




 本文介绍了如何下载Faster R-CNN模型并应用于FLIR数据集,包括数据集预处理(json转txt和txt转xml),网络调整步骤,以及训练和预测过程中遇到的问题,特别提到了Bicycles检测的挑战。
本文介绍了如何下载Faster R-CNN模型并应用于FLIR数据集,包括数据集预处理(json转txt和txt转xml),网络调整步骤,以及训练和预测过程中遇到的问题,特别提到了Bicycles检测的挑战。
1. Fater RCNN检测网络下载
网络学习视频
[源码地址]https://github.com/bubbliiiing/faster-rcnn-pytorch
2. FLIR 数据集准备
数据集的具体格式和内容请看
FLIR数据集介绍
在该数据集中提供的annotations文件为json,需要将其转换为xml,由于我之前使用yolov5网络训练,所以目前我使用的转换方法是从json转换到txt,目前我从txt进一步转换为xml
json转换为txt
可能有些朋友在转.txt文件中存在很多问题,我直接给大家将我转的传到了网盘,大家可以直接下载
链接:链接:https://pan.baidu.com/s/1H1YNqXWF_Ee632a8E3Tngg
提取码:1c4n
链接:https://pan.baidu.com/s/1QxbdV0zbzNcQFoo4oQ1fgg
提取码:smua
3. 网络调整

