



沙诺瓦:应用软件即服务分发模式管理脑成像研究数据库
引言 上下文
对于进行神经影像实验的研究人员和临床医生而言,两个主要关注的问题是管理大量且多样化的数据,以及能够将自己的实验和所开发的程序与同行进行比较。实际上,神经影像领域的研究人员和临床医生被鼓励开展大规模实验,但由于无法在当地招募到足够符合特定标准的受试者,因此需要通过合作来收集相关影像数据。通过互联网共享实验结果以及各中心之间的协作,可以获得更大且更具针对性的受试者群体,从而拓展科学研究的范围和价值。
对分布式神经影像数据库进行搜索,以查找包含奇异点(异常、特殊性等)的相似结果和图像,或利用数据挖掘技术,可能会揭示潜在的相似性。此类努力在保持工作质量的同时,也扩大了参与神经影像研究的人员范围。事实上,神经科学界在20世纪90年代初产生的数据激增,促使人们需要创新的数据与知识共享及再利用技术(罗兰和齐勒斯,1994;马齐奥塔等人,1995;谢泼德等人,1998)。这推动了人脑大规模项目的出现。近年来,在上述初始问题的基础上新增的一个目标是,将数据分析和数据处理软件应用于各种数据存储库系统,以实现知识发现和数据挖掘,包括最近扩展到整合影像与遗传数据的研究(希巴尔等人,2015)。
与此同时,网络应用的发展激发了研究人员和临床医生对分布式数据库和信息共享的兴趣。
如背今景,神经影像学界普遍认为,共享数据和图像处理服务将在转化研究中发挥至关重要的作用(巴里洛等人,2003;沃尔波特和布雷斯特,2011;波林等人,2012;基亚托等人,2013;范霍恩和加扎尼加,2013;波尔德拉克和戈戈列夫斯基,2014)。科研资助机构现在明确将科学资源(数据处理)的共享列为优先重点。国际组织,如国际神经信息学协调设施(INCF)目前正致力于推动神经信息学领域的发展(布克等人,2013;肯尼迪等人,2015)。转化研究需要共享数据和图像处理服务,原因如下:
(1) 用于人群范围研究的大数据集整合及影像队列的构建(Shepherd et al., 1998;Van Horn et al., 2001;Barillot et al., 2006;Evans and Brain Development Cooperative Group, 2006;Jack et al., 2008;Hall et al., 2012;Weiner et al., 2012;Marcus et al., 2013;Van Essen et al., 2013),
(2) 基于参考数据集对图像处理工具进行验证,以实现对图像处理流程的验证和质量控制(Styner et al., 2008;Menze et al., 2015),
(3) 在不同数据集和不同同行之间重用图像处理流水线以共享处理工具(Keator et al., 2009, 2013;Ooi et al., 2009;Dinov et al., 2010;Gorgolewski et al., 2011;Bellec et al., 2012;Glatard et al., 2014),以及
(4) 基于经过验证的统计分析方法对图像进行研究结果验证,以实现对实验研究的验证和质量控制(Carp, 2012;Button et al., 2013;Ioannidis, 2014;Ioannidis et al., 2014)。
这在神经影像领域尤其重要,最近几项大型多中心研究项目已经证明了这一点。这些项目包括埃文斯和脑发育合作组(2006),其开展了一项使用磁共振的研究,从出生到成年期间约500名儿童的正常脑成熟神经影像(MRI)研究,这些儿童存在行为障碍;以及阿尔茨海默病神经影像学倡议(ADNI),该倡议为其工作汇集了多种多样的图像(韦纳等人,2012)。人类连接组计划(HCP)是另一个著名实例,该计划通过1200名健康志愿者研究正常大脑中的脑连接性(马库斯等人,2013;范艾森等人,2013),说明了聚合影像数据的重要性,并将数据仓库与图像处理资源关联起来。
