether options defined in Figures 7.1 and 7.2 are supported, and if so, print their default value. Figure 7.3 contains the declarations for our program.

Declare union of possible values 3-8
- Our union contains one member for each possible return value from getsockopt.
Define function prototypes 9-12
- We define function prototypes for four functions that are called to print the value for a given socket option.
Define structure and initialize array 13-52
- Our sock_opts structure contains all the information necessary to call getsockopt for each socket option and then print its current value. opt_val_str is a pointer to one of our four functions that will print the option value.
- We allocate and initialize an array of these structures, one element for each socket option.
- Not all implementations support all socket options. The way to determine if a given option is supported is to use an #ifdef or a #if defined, as for SO_REUSEPORT. For completeness, every element of the array should be compiled similarly to what we show for SO_REUSEPORT, but we omit these because the #ifdef s just lengthen the code that we show and add nothing to the discussion.

Go through all options 59-63
- We go through all elements in our array. If the opt_val_str pointer is null, the option is not defined by the implementation(which we showed for SO_REUSEPORT).
Create socket 63-82
- We create a socket on which to try the option. To try socket, IPv4, and TCP layer socket options, we use an IPv4 TCP socket. To try IPv6 layer socket options, we use an IPv6 TCP socket, and to try SCTP layer socket options, we use an IPv4 SCTP socket.
Call getsockopt 83-87
- We call getsockopt but do not terminate if an error is returned. Many implementations define some of the socket option names even though they do not support the option. Unsupported options should elicit an error of ENOPROTOOPT.
Print option’s default value 88-89
- If getsockopt returns success, we call our function to convert the option value to a string and print the string.
- In Figure 7.3, we showed four function prototypes, one for each type of option value that is returned. Figure 7.5 shows one of these four functions, sock_str_flag, which prints the value of a flag option. The other three functions are similar.

- 99-104
Recall that the final argument to getsockopt is a value-result argument. The first check we make is that the size of the value returned by getsockopt is the expected size. The string returned is off or on, depending on whether the value of the flag option is zero or nonzero, respectively. - Running this program under FreeBSD 4.8 with KAME SCTP patches gives the following output:
freebsd % checkopts
SO_BROADCAST: default = off
SO_DEBUG: default = off
SO_DONTROUTE: default = off
SO_ERROR: default = 0
SO_KEEPALIVE: default = off
SO_LINGER: default = l_onoff = 0, l_linger = 0
SO_OOBINLINE: default = off
SO_RCVBUF: default = 57344
SO_SNDBUF: default = 32768
SO_RCVLOWAT: default = 1
SO_SNDLOWAT: default = 2048
SO_RCVTIMEO: default = 0 sec, 0 usec
SO_SNDTIMEO: default = 0 sec, 0 usec
SO_REUSEADDR: default = off
SO_REUSEPORT: default = off
SO_TYPE: default = 1
SO_USELOOPBACK: default = off
IP_TOS: default = 0
IP_TTL: default = 64
IPV6_DONTFRAG: default = off
IPV6_UNICAST_HOPS: default = -1
IPV6_V6ONLY: default = off
TCP_MAXSEG: default = 512
TCP_NODELAY: default = off
SCTP_AUTOCLOSE: default = 0
SCTP_MAXBURST: default = 4
SCTP_MAXSEG: default = 1408
SCTP_NODELAY: default = off- The value of 1 returned for the SO_TYPE option corresponds to SOCK_STREAM for this implementation.
7.4 Socket States
- Some socket options have timing considerations about when to set or fetch the option versus the state of the socket. We mention these with the affected options.
- The following socket options are inherited by a connected TCP socket from the listening socket: SO_DEBUG, SO_DONTROUTE, SO_KEEPALIVE, SO_LINGER, SO_OOBINLINE, SO_RCVBUF, SO_RCVLOWAT, SO_SNDBUF, SO_SNDLOWAT, TCP_MAXSEG, and TCP_NODELAY.
- This is important with TCP because the connected socket is not returned to a server by accept until the three-way handshake is completed by the TCP layer. To ensure that one of these socket options is set for the connected socket when the three-way handshake completes, we must set that option for the listening socket.
7.5 Generic Socket Options
- Generic socket options are protocol-independent, but some of the options apply to only certain types of sockets.
SO_BROADCAST Socket Option
- This option enables or disables the ability of the process to send broadcast messages.
- Broadcasting is supported for only datagram sockets and only on networks that support the concept of a broadcast message(e.g., Ethernet, token ring, etc.). You cannot broadcast on a point-to-point link or any connection-based transport protocol such as TCP.
- An application must set this socket option before sending a broadcast datagram to prevents a process from sending a broadcast when the application was never designed to broadcast.
- For example, a UDP application might take the destination IP address as a command-line argument, but the application never intended for a user to type in a broadcast address. Rather than forcing the application to try to determine if a given address is a broadcast address or not, the test is in the kernel: If the destination address is a broadcast address and this socket option is not set, EACCES is returned.
SO_DEBUG Socket Option
- This option is supported only by TCP.
- When enabled for a TCP socket, the kernel keeps track of detailed information about all the packets sent or received by TCP for the socket. These are kept in a circular buffer within the kernel that can be examined with the trpt program.
SO_DONTROUTE Socket Option
- This option specifies that outgoing packets are to bypass the normal routing mechanisms of the underlying protocol.
- With IPv4, the packet is directed to the appropriate local interface, as specified by the network and subnet portions of the destination address. If the local interface cannot be determined from the destination address(e.g., the destination is not on the other end of a point-to-point link, or is not on a shared network), ENETUNREACH is returned.
- The equivalent of this option can be applied to individual datagrams using the MSG_DONTROUTE flag with the send, sendto, or sendmsg functions.
- This option is often used by routing daemons(e.g., routed and gated) to bypass the routing table and force a packet to be sent out a particular interface.
SO_ERROR Socket Option
- When an error occurs on a socket, the protocol module in a Berkeley-derived kernel sets a variable named so_error for that socket to one of the standard Unix EXXX values. This is called the pending error for the socket. The process can be immediately notified of the error in one of two ways:
- If the process is blocked in a call to select on the socket(Section 6.3), for either readability or writability, select returns with either or both conditions set.
- If the process is using signal-driven I/O(Chapter 25), the SIGIO signal is generated for either the process or the process group.
- The process can then obtain the value of so_error by fetching the SO_ERROR socket option. The integer value returned by getsockopt is the pending error for the socket. The value of so_error is then reset to 0 by the kernel.
- If so_error is nonzero when the process calls read and there is no data to return, read returns -1 with errno set to the value of so_error(p.516 of TCPv2). The value of so_error is then reset to 0. If there is data queued for the socket, that data is returned by read instead of the error condition. If so_error is nonzero when the process calls write, -1 is returned with errno set to the value of so_error and so_error is reset to 0.
- This is the first socket option that we have encountered that can be fetched but cannot be set.
