




 本文探讨了表单设计的重要性和原则,强调减少用户填写痛苦并保持一致性。内容涵盖表单问题的选取与内容组织,标签和输入框的设计,即时校验与帮助,以及动作设计,通过‘京东商城’注册表单为例进行实战解析。
本文探讨了表单设计的重要性和原则,强调减少用户填写痛苦并保持一致性。内容涵盖表单问题的选取与内容组织,标签和输入框的设计,即时校验与帮助,以及动作设计,通过‘京东商城’注册表单为例进行实战解析。
一、表单设计的影响与原则
1、表单的产生
- 由内而外,从数据库映射成表单
- 由外而内,从用户能做什么推出表单
2、表单的重要性
- 电子商务(携程订票、淘宝购物、产品信息发布)
- 社交活动(社区、论坛)
- 职业生涯(前程无忧、智联招聘)等等
3、表单设计的影响
- 因为迷茫而放弃表单注册
- 因为填写信息繁琐而放弃创建简历
- 因为提交订单过程麻烦而放弃购物
- 因为填写表单困难而放弃发布产品信息
4、表单设计的原则
- 尽量减少用户填写表单的痛苦
- 说明填写完成路径
- 表单的设计要考虑情景
- 确保沟通一致
二、表单问题的设计与内容组织
1、表单问题的选取
- 保留,和用户达成一致,用户渴望给出答案
- 删减,问题对用户没有意义,对表单自身没有意义
- 延迟,有些问题不需要马上获得答案
- 解释,涉及到用户隐私问题,给予解释
2、表单内容组织
- 表单内容划分成有意义的组
- 向导型表单(适合较长、较复杂的表单)
三、表单的标签和输入框
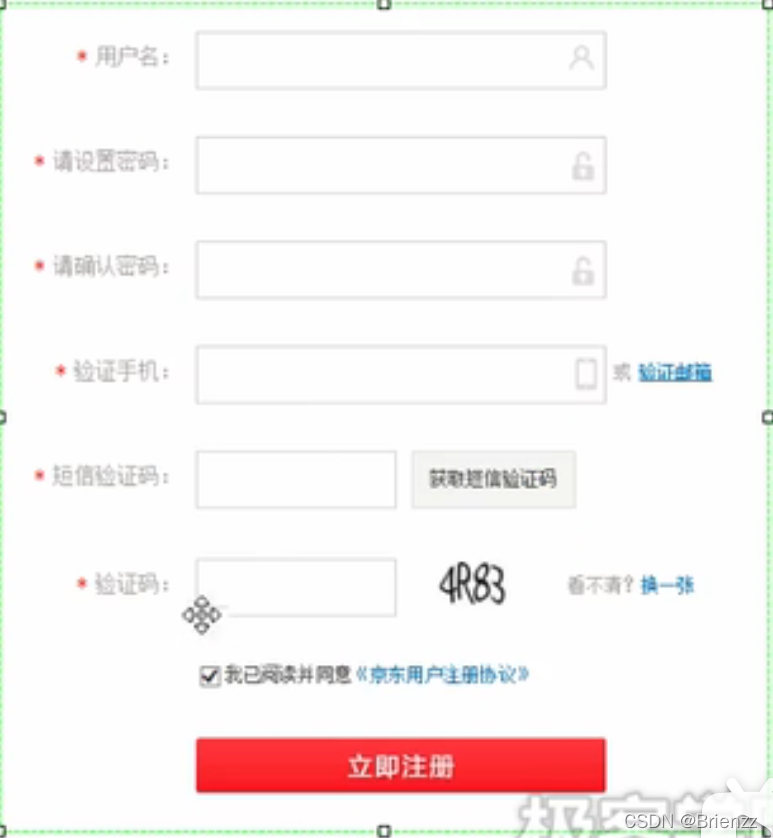
四、实例:“京东商城”注册表单设计
五、表单的输入
1、表单的输入
- 去除无用的输入
- 设置默认的输入
- 基于选择的输入
- 水平或者垂直选项的输入
六、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5777
5777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