为了为大型或多种多中心项目提供存档解决方案,已有若干架构被提出。生物医学信息学研究网络(BIRN)在推出脑成像解决方案方面处于领先地位(Gupta et al., 2003;Keator et al., 2008,2009;Ashish et al., 2010)。另一个早期项目FMRIDC项目旨在共享基于任务的fMRI影像数据(Van Horn and Gazzaniga, 2013)。@NeurIST 建立了一个专用解决方案(由一个综合欧洲项目资助),以利用异构数据、计算和复杂处理服务来支持脑动脉瘤的研究与治疗(Benkner et al., 2010)。LORIS/CBRAIN项目是一项旨在开发泛加拿大平台的倡议,用于分布式处理、分析、交换和可视化脑成像数据(Das et al., 2011;Sherif et al., 2014)。最后,其他一些通用数据管理系统也被提出,以提供管理多中心研究的共享解决方案。这些系统包括可扩展神经影像归档工具包(XNAT)(Marcus et al., 2007),该工具包因其在大型项目管理中的集成而取得成功(Marcus et al., 2013),并具备通过专用REST网络服务与数据管理服务器via通信的能力,以及协作信息学与神经影像套件(COINS),其提供了一个基于网络的神经影像与神经心理学软件套件(Scott et al., 2011)。尽管这些平台的可扩展性是其设计动机的一部分,但它们中没有任何一个建立在形式化的语义模型或本体之上,因而无法保证原始数据架构任何演化的可持续性。
意义
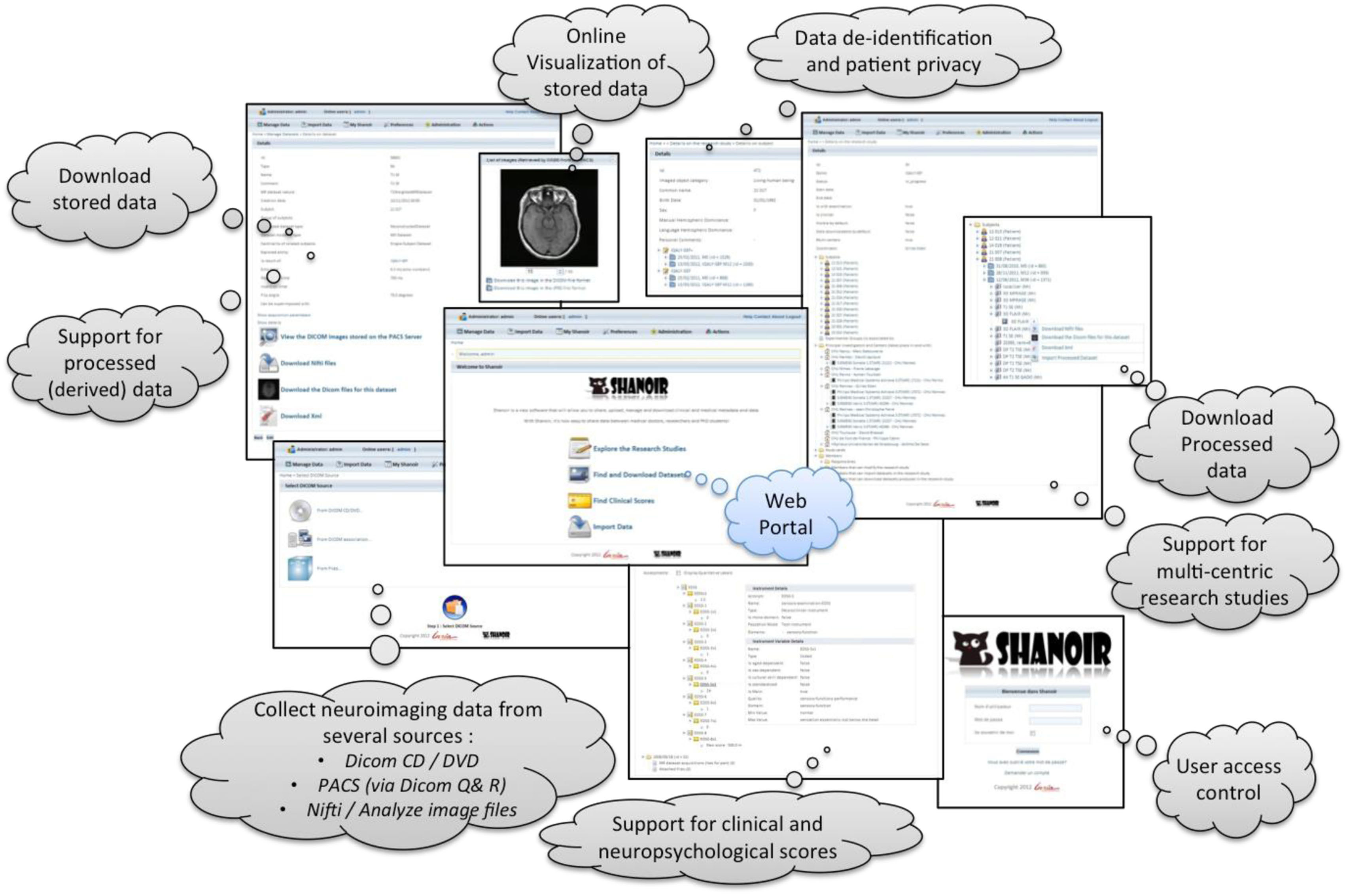
在此背景下,共享神经影像资源(Shanoir)环境可通过互联网实现分布式来源的神经影像信息共享,无论这些来源位于各个实验中心、神经科临床部门,还是认知神经科学研究中心或图像处理研究中心。大量用户因此能够几乎像本地存储数据一样便捷地通过软件即服务(SaaS)类型的云计算(Rimal 等,2009年)共享、交换并受控访问神经影像信息。
本文介绍了Shanoir软件环境,该环境用于在临床神经科学背景下管理神经影像数据的生成,并展示了如何通过沙诺瓦数据管理系统访问这些图像。Shanoir是一个开源神经信息学环境,旨在对神经影像数据进行结构化、管理、存档、可视化和共享,特别侧重于多机构协作研究项目。
该软件提供了神经影像领域常见的功能
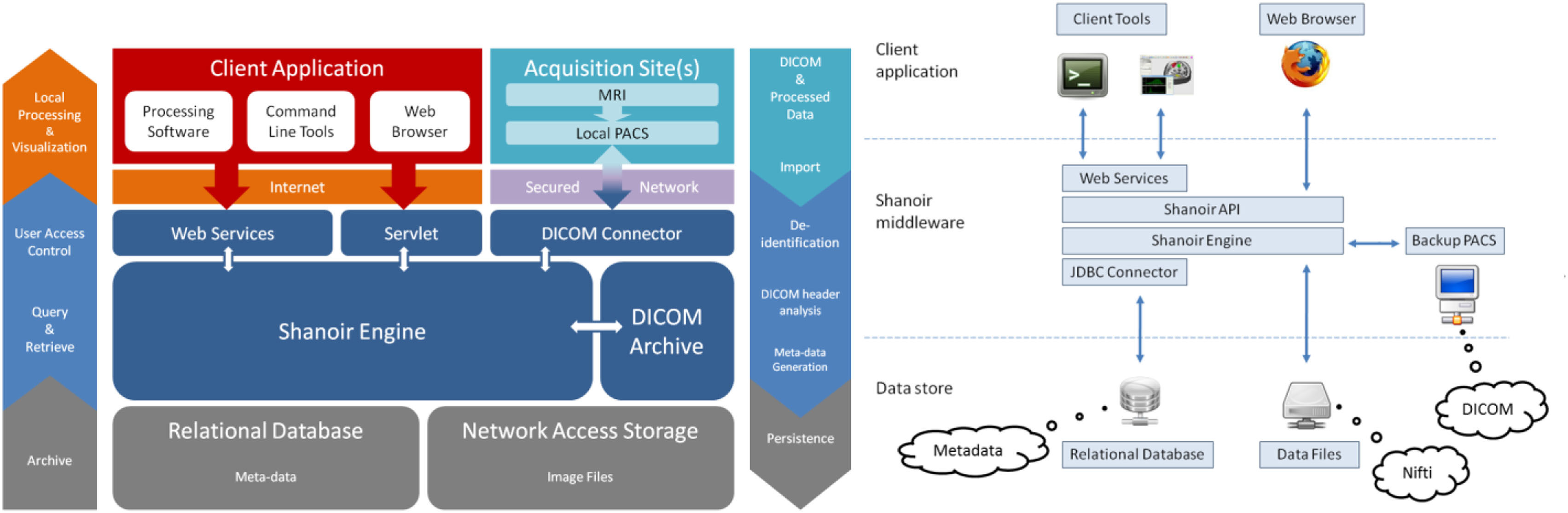
Shanoir 软件环境
软件环境概述
Shanoir 是一个采用 QPL 许可的开源软件环境,旨在存档、结构化、管理、可视化和共享神经影像数据,尤其侧重于管理协作研究项目。它包含了神经影像数据管理系统常见的功能,以及面向研究的数据组织方式和增强的可访问性。
Shanoir 基于运行在 JBoss 服务器上的安全 J2EE 应用程序,可通过浏览器中的图形界面或通过使用简单对象访问协议(SOAP)的网络服务由第三方程序进行访问。它表现为一个神经影像文件存储库,并与包含元数据的关系数据库相结合(图1)。
沙诺瓦使用语义来构建OntoNeuroLOG本体(特莫尔等人,2008;米歇尔等人,2010)所定义的概念。OntoNeuroLOG重用并扩展了先前定义的OntoNeuroBase本体(巴里洛等人,2006)(见图2)。两者均基于基础性语言与认知工程描述性本体(DOLCE)的方法论框架(特莫尔等人,2008)(马索洛等人,2003)设计而成,并一些核心本体,提供了特定领域(如人工制品、参与者角色、信息和话语行为)中的通用、基本和最小概念及关系。
在沙诺瓦中,OWL‐Lite 实现是从 OntoNeuroLOG 的初始表达式表示手动推导为 Java类 的。基于该本体的数据模型专用于神经影像领域,并围绕研究课题进行结构化,在这些研究课题中,患者接受检查以生成图像采集或临床评分。每次图像采集由数据集组成,这些数据集由采集参数和图像文件表示。出于安全和法律原因,系统上的所有数据默认均为匿名,这可以通过特定算法进行定制(例如,去识别化目前尚未实现,但可以轻松嵌入到沙诺瓦将调用的特定匿名化工具中)。
