




目标检测
对计算机而言,能够“看到”的是图像被编码之后的数字,但它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定位目标出现在图像中哪个区域。
目标检测的主要目的是让计算机可以自动识别图片或者视频帧中所有目标的类别,并在该目标周围绘制边界框,标示出每个目标的位置
分类 VS 检测
分类

分类问题:所属类别(用卷积网络提取特征,然后用特征预测分类概率)
图像分类流程示意图:
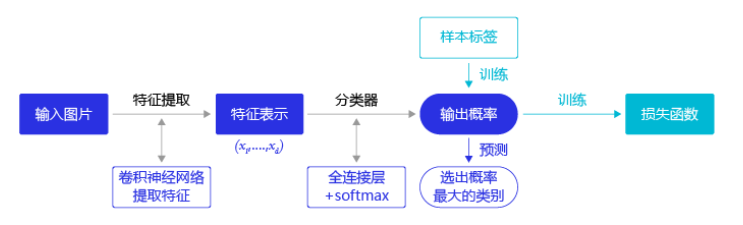
通过图(a),分类任务:得到最终的分类所属类别可能是动物或是斑马
检测

检测问题:所属类别 + 物体位置
不仅要检测出图片上出现了哪些物体,还要标出物体所在的区域
最终要完成的检测任务效果是要做出来矩形框:把物体所在的区域给框住,并且告诉人们,这是一个什么类别的物体。
目标检测发展历程
假设我们现在有某种方式可以在输入图片上生成一系列可能包含物体的区域,这些区域称为候选区域,然后对每个候选区域,可以把它单独当成一幅图像来看待,使用图像分类模型对它进行分类,看它属于哪个类别或者背景。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









