




 该博客记录了语义分割和目标检测的学习笔记。语义分割部分介绍了FCN、U-net、SegNet和deeplabv1 - v3系列等方法,分析了各方法的原理、优缺点及改进点;目标检测部分提及了R-CNN。还总结了语义分割的一些研究思路和要点。
该博客记录了语义分割和目标检测的学习笔记。语义分割部分介绍了FCN、U-net、SegNet和deeplabv1 - v3系列等方法,分析了各方法的原理、优缺点及改进点;目标检测部分提及了R-CNN。还总结了语义分割的一些研究思路和要点。
语义分割
FCN
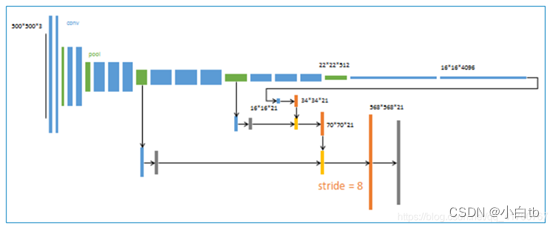
FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。与上面介绍的经典CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。
缺点
得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感
对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性
原文链接:https://blog.youkuaiyun.com/qq_41760767/article/details/97521397
U-net
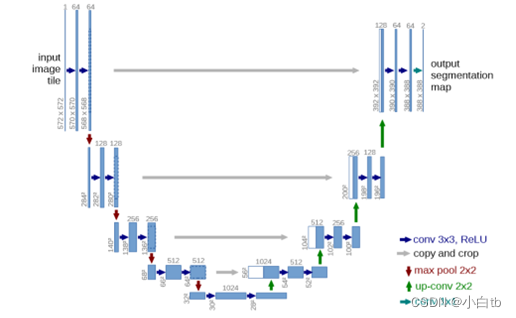
U-net是一个用于医学图像分割的全卷积神经网络。目前很多神经网络的输出结果都是最终的分类类别标签,但对医学影像的处理,医务人员除了想要知道图像的类别以外,更想知道的是图像中各种组织的位置分布,而U-net就可以实现图片像素的定位,该网络对图像中的每一个像素点进行分类,最后输出的是根据像素点的类别而分割好的图像。
原文链接:https://blog.youkuaiyun.com/qq_33924470/article/details/106891015
SegNet
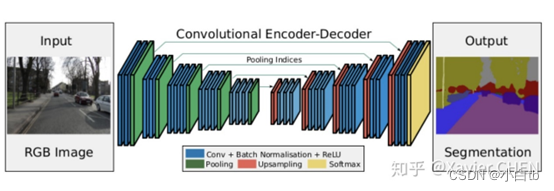
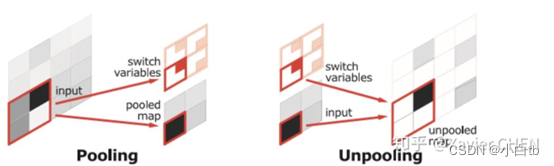
在结构上看,SegNet和U-net其实大同小异,都是编码-解码结果。区别在意,SegNet没有直接融合不同尺度的层的信息,为了解决为止信息丢失的问题,SegNet使用了带有坐标(index)的池化。如下图所示,在Max pooling时,选择最大像素的同时,记录下该像素在Feature map的位置(左图)。在反池化的时候,根据记录的坐标,把最大值复原到原来对应的位置,其他的位置补零(右图)。后面的卷积可以把0的元素给填上。这样一来,就解决了由于多次池化造成的位置信息的丢失。
deeplabv1-v3系列对比
Deeplabv1
DeepLabv1是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。在实验中发现DCNNs做语义分割时精准度不够的问题,根本原因是DCNNs的高级特征的平移不变性(即高层次特征映射)。DeepLab解决这一问题的方法是通过将DCNNs层的响应和完全连接的条件随机场(CRF)结合。同时模型创新性的将空洞卷积算法应用到DCNNs模型上。
这里先描述一下Deeplabv1 的DCNN是如何设计的:调整VGG16模型,转为一个可以有效提取特征的语义分割系统。具体来说,先将VGG16的FC层(如下图FC6、FC7、FC8)转为卷积层(这里是空洞卷积),模型变为全卷积的方式,也就是类似于FCN那样。但为了以得到更加稠密的特征,在最后的两个最大池化层不下采样(stride=1),再通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅。这里就不详细叙述了,参见FCN精华提炼,然后将空洞卷积作为解码器部分(即VGG16的全连接层被替换成的空洞卷积块)的卷积块。在得到上采样输出的初步结果后,为了使得输出结果更加精细、平滑,后面接上了条件随机场CRF。
原文链接:https://blog.youkuaiyun.com/weixin_43572595/article/details/110083302
Deeplabv2
相较于上一个版本,这个版本的主要改进在于:
使用ResNet101替代vgg16,做基础网络的改进,可以得到更好的准确性
提出atrous spatial pyramid pooling (ASPP即空洞卷进金字塔池化)来替代多尺度预测,可以大大增加感受野,感受野从普通卷积的kk增大到(k + (k - 1)(r - 1))(k + (k - 1)(r - 1))。其实就是将前面的最后一个池化层的输出以下图(b)的结构继续得到结果。
Deeplabv3
这个版本中依旧延续了v2的深层空洞卷积网络(2、级联形式的空洞卷积代入ResNet块)和空洞卷积空间金字塔(3、并行化策略:重新设计ASPP,加入了Batch Normalization)两种策略,分别做了测试。但是去掉了后面的CRF后处理块。
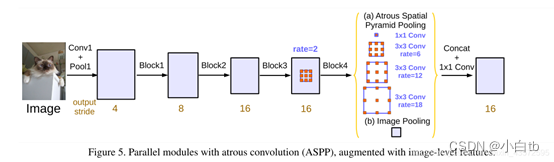
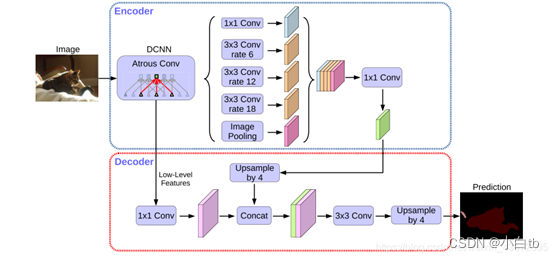
Deeplabv3+:
将ResNet改为了Xception块,因为Xception各方面表现更好。
将网络的整体结构改为了encode-decode的编解码结构,使得特征得到充分利用,提升输出精细程度
同时保留了ASPP模块
原文链接:http://t.csdn.cn/JvLO0
总结:
1.全卷积网络,滑窗的形式
2.感受野的控制: Pooling+Upsample => Atrous convolution
3.不同Level的特征融合: 统一尺寸之后Add / Concat+Conv, SPP, ASPP…
4.考虑相邻像素之间的关系:CRF
5.在条件允许的情况下,图像越大越好。
6.分割某一个特定的类别,可以考虑使用先验知识+ 对结果进行图像形态学处理
7.此外还有一些其他的研究思路:实时语义分割,视频语义分割
8.替换主干网络进行特征提取加速。

















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