原始数据以及衍生(即后处理)图像文件也可以通过医学成像技术导入系统,例如基于医学数字成像和通信(DICOM)标准的介质、PACS或神经影像信息学技术倡议(NIfTI)/Analyze格式数据的图像文件,可通过在线向导(可自动补全相关元数据)、命令行工具或SOAP网络服务进行导入。在导入过程中,当原始数据的身份信息被移除后,系统将自动提取DICOM头内容,并加以丰富,再通过可自定义的“研究卡片”功能插入数据库中。沙诺瓦还可记录针对特定数据集所应用工作流的任何执行过程,以便与衍生数据一同进行检索。
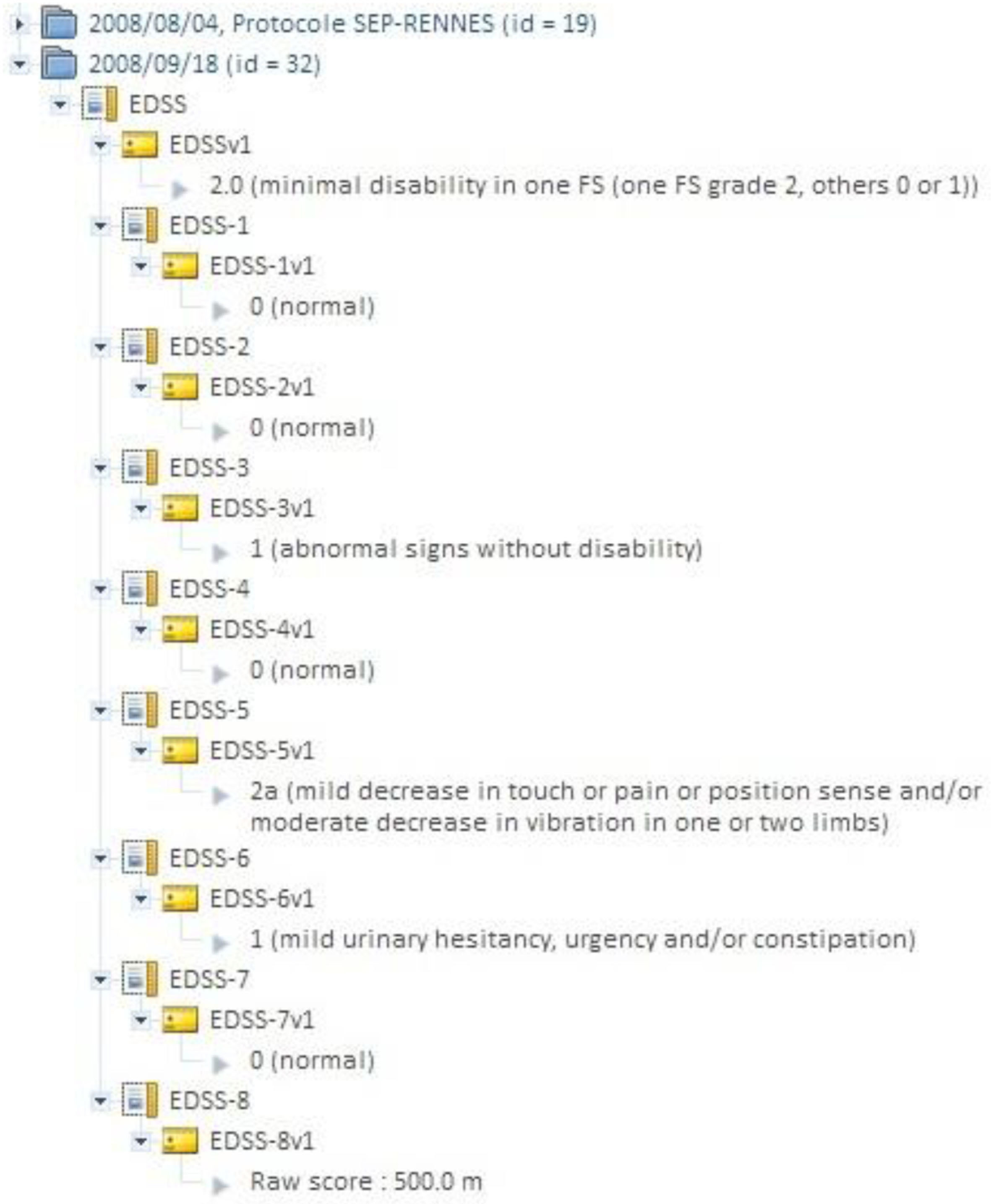
来自测量工具评估的临床评分(例如,神经心理学测试)可以被记录,并以不同格式(Excel、CSV 和 XML)轻松检索和导出。测量工具数据库具有可扩展性,可根据特定项目需求添加新的测量指标(图3)。评分、图像采集和后处理图像相互关联,以便进行关系分析。通过跨数据导航和高级搜索条件,用户可以快速指定要下载的数据子集。还开发了客户端应用程序,以便通过网络服务本地访问和利用数据。
安全
系统的功能需要使用为每个研究设置的用户权限进行身份验证。研究管理员可以定义允许查看、下载或向其研究中导入数据的用户,或者直接将其设为公开。
实际上,沙诺瓦通过高效组织研究并与其他实验室合作,为神经影像研究人员提供服务。通过管理患者隐私,沙诺瓦提供了在研究环境中使用临床数据的可能性。最后,它还是一种方便的解决方案,可用于向更广泛的社区发布和共享数据。
研究卡片和质量控制概念
图像可以从多种来源导入沙诺瓦,包括DICOM介质、PACS(通过DICOM查询与检索)以及3D/4D图像文件(采用NIfTI/Analyze格式)。用户可通过在线表单逐步完成导入操作。除了归档DICOM文件外,系统还会自动生成并保存NIfTI副本。由于NIfTI格式比DICOM格式更适用于图像处理(如配准、分割和统计分析),这一功能非常便捷。
研究卡片
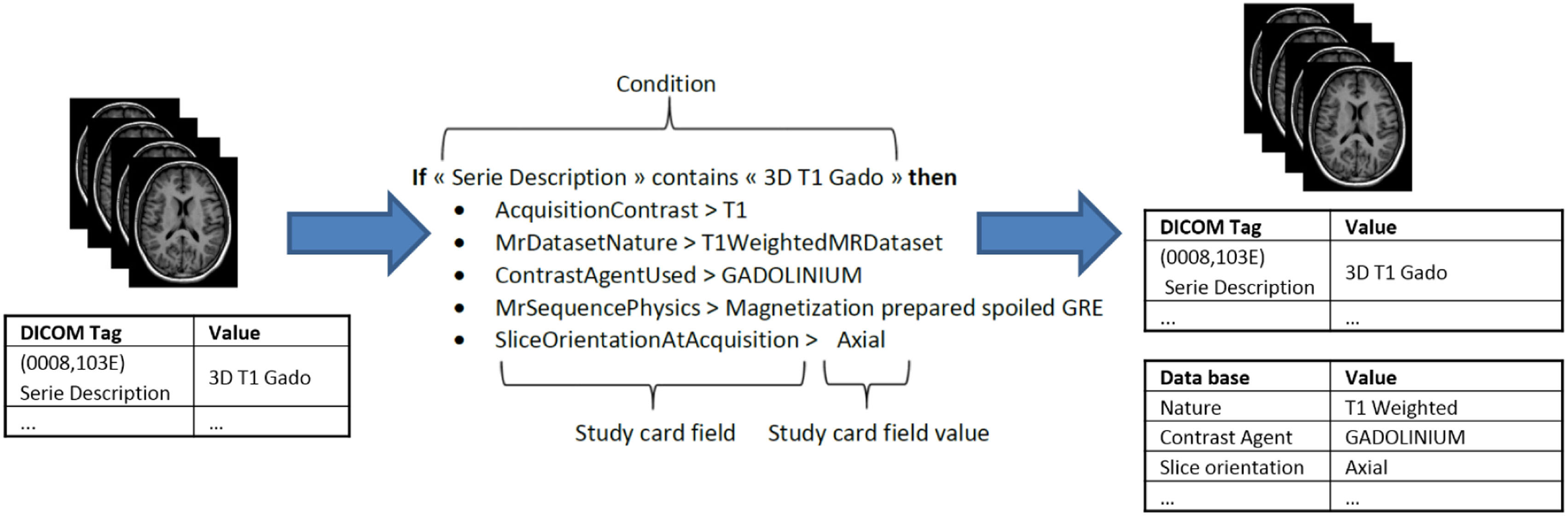
在归档期间,医学数字成像和通信文件会经过两个阶段处理。第一阶段去除图像身份信息。第二阶段使用从DICOM头生成并结合研究卡片进行丰富的新元数据项填充数据库,从而实现待导入的本地数据(如中心、采集设备等)与数据将被分配到的研究项目的语义概念之间的在线元数据封装。因此,实际的DICOM元数据可以与本体对齐,并为存储的图像提供更贴近研究方案的额外概念分配(例如,功能性磁共振成像、灌注成像、对比剂、弥散成像等)。该功能背后的机制基于用户预先定义的一组规则,用于将特定的采集设备和特定的数据生产地点关联到目标研究项目。每条规则根据一个或多个特定DICOM标签(例如,序列描述,见图4)的值确定元数据项的具体值。这极大地促进了研究项目中所有数据的元数据在导入图像时无需繁琐流程即可一致记录并与其本体对齐。由于流程简单,执行数据导入无需特殊技能,通过互联网仅需几分钟即可完成。
“研究卡片”概念使得利用元数据对导入数据进行自动质量控制成为可能。例如,可根据与研究卡片规则的匹配分数,为导入的数据附加一致性声明。
质量评估
沙诺瓦的下一个主要功能涉及对图像进行质量检查,以确保导入的数据符合预定义的研究方案,并保证归档数据的完整性。我们确定了三个级别的控制:
- 研究方案 :由该研究的主要研究者(PI)定义,控制检查之间的时间间隔(预期访问);
- 采集协议 :由该研究的主要研究者(PI)定义,控制成像协议中所有序列的存在;
- 原始数据 :
- 该软件会自动检查给定协议、实验中心或采集的参数范围根据主要研究者的技术代表在研究卡片中定义的扫描仪;
- 可以对图像质量和完整性的目视检查结果进行报告并分配给导入的数据;然而,用于检测视觉质量的机制尚未集成到 Shanoir 环境中。
在 Shanoir 的下一个版本中,质量评估将以数据库中的标志(无缺陷、可接受或不可接受)形式存在。
