



Langchain1.0实战:OCR 多模态PDF解析系统
本文将带你完整了解:
- 多模态 OCR 的核心诉求与落地权衡
- 热门开源 OCR 项目横向对比
- 实战:基于 Langchain 1.0 的 多模态PDF解析系统,其中集成了 PaddleOCR、MinerU、DeepSeek-OCR 三大热门 OCR 项目(找 小助理 免费领取完整项目源码)
演示视频:
多模态文档解析演示视频
一、多模态 OCR 的核心诉求与落地权衡
目前企业在做的大部分业务场景都是以正确识别不同文档类型的内容为前提,比如处理 图片/PDF 等 格式的发票、合同、财报、收据,通过 OCR 把这些文档转换为结构化的数据,为后续的存储、检索、分析做支撑。
就目前的发展来看,单纯“图像 → 文本”的简单转换远远不够的,而是要做到同时理解 视觉(图像)、语言(文本)、版面结构(布局)、场景环境(上下文) 等多模态信息。
对于复杂的 PDF 或图像文档,系统需要能同时识别文字、图像、表格、公式,甚至页面的逻辑结构与阅读顺序。正因如此,企业在落地多模态 OCR 项目时,往往需要在“性能”“生态”“资源开销”“易集成性”等维度之间做权衡。
二、热门开源 OCR 项目对比
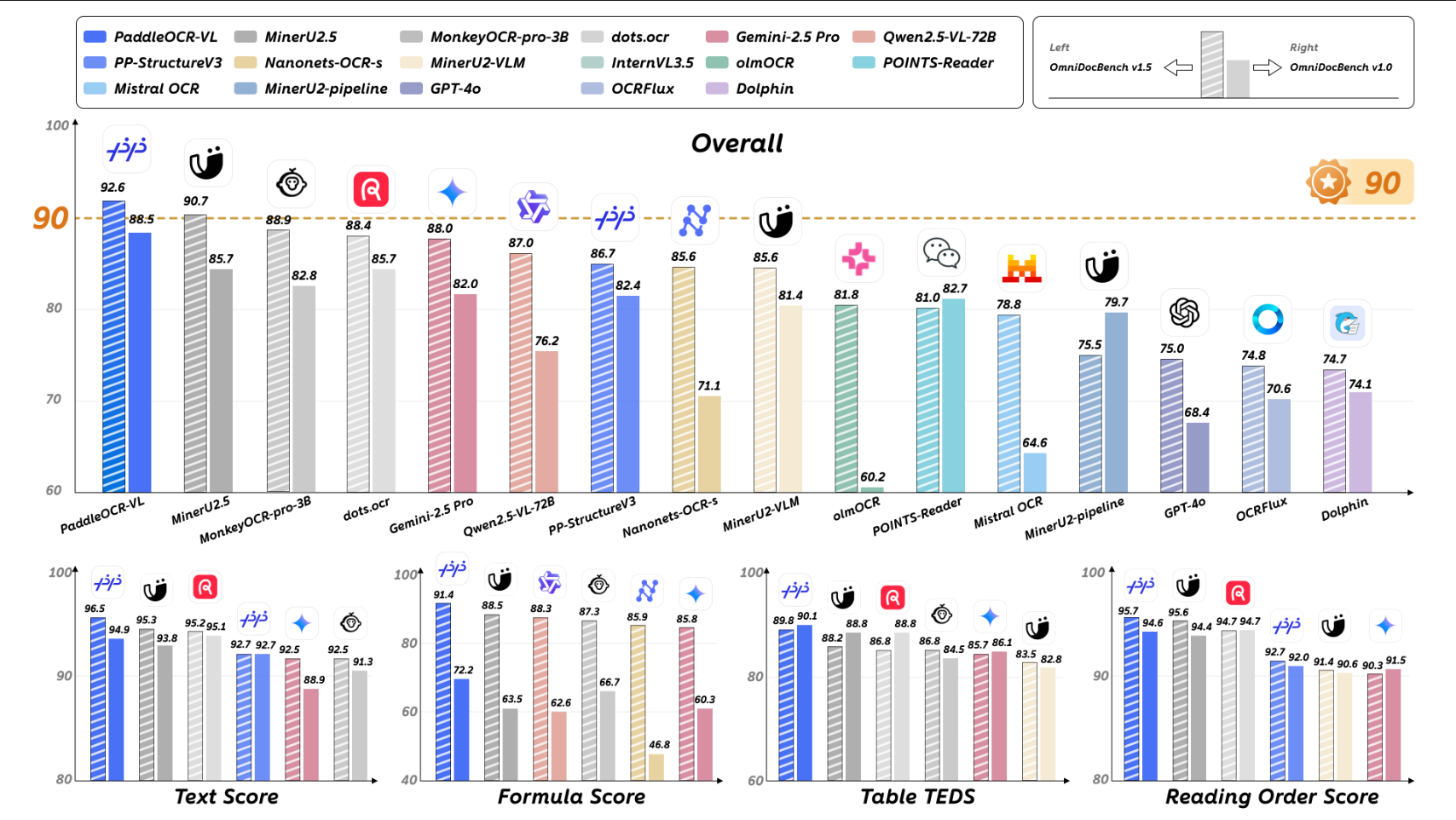
MinerU
MinerU:点击进入
MinerU 提供在线 Demo 。试用地址:https://opendatalab.com/OpenSourceTools/Extractor/PDF/
MinerU 由 OpenDataLab(上海人工智能实验室团队)发起,目标是将复杂 PDF 转换为可机读的结构化格式(Markdown / JSON)。其设计并非传统意义上的“OCR 识字”,而是“完整复现文档结构”。
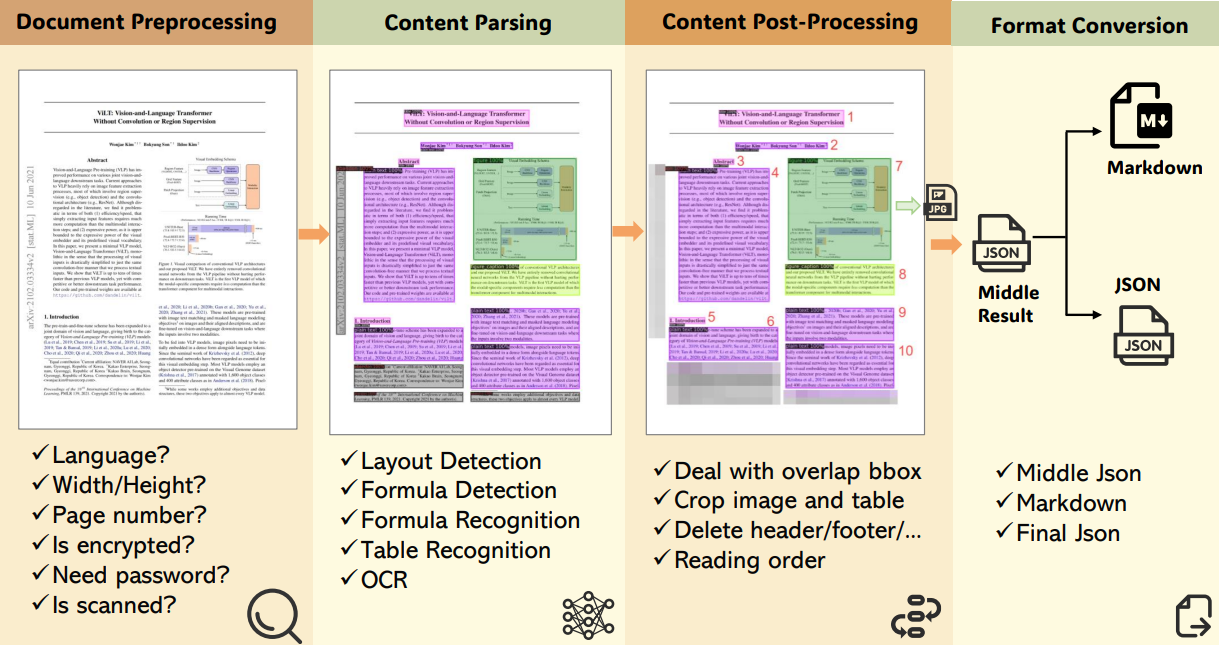
MinerU 的核心价值在于它提供了一条完整的处理管线:
- 文档预处理:检测语言、页面、扫描状态
- 内容解析:区分文本、表格、图像与公式(支持公式 LaTeX 输出)
- 版面还原:修复元素重叠,重建自然阅读顺序
- 结构化输出:统一导出 Markdown / JSON
MinerU 的主要工作流程分为以下几个阶段:
- 输入:接收
PDF格式文本,可以是简单的纯文本,也可以是包含双列文本、公式、表格或图等多模态PDF文件; - 文档预处理(Document Preprocessing):检查语言、页面大小、文件是否被扫描以及加密状态;
- 内容解析(Content Parsing):
- 局分析:区分文本、表格和图像。
- 公式检测和识别:识别公式类型(内联、显示或忽略)并将其转换为
LaTeX格式。 - 表格识别:以
HTML/LaTeX格式输出表格。 - OCR:对扫描的
