




 本文介绍了一种结合生成对抗网络(GAN)与强化学习(RL)的方法,用于从一系列图片中自动生成叙述性段落。该方法通过多模态判别器和语言风格判别器来提高生成文本的相关性和自然度。
本文介绍了一种结合生成对抗网络(GAN)与强化学习(RL)的方法,用于从一系列图片中自动生成叙述性段落。该方法通过多模态判别器和语言风格判别器来提高生成文本的相关性和自然度。
这是AAAI2018用GAN和reinforcement learning(RL)做Photo Stream Story Telling的文章。paper链接https://pdfs.semanticscholar.org/977b/eecdf0b5c3487d03738cff501c79770f0858.pdf,暂时还没有找到作何的主页和相关的code,文章题目Show, Reward and Tell: Automatic Generation of Narrative Paragraph from Photo Stream by Adversarial Training
个人瞎扯:看这篇文章的两个原因
- 这个task算是跨媒体任务中比较有意思的。
- 这篇paper同时利用了GAN和reinforcement learning(RL)
文章要做的事情(Photo Stream Story Telling):
输入:photo strean(several images) 输出:paragraph
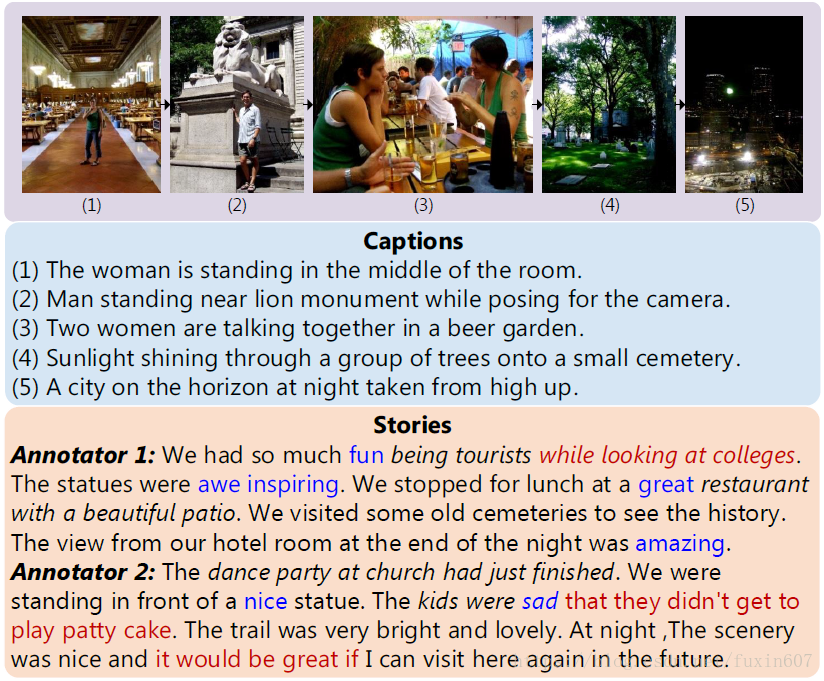