SO_KEEPALIVE Socket Option
- When the keep-alive option is set for a TCP socket and no data has been exchanged across the socket in either direction for two hours, TCP automatically sends a keep-alive probe to the peer. This probe is a TCP segment to which the peer must respond. One of three scenarios results:
- The peer responds with ACK. The application is not notified(since everything is okay). TCP will send another probe following another two hours of inactivity.
- The peer responds with an RST, which tells the local TCP that the peer host has crashed and rebooted. The socket’s pending error is set to ECONNRESET and the socket is closed.
- There is no response from the peer. Berkeley-derived TCPs send 8 additional probes, 75 seconds apart, trying to elicit a response. TCP will give up if there is no response within 11 minutes and 15 seconds after sending the first probe.
If there is no response at all to TCP’s keep-alive probes, the socket’s pending error is set to ETIMEDOUT and the socket is closed. But if the socket receives an ICMP error in response to one of the keep-alive probes, the corresponding error(Figures A.15 and A.16) is returned instead and the socket is still closed. A common ICMP error is “host unreachable”, indicating that the peer host is unreachable, and the pending error is set to EHOSTUNREACH. This can occur either because of a network failure or because the remote host has crashed and the last-hop router has detected the crash.
- Whether the timing parameters can be modified?(usually to reduce the two-hour period of inactivity to some shorter value) Appendix E of TCPv1 discusses how to change these timing parameters for various kernels, but most kernels maintain these parameters on a per-kernel basis, not on a per-socket basis, so changing the inactivity period will affect all sockets on the host that enable this option.
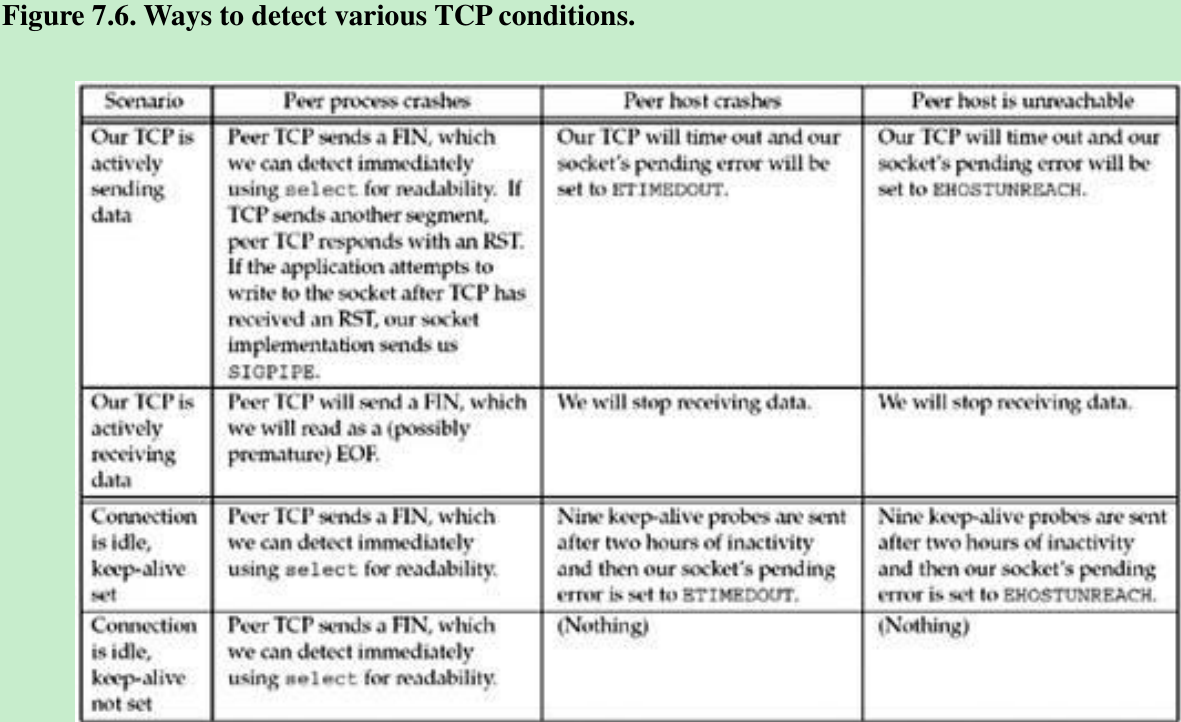
- The purpose of this option is to detect if the peer host crashes or becomes unreachable(e.g., dial-up modem connection drops, power fails, etc.). If the peer process crashes, its TCP will send a FIN across the connection, which we can detect with select. Realize that if there is no response to any of the keep-alive probes (scenario 3), we are not guaranteed that the peer host has crashed, and TCP may well terminate a valid connection. It could be that some intermediate router has crashed for 15 minutes, and that period of time just happens to completely overlap our host’s 11-minute and 15-second keep-alive probe period. In fact, this function might more properly be called “make-dead” rather than “keep-alive” since it can terminate live connections.
- This option is normally used by servers. Servers use the option because they spend most of their time blocked waiting for a client request. But if the client host’s connection drops, is powered off, or crashes, the server process will never know about it, and the server will continually wait for input that can never arrive. This is called a half-open connection. The keep-alive option will detect these half-open connections and terminate them.
- Some servers provide an application timeout, often on the order of minutes. This is done by the application itself, normally around a call to read, reading the next client command. This timeout does not involve this socket option. This is a better method of eliminating connections to missing clients, since the application has complete control if it implements the timeout itself.
- Figure 7.6 summarizes the various methods that we have to detect when something happens on the other end of a TCP connection. When we say “using select for readability,” we mean calling select to test whether a socket is readable.
SO_LINGER Socket Option
- This option specifies how the close function operates for a connection-oriented protocol.
- By default, close returns immediately, but if there is any data still remaining in the socket send buffer, the system will try to deliver the data to the peer. SO_LINGER socket option can change this default.
- This option requires the following structure to be passed between the user process and the kernel. It is defined in
struct linger
{
int l_onoff; // 0=off, nonzero=on
int l_linger; // linger time, POSIX specifies units as seconds
};- Calling setsockopt leads to one of the following three scenarios, depending on the values of the two structure members:
- If l_onoff is 0, the option is turned off. The value of l_linger is ignored and the TCP default applies: close returns immediately.
- If l_onoff is nonzero and l_linger is zero, TCP aborts the connection when it is closed. TCP discards any data still remaining in the socket send buffer and sends an RST to the peer, not the normal four-packet connection termination sequence. This avoids TCP’s TIME_WAIT state, but leaves open the possibility of another incarnation of this connection being created within 2MSL seconds(Section 2.7) and having old duplicate segments from the just-terminated connection being incorrectly delivered to the new incarnation.
Occasional USENET postings advocate the use of this feature just to avoid the TIME_WAIT state and to be able to restart a listening server even if connections are still in use with the server’s well-known port. This should NOT be done and could lead to data corruption. The SO_REUSEADDR socket option should always be used in the server before the call to bind. The TIME_WAIT state is our friend and is there to help us(i.e., to let old duplicate segments expire in the network). Instead of trying to avoid the state, we should understand it(Section 2.7). - If l_onoff is nonzero and l_linger is nonzero, then the kernel will linger when the socket is closed.