此质量保证功能不涉及对图像形成的控制,例如检查图像人工制品(偏置、运动、重影等)。此类质量保证可通过专用的图像可视化和处理工具来实现,这些工具通过专用的网络服务与沙诺瓦进行互操作。
网络门户
沙诺瓦提供用户友好的安全网络访问,并通过直观的工作流程,促进从多个来源采集和检索神经影像数据(图5)。
在主页上,用户可直接访问最常用的功能:查找和下载数据集、浏览研究项目、查找临床评分和导入数据(图6)。
在所有页面的顶部,用户始终可以使用完整的导航菜单,通往所有服务。
互操作性
互操作性对于Shanoir环境而言是一个非常重要的问题。
Shanoir提供了面向多种客户端的开放Web服务接口。我们已经为不同的外部应用程序提供了多个专用接口。以下将介绍目前可用且彼此独立运行的四项外部服务: ShanoirUploader、Qt沙诺瓦、medInria和iShanoir,这些服务分别在C++、Java或Objective‐C环境中开发。
SOAP 用于服务集成
沙诺瓦(Shanoir)的Web服务接口基于SOAP。客户端与服务器之间的消息通过具有明确定义元素的可扩展标记语言(XML)进行交换。通信采用带有传输层安全性(TLS)的超文本传输协议(HTTP)。元素和服务使用Web服务描述语言(WSDL)进行描述。基于此描述,可以自动生成客户端存根,以简化新客户端的连接。该Web服务层通过用于XML Web服务的Java API(JAX‐WS)实现。
Shanoir 提供了众多专用的网络服务:
- “EntityCreator”:创建新实体,例如在数据库中创建新受试者
- “CredentialTester”:验证用户名和密码是否正确
- “下载器”:基于数据集ID下载文件/数据集
- “中心查找器”:根据不同的搜索条件(例如研究或调查者)查找中心
- “数据集采集查找器”:根据ID或检查查找采集信息
- “DatasetFinder”:根据多个搜索条件/筛选器查找数据集
- “DatasetProcessingFinder”:根据 ID 查找数据集处理
- “ExaminationFinder”:根据多个搜索条件/筛选器查找检查
- “ExperimentalGroupOfSubjectsFinder”:根据多个条件查找受试者组
- “InvestigatorFinder”:根据 ID 或研究中心查找研究者
- “MrDatasetFinder”:根据多个搜索条件/筛选器查找 MR 数据集
- “研究查找器”:根据多个搜索条件/筛选器查找研究项目
- “受试者查找器”:基于多个筛选条件的ID查找受试者
- “数据集导入器”:将数据集文件导入到数据库中已存在的实体
- “参考列表生成器”:显示存储在数据库中的参考字符串列表
- “文件上传器”:上传本地存档中的文件以供后续导入,由 Shanoir上传器使用
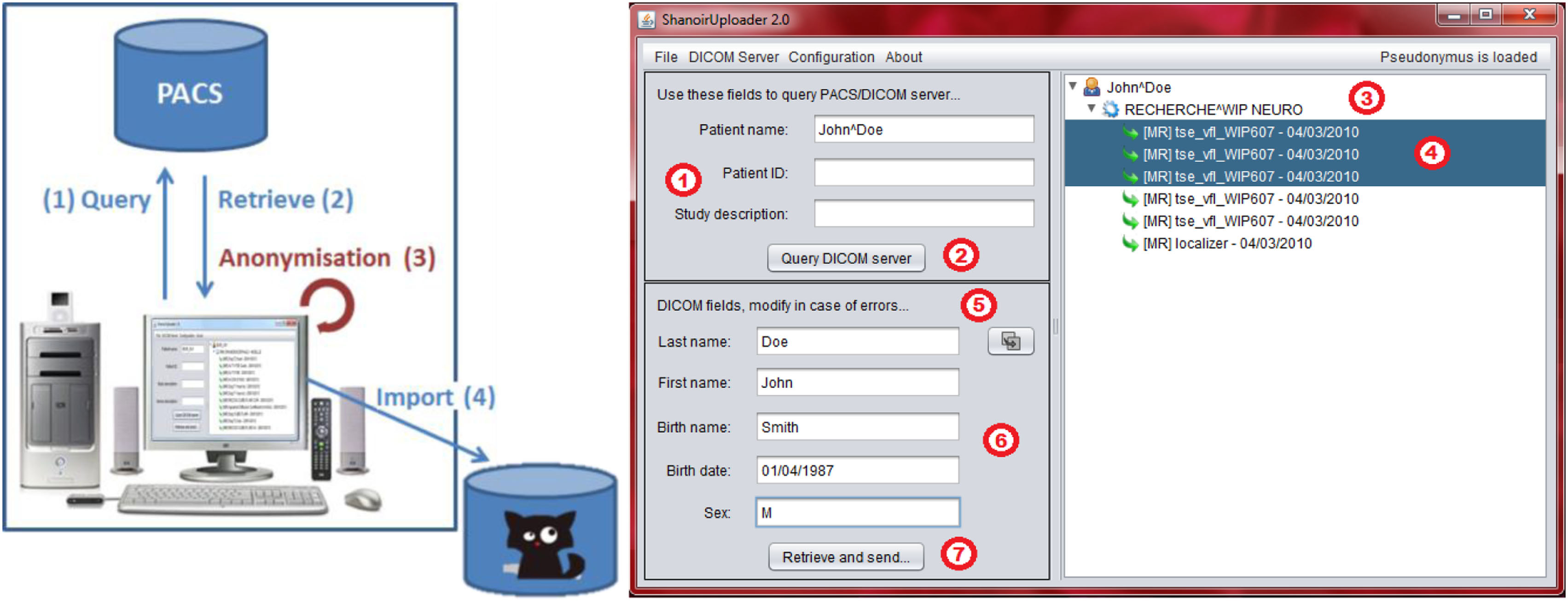
Shanoir上传器用于数据的无缝集成
“ShanoirUploader” 是一款 Java 桌面应用程序,可在 PACS 与 Shanoir服务器 实例之间(例如在医院内部)安全地传输数据。它既提供了直接的医学数字成像和通信查询/检索连接,用于从本地 PACS 搜索和下载图像,也具备医学数字成像和通信光盘上传功能。在检索之后,医学数字成像和通信文件会在本地进行匿名化处理,然后上传至 Shanoir服务器(匿名化算法可根据特定的操作/法规限制进行定制)。该应用程序的主要目标是实现不同远程服务器实例之间的大规模数据传输,并减少将数据导入沙诺瓦时的用户等待时间。因此,大部分导入时间都用于数据传输。
“Shanoir上传器”需要本地Java安装。为了更简单地分发和安装该软件,Java可以使用Web Start(JWS)。该应用程序可通过在网络浏览器中打开一个简单的网络链接进行安装。Java负责安装,以及后续的自动更新。内部组件基于Java Swing构建图形界面用户界面(图7)、dcm4chee库用于连接PACS以及Java和 Web服务(JAX‐WS),以将数据传输到Shanoir服务器。
 .)