1.准备数据集
我们需要将生成的image图像和xml标签文件放置到VOCdevkit->VOC2007->Annotations和JPEGImages中。
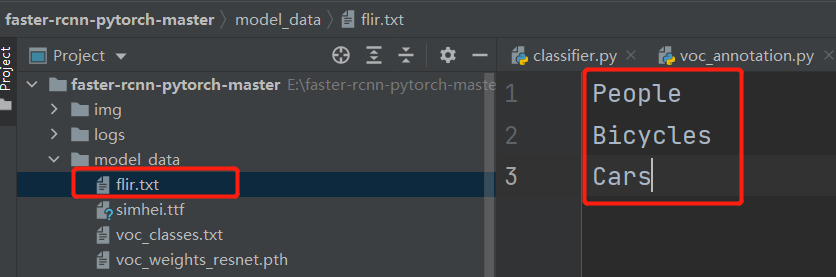
2.制作类文件
如图,在model_data中创建flir.txt文件,内容为People, Bicycles, Cars
3. 生成对应训练文件
检查是否有txt文件,如果有删除,需要生成对应FLIR数据集的txt文件
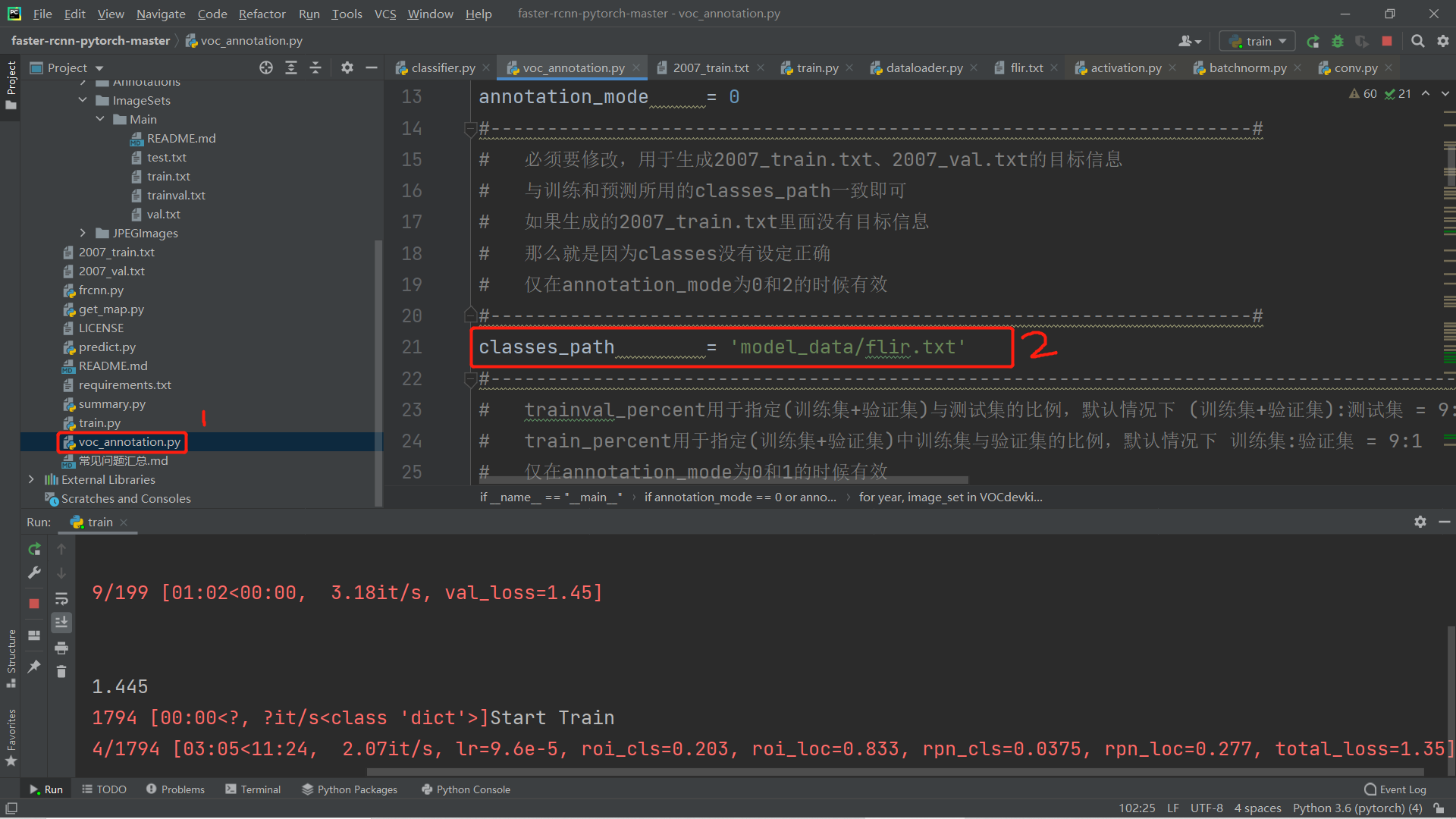
点击voc_annotation.py,修改里面classes_path = model_data/flir.txt,查找jpg修改为jpeg即可。
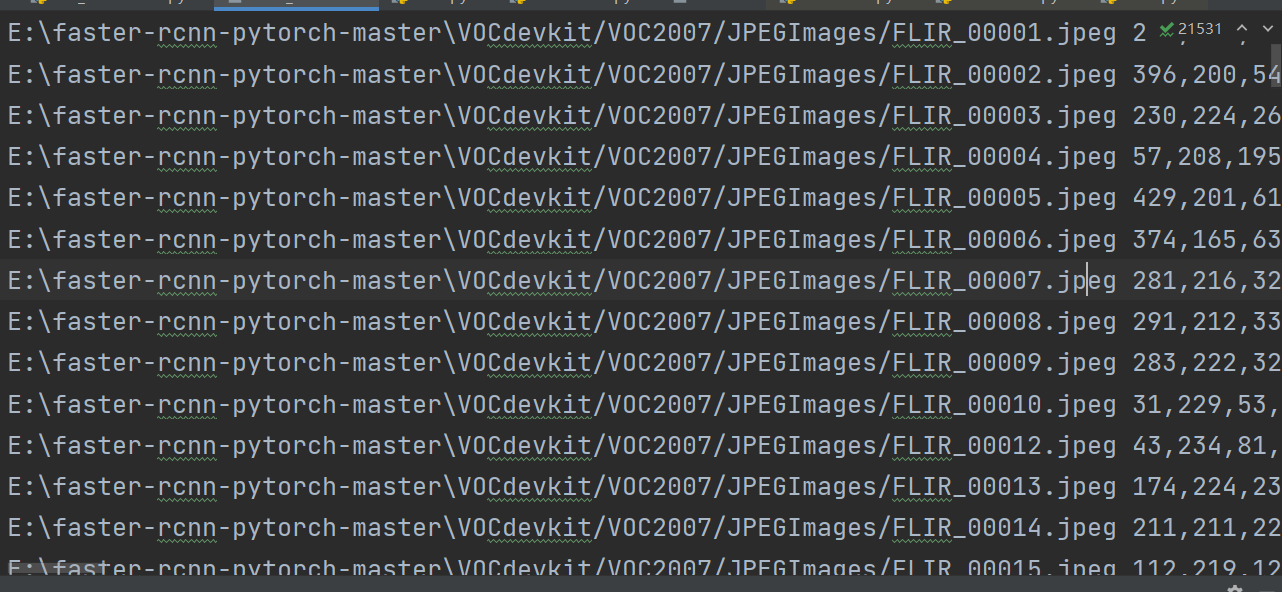
点击运行,会生成刚才删除的txt文件,可以打开看看,2007_train.txt中是训练图像的存储地址和标签。
4. 开始训练
点击train.py文件,修改classes_path = 'model_data/flir.txt'。点击运行按钮开始训练。