That is, if there is any data still remaining in the socket send buffer, the process is put to sleep until either:
(i) all the data is sent and acknowledged by the peer TCP, or
(ii) the linger time expires.
If the socket has been set to nonblocking(Chapter 16), it will not wait for the close to complete, even if the linger time is nonzero. When using this feature of the SO_LINGER option, it is important for the application to check the return value from close, because if the linger time expires before the remaining data is sent and acknowledged, close returns EWOULDBLOCK and any remaining data in the send buffer is discarded.
- Assume the client writes data to the socket and then calls close. Figure 7.7 shows the default situation.
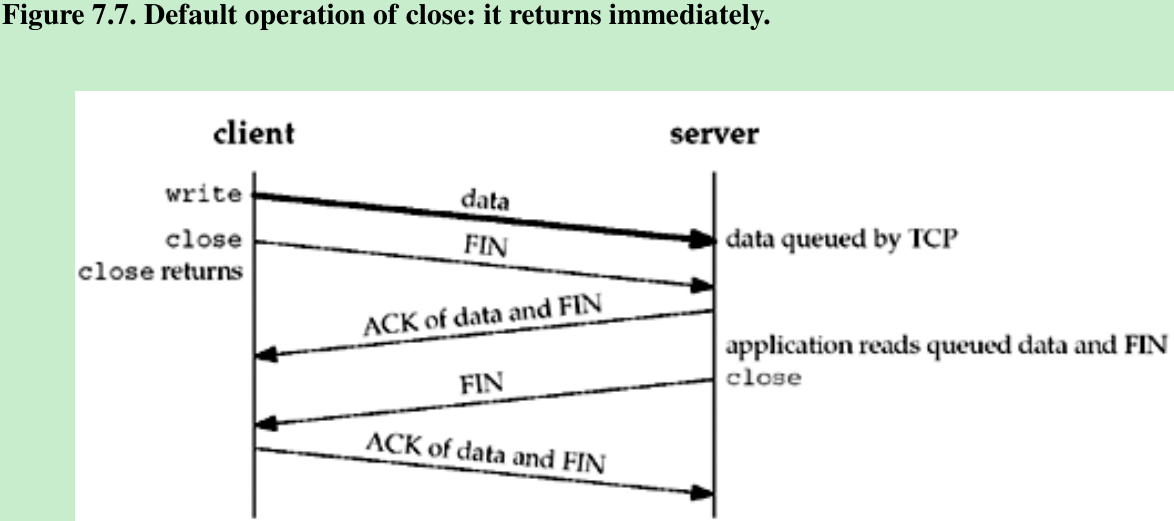
- Assume when the client’s data arrives, the server is busy, so the data is added to the socket receive buffer by its TCP. The next segment, the client’s FIN, is also added to the socket receive buffer. By default, the client’s close returns immediately before the server reads the remaining data in its socket receive buffer. Therefore, it is possible for the server host to crash before the server application reads this remaining data, and the client application will never know.
- The client can set the SO_LINGER socket option, specifying some positive linger time. When this occurs, the client’s close does not return until all the client’s data and its FIN have been acknowledged by the server TCP. Figure 7.8.
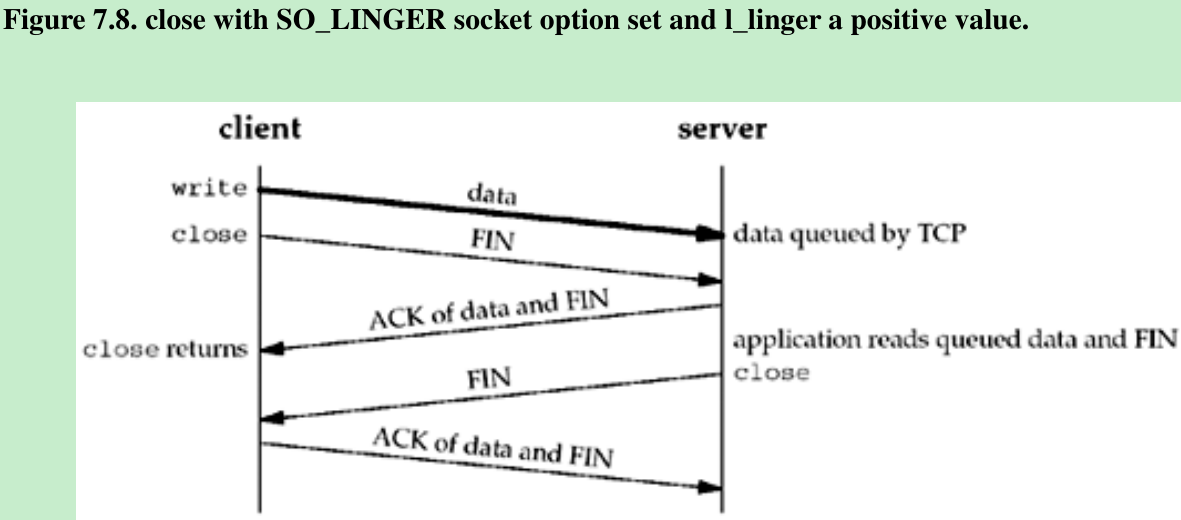
- But we still have the same problem as in Figure 7.7: The server host can crash before the server application reads its remaining data, and the client application will never know. Figure 7.9 shows what can happen when the SO_LINGER option is set to a value that is too low.
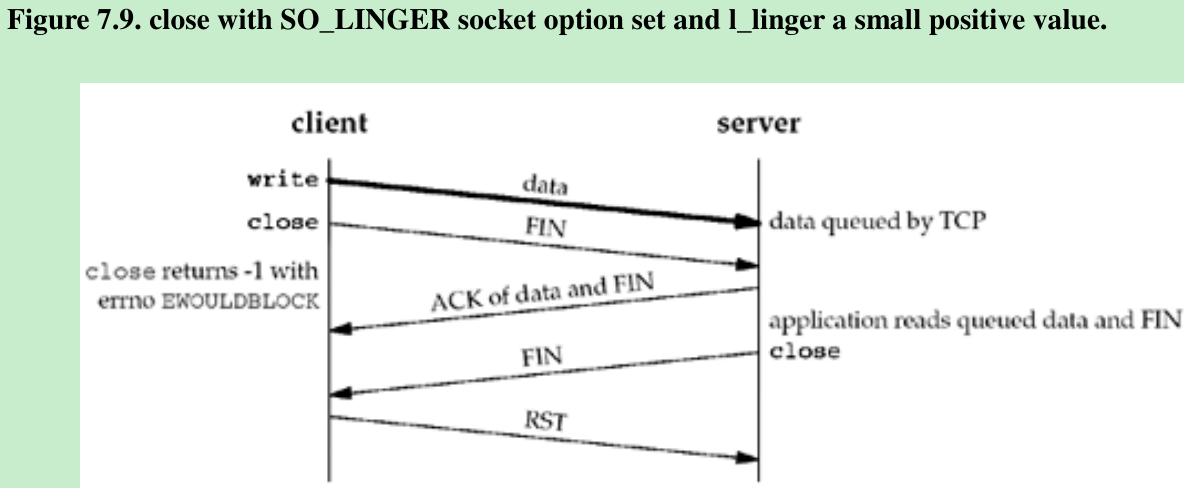
- The basic principle here is that a successful return from close, with the SO_LINGER socket option set, only tells us that the data and FIN we sent have been acknowledged by the peer TCP. This does not tell us whether the peer application has read the data. If we do not set the SO_LINGER socket option, we do not know whether the peer TCP has acknowledged the data.