PDF执行文本识别。
- 内容后处理(Content Post-processing):修复文档解析后可能出现的问题。比如解决文本、图像、表格和公式块之间的重叠,并根据人类阅读模式重新排序内容,确保最终输出遵循自然的阅读顺序。
- 格式转换(Format Conversion):以
Markdown或JSON格式生成输出。 - 输出(Output):高质量、结构良好的解析文档。
MinerU 实现了三个不同的处理后端,每个后端针对不同的用例和硬件配置进行了优化。其中Pipeline后端是默认的,也是最通用的后端
MinerU 后端默认模型配置
| 后端类型 | 默认模型 | 适用场景 | 资源需求 |
|---|---|---|---|
| VLM-Transformer | MinerU2.5-2509-1.2B | 高精度解析 | 中等 GPU |
| VLM-SGLang | MinerU2.5-2509-1.2B | 高速推理 | 高端 GPU |
| Pipeline | PDF-Extract-Kit-1.0 | 轻量部署 | CPU 友好 |
在部署和使用方面,MinerU 支持Linux、Windows、MacOS 多平台部署的本地部署,并且其中用的到布局识别模型、OCR 模型、公式识别模型、表格识别模型都是开源的,我们可以直接下载到本地进行使用。而且,MinerU 项目是完全支持华为昇腾系列芯片的,可适用性非常广。
PaddleOCR-VL
PaddleOCR:点击进入
PaddleOCR 由百度团队基于 PaddlePaddle 框架构建,是生态最成熟的 OCR 工具箱之一。
其最新模块 PaddleOCR-VL 引入了视觉-语言模型(VLM)架构,能够在解析过程中综合考虑图像与文本两种信息。

在解析多模态数据方面,PaddleOCR将这项工作分为个阶段:
- 首先检测并排序布局元素。
- 使用紧凑的视觉语言模型精确识别每个元素。
第一阶段是执行布局分析(PP-DocLayoutV2),此部分标识文本块、表格、公式和图表。它使用:
- RT-DETR 用于物体检测(基本上是边界框 + 类标签)。
- 指针网络 (6 个转换器层)可确定元素的读取顺序 ,从上到下、从左到右等。
最终输出统一模式的图片标注数据,如下图所示:

第二阶段则是元素识别(PaddleOCR-VL-0.9B),这就是视觉语言模型发挥作用的地方。它使用:
- NaViT 风格编码器 (来自 Keye-VL),可处理动态图像分辨率。无平铺,无拉伸。
- 一个简单的 2 层 MLP, 用于将视觉特征与语言空间对齐。
- ERNIE-4.5–0.3B 作为语言模型,该模型规模虽小但速度很快,并且采用 3D-RoPE 进行位置编码
