




语义分割的那些loss(甚至还有ssim)
今天我们看下关于语义分割的常规 l o s s loss loss设计,其中还有多个 l o s s loss loss联合一起用的,其中就如 B A S N e t BASNet BASNet这种显著性检测的工作,我们也分析了它的 l o s s loss loss设计。希望各位做分割的,可以在 l o s s loss loss层面,有所启发~
交叉熵损失 Cross Entropy Loss Function
用于图像语义分割任务的最常用损失函数是像素级别的交叉熵损失,这种损失会逐个检查每个像素,将对每个像素类别的预测结果(概率分布向量)与我们的独热编码标签向量( o n e − h o t one-hot one−hot形式)进行比较。
每个像素对应的损失函数为
L = − ∑ c = 1 M y c l o g ( p c ) L = -\sum_{c=1}^{M}y_c log(p_c) L=−c=1∑Myclog(pc)
其中, M M M代表类别数, y c y_c yc是one-hot向量,元素只有 0 0 0 和 1 1 1 两种取值,至于 p c p_c pc表示预测样本属于 c c c 类别的概率。假设我们需要对每个像素的预测类别有5个,则预测的概率分布向量长度为5:
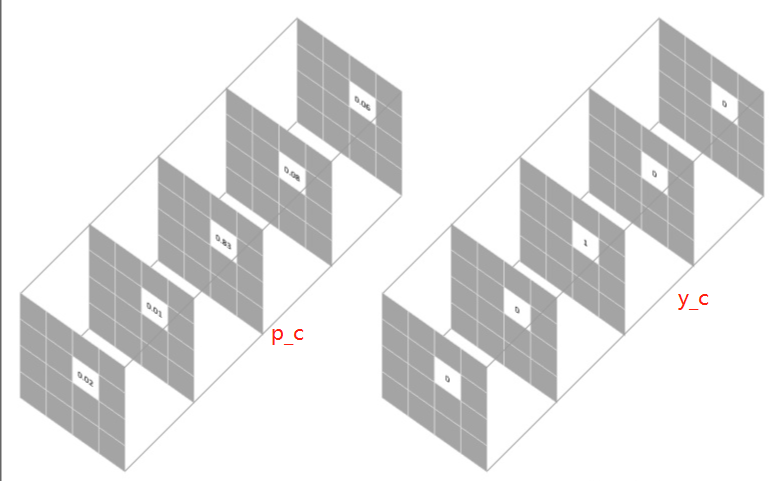
整个图像的损失就是对每个像素的损失求平均值。
特别注意的是,binary entropy loss 是针对类别只有两个的情况,简称 bce loss,损失函数公式为:
b c e l o s s = − y t r u e l o g ( y p r e d ) − ( 1 − y t r u e ) l o g ( 1 − y p r e d ) bce \ loss = -y_{true}log(y_{pred}) - (1-y_{true})log(1-y_{pred}) bce loss=−ytruelog(ypred)−(1−ytrue)log(1−ypred)
交叉熵 L o s s Loss Loss可以用在大多数语义分割场景中,但它有一个明显的缺点,那就是对于只用分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,即 y = 0 y=0 y=0 的数量远大于 y = 1 y=1 y=1 的数量,损失函数中 y = 0 y=0 y=0的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn as nn
import torch.nn.functional as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)
weighted loss
由于交叉熵损失会分别评估每个像素的类别预测,然后对所有像素的损失进行平均,因此我们实质上是在对图像中的每个像素进行平等地学习。如果多个类在图像中的分布不均衡,那么这可能导致训练过程由像素数量多的类所主导,即模型会主要学习数量多的类别样本的特征,并且学习出来的模型会更偏向将像素预测为该类别。
比如对于二分类,正负样本比例为1: 99,此时模型将所有样本都预测为负样本,那么准确率仍有99%这么高,但其实该模型没有任何使用价值。
为了平衡这个差距,就对正样本和负样本的损失赋予不同的权重,带权重的二分类损失函数公式如下:
l o s s = − p o s _ w e i g h t × y t r u e l o g ( y p r e d ) − ( 1 − y t r u e ) l o g ( 1 − y p r e d ) loss = -pos\_weight \times y_{true}log(y_{pred}) - (1-y_{true})log(1-y_{pred}) loss=−pos_weight×ytruelog(ypred)−(1−ytrue)log(1−ypred)
p o s _ w e i g h t = n u m _ n e g n u m _ p o s pos\_weight = \frac{num\_neg}{num\_pos} pos_weight=num_posnum_neg
要减少假阴性样本的数量,设置 p o s _ w e i g h t > 1 pos\_weight>1 pos_weight>1;要减少假阳性样本的数量,设置 p o s _ w e i g h t < 1 pos\_weight<1 pos_weight<1。
Focal loss
何凯明团队在RetinaNet论文中引入了Focal Loss来解决难易样本数量不平衡,我们来回顾一下。 我们知道,One-Stage的目标检测器通常会产生10k数量级的框,但只有极少数是正样本,正负样本数量非常不平衡。为了解决正负样本不均衡的问题,经常在交叉熵损失前加入一个参数 α \alpha α
C E = { − α l o g ( p ) i f y = 1 − ( 1 − α ) l o g ( 1 − p ) o t h e r CE = \left\{\begin{matrix} -\alpha log(p) & if \ y =1\\ -(1-\alpha)log(1-p) & other \end{matrix}\right. CE={
−αlog(p)−(1−α)log(1−p)if y=1other
虽然 α \alpha α 平衡了正负样本数量,但实际上,目标检测中大量的候选目标都是易分样本,这些样本会使损失很低,因此模型应关注那些难分样本,将高置信度的样本损失函数降低一些,就有了Focal loss
F L = { − α ( 1 − p ) γ l o g ( p ) i f y = 1 − ( 1 − α ) p γ l o g ( 1 − p ) i f y = 0 FL = \left\{\begin{matrix} -\alpha(1-p)^{\gamma} log(p) & if \ y =1\\ -(1-\alpha)p^{\gamma} log(1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2414
2414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