- One way for the client to know that the server has read its data is to call shutdown with a second argument of SHUT_WR instead of close and wait for the peer to close its end of the connection. We show this scenario in Figure 7.10.
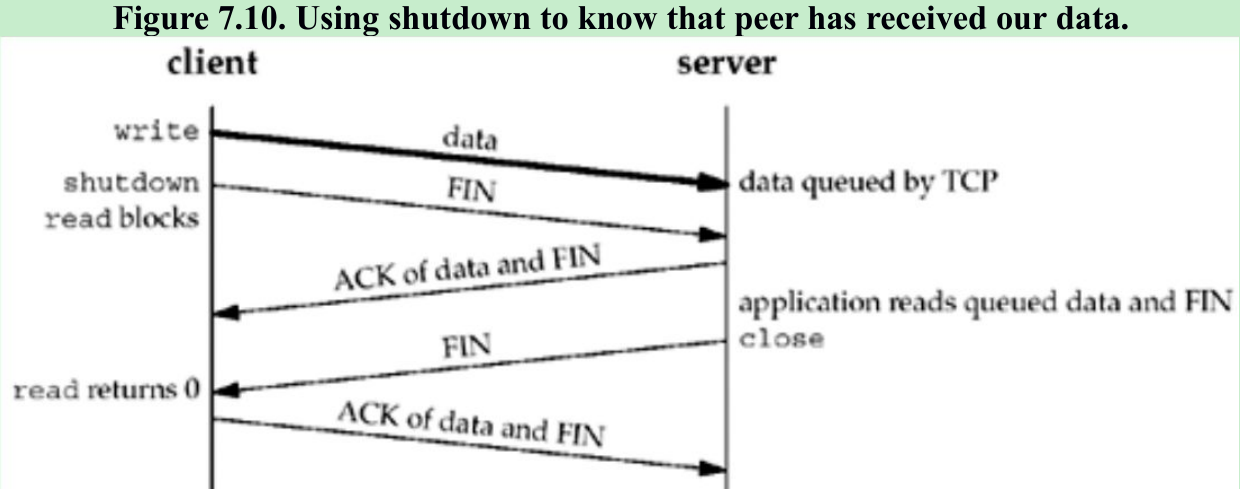
- Comparing to Figures 7.7 and 7.8 we see that when we close our end of the connection, depending on the function called(close or shutdown) and whether the SO_LINGER socket option is set, the return can occur at three different times:
- close returns immediately, without waiting at all(the default; Figure 7.7).
- close lingers until the ACK of our FIN is received(Figure 7.8).
- shutdown followed by a read waits until we receive the peer’s FIN(Figure 7.10).
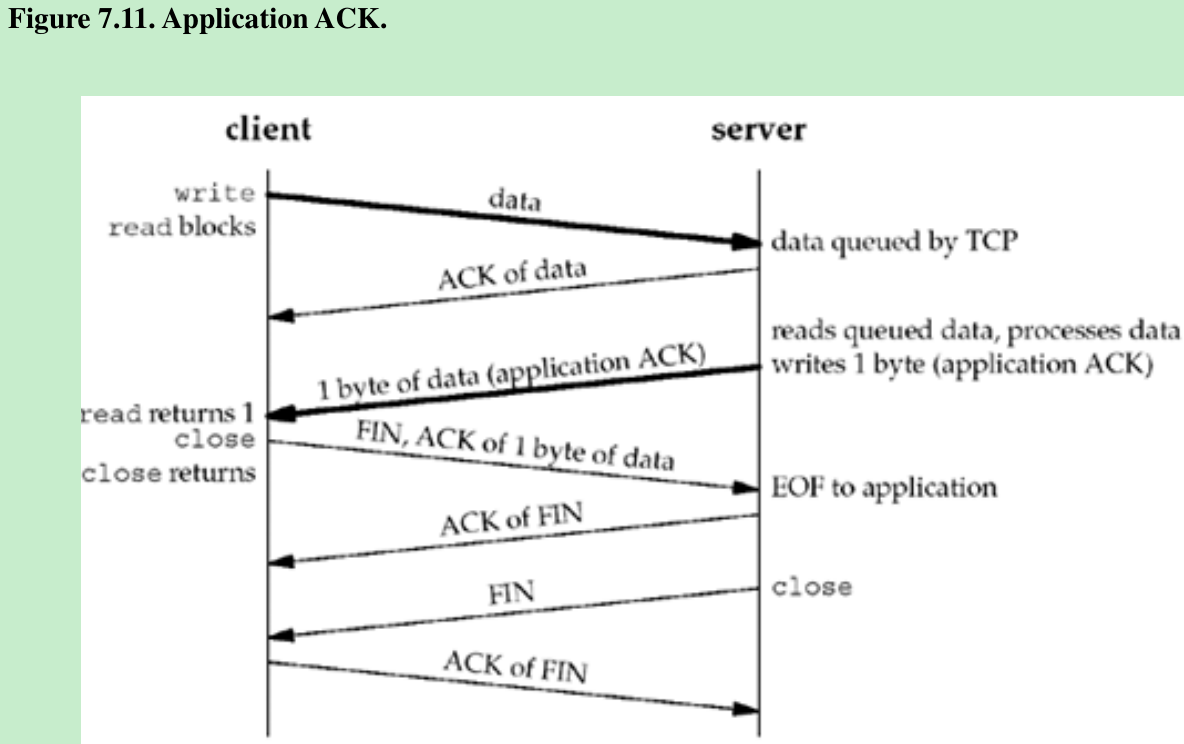
- Another way to know that the peer application has read our data is to use an application-level acknowledgment, or application ACK. For example, the client sends its data to the server and then calls read for one byte of data:
char ack;
Write(sockfd, data, nbytes); /* data from client to server */
n = Read(sockfd, &ack, 1); /* wait for application-level ACK */- The server reads the data from the client and then sends back the one-byte application-level ACK:
nbytes = Read(sockfd, buff, sizeof(buff));/* data from client */
/* server verifies it received correct amount of data from client */
Write(sockfd, "", 1);/* server's ACK back to client */- We are guaranteed that when the read in the client returns, the server process has read the data we sent. (This assumes that either the server knows how much data the client is sending, or there is some application-defined end-of-record marker.) Here, the application-level ACK is a byte of 0, but the contents of this byte could be used to signal other conditions from the server to the client. Figure 7.11 shows the possible packet exchange.