最终模型输出结构化 Markdown 或 JSON 格式的文件用于后续的处理。
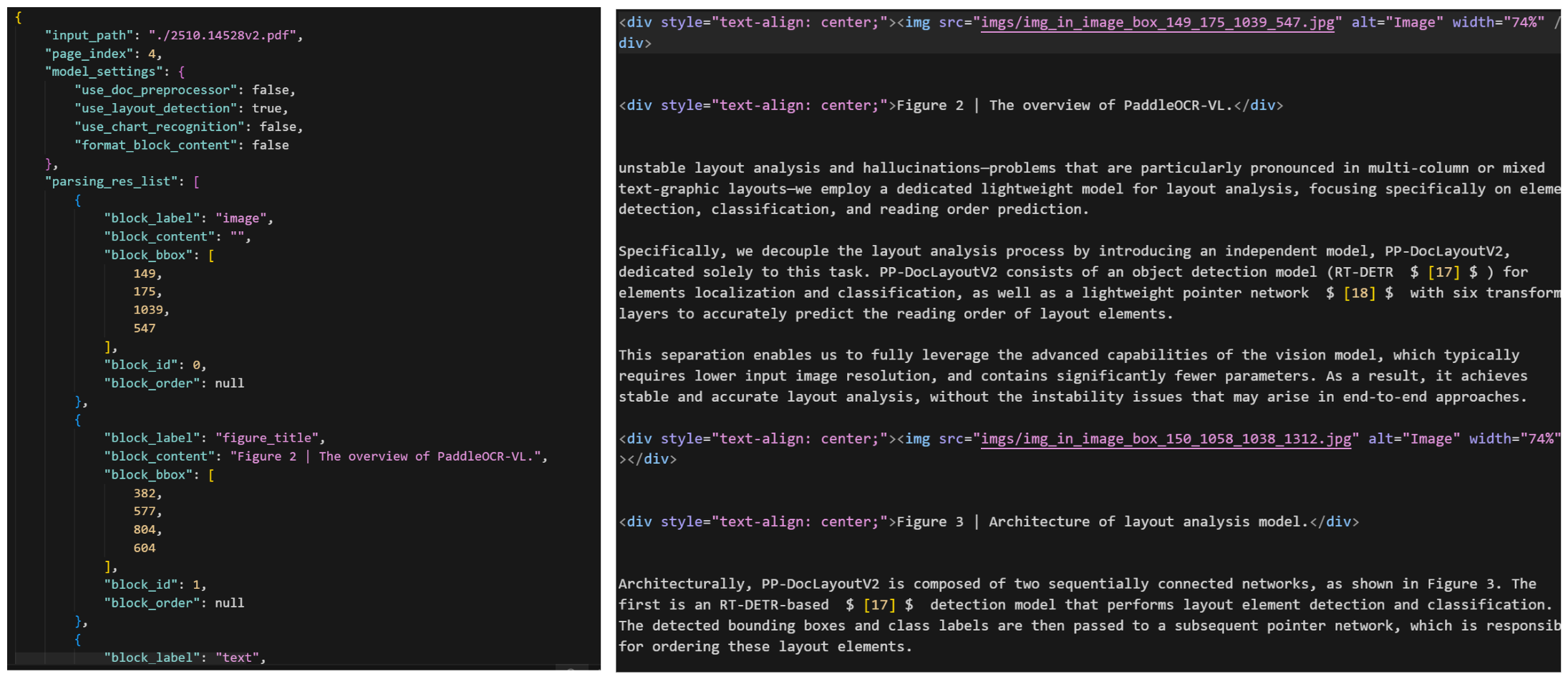
这种“布局 + 识别”分离的架构使得 PaddleOCR-VL 比通常的一体化系统更快、更稳定。
另外在多语言支持方面,PaddleOCR 已覆盖 100+ 语种,是国际化项目的常用选择。
DeepSeek-OCR
DeepSeek-OCR:点击进入
DeepSeek 团队在 2025 年推出的 DeepSeek-OCR 聚焦于“以最小资源消耗实现高精度识别”。
模型仅需 7GB 显存即可运行,支持表格、公式、图像文字及图表语义识别。
DeepSeek-OCR 提供基于 Transformers 与 vLLM 的启动示例,可轻松嵌入现有解析管线中。
其提出”光学上下文压缩“技术,达到用远少于传统模型的“视觉 tokens”达到类似或更好的表现。
dots.ocr
dots.ocr:点击进入
由 rednote-hilab 开发的 dots.ocr 采用了单一 VLM 模型(约 1.7B 参数)完成布局检测 + 内容识别 + 阅读顺序排序三合一任务。
用户可通过 prompt 控制模型行为,例如输出版式元素的类别、边界框与文本内容。

这种“Prompt + VLM”模式使系统在多语言、多版式文档中具有极强的通用性。
不过在极复杂表格(跨页、合并单元格)或特殊排版中仍存在一定局限。
综合对比
从企业落地视角来看,这四个项目并无绝对的“优劣之分”,选型应该根据实际需求与资源条件进行评估
| 项目 | 核心特点 |
|---|---|
| MinerU | 多模块全流程解析 |
| PaddleOCR-VL | 双阶段视觉语言模型 |
| DeepSeek-OCR | 光学上下文压缩技术 |
| dots.ocr | Prompt 驱动统一模型 |
三、实战:基于 Langchain 1.0 的 多模态PDF解析系统
完整项目代码添加 小助理 免费领取,还有更多Agent、数据分析等课程,等你来学
项目基于 Langchain 1.0 框架,集成了 PaddleOCR、MinerU、DeepSeek-OCR 三大热门 OCR 项目
项目演示视频:
MinerU 项目概览与 vLLM 服务接口
本文是在Linux系统下安装MinerU项目并进行文档解析实战。
其他操作系统可以参考如下链接进行自行实践:Windows 10/11 + GPU ,Docker 部署 ,
1 MinerU 源码安装
CUDA 版本检查
在 Linux 系统下,通过 nvidia-smi 命令查看 CUDA 版本
CUDA Version 显示的版本号必须 >= 12.1,如显示的版本号小于12.1,请自行升级CUDA 版本。
下载MinerU源码文件
