



背景
在跑一些 数据处理,模型评测中单机单卡效率太低,需要用到多级多卡来实现高效工作,故整理使用的多级多卡内容
功能
字段:
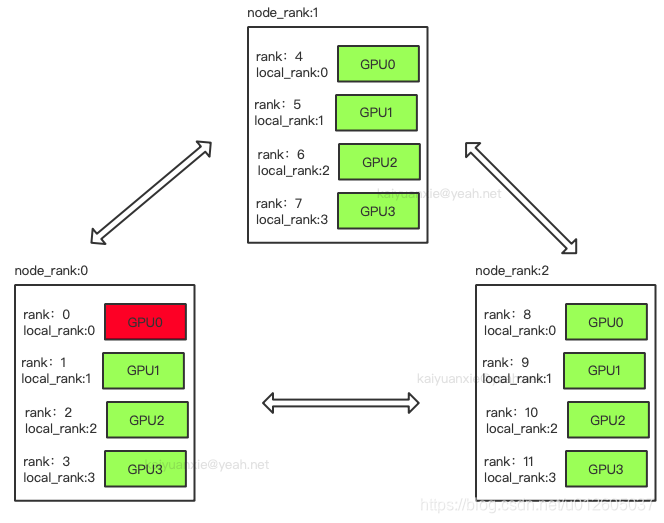
- rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
- node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
nnodes、node_rank与nproc_per_node: nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
word_size : 全局(一个分布式任务)中,rank的数量。
图中:一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都一个对应的node_rank。
# run.sh
# 单机多卡
python -m torch.distributed.run --nproc_per_node=$GPUS --master_port=$PORT \
tools/test.py $CONFIG $CHECKPOINT --launcher pytorch
# 多级多卡
python -m torch.distributed.launch \
--nnodes $MLP_WORKER_NUM \
--nproc_per_node=${MLP_WORKER_GPU} \
--node_rank=${MLP_ROLE_INDEX} \
--master_addr=${MLP_WORKER_0_HOST} \
--master_port=${MLP_WORKER_0_PORT} \
dist_test/test.py --launcher torch
# test.py
import argparse
def arg_parse():
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default="-1")
parser.add_argument(
"--launcher",
type=str,
choices=["torch", "mpi"],
default=None,
help="job launcher for multi machines",
)
return parser.parse_args()
if __name__ == "__main__":
args = arg_parse() # 主要需要local_rank 实现多卡问题
dist.init_process_group("nccl")
local_rank = args.local_rank
torch.cuda.set_device(int(local_rank))
main()
dist.destroy_process_group()


















 3597
3597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