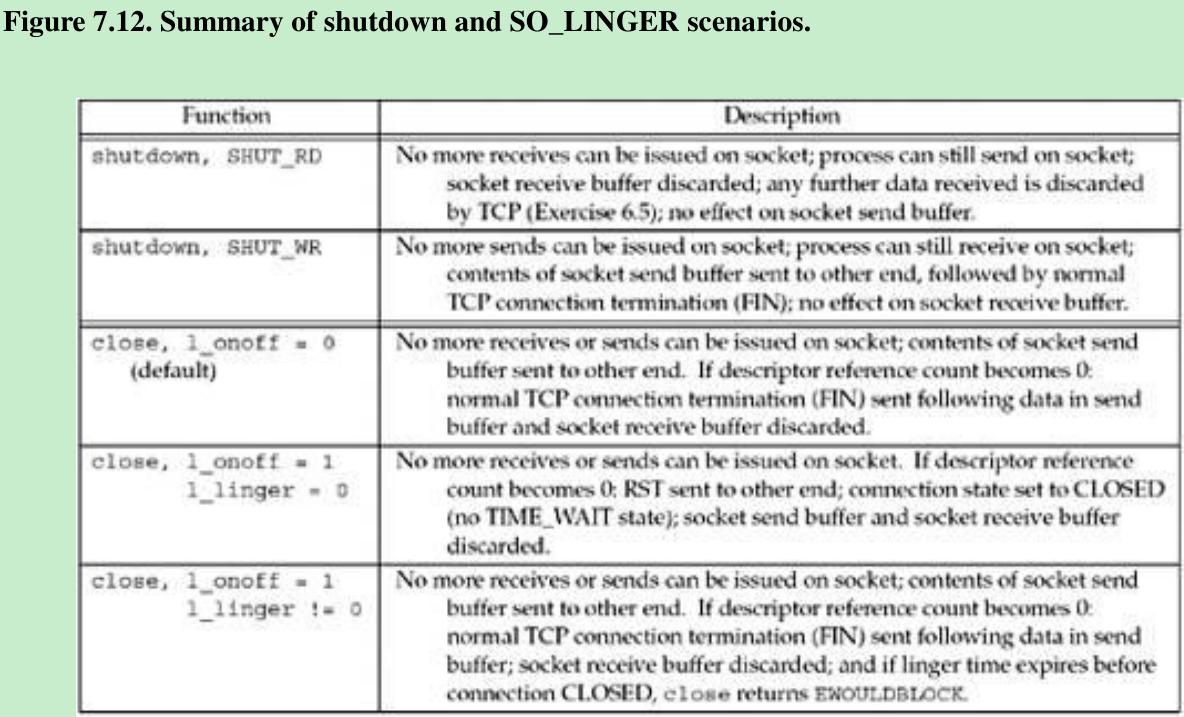
- Figure 7.12 summarizes the two possible calls to shutdown and the three possible calls to close, and the effect on a TCP socket.
SO_OOBINLINE Socket Option
- When this option is set, out-of-band data will be placed in the normal input queue. When this occurs, the MSG_OOB flag to the receive functions cannot be used to read the out-of-band data.Chapter 24.
SO_RCVBUF and SO_SNDBUF Socket Options
- The receive buffers are used by TCP, UDP to hold received data until it is read by the application.
- With TCP, the available room in the socket receive buffer limits the window that TCP can advertise to the other end. The TCP socket receive buffer cannot overflow because the peer is not allowed to send data beyond the advertised window. This is TCP’s flow control, and if the peer ignores the advertised window and sends data beyond the window, the receiving TCP discards it.
- With UDP, when a datagram arrives that will not fit in the socket receive buffer, that datagram is discarded. Since UDP has no flow control, it is easy for a fast sender to overwhelm a slower receiver, causing datagrams to be discarded by the receiver’s UDP. In fact, a fast sender can overwhelm its own network interface, causing datagrams to be discarded by the sender itself.
- These two socket options let us change the default sizes. The default values differ between implementations. Systems use values anywhere from 8,192 to 61,440 bytes. The UDP send buffer size often defaults to a value around 9,000 bytes if the host supports NFS, and the UDP receive buffer size often defaults to a value around 40,000 bytes.
- When setting the size of the TCP socket receive buffer, the ordering of the function calls is important. This is because of TCP’s window scale option(Section 2.6), which is exchanged with the peer on the SYN segments when the connection is established.
- For a client, this means the SO_RCVBUF socket option must be set before calling connect.
- For a server, this means the socket option must be set for the listening socket before calling listen. Setting this option for the connected socket will have no effect whatsoever on the possible window scale option because accept does not return with the connected socket until TCP’s three-way handshake is complete. That is why this option must be set for the listening socket. The sizes of the socket buffers are always inherited from the listening socket by the newly created connected socket.
- The TCP socket buffer sizes should be at least four times the MSS for the connection. If we are dealing with unidirectional data transfer, when we say “socket buffer sizes,” we mean the socket send buffer size on the sending host and the socket receive buffer size on the receiving host. For bidirectional data transfer, we mean both socket buffer sizes on the sender and both socket buffer sizes on the receiver. With typical default buffer sizes of 8,192 bytes or larger, and a typical MSS of 512 or 1,460, this requirement is normally met.
- The minimum MSS multiple of four is a result of the way that TCP’s fast recovery algorithm works. The TCP sender uses three duplicate acknowledgments to detect that a packet was lost. The receiver sends a duplicate acknowledgment for each segment it receives after a lost segment. If the window size is smaller than four segments, there cannot be three duplicate acknowledgments, so the fast recovery algorithm cannot be invoked.
- To avoid wasting potential buffer space, the TCP socket buffer sizes should also be an even multiple of the MSS for the connection. Some implementations handle this detail for the application, rounding up the socket buffer size after the connection is established. This is another reason to set these two socket options before establishing a connection. For example, using the default 4.4BSD size of 8,192 and assuming an Ethernet with an MSS of 1,460, both socket buffers are rounded up to 8,760(6*1460) when the connection is established. This is not a crucial requirement; the additional space in the socket buffer above the multiple of the MSS is simply unused.
- Another consideration in setting the socket buffer sizes deals with performance. Figure 7.13 shows a TCP connection between two endpoints(which we call a pipe) with a capacity of eight segments.

- We show four data segments on the top and four ACKs on the bottom. Even though there are only four segments of data in the pipe, the client must have a send buffer capacity of at least eight segments, because the client TCP must keep a copy of each segment until the ACK is received from the server.
- What is important to understand is the concept of the full-duplex pipe, its capacity, and how that relates to the socket buffer sizes on both ends of the connection. The capacity of the pipe is called the bandwidth-delay product and we calculate this by multiplying the bandwidth(in bits/sec) times the RTT(in seconds), converting the result from bits to bytes.
- The bandwidth is the value corresponding to the slowest link between two endpoints and must be known. For example, a T1 line(1,536,000 bits/sec) with an RTT of 60 ms gives a bandwidth-delay product of 11,520 bytes. If the socket buffer sizes are less than this, the pipe will not stay full, and the performance will be less than expected. Large socket buffers are required when the bandwidth gets larger(e.g., T3 lines at 45 Mbits/sec) or when the RTT gets large(e.g., satellite links with an RTT around 500 ms). When the bandwidth-delay product exceeds TCP’s maximum normal window size(65,535 bytes), both endpoints also need the TCP long fat pipe options that we mentioned in Section 2.6.