截止目前最新的MinerU项目源码版本为是:2.6.4-released,但当前版本的源码在使用MCP Server时存在一些Bug,所以我们针对源码做了一些修改。因此大家一定要找 小助理 免费领取网盘中的源码文件进行部署和使用。下载后上传至服务器中,解压文件,并进入解压后的文件夹
# 解压
unzip MinurU-master.zip
创建并激活虚拟环境
cd MinerU-master
conda create --name mineru_2.5 python==3.11 -y
conda activate mineru_2.5
安装 MinerU 项目依赖
pip install -e .[all] -i https://mirrors.aliyun.com/pypi/simple
检查 MinerU 安装
pip show mineru
输出版本号则说明安装成功
下载 MinerU 中用到的模型文件
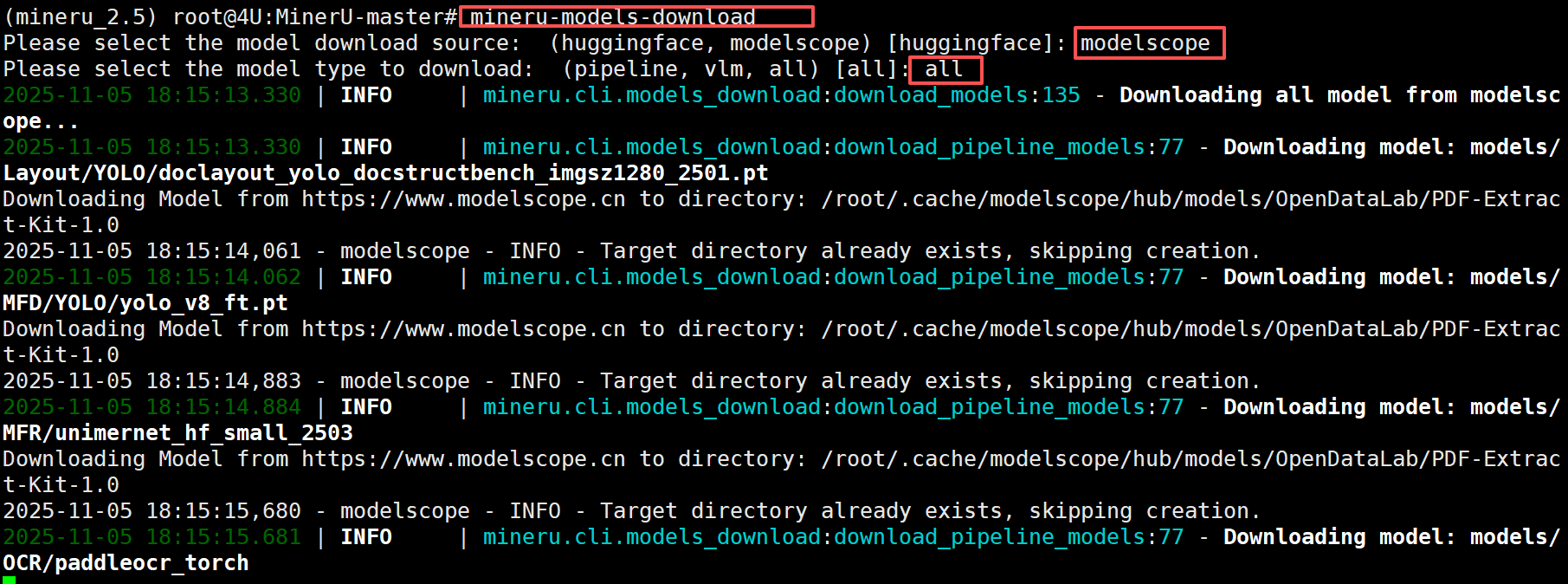
运行一键下载所有模型文件的脚本
mineru-models-download
执行该命令需要我们根据自己的需求灵活的选择要下载到本地的模型。其中modelscope 和 huggingface 是两个不同的模型下载源,我们只需要选择其中一个即可。pipeline指的是用于文档解析的一系列模型,而vlm指的是用于视觉语言模型的模型,即MinerU2.0-2505-0.9B 模型。如果是all,则会全部下载。
等待下载完成后,所有模型文件的默认存储路径是:
/root/.cache/modelscope/hub/models/OpenDataLab
2. MinerU 启动vLLM API 推理服务
接下来新打开一个终端,启动mineru-api 服务:
export MINERU_MODEL_SOURCE=local # 注意:这里需要将模型源设置为本地
export CUDA_VISIBLE_DEVICES=3 # 使用 哪一块GPU
mineru-api --host 192.168.110.131 --port 50000 # 这里换为你的IP
3. MinerU vLLM API服务连接测试及项目实现
下面我们通过一个完整的代码示例,来演示如何调用 OCR 服务。
#!/usr/bin/env python3
"""
测试 MinerU API 的不同 backend
通过 50000 端口调用,传递不同的 backend 参数来使用不同的模型
"""
import requests
import sys
from pathlib import Path
def test_mineru_api(pdf_path: str, backend: str = "pipeline"):
"""
测试 MinerU API