.)
Apache Solr用于元数据查询
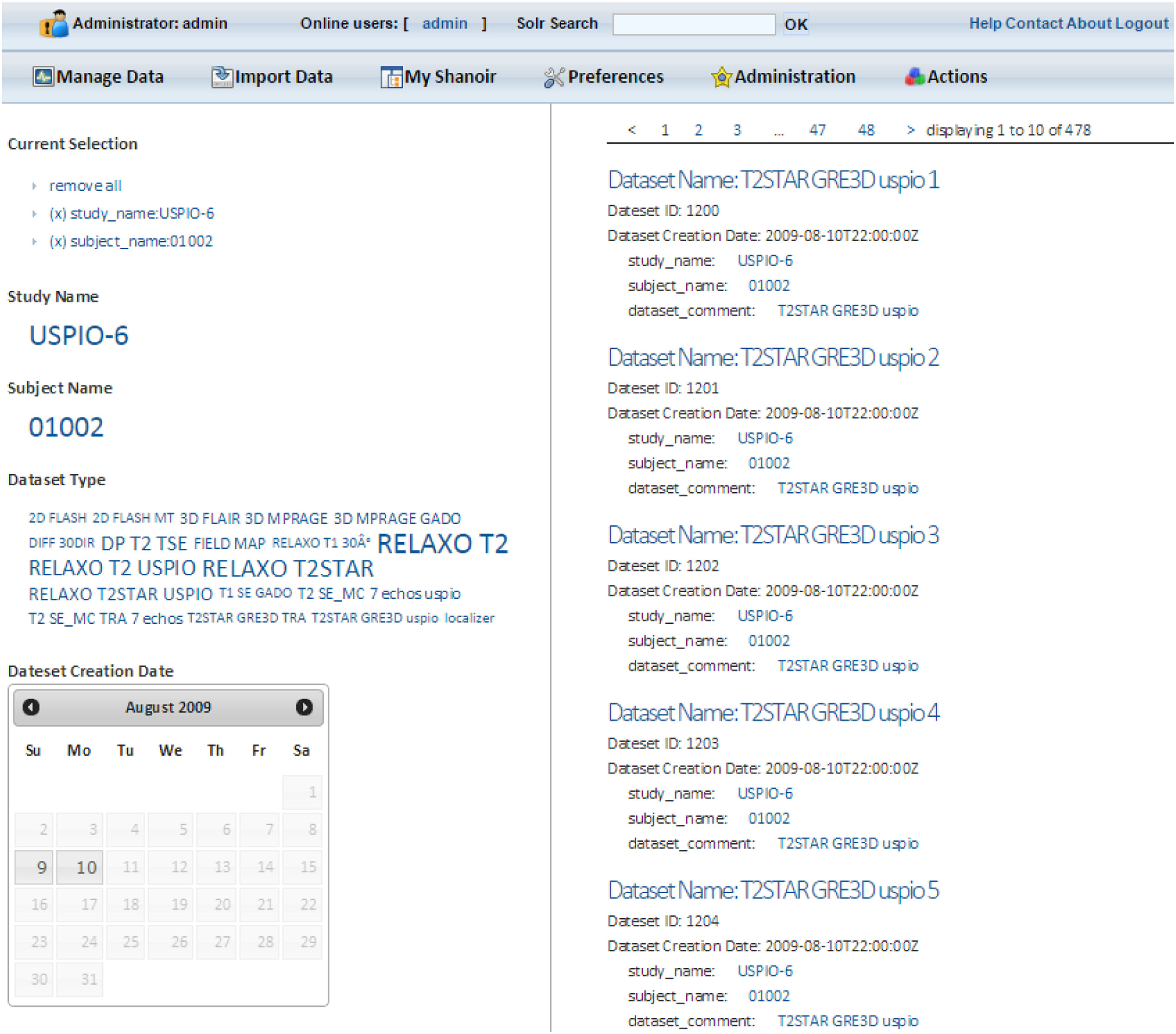
沙诺瓦集成了开源企业搜索平台Apache Solr,为用户提供了一系列高级功能,如近实时索引和查询、全文搜索、分面导航、自动建议和自动补全。
Solr搜索最重要的功能之一是分面导航。分面对应于 Solr信息元素的属性,并通过分析与沙诺瓦所使用的本体模型相关的预存元数据得出。
沙诺瓦用户可通过简单的Solr搜索栏访问所有元数据。输入至少一个字符后,系统将自动引导用户完成搜索。数据按类别排序,选择某个面(facet)后会动态显示。通过点击Solr数据结果,用户可访问沙诺瓦中与其搜索相对应的所有附加信息,并利用这些查询进行本地下载(图8)。
所有元数据均被索引到托管Solr Servlet的JBoss服务器中。此外,已在沙诺瓦中开发并实施了自定义的安全后过滤器以控制用户访问。该过滤器获取沙诺瓦中的用户标识和访问权限,并与Solr服务器交互,以显示用户有权访问的相关结果。
iShanoir 用于移动数据访问
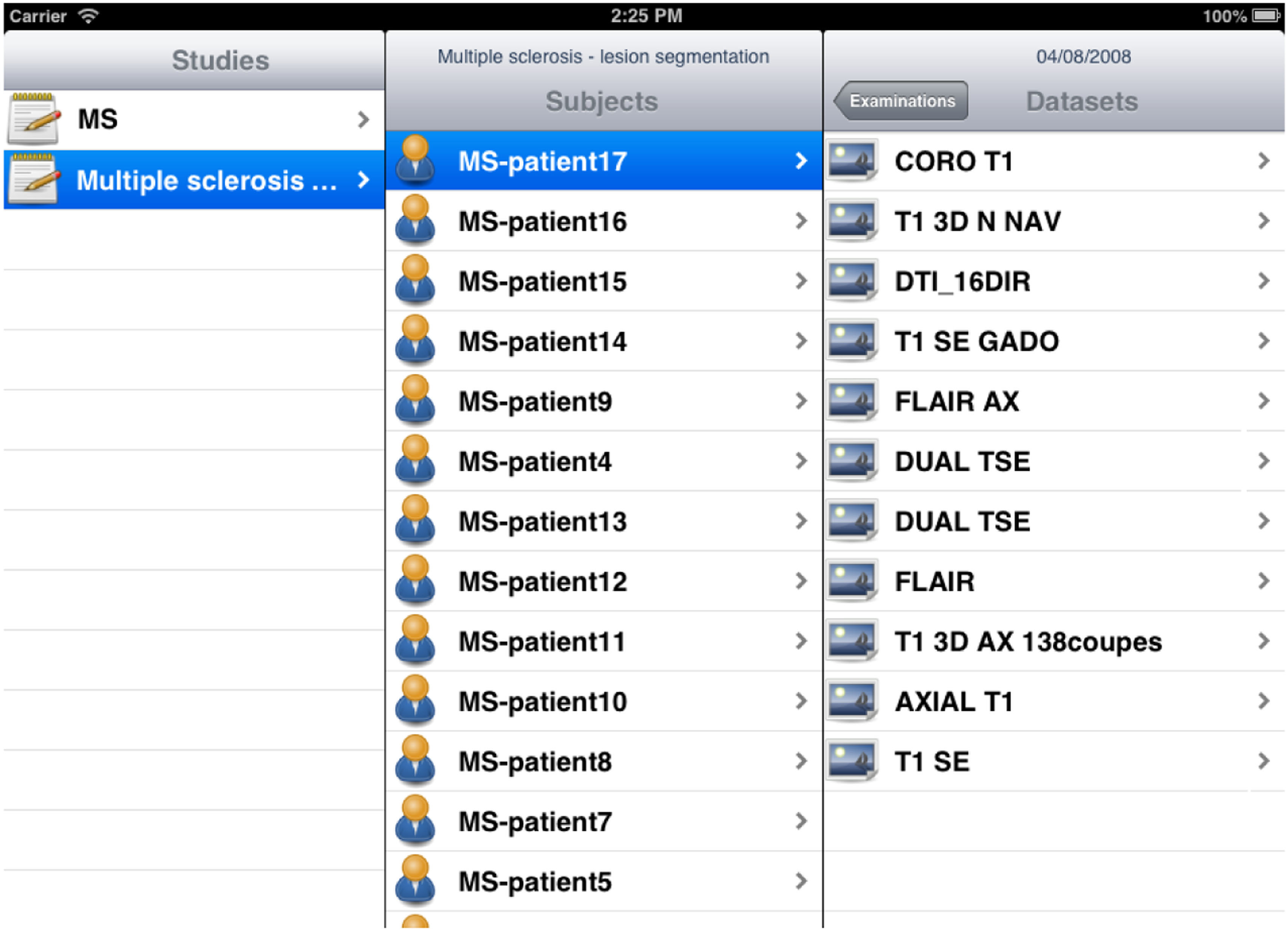
一款名为iShanoir的iOS应用程序已为iPhone和iPad开发,它可与Shanoir服务器建立安全连接,并使用户能够访问存储在Shanoir服务器上的数据。通过 iShanoir,用户可以在Shanoir服务器的数据树结构中进行浏览。在移动应用程序中选择数据后,图像可以下载到本地设备,并通过任何本地DICOM查看器或云服务(例如 Dropbox、iCloud、谷歌或OneDrive)进行显示和分析。
iShanoir 应用程序使用 Xcode 开发,并以 Objective‐C 实现。对于图形用户界面,开发了两个故事板以适配 iPhone 和 iPad 之间的不同显示屏尺寸(图9)。该应用使用了以下 iOS 框架:Foundation、CoreFoundation、 UIKit 和 CFNetwork。为了实现 SOAP 网络服务客户端,采用了 WSDL2ObjC 工具,因为它可以根据服务器 WSDL 文档提供客户端存根代码生成。
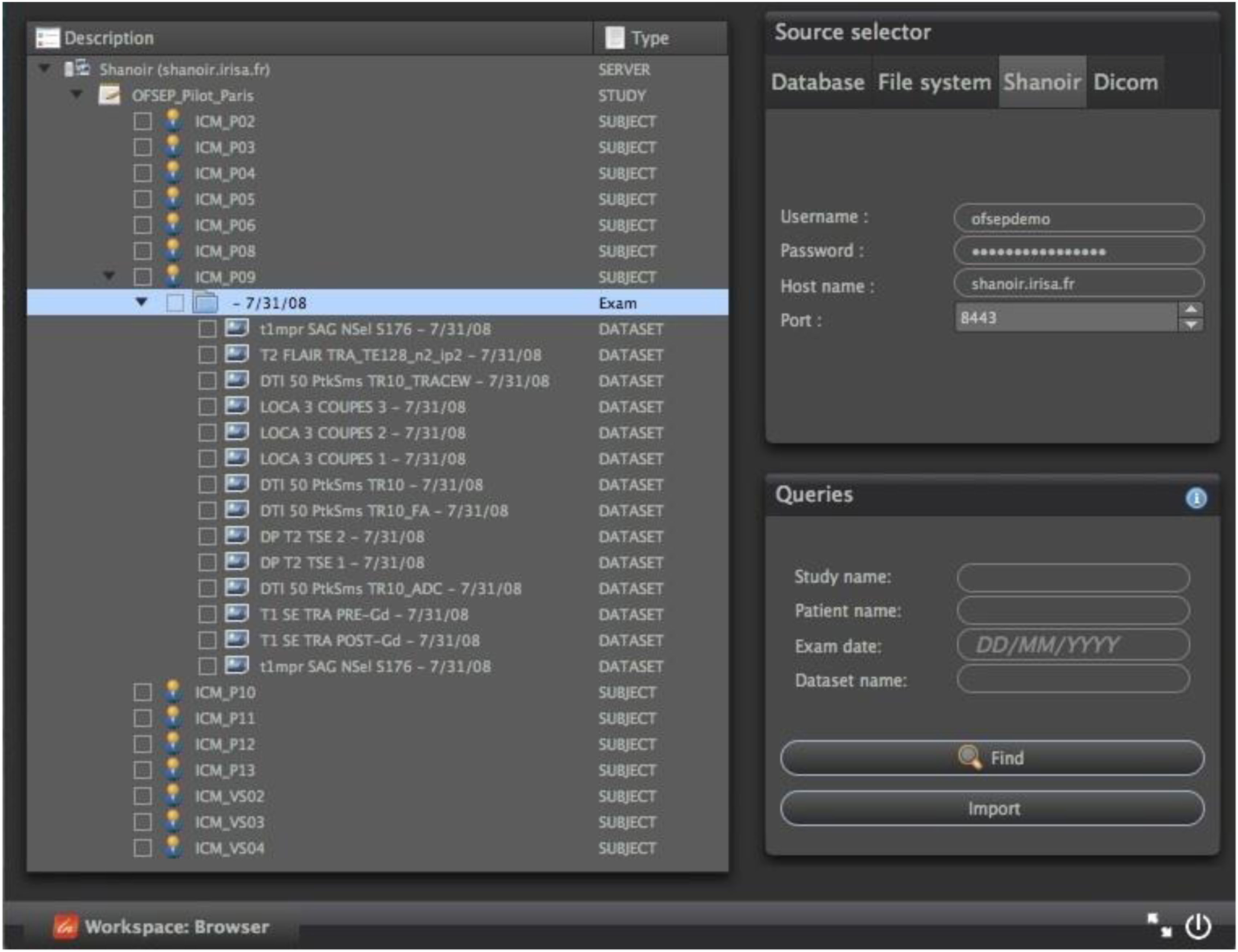
Qt沙诺瓦用于图像处理
沙诺瓦网络服务还可以通过QtShanoir库从独立的C++/ Qt应用程序进行查询,该库使用沙诺瓦服务器提供的 SOAP网络服务来访问和显示研究、患者及数据及其相关元数据。在QtShanoir中定义了一组Qt小部件,可以嵌入到任何Qt应用程序中。该库被用于在medInria可视化与处理软件中实现一个沙诺瓦查询插件,以从沙诺瓦查询和下载图像数据并在medInria中进行处理(例如使用可用的处理工具),然后将处理结果连同正确的元数据值上传回沙诺瓦服务器(图10)。
沙诺瓦的分发
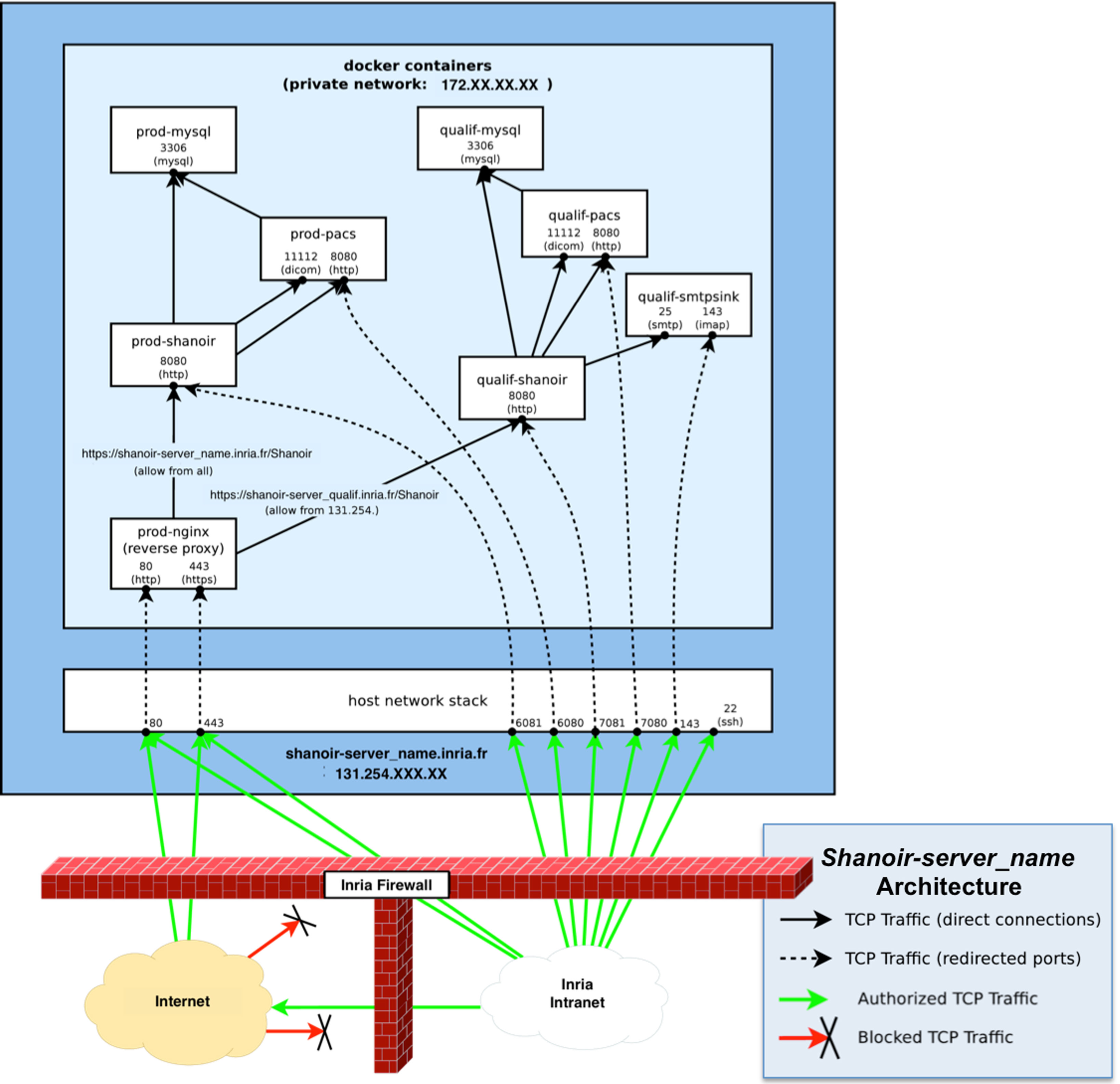
Shanoir服务器可按请求免费下载。目前,它通过在Linux上运行的Docker容器进行部署。Docker是用于在Linux上管理轻量级虚拟化(称为容器)的工具,比传统虚拟机更轻量。主机和客户机系统共享同一个内核。内核负责主机↔ 客户机和客户机↔ 客户机的隔离(系统调用的结果取决于调用进程所运行的容器)。如图11所述,一个最小化的沙诺瓦部署包含四个服务器,分别运行在至少四个独立的容器中:
- “Shanoir容器”:实际的Shanoir服务器。它依赖于一个_mysql容器(用于数据库)和PACS容器(用于存档DICOM数据),
- “pacs_container”:由dcm4chee管理的医学数字成像和通信PACS服务器,
- “mysql_container”:托管两个数据库shanoirdb和pacsdb的数据库服务器,
- “nginx_container”:基于配置为反向代理以访问Shanoir服务器的nginx HTTP服务器的Web前端服务器。它是唯一可公开访问的服务器,提供TLS加密和安全过滤,
- “smtpsink_container”:用于外发邮件的可选SMTP服务器。
数据存储库
每个沙诺瓦存储库都有一位管理员,负责管理该存储库的访问权限。每位用户通过基于网页的表单申请账户,并注明其希望访问的研究项目、联系方式、在研究中的角色、所需的专长/访问级别(客户机、用户、专家或管理员)等信息。根据所提供的信息,沙诺瓦存储库的管理员将决定该用户是否可以访问系统。对特定研究项目的访问权限由该研究项目的负责人(即主要研究者或官方代表)授予。根据这些设置,新用户将能够查看、下载和导入数据集,甚至修改研究参数。相应的权限将在有限的时间内生效,需定期续期。如用户提出请求,每当有数据导入研究时,系统可通过电子邮件向其发送报告。
shanoir@Neurinfo 仓储
始于2009年,Neurinfo MRI 研究设施促进转化临床研究并支持发展临床研究、技术活动和方法学活动。它为活体人体成像采集、图像数据分析和图像数据管理提供资源。一个庞大的用户群体,包括临床医生和科学家,将这些资源用于本地、国家和国际的基于成像的研究项目。
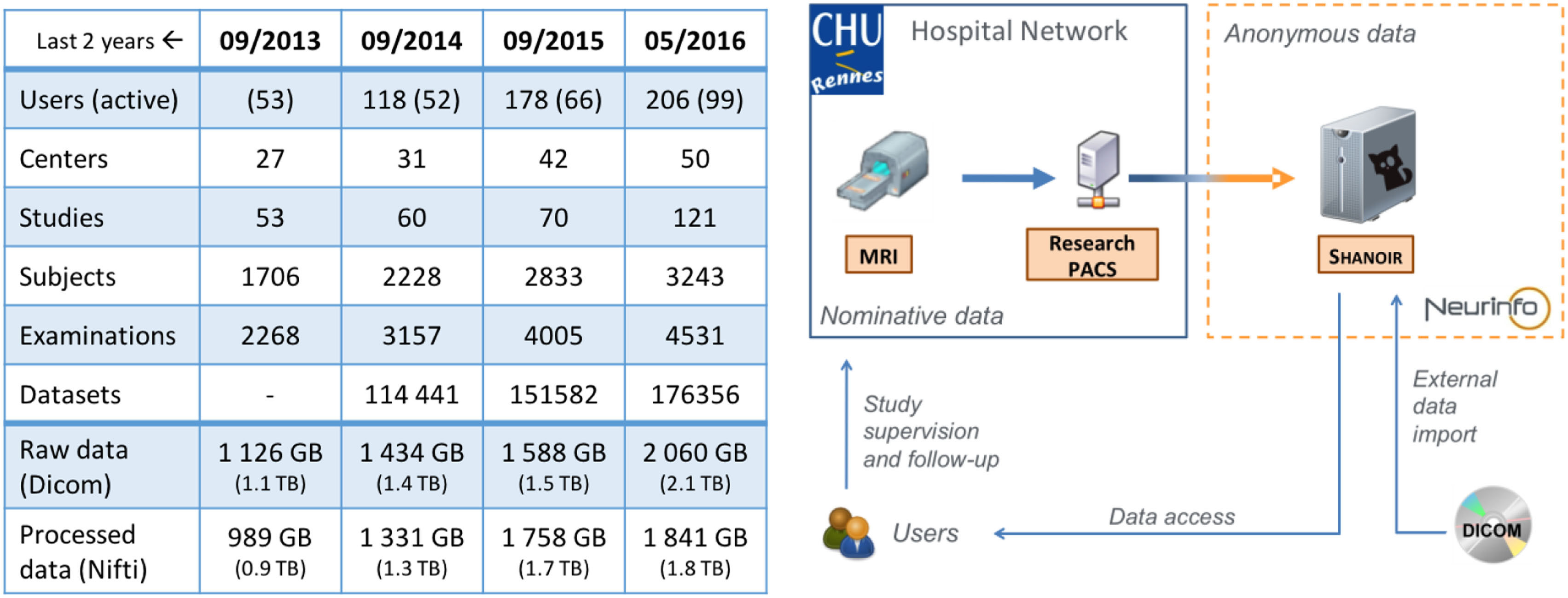
纽尔信息为学术或临床研究目的产生的所有数据均通过由该机构工作人员管理的专用Shanoir@Neurinfo存储库(图12)进行管理。Shanoir@Neurinfo服务器还托管来自多个站点的影像研究数据。目前,该存储库已归档来自42个中心和50台MR扫描仪的约2太字节数据。数据量每月增加30吉字节(见图12中的表格)。
在日常实践中,技术人员从本地PACS、光盘/DVD或根目录下包含DICOMDIR及DICOM文件的磁盘驱动器导入 DICOM数据。
存储在纽尔信息沙诺瓦服务器上的临床研究涉及全身(脑、脊柱、心脏、肺、骨盆、血管等),重点是正常对照和病理人群的脑解剖学与功能。
在纽尔信息平台正在进行的大约70项研究课题中,75%涉及脑成像,15%涉及腹部成像,10%涉及心脏成像。在神经影像临床研究中,多发性硬化症、痴呆、肿瘤、中风和情绪障碍是最受关注的病理。
根据具体研究的性质,典型的神经影像协议包括结构成像、功能BOLD MRI、动脉自旋标记灌注成像、弥散成像、弛豫测量序列、钆前和钆后T1加权序列或血管序列。
