




 本文介绍了一款用于抓取优快云博客文章的Python爬虫程序,该程序能够遍历指定用户的博客页面,抓取每篇文章的链接并下载其内容。通过使用urllib和正则表达式,爬虫能够有效地解析网页并保存文章为本地HTML文件。
本文介绍了一款用于抓取优快云博客文章的Python爬虫程序,该程序能够遍历指定用户的博客页面,抓取每篇文章的链接并下载其内容。通过使用urllib和正则表达式,爬虫能够有效地解析网页并保存文章为本地HTML文件。
# -*- coding: utf-8 -*-
import html
import os
import queue
import re
import threading
import urllib
'''author fzuim'''
BlogSet = set()
class CsdnBlogSpider:
def __init__(self, bolgname, myqueue):
self.bolgname = bolgname
self.pageindex = 1
self.myqueue = myqueue
self.blogurl = 'https://blog.youkuaiyun.com/' + bolgname
self.getfinish = False
def GetPageCode(self, PageIndex):
pageurl = self.blogurl + '/article/list/' + str(PageIndex)
try:
req = urllib.request.Request(pageurl)
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
res = urllib.request.urlopen(req)
Code = res.read().decode('utf-8')
return Code
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print(u'查看博客失败:', e.reason)
return None
def GetBlogList(self):
global BlogSet
Code = self.GetPageCode(self.pageindex)
# 判断是否爬取完毕
IsNone = re.search(u'空空如也', Code)
if IsNone:
self.getfinish = True
return
# 获取当前页,所有博客链接
rule = '/' + self.bolgname + '/article/details/' + '\\d*'
# 用以下正则,会多匹配到一篇为yoyo_liyy写的[帝都的凛冬]....
# rule = '<main>.*?class="article-list">.*?<a href="(.*?)" target='
pattern = re.compile(rule)
for url in pattern.findall(Code):
url = 'https://blog.youkuaiyun.com' + url
if url not in BlogSet:
self.myqueue.put(url)
BlogSet.add(url)
self.pageindex += 1
def SaveHtmlData(self):
while True:
try:
# Queue.get为阻塞获取,设置超时5秒,若获取不到则认为总的爬取完毕,自动退出线程
url = self.myqueue.get(timeout=5)
except queue.Empty:
break
print(u'正在爬取-->', url)
try:
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')
res = urllib.request.urlopen(req)
Data = res.read().decode('utf-8')
# 解析博客标题
title_re = '<div class="article-title-box">.*?class="article-type.*?>(.*?)</span>'
title_re += '.*?<h1 class="title-article">(.*?)</h1>'
pattern = re.compile(title_re, re.S)
items = re.findall(pattern, Data)
for item in items:
title = '[' + item[0] + '] ' + html.unescape(item[1])
# 文件名特殊字符替换,否则文件创建失败
title = title.replace('\\', '-').replace('/', '-').replace(':', '-').replace('*', '-').\
replace('?', '-').replace('"', '-').replace('<', '-').replace('>', '-').replace('|', '-')
# 保存成.html格式文件
if not os.path.exists('blog'):
blog_path = os.path.join(os.path.abspath('.'), 'blog')
os.mkdir(blog_path)
try:
fout = open('./blog/' + title.strip() + '.html', 'wb')
fout.write(Data.encode('utf-8'))
except IOError as e:
print(e)
finally:
fout.close()
except urllib.error.URLError as e:
if hasattr(e, 'reason'):
print(u'爬取失败:', e.reason)
self.myqueue.task_done()
def Start(self):
self.getfinish = False
thread = threading.Thread(target=self.SaveHtmlData)
thread.start()
while not self.getfinish:
self.GetBlogList()
thread.join()
print(u'爬取完毕...')
if __name__ == "__main__":
blogname = input(u'请输入待爬取的博客名称:')
myqueue = queue.Queue()
spider = CsdnBlogSpider(blogname, myqueue)
spider.Start()
运行示例: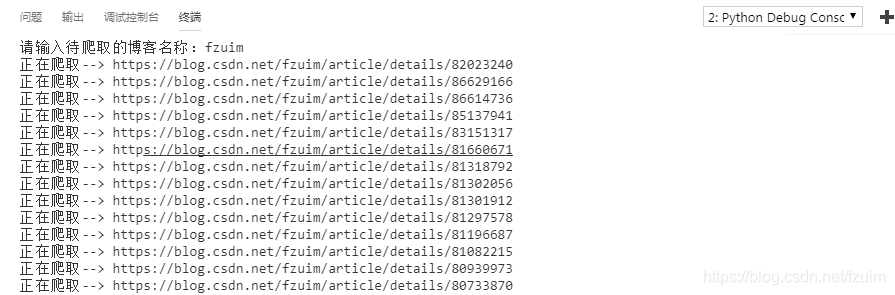


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