Args:
pdf_path: PDF 文件路径
backend: 后端类型,可选值:
- "pipeline" (默认,使用本地 PyTorch)
- "vlm-vllm-async-engine" (使用 vLLM 加速)
"""
api_url = "http://192.168.130.4:50000/file_parse"
print(f"\n{'='*60}")
print(f"测试 MinerU API with backend: {backend}")
print(f"{'='*60}")
print(f"API URL: {api_url}")
print(f"PDF 文件: {pdf_path}")
print(f"Backend: {backend}")
print()
# 检查文件是否存在
if not Path(pdf_path).exists():
print(f"错误: 文件不存在 - {pdf_path}")
return None
try:
# 打开文件并发送请求
with open(pdf_path, 'rb') as f:
files = [('files', (Path(pdf_path).name, f, 'application/pdf'))]
data = {
'backend': backend,
'parse_method': 'auto',
'lang_list': 'ch',
'return_md': 'true',
'return_middle_json': 'false',
'return_model_output': 'false',
'return_content_list': 'false',
'start_page_id': '0',
'end_page_id': '1', # 只处理前2页,快速测试
}
print("发送请求...")
response = requests.post(
api_url,
files=files,
data=data,
timeout=300
)
# 检查响应
if response.status_code != 200:
print(f"请求失败: HTTP {response.status_code}")
print(f"响应: {response.text[:500]}")
return None
# 解析 JSON 响应
result = response.json()
# 提取信息
backend_used = result.get('backend', 'unknown')
version = result.get('version', 'unknown')
results = result.get('results', {})
print(f"请求成功!")
