




 本文详细介绍了正则表达式的各种符号及其用法,包括常见的匹配模式如A|B、.、^、$等,以及如何使用特殊字符进行精确匹配。通过本文,读者可以快速掌握正则表达式的基本原理和实践技巧。
本文详细介绍了正则表达式的各种符号及其用法,包括常见的匹配模式如A|B、.、^、$等,以及如何使用特殊字符进行精确匹配。通过本文,读者可以快速掌握正则表达式的基本原理和实践技巧。
正则表达式
学习资源:https://github.com/EbookFoundation/free-programming-books/blob/master/free-programming-books-zh.md
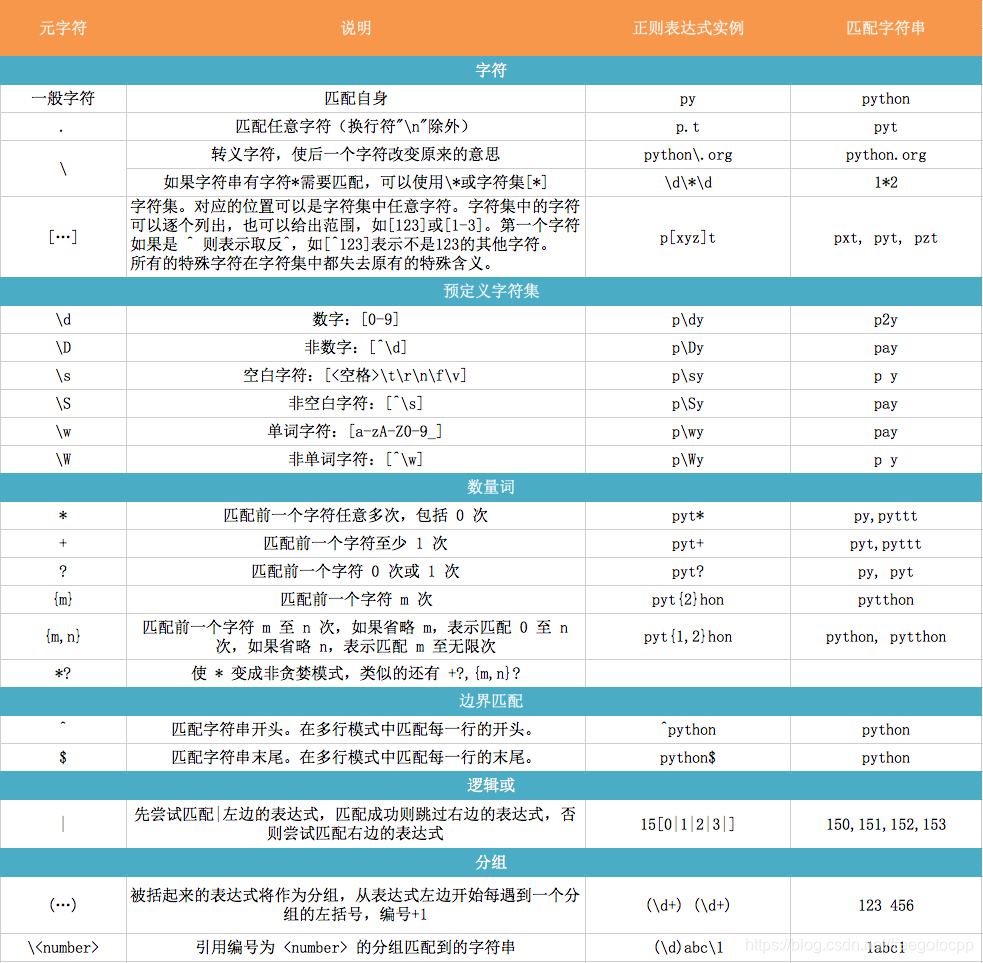
正则表达例子:
| A|B 匹配 A或者B
. A.A 匹配 A.A 匹配任何字符 除了\n除外
^ ^Demo 匹配字符串起始部分
$ abc$ 匹配字符串终止部分
* [A-Za-z0-9]* 匹配零次多次前面出现的表达式
+ [a-z]+\.com 匹配1次或多次前面出现的表达式
? abc? 匹配0次或者1次前面出现的表达式
{N} [0-9]{3} 匹配N次前面出现的表达式 {指定参数} {,逗号分割参数}
[...] [abc] 匹配来自字符集的任意单一字符
[..x-y..] [a-z]匹配下x-y范围中的任意单一字符
[^...] [^abc],[^a-z]不匹配此字符集中出现的任何一个字符,包括某一范围的字符
(*|+|?{})? .*?[a-z] 用于匹配上面频繁出现/重复出现符号的非贪婪版本
(...) ([0-9]{3})?,f(00|u)bar 匹配封闭的正则表达式,然后另存为子组
特殊字符用法
\d data\d+.txt 匹配任何十进制[0-9] \D与\d相反,不匹配任何非数值型的数字
\w [A-Za-z]\w+ 匹配任何字母数字字符 \W相反
\s of\sthe 匹配任何空格字符, \S相反
\b \bThe\b匹配任何单词边界 , \B相反
\N 匹配已保存的子组N
\c \.,\\,\* 逐字匹配任何特殊字符
\A(\Z) 匹配字符串的起始
扩展表示法
(?iLmsux) (?x), (? im) 在正则表达式中嵌入一个或多个特殊标记参数
(?:...) (?:\w+\.)* 表示一个匹配不用保存的分组
(?P<name>...) 像一个仅有name标识符而不是数字ID标识的正则分组匹配
(?P=name) 在同一个字符中匹配由(?P<name>)分组的之前文本
(?#...) 表示注释
(?=...) 匹配条件是如果...出现在之后的位置,而不使用输入字符;称作向前视断言
(?!..) 匹配条件是如果...不出现在之后的位置
(?<=...) 匹配条件是如果,出现在之前的位置
(?<!...) 匹配条件是如果...不出现在之前的位置
(?(id/name)Y/N) 如果分组所提供的id或者name存在,就返回正则表达式的条件匹配Y,如果不存在,就返回N ,N可选项

















 2366
2366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