- Most implementations have an upper limit for the sizes of the socket send and receive buffers, and this limit can be modified by the administrator. Implementations have a default limit of 256,000 bytes or more, and this can usually be increased by the administrator. But there is no simple way for an application to determine this limit. POSIX defines the fpathconf function and using the _PC_SOCK_MAXBUF constant as the second argument, we can retrieve the maximum size of the socket buffers. Alternately, an application can try setting the socket buffers to the desired value, and if that fails, cut the value in half and try again until it succeeds.
- Finally, an application should make sure that it’s not actually making the socket buffer smaller when it sets it to a pre-configured “large” value; calling getsockopt first to retrieve the system’s default and seeing if that’s large enough is often a good start.
SO_RCVLOWAT and SO_SNDLOWAT Socket Options
- Every socket also has a receive low-water mark and a send low-water mark. These are used by the select function(Section 6.3). SO_RCVLOWAT and SO_SNDLOWAT let us change these two low-water marks.
- The receive low-water mark is the amount of data that must be in the socket receive buffer for select to return “readable.” It defaults to 1 for TCP, UDP, and SCTP sockets.
- The send low-water mark is the amount of available space that must exist in the socket send buffer for select to return “writable.” It defaults to 2,048 for TCP sockets. For UDP: the number of bytes of available space in the send buffer for a UDP socket never changes(UDP does not keep a copy of the datagrams sent by the application), as long as the UDP socket send buffer size is greater than the socket’s low-water mark, the UDP socket is always writable. Figure 2.16: UDP does not have a send buffer; it has only a send buffer size.
SO_RCVTIMEO and SO_SNDTIMEO Socket Options
- These two socket options allow us to place a timeout on socket receives and sends.
- The argument to the two sockopt functions is a pointer to a timeval structure that lets us specify the timeouts in seconds and microseconds. We disable a timeout by setting its value to 0 seconds and 0 microseconds. Both timeouts are disabled by default.
- Receive timeout affects five input functions: read, readv, recdv, recvfrom, and recvmsg. Send timeout affects the five output functions: write, writev, send, sendto, and sendmsg.(Section 14.2.)
SO_REUSEADDR and SO_REUSEPORT Socket Options
- The SO_REUSEADDR socket option serves four different purposes:
- SO_REUSEADDR allows a listening server to start and bind its well-known port, even if previously established connections exist that use this port as their local port. This condition is encountered as follows:
a. A listening server is started.
b. A connection request arrives and a child process is spawned to handle that client.
c. The listening server terminates, but the child continues to service the client on the existing connection.
d. The listening server is restarted.
- SO_REUSEADDR allows a listening server to start and bind its well-known port, even if previously established connections exist that use this port as their local port. This condition is encountered as follows:
- By default, when the listening server is restarted in (d) by calling socket, bind, and listen, the call to bind fails because the listening server is trying to bind a port that is part of an existing connection(the one being handled by the previously spawned child). But if the server sets the SO_REUSEADDR socket option between the calls to socket and bind, the latter function will succeed. All TCP servers should specify this socket option to allow the server to be restarted in this situation.
- SO_REUSEADDR allows a new server to be started on the same port as an existing server that is bound to the wildcard address, as long as each instance binds a different local IP address.
- This is common for a site hosting multiple HTTP servers using the IP alias technique (Section A.4). Assume the local host’s primary IP address is 198.69.10.2 but it has two aliases: 198.69.10.128 and 198.69.10.129. Three HTTP servers are started. The first HTTP server would call bind with the wildcard as the local IP address and a local port of 80(well-known port for HTTP). The second server would call bind with a local IP address of 198.69.10.128 and a local port of 80. But the second call to bind fails unless SO_REUSEADDR is set before the call. The third server would bind 198.69.10.129 and port 80. Again, SO_REUSEADDR is required for this final call to succeed.
- Assuming SO_REUSEADDR is set and the three servers are started, incoming TCP connection requests with a destination IP of 198.69.10.128 and a destination port of 80 are delivered to the second server, incoming requests with a destination IP of 198.69.10.129 and a destination port of 80 are delivered to the third server, and all other TCP connection requests with a destination port of 80 are delivered to the first server. This default server handles requests destined for 198.69.10.2 in addition to any other IP aliases that the host may have configured. The wildcard means “everything that doesn’t have a better(more specific) match.”
- This scenario of allowing multiple servers for a given service is handled automatically if the server always sets the SO_REUSEADDR socket option.
- With TCP, we are never able to start multiple servers that bind the same IP address and the same port(a completely duplicate binding) even if we set the SO_REUSEADDR socket option.
- SO_REUSEADDR allows a single process to bind the same port to multiple sockets, as long as each bind specifies a different local IP address.
- This is common for UDP servers that need to know the destination IP address of client requests on systems that do not provide the IP_RECVDSTADDR socket option.
- This technique is not used with TCP servers since a TCP server can always determine the destination IP address by calling getsockname after the connection is established. A TCP server wishing to serve connections to some, but not all, addresses belonging to a multihomed host should use this technique.
- SO_REUSEADDR allows completely duplicate bindings: a bind of an IP address and port, when that same IP address and port are already bound to another socket, if the transport protocol supports it
- This feature is supported only for UDP sockets. This feature is used with multicasting to allow the same application to be run multiple times on the same host. When a UDP datagram is received for one of these multiply bound sockets, the rule is that if the datagram is destined for either a broadcast address or a multicast address, one copy of the datagram is delivered to each matching socket. But if the datagram is destined for a unicast address, the datagram is delivered to only one socket. If, in the case of a unicast datagram, there are multiple sockets that match the datagram, the choice of which socket receives the datagram is implementation-dependent.
- 4.4BSD introduced the SO_REUSEPORT socket option when support for multicasting was added. Instead of overloading SO_REUSEADDR with the desired multicast semantics that allow completely duplicate bindings, this socket option was introduced with the following semantics:
- This option allows completely duplicate bindings, but only if each socket that wants to bind the same IP address and port specify this socket option.
- SO_REUSEADDR is considered equivalent to SO_REUSEPORT if the IP address being bound is a multicast address.
- Problem with SO_REUSEPORT: Not all systems support it, on those that do not support the option but do support multicasting, SO_REUSEADDR is used instead of SO_REUSEPORT to allow completely duplicate bindings when it makes sense(i.e., a UDP server that can be run multiple times on the same host at the same time and that expects to receive either broadcast or multicast datagrams).
- Summarize of these socket options with the recommendations:
- Set the SO_REUSEADDR socket option before calling bind in all TCP servers.
- When writing a multicast application that can be run multiple times on the same host at the same time, set the SO_REUSEADDR socket option and bind the group’s multicast address as the local IP address.
SO_TYPE Socket Option
- This option returns the socket type. The integer value returned is a value such as SOCK_STREAM or SOCK_DGRAM. This option is typically used by a process that inherits a socket when it is started.