print(f" 使用的 backend: {backend_used}")
print(f" 版本: {version}")
print(f" 结果数量: {len(results)}")
# 提取 markdown 内容
if results:
file_key = list(results.keys())[0]
md_content = results[file_key].get('md_content', '')
print(f"\nMarkdown 内容预览 (前500字符):")
print("-" * 60)
print(md_content[:500])
print("-" * 60)
# 保存 markdown 到文件
output_file = f"output_{backend}.md"
with open(output_file, 'w', encoding='utf-8') as f:
f.write(md_content)
print(f"\n完整 Markdown 已保存到: {output_file}")
return md_content
else:
print("未找到结果")
return None
except Exception as e:
print(f"测试失败: {e}")
import traceback
traceback.print_exc()
return None
def main():
# 默认测试文件
pdf_path = "./2507.05595v1.pdf"
print(f"\n开始测试 MinerU API 的不同 backend")
print(f"测试文件: {pdf_path}\n")
# 测试 1: pipeline backend (本地 PyTorch)
print("\n" + "="*60)
print("测试 1: pipeline backend (本地 PyTorch)")
print("="*60)
result_pipeline = test_mineru_api(pdf_path, backend="pipeline")
# 测试 2: vLLM backend (vLLM 加速)
print("\n" + "="*60)
print("测试 2: vlm-vllm-async-engine backend (vLLM 加速)")
print("="*60)
result_vllm = test_mineru_api(pdf_path, backend="vlm-vllm-async-engine")
# 总结
print("\n" + "="*60)
print("测试总结")
print("="*60)
print(f"Pipeline backend: {'成功' if result_pipeline else '失败'}")
print(f"vLLM backend: {'成功' if result_vllm else '失败'}")
if result_pipeline and result_vllm:
print("\n所有测试通过! MinerU 可以通过 backend 参数切换不同模型")
print("\n💡 提示:")
print(" - pipeline: 使用本地 PyTorch,适合调试")
print(" - vlm-vllm-async-engine: 使用 vLLM 加速,速度更快")
if __name__ == "__main__":
main()
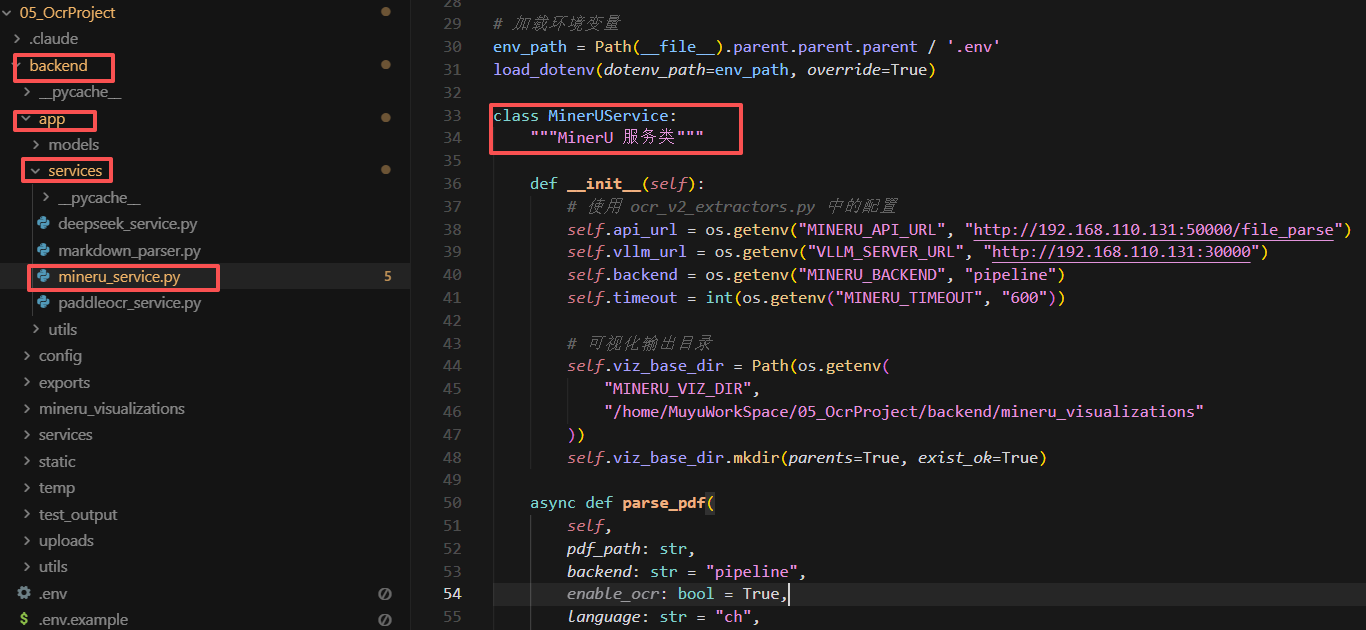
项目中 MinerU 的核心代码逻辑:
完整项目代码添加 小助理 免费领取,还有更多Agent、数据分析课程,等你来学
PaddleOCR-VL 部署与 vLLM 服务启动
1. 安装 PaddleOCR-VL 并启动 vLLM 服务
创建并激活虚拟环境
conda create -n ppocr-vllm python=3.11 -y
conda activate ppocr-vllm
安装 PaddleOCR 工具框架
这里安装 PaddlePaddle 3.2.0 版本。执行如下命令:
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
接下来要重点关注的是:PaddleOCR-VL 使用 safetensors 格式存储模型权重,需要额外安装,同时需要安装指定版本的,执行如下命令
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
通过 modelscope 下载PaddleOCR-VL模型
pip install modelscope
新建一个 download_paddleocr_vl.py 文件,写入如下代码:
from modelscope import snapshot_download
# 下载完整模型(包含 PaddleOCR-VL-0.9B 和 PP-DocLayoutV2)
model_dir = snapshot_download('PaddlePaddle/PaddleOCR-VL', local_dir='.')