5. 预测
将val验证集的图像放入
修改预测的权重文件(选择loss和val-loss都小的权重值即可),修改类文件位置。
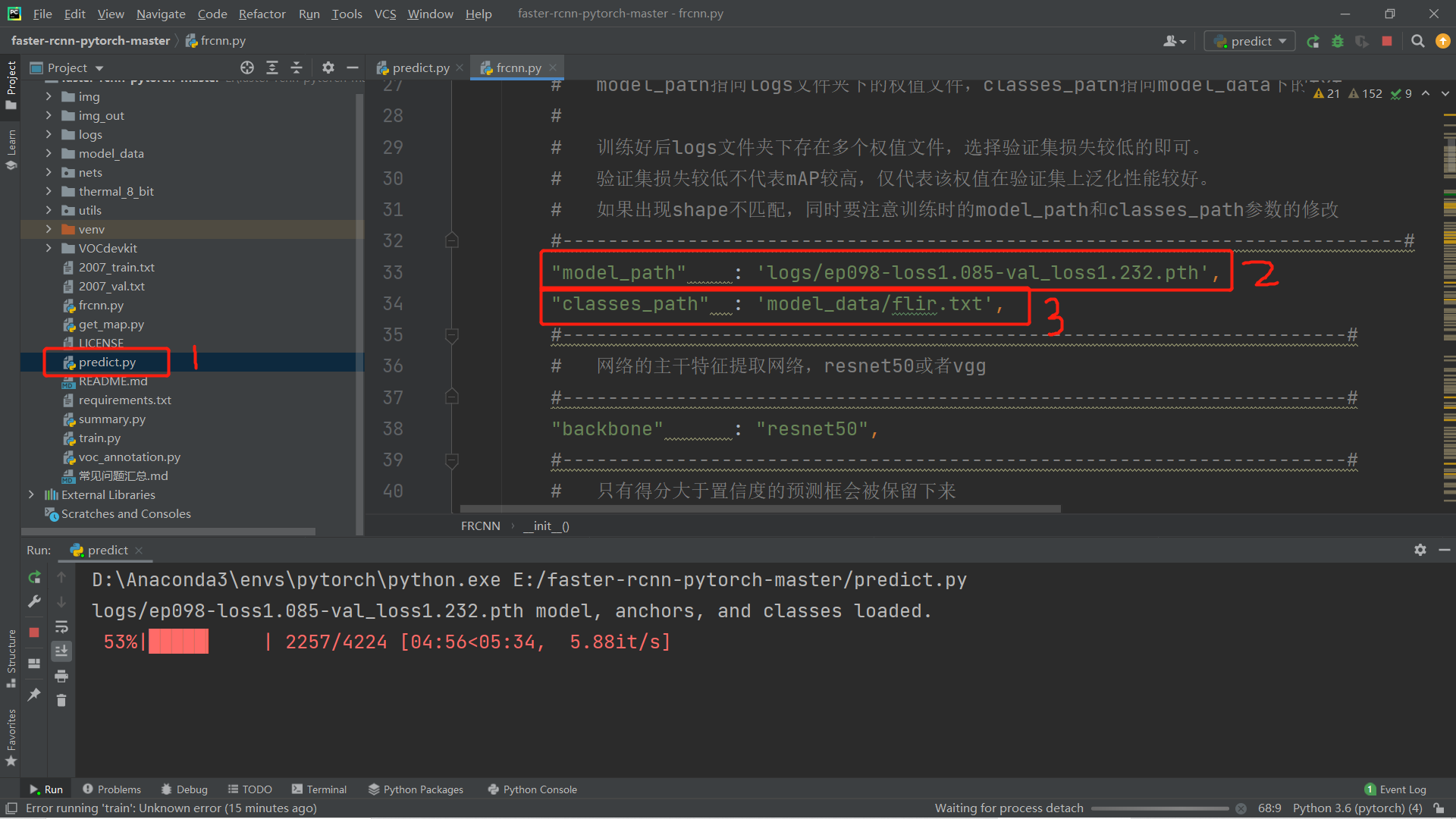

更改输入文件名称,复制改成导入的文件名称。

运行predict.py程序,生成img_out图像。
检测结果如下图所示:


总结
对比我之前训练的yolov5来说,这个检测效果感觉没那么好,但是相对于纯视觉来说已经好多了,削弱了光线的影响。
最后,我发现我训练的结果中自行车Bicycles的检测有点问题,如果有博友按照这个方法训练完成了,可以看看Bicycles类能不能正常检测。




















 3451
3451









 到【灌水乐园】发言
到【灌水乐园】发言