SO_USELOOPBACK Socket Option
- This option applies only to sockets in the routing domain(AF_ROUTE). This option defaults to ON for these sockets(the only one of the SO_xxx socket options that defaults to ON instead of OFF). When this option is enabled, the socket receives a copy of everything sent on the socket.
- Another way to disable these loopback copies is to call shutdown with a second argument of SHUT_RD.
7.6 IPv4 Socket Options
- These socket options are processed by IPv4 and have a level of IPPROTO_IP. We discuss multicasting socket options in Section 21.6.
IP_HDRINCL Socket Option
- If this option is set for a raw IP socket(Chapter 28), we must build our own IP header for all the datagrams we send on the raw socket. Normally, the kernel builds the IP header for datagrams sent on a raw socket, but there are some applications(traceroute) that build their own IP header to override values that IP would place into certain header fields.
- When this option is set, we build a complete IP header, with the following exceptions:
- IP always calculates and stores the IP header checksum.
- If we set the IP identification field to 0, the kernel will set the field.
- If the source IP address is INADDR_ANY, IP sets it to the primary IP address of the outgoing interface.
- Setting IP options is implementation-dependent. Some implementations take any IP options that were set using the IP_OPTIONS socket option and append these to the header that we build, while others require our header to also contain any desired IP options.
- Some fields must be in host byte order, and some in network byte order. This is implementation-dependent, which makes writing raw packets with IP_HDRINCL not portable.
IP_OPTIONS Socket Option
- Setting this option allows us to set IP options in the IPv4 header. This requires intimate knowledge of the format of the IP options in the IP header. We discuss this option with regard to IPv4 source routes in Section 27.3.
IP_RECVDSTADDR Socket Option
- This socket option causes the destination IP address of a received UDP datagram to be returned as ancillary data by recvmsg. We show an example of this option in Section 22.2.
IP_RECVIF Socket Option
- This socket option causes the index of the interface on which a UDP datagram is received to be returned as ancillary data by recvmsg. We show an example of this option in Section 22.2.
IP_TOS Socket Option
- This option lets us set the type-of-service(TOS) field(which contains the DSCP and ECN fields, Figure A.1) in the IP header for a TCP, UDP, or SCTP socket. If we call getsockopt for this option, the current value that would be placed into the DSCP and ECN fields in the IP header(defaults to 0) is returned. There is no way to fetch the value from a received IP datagram.
- An application can set the DSCP to a value negotiated with the network service provider to receive prearranged services, e.g., low delay for IP telephony or higher throughput for bulk data transfer. The diffserv architecture, defined in RFC 2474, provides for only limited backward compatibility with the historical TOS field definition from RFC 1349.
- Application that set IP_TOS to one of the contents from
7.7 ICMPv6 Socket Option
7.8 IPv6 Socket Options
7.9 TCP Socket Options
- There are two socket options for TCP. We specify the level as IPPROTO_TCP.
TCP_MAXSEG Socket Option
- This socket option allows us to fetch or set the MSS for a TCP connection. The value returned is the maximum amount of data that our TCP will send to the other end; often, it is the MSS announced by the other end with its SYN, unless our TCP chooses to use a smaller value than the peer’s announced MSS. If this value is fetched before the socket is connected, the value returned is the default value that will be used if an MSS option is not received from the other end. Also be aware that a value smaller than the returned value can actually be used for the connection if the timestamp option, for example, is in use, because this option occupies 12 bytes of TCP options in each segment.
- The maximum amount of data that our TCP will send per segment can also change during the life of a connection if TCP supports path MTU discovery. If the route to the peer changes, this value can go up or down.
- We note in Figure 7.1 that this socket option can also be set by the application. This is not possible on all systems; it was originally a read-only option. 4.4BSD limits the application to decreasing the value: We cannot increase the value (p. 1023 of TCPv2).
- Since this option controls the amount of data that TCP sends per segment, it makes sense to forbid the application from increasing the value. Once the connection is established, this value is the MSS option announced by the peer, and we cannot exceed that value. Our TCP, however, can always send less than the peer’s announced MSS.
TCP_NODELAY Socket Option
- If set, this option disables TCP’s Nagle algorithm (Section 19.4 of TCPv1 and pp.858-859 of TCPv2). By default, this algorithm is enabled.
- The purpose of the Nagle algorithm is to reduce the number of small packets on a WAN. The algorithm states that if a given connection has outstanding data (i.e., data that our TCP has sent, and for which it is currently awaiting an acknowledgment), then no small packets will be sent on the connection in response to a user write operation until the existing data is acknowledged. The definition of a “small” packet is any packet smaller than the MSS. TCP will always send a full-sized packet if possible; the purpose of the Nagle algorithm is to prevent a connection from having multiple small packets outstanding at any time.
- The two common generators of small packets are the Rlogin and Telnet clients, since they normally send each keystroke as a separate packet. On a fast LAN, we normally do not notice the Nagle algorithm with these clients, because the time required for a small packet to be acknowledged is typically a few milliseconds—far less than the time between two successive characters that we type. But on a WAN, where it can take a second for a small packet to be acknowledged, we can notice a delay in the character echoing, and this delay is often exaggerated by the Nagle algorithm.
- Consider the following example: We type the six-character string “hello!” to either an Rlogin or Telnet client, with exactly 250 ms between each character. The RTT to the server is 600 ms and the server immediately sends back the echo of each character.
- We assume the ACK of the client’s character is sent back to the client along with the character echo and we ignore the ACKs that the client sends for the server’s echo.
- (We will talk about delayed ACKs shortly.) Assuming the Nagle algorithm is disabled, we have the 12 packets shown in Figure 7.14.
- Each character is sent in a packet by itself: the data segments from left to right, and the ACKs from right to left.
- If the Nagle algorithm is enabled (the default), we have the eight packets shown in Figure 7.15. The first character is sent as a packet by itself, but the next two characters are not sent, since the connection has a small packet outstanding. At time 600, when the ACK of the first packet is received, along with the echo of the first character, these two characters are sent. Until this packet is ACKed at time 1200, no more small packets are sent.
- The Nagle algorithm often interacts with another TCP algorithm: the delayed ACK algorithm. This algorithm causes TCP to not send an ACK immediately when it receives data; instead, TCP will wait some small amount of time (typically 50-200 ms) and only then send the ACK. The hope is that in this small amount of time, there will be data to send back to the peer, and the ACK can piggyback with the data, saving one TCP segment. This is normally the case with the Rlogin and Telnet clients, because the servers typically echo each character sent by the client, so the ACK of the client’s character piggybacks with the server’s echo of that character.
- The problem is with other clients whose servers do not generate traffic in the reverse direction on which ACKs can piggyback. These clients can detect noticeable delays because the client TCP will not send any data to the server until the server’s delayed ACK timer expires. These clients need a way to disable the Nagle algorithm, hence the TCP_NODELAY option.