以下研究是使用Shanoir@Neurinfo服务开展的研究示例,以及由Shanoir@Neurinfo存储库管理的数据类型。除了MRI原始数据外,每个数据集的后处理图像也可以被存储。例如,在一项关于功能运动激活的研究中,训练有素的放射科医生勾画出运动区域,并将其与每个3D T1加权图像相关联。多发性硬化症(MS)病灶分割掩模也可以附加到检查中。除了图像数据外,受试者的临床评分也可以存储在存储库中。多项多发性硬化症临床研究收集诸如新T2病灶数量、T1加权钆增强病灶数量或扩展残疾状态量表(EDSS)等临床评分。这些测量结果也被包含在搜索引擎中,因此可以通过请求轻松访问。对于更高级的临床随访,沙诺瓦(Shanoir)可以轻松地与现有数据库进行对接。
shanoir@Neurinfo 仓储中关于特定研究相关数据传播的总体政策,需事先与主要研究者(PI)协商确定,并符合由伦理委员会批准且由参与者签署的知情同意书。任何向第三方开放数据的行为,均须在允许第三方用户(完全或部分)访问之前,获得主要研究者(PI)的批准。然而,为了确保通过公共资金获取的数据得到广泛传播和最佳利用,纽尔信息团队强烈鼓励研究人员共享其数据,此类共享通常在禁运期结束后进行。
沙诺瓦@OFSEP仓库
法国多发性硬化症观察站(OFSEP)是科学界用于多发性硬化症的重要流行病学工具,在法国未来投资计划资助的队列2010项目征集后被选中。该项目是一个合作项目,涉及法国40多个多发性硬化症研究中心。项目的目标是建立并维护一个全国性多发性硬化症患者队列,并通过生物样本、社会经济数据和神经影像来丰富临床数据。
一个专门的影像工作组负责获取、处理和整合影像及衍生影像数据到共享影像资源中心(IRC),并确保IRC与临床数据库相整合。对基于磁共振成像的测量进行大规模一致性评估需要稳健高效的图像处理流程。本项目的另一个目标是建立一个信息技术基础设施,以实现对影像数据的审计访问,并提供一个虚拟实验室环境,支持由不同国内和国际研究中心开发的专业化图像分析流程的分布式协同开发、验证和部署。为确保便捷访问影像数据并允许进行修改、查询、注释和访问控制,已选定 Shanoir环境。它还将确保与队列影像部分相关的互操作性和数据管理(临床部分由EDMUS系统管理)。为此,我们已建立了一个特定的沙努瓦@OFSEP影像存储库,目前该存储库处于试点阶段。
沙努瓦@OFSEP 服务器始于2012年,用于存储 OFSEP队列的影像数据,该队列将在未来10年内研究4万名多发性硬化症患者的神经影像数据。关于采集协议已达成共识,要求每3年至少进行一次脑部MRI,每6年进行一次脊髓MRI,即在10年内完成20万次MRI。沙努瓦@OFSEP数据库将在这一时期及之后持续增长(科顿等人,2015年)。
由于OFSEP是一个覆盖众多患者、多个IRC以及多种不同类型MRI采集设备的全国性项目,因此需要一个具有全国访问权限和统一措施的国家存储库。OFSEP影像工作组正在持续吸纳新的采集中心自愿加入该队列。在沙努瓦 @OFSEP中,目前约有30个IRC,包括31台MRI采集设备,代表来自三家MR制造商(西门子、飞利浦和通用电气)的14种不同的MR扫描仪型号。所有中心均按照“母队列”这一主研究进行数据导入。每个中心遵循OFSEP协议,该协议将通过“质量评估”部分所述的质量控制模块进行检查。
如有必要,衍生影像数据可重新导入服务器,以便参考潜在的后处理信息和多发性硬化特异性影像生物标志物,供授权用户使用。