文章show出来的example如下图所示。
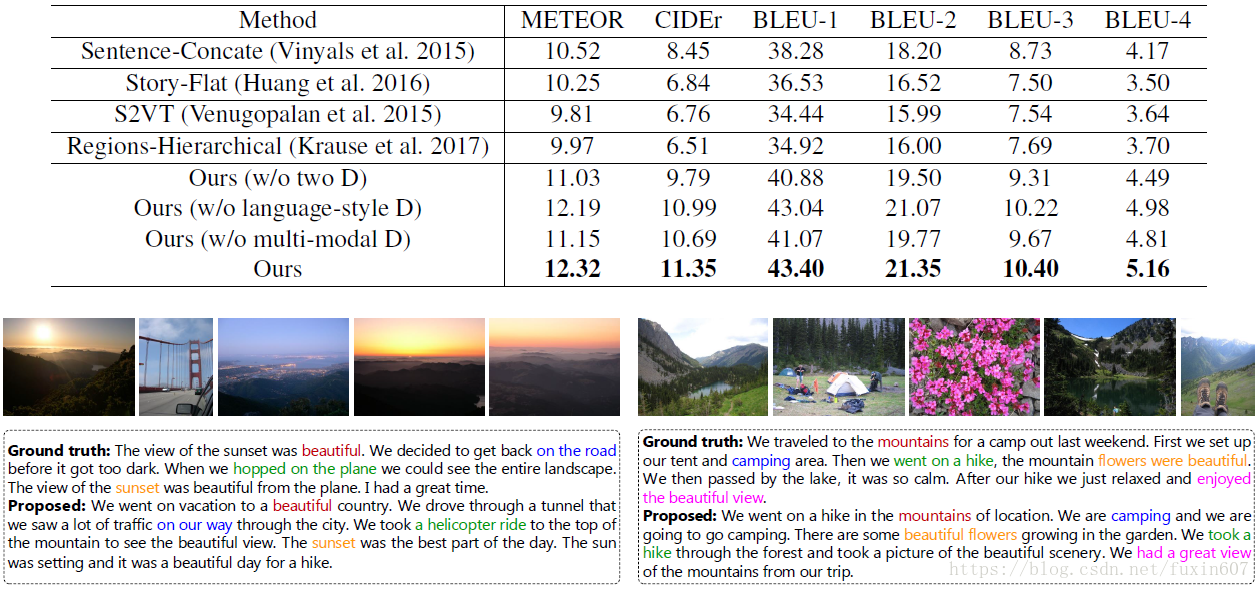
与state-of-the-art方法和ground-truth对比结果如下所示。
method
paper的framework如下所示。
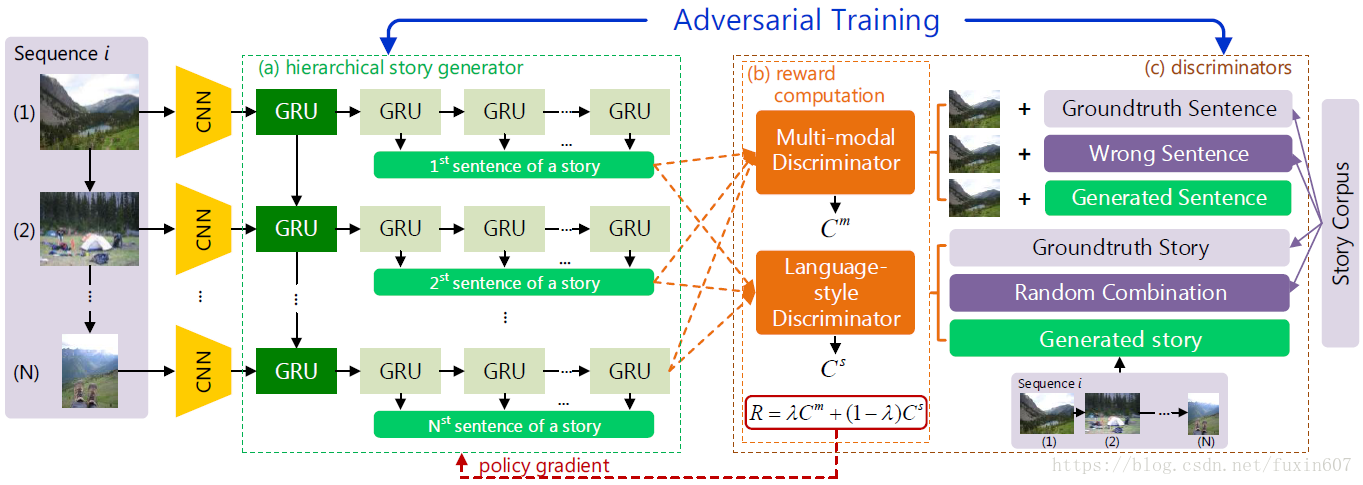
文章中的几个点:
Multi-modal Discriminator(sentence-level): generate relevance sentence of image。判断的内容为图像分别与成对,不成对和生成的sentence做concatenation(discriminate concatenation)。
Language-style Discriminator(paragraph-level): generate human-level story。判断的内容为ground truth stories (gt), random combinations of ground truth sentences (random) and the generated narrative paragraphs (generated)(discriminate paragraph)。
Reward Function: 对relevant sentence和human-level story做reward。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