运行新建的 download_paddleocr_vl.py 文件,执行如下命令:
python download_paddleocr_vl.py
下载完成后的模型目录结构如下所示:

安装依赖包
python -m pip install "paddleocr[doc-parser]"
然后,使用 PaddleOCR CLI 安装 vLLM 的推理加速服务依赖:
paddleocr install_genai_server_deps vllm
安装 flash-atten 编译包:
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu12torch2.8cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
启动vLLM 服务器服务器了。如下代码所示:
paddlex_genai_server \
--model_name PaddleOCR-VL-0.9B \
--backend vllm \
--host 0.0.0.0 \
--port 8118
vLLM 服务启动后,保持这个终端窗口运行,不要关闭。同时打开一个新的终端,使用paddlex连接启动的paddleocr-vl服务,首先进行初始化服务配置:
paddlex --install serving
然后生成 .yaml 配置文件:
paddlex --get_pipeline_config PaddleOCR-VL
找到 genai_config 配置项,修改为如下所示:
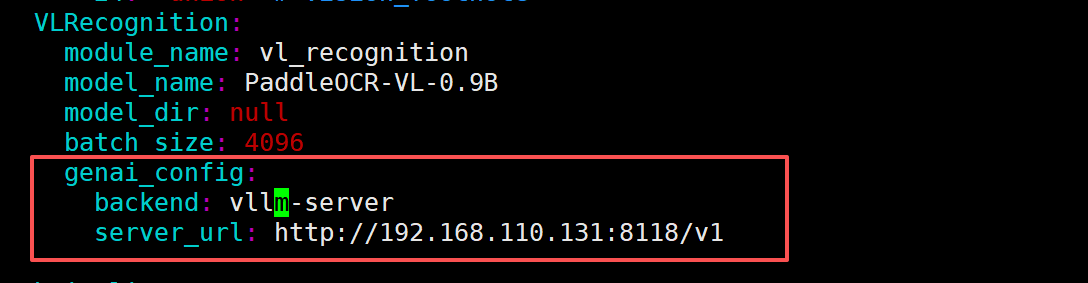
最后,启动 PaddleOCR API 服务:
paddlex --serve --pipeline PaddleOCR-VL.yaml --port 10800 --host 192.168.110.131 --paddle_model_dir /home/MuyuWorkSpace/02_OcrRag
2. PaddleOCR vLLM API服务连接测试及项目实现
下面我们通过一个完整的代码示例,来演示如何调用 OCR 服务。
import base64
import json
import requests
import os
# === 1. 服务端地址 ===
SERVER_URL = "http://192.168.130.4:10800/layout-parsing"
# === 2. 待处理文件路径 ===
input_path = "./course.pdf" # 也可以是 test.png
output_md = "result.md"
# === 3. 读取文件并转为 Base64 ===
with open(input_path, "rb") as f:
file_base64 = base64.b64encode(f.read()).decode("utf-8")
# === 4. 构造 JSON 请求体 ===
payload = {
"file": file_base64,
"fileType": 0 if input_path.lower().endswith(".pdf") else 1,
"prettifyMarkdown": True,
"visualize": False,
}
headers = {"Content-Type": "application/json"}
# === 5. 发送请求 ===
resp = requests.post(SERVER_URL, headers=headers, data=json.dumps(payload))
# === 6. 解析响应 ===
if resp.status_code == 200:
data = resp.json()
if data.get("errorCode") == 0:
# PDF 的结果在 layoutParsingResults 数组中
results = data["result"]["layoutParsingResults"]
md_text = ""
for i, page in enumerate(results, 1):
md_text += f"\n\n# Page {i}\n\n"
md_text += page["markdown"]["text"]
with open(output_md, "w", encoding="utf-8") as f:
f.write(md_text)
print(f"成功生成 Markdown:{output_md}")
else:
print(f"服务端错误:{data.get('errorMsg')}")
else:
print(f"HTTP 错误:{resp.status_code}")
print(resp.text)
项目中PaddleOCR 的核心代码逻辑:
DeepSeek-OCR 部署与 vLLM 服务启动
1. DeepSeek-OCR模型下载
创建并激活虚拟环境
conda create --name deepseek-ocr-vllm python==3.10
conda activate deepseek-ocr-vllm
接下来,在ModelScope 平台下载 DeepSeek-OCR 模型文件。
pip install modelscope
新建 download_deepseek_ocr.py 文件,内容如下:
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-OCR',local_dir='.')
接下来执行如下代码进行模型权重安装:
python download_deepseek_ocr.py
2. Deepseek-OCR vLLM 项目文件
DeepSeek-OCR通过 vLLM 平台启动,我们是借助DeepSeek-OCR官方提供的项目代码,并做了一些优化和调整,其官方源码下载地址:https://github.com/deepseek-ai/DeepSeek-OCR/tree/main/DeepSeek-OCR-master/DeepSeek-OCR-vllm
找 小助理 免费领取网盘中的源码文件
其中deepseek_ocr.py 和 flash_attn-2.7.3+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl 使我们给大家提供的两个核心文件,一个用于封装 DeepSeek OCR API 接口,另一个则是离线安装的 fla_ttn 的离线安装包。
pip install flash_attn-2.7.3+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
安装 vLLM 运行 DeepSeek-OCR的依赖包:
pip install -r requirements.txt
启动命令如下:
python ocr_client.py --model-path /home/data/nongwa/workspace/model/OCR/DeepSeek-OCR --gpu-id 3 --port 8797 --host 192.168.110.131
3. DeepSeek-OCR API 连接测试及项目实现
下面我们通过一个完整的代码示例,来演示如何调用 OCR 服务。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
测试 DeepSeek-OCR API
直接调用 API 并保存返回的 markdown 和图像数据
"""
import requests
import json
import sys
from pathlib import Path
def test_deepseek_ocr(pdf_path: str, output_dir: str = "./test_output"):
"""
测试 DeepSeek-OCR API
Args:
pdf_path: PDF 文件路径
output_dir: 输出目录
"""
# API 配置
api_url = "http://192.168.130.4:8797/ocr"
# 确保输出目录存在
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
print(f"测试文件: {pdf_path}")
print(f"API 地址: {api_url}")
print(f"输出目录: {output_dir}")
print("-" * 60)
# 读取 PDF 文件
try:
with open(pdf_path, 'rb') as f:
files = {'file': (Path(pdf_path).name, f, 'application/pdf')}
# API 参数
data = {
'enable_description': 'false', # 是否生成图片描述
}
print("发送请求到 DeepSeek API...")