- Another type of client that interacts badly with the Nagle algorithm and TCP’s delayed ACKs is a client that sends a single logical request to its server in small pieces. For example, assume a client sends a 400-byte request to its server, but this is a 4-byte request type followed by 396 bytes of request data. If the client performs a 4-byte write followed by a 396-byte write, the second write will not be sent by the client TCP until the server TCP acknowledges the 4-byte write. Also, since the server application cannot operate on the 4 bytes of data until it receives the remaining 396 bytes of data, the server TCP will delay the ACK of the 4 bytes of data (i.e., there will not be any data from the server to the client on which to piggyback the ACK). There are three ways to fix this type of client:
- 1.2.3.Use writev (Section 14.4) instead of two calls to write. A single call to writev ends up with one call to TCP output instead of two calls, resulting in one TCP segment for our example. This is the preferred solution.
- Copy the 4 bytes of data and the 396 bytes of data into a single buffer and call write once for this buffer.
- Set the TCP_NODELAY socket option and continue to call write two times. This is the least desirable solution, and is harmful to the network, so it generally should not even be considered.
7.10 SCTP Socket Options
7.11 ‘fcntl’ Function
- fcntl stands for “file control” and this function performs various descriptor control operations. Before describing the function and how it affects a socket, we need to look at the bigger picture. Figure 7.20 summarizes the different operations performed by fcntl, ioctl, and routing sockets.
- The first six operations can be applied to sockets by any process; the second two (interface operations) are less common, but are still general-purpose; and the last two (ARP and routing table) are issued by administrative programs such as ifconfig and route. We will talk more about the various ioctl operations in Chapter 17 and routing sockets in Chapter 18.
- There are multiple ways to perform the first four operations, but we note in the final column that POSIX specifies that fcntl is the preferred way. We also note that POSIX provides the sockatmark function (Section 24.3) as the preferred way to test for the out-of-band mark. The remaining operations, with a blank final column, have not been standardized by POSIX.
- We also note that the first two operations, setting a socket for nonblocking I/O and for signal-driven I/O, have been set historically using the FNDELAY and FASYNC commands with fcntl. POSIX defines the O_XXX constants.
- The fcntl function provides the following features related to network programming:
- Nonblocking I/O— We can set the O_NONBLOCK file status flag using the F_SETFL command to set a socket as nonblocking. We will describe nonblocking I/O in Chapter 16.
- Signal-driven I/O— We can set the O_ASYNC file status flag using the F_SETFL command, which causes the SIGIO signal to be generated when the status of a socket changes. We will discuss this in Chapter 25.
- The F_SETOWN command lets us set the socket owner (the process ID or process group ID) to receive the SIGIO and SIGURG signals. The former signal is generated when signal-driven I/O is enabled for a socket (Chapter 25) and the latter signal is generated when new out-of-band data arrives for a socket (Chapter 24). The F_GETOWN command returns the current owner of the socket.
- The term “socket owner” is defined by POSIX. Historically, Berkeley-derived implementations have called this “the process group ID of the socket” because the variable that stores this ID is the so_pgid member of the socket structure.
#include <fcntl.h>
int fcntl(intfd, int cmd, ... /* int arg */ );
Returns: depends on cmd if OK, -1 on error- Each descriptor (including a socket) has a set of file flags that is fetched with the F_GETFL command and set with the F_SETFL command. The two flags that affect a socket are
O_NONBLOCK—nonblocking I/O
O_ASYNC—signal-driven I/O - We will describe both of these features in more detail later. For now, we note that typical code to enable nonblocking I/O, using fcntl, would be:
int flags;
/* Set a socket as nonblocking */
if((flags = fcntl (fd, F_GETFL, 0)) < 0)
{
err_sys("F_GETFL error");
}
flags |= O_NONBLOCK;
if (fcntl(fd, F_SETFL, flags) < 0)
{
err_sys("F_SETFL error");
}- Beware of code that you may encounter that simply sets the desired flag.
/* Wrong way to set a socket as nonblocking */
if (fcntl(fd, F_SETFL, O_NONBLOCK) < 0)
{
err_sys("F_SETFL error");
}- While this sets the nonblocking flag, it also clears all the other file status flags. The only correct way to set one of the file status flags is to fetch the current flags, logically OR in the new flag, and then set the flags.
- The following code turns off the nonblocking flag, assuming flags was set by the call to fcntl shown above:
flags &= ~O_NONBLOCK;
if (fcntl(fd, F_SETFL, flags) < 0)
err_sys("F_SETFL error");- The two signals SIGIO and SIGURG are different from other signals in that they are generated for a socket only if the socket has been assigned an owner with the F_SETOWN command. The integer arg value for the F_SETOWN command can be either a positive integer, specifying the process ID to receive the signal, or a negative integer whose absolute value is the process group ID to receive the signal. The F_GETOWN command returns the socket owner as the return value from the fcntl function, either the process ID (a positive return value) or the process group ID (a negative value other than -1). The difference between specifying a process or a process group to receive the signal is that the former causes only a single process to receive the signal, while the latter causes all processes in the process group (perhaps more than one) to receive the signal.
- When a new socket is created by socket, it has no owner. But when a new socket is created from a listening socket, the socket owner is inherited from the listening socket by the connected socket.
7.12 Summary
- Socket options run the gamut from the very general (SO_ERROR) to the very specific (IP header options). The most commonly used options that we might encounter are SO_KEEPALIVE, SO_RCVBUF, SO_SNDBUF, and SO_REUSEADDR. The latter should always be set for a TCP server before it calls bind (Figure 11.12). The SO_BROADCAST option and the 10 multicast socket options are only for applications that broadcast or multicast, respectively.
- The SO_KEEPALIVE socket option is set by many TCP servers and automatically terminates a half-open connection. The nice feature of this option is that it is handled by the TCP layer, without requiring an application-level inactivity timer; its downside is that it cannot tell the difference between a crashed client host and a temporary loss of connectivity to the client. SCTP provides 17 socket options that are used by the application to control the transport. SCTP_NODELAY and SCTP_MAXSEG are similar to TCP_NODELAY and TCP_MAXSEG and perform equivalent functions. The other 15 options give the application finer control of the SCTP stack; we will discuss the use of many of these socket options in Chapter 23.
- The SO_LINGER socket option gives us more control over when close returns and also lets us force an RST to be sent instead of TCP’s four-packet connection termination sequence. We must be careful sending RSTs, because this avoids TCP’s TIME_WAIT state. Much of the time, this socket option does not provide the information that we need, in which case, an application-level ACK is required.
- Every TCP and SCTP socket has a send buffer and a receive buffer, and every UDP socket has a receive buffer. The SO_SNDBUF and SO_RCVBUF socket options let us change the sizes of these buffers. The most common use of these options is for bulk data transfer across long fat pipes: TCP connections with either a high bandwidth or a long delay, often using the RFC 1323 extensions. UDP sockets, on the other hand, might want to increase the size of the receive buffer to allow the kernel to queue more datagrams if the application is busy.
Exercises(Redo)
Please indicate the source: http://blog.youkuaiyun.com/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1

















 1561
1561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