目前,沙诺瓦@OFSEP仓库已托管了五项研究:“母队列”(计划在未来进行20万次MRI)10年)以及四项多发性硬化影像临床研究项目。未来几年将整合更多“OFSEP认证”的临床研究项目或嵌套队列。只要使用OFSEP方案,任何人都可以加入“母队列”研究。此外,一旦主要研究者向OFSEP科学委员会提交其研究课题并获得批准(或不批准)主机资格,也可请求OFSEP通过其研究为项目做出贡献。存储在沙努瓦@OFSEP上的数据在研究期间将保持保密(私有),但可通过特定OFSEP应用程序向所有研究人员开放。
结论与展望
Shanoir 软件即服务通过互联网管理分布在神经影像领域的信息源的共享,无论这些资源位于实验中心、神经科临床科室,还是认知神经科学或图像处理的研究中心。通过对管理 Shanoir 环境的两个存储库(Neurinfo 和 OFSEP)的描述,我们展示了大量用户如何在对等节点之间传播、共享或访问神经影像信息,其便捷程度几乎如同数据存储在本地医院、研究实验室或公司中一样。通过对 Shanoir 软件环境的描述,我们展示了神经影像数据如何被结构化、管理、归档、可视化和共享。
在中期,我们计划通过法国国家基础设施“法国生命成像”(FLI) ,特别是其致力于为活体成像提供大规模IT基础设施的“信息分析与管理”(IAM)节点,将沙诺瓦的资源和服务与开放社区整合。为此,FLI–IAM节点将构建并运营一个用于存储、管理和处理来自人体或临床前程序的 in vivo 成像数据的基础架构。IAM 节点的主要成果将包括一个由多个子组件组成的多功能软件平台,该平台将连接软硬件设施以实现以下建设:一个用于体内图像的存档与管理基础设施,以及通过专用的软硬件解决方案处理和管理所获取数据的方案;用于活体成像的多功能图像分析和数据管理解决方案,以促进生产站点与用户之间的互操作性,并为原始数据和元数据索引提供异构和分布式存储解决方案(例如,通过使用语义模型)。
因此,我们正在将沙诺瓦(Shanoir)作为FLI‐IAM设施的数据管理解决方案之一进行整合,同时整合一系列配套的数据管理软件平台,例如CATI‐DB和ArchiMed,以及一系列处理客户端或高性能计算工作流设施,例如 medInria、BrainVisa、和VIP平台。为此,在 FLI‐IAM内部,我们正在建立这些平台之间的“胶合层”,以实现它们之间的连接与互操作。此外,通过FLI‐IAM,我们将提供必要的信息,以便其他资源加入通过定义基本的合规性声明,实现FLI‐IAM基础设施,从而使FLI‐IAM的技术和可扩展性成为可能。
尽管如此,如“引言”部分所述,最近在医学影像研究领域出现了许多类似的倡议,例如人脑计划、阿尔茨海默病神经影像学倡议、基于XNAT的解决方案等。对于这些倡议以及沙诺瓦而言,目标都是在很大程度上共享数据。如果没有在该领域的标准化以及针对相似服务的软件平台之间的互操作性方面付出重大额外努力,这是无法实现的。这正是沙诺瓦被纳入法国FLI‐IAM电子基础设施倡议的原因。未来面临的挑战是在国际层面上持续推进这一努力。

















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