# 发送请求
response = requests.post(
api_url,
files=files,
data=data,
timeout=300
)
if response.status_code != 200:
print(f"API 返回错误: {response.status_code}")
print(f"错误信息: {response.text[:500]}")
return False
# 解析响应
result = response.json()
print(f"API 响应成功")
print(f"响应包含的字段: {list(result.keys())}")
print("-" * 60)
# 提取数据
markdown_content = result.get("markdown", "")
page_count = result.get("page_count", 0)
images_data = result.get("images", {})
print(f"Markdown 长度: {len(markdown_content)} 字符")
print(f"页数: {page_count}")
print(f"图像数量: {len(images_data)}")
if images_data:
print(f"图像列表:")
for img_key in list(images_data.keys())[:10]:
img_size = len(images_data[img_key])
print(f" - {img_key}: {img_size} 字符 (base64)")
print("-" * 60)
# 保存 Markdown
md_file = output_path / f"{Path(pdf_path).stem}_deepseek.md"
with open(md_file, 'w', encoding='utf-8') as f:
f.write(markdown_content)
print(f"Markdown 已保存: {md_file}")
# 保存完整响应
json_file = output_path / f"{Path(pdf_path).stem}_response.json"
with open(json_file, 'w', encoding='utf-8') as f:
# 为了避免文件过大,只保存图像的部分信息
simplified_result = {
"markdown": markdown_content,
"page_count": page_count,
"images_count": len(images_data),
"image_keys": list(images_data.keys())
}
json.dump(simplified_result, f, ensure_ascii=False, indent=2)
print(f"响应摘要已保存: {json_file}")
# 保存图像数据(可选,如果需要)
if images_data:
images_file = output_path / f"{Path(pdf_path).stem}_images.json"
with open(images_file, 'w', encoding='utf-8') as f:
json.dump(images_data, f, ensure_ascii=False, indent=2)
print(f"图像数据已保存: {images_file}")
# 统计信息
print("-" * 60)
print("统计信息:")
# 统计表格数量
import re
table_count = len(re.findall(r'<table>', markdown_content, re.IGNORECASE))
print(f" - HTML 表格: {table_count} 个")
# 统计图片引用
img_ref_count = len(re.findall(r'!\[.*?\]\(.*?\)', markdown_content))
print(f" - Markdown 图片引用: {img_ref_count} 个")
# 统计行数
line_count = len(markdown_content.split('\n'))
print(f" - Markdown 行数: {line_count} 行")
print("-" * 60)
print("测试完成!")
return True
except FileNotFoundError:
print(f"文件不存在: {pdf_path}")
return False
except requests.exceptions.Timeout:
print(f"请求超时")
return False
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
return False
def main():
"""主函数"""
success = test_deepseek_ocr(
pdf_path='./course.pdf',
output_dir='./')
if __name__ == "__main__":
main()
项目中DeepSeek-OCR 的核心代码逻辑:
OCR 多模态解析系统
后端服务启动
需要依次执行如下操作:
配置环境变量 (.env 文件)
# Server Configuration
PORT=8000
HOST=0.0.0.0
DEBUG=True
# MinerU Configuration
MINERU_API_URL=http://192.168.110.131:50000/file_parse
VLLM_SERVER_URL=http://192.168.110.131:40000
MINERU_BACKEND=vlm-vllm-async-engine
MINERU_TIMEOUT=600
MINERU_VIZ_DIR=/home/MuyuWorkSpace/05_OcrProject/backend/mineru_visualizations
# DeepSeek OCR Configuration
DEEPSEEK_OCR_API_URL=http://192.168.110.131:8797/ocr
# PaddleOCR Configuration
PADDLEOCR_API_URL=http://192.168.110.131:10800/layout-parsing
# File Upload Limits
MAX_FILE_SIZE=10485760
ALLOWED_FILE_TYPES=application/pdf,image/png,image/jpeg,image/jpg,image/webp
# CORS Settings
ALLOWED_ORIGINS=http://localhost:3000,http://localhost:5173
启动后端服务
cd backend
# 创建并激活虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt
# 启动服务
python main.py
其中:
配置说明
| 配置项 | 说明 |
|---|---|
MINERU_BACKEND | pipeline: 使用本地 PyTorchvlm-vllm-async-engine: 使用 vLLM 加速 |
VLLM_SERVER_URL | vLLM 服务器地址(仅在使用 vLLM 时需要) |
MINERU_API_URL | MinerU API 服务地址 |
前端服务启动
需要依次执行如下操作:
# 1. 进入前端目录
cd frontend
# 2. 安装依赖
npm install
# 3. 启动开发服务器
npm run dev
启动成功后,即可通过http://localhost:3000访问应用。


















 2364
2364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









