




 本文深入探讨Linux内核中的多种锁机制,包括原子操作、自旋锁、信号量、RCU机制、内存屏障、读者/写者锁、大内核锁、互斥量等,并解析System V IPC机制,如信号量、消息队列、共享内存的工作原理。
本文深入探讨Linux内核中的多种锁机制,包括原子操作、自旋锁、信号量、RCU机制、内存屏障、读者/写者锁、大内核锁、互斥量等,并解析System V IPC机制,如信号量、消息队列、共享内存的工作原理。
http://note.youdao.com/yws/public/redirect/share?id=cff581642044a36bd88984432da8b6e6&type=false
参考《Professional Linux kernel Architecture》 .
1、相关概念:
IPC :(Interprocess communication) 进程间通信
竞态条件 :几个进程在访问资源时彼此干扰的情况,进程执行在不应该中断的地方被中断,从而导致进程工作不正确。
锁的作用:确保每次只有一个CPU或者进程访问被保护的范围
2、内核锁机制:
原子操作:
简单来说就是不能被中断的操作,最简单的锁操作;

自旋锁:
用于短期保护某段代码,防止其他处理器访问,内核等等自旋锁释放期间会重复检查是否获得锁,不会进入休眠状态,所谓“自旋”的形象描述;

需要注意:
1、自旋锁获得后不释放系统将变得不可用,会进入死循环,产生死锁;
2、自旋锁块不应该长期持有,影响性能;
3、需要保证自旋锁保护的代码绝对不会进入睡眠;
信号量:
1、进程执行危险代码段时前,需要对信号量做 down(减1)操作,如果此时已经为0,说明已经有进程再执行危险代码了,此时该进程进入阻塞休眠状态(和自旋锁不同),直到前一个进程退出执行Up操作,调度器无法中断执行down操作的过程,属于原子操作;
2、缺点:内核开销大,影响性能;
3、数据结构:

count:指定可同时处于信号量保护临界区进程数目;
sleepers:指定等待运行进入临界区进程数目,等待的进程会进入睡眠,直到信号量释放才被唤醒;
wait:实现一个队列,保存所有信号量上睡眠的进程的task_struct
4、用法:
内核提供了简化宏定义接口:DECLARE_MUTEX,声明一个二值信号量.

值得注意的是,最新3.18版本内核已经使用互斥锁代替.
3、RCU机制:
rcu :read-copy-update 读-复制-更新
原理:数据结构将要改变时,先创建一个新副本,在副本中修改,所有访问者结束对旧副本读取后,指针指向新副本。
使用实例:
假设ptr指针指向被rcu保护的数据结构,那么需要被以下高亮部分代码保护起来:
dev->ip6_ptr 是被rcu保护的数据结构指针.

资源释放函数:
synchronize_rcu(); 该函数后释放所有关联资源是安全的;
call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu)) 用于注册一个函数在所有资源访问完成后回调。
rcu机制可以保护链表,接口函数是在原有的内核标准链表函数直接加上 _rcu后缀即可,列举:
<rculist.h>

4、内存和优化屏障 barrier
rmb() 读访问内存屏障,它保证该函数前的所有读操作不可乱序执行(流水线指令重排);
wmb() 写访问内存屏障,原理类似
mb() 合并了rmb() + wmb() 功能;
这是Linux kernel层面上的屏障接口,向下对接各种体系结构CPU具体的接口,比如ARMv7以后架构:

5、读者/写者锁
任何并发处理器可以对数据结构经常读操作,但只有一个处理器可以进行写操作。
读:read_lock /read_unlock, 允许临界区内任意数目的读进程并发访问;
写:write_lock/write_unlock, 内核只允许一个写进程处于临界区访问;

6、大内核锁 BKL
可以锁住整个内核,非常影响性能,最新3.18版本内核已将它弃用,成为了历史;
7、互斥量 <mutex.h> (互斥锁)
和信号量互斥原理类似,定义方法分为静态和动态两种:
1、静态定义: 使用 DEFINE_MUTEX 产生;
2、动态定义:mutex_init() ,在运行时产生;
mutex_lock/mutex_unlock 用于上锁和解锁

实时互斥量 rt_mutex,用于解决优先级反转问题,最新内核3.18代码好像已经弃用或者新机制代替。
标准函数:
rt_mutex_init
rt_mutex_lock
rt_mutex_unlock
*一个很重要很常见的数据结构:container_of(ptr,type,member)

这个数据结构在内核代码中大量被使用,初看起来数据结构十分复杂,但是只要明白了原理就很好理解了.
ptr指针的类型和member是类似的,type是包含member成员类型的容器,
这个宏定义的作用简单理解就是:给出一个结构实例,通过计算该结构在所在容器的内存偏移,反向找到所在容器的首地址。
找出ptr指向实例本身所在的容器结构首地址,结构类型是type,比如以下代码:

找出napi数据结构所在容器结构的首地址.
进程间通信
1、System V 机制
类型 : 信号量(和上面的信号量锁没有任何关系)、消息队列、共享内存;
主要用于两个不同进程间临界区的代码保护,实现“通信”.
信号灯(信号量IPC另外叫法)与其他进程间通信方式不大相同,它主要提供对进程间共享资源访问控制机制。相当于内存中的标志,进程可以根据它判定是否能够访问某些共享资源,同时,进程也可以修改该标志。除了用于访问控制外,还可用于进程同步。信号灯有以下两种类型:
- 二值信号灯:最简单的信号灯形式,信号灯的值只能取0或1,类似于互斥锁。
注:二值信号灯能够实现互斥锁的功能,但两者的关注内容不同。信号灯强调共享资源,只要共享资源可用,其他进程同样可以修改信号灯的值;互斥锁更强调进程,占用资源的进程使用完资源后,必须由进程本身来解锁。
注:二值信号灯能够实现互斥锁的功能,但两者的关注内容不同。信号灯强调共享资源,只要共享资源可用,其他进程同样可以修改信号灯的值;互斥锁更强调进程,占用资源的进程使用完资源后,必须由进程本身来解锁。
- 计算信号灯:信号灯的值可以取任意非负值(当然受内核本身的约束)。
数据结构:
使用几个数据结构建立网状结构,负责将信号量与等待进程关联起来
struct ipc_namespace {
...
struct ipc_ids *ids[3]; //0 ->共享内存,1->信号量,2->消息队列;
...
}
ipc_namespace 默认由以下实例实现:
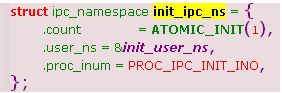
ipc_ids:

in_use: 当前使用中ipc对象的数目;
seq: 用于产生ipc ID,内核通过ID来管理ipc对象;
rwsem:内核信号量(锁)
ipcs_idr 用于关联kern_ipc_perm 实例指针,每个ipc对象都由kern_ipc_perm一个实例表示;

数据结构网状关系图:
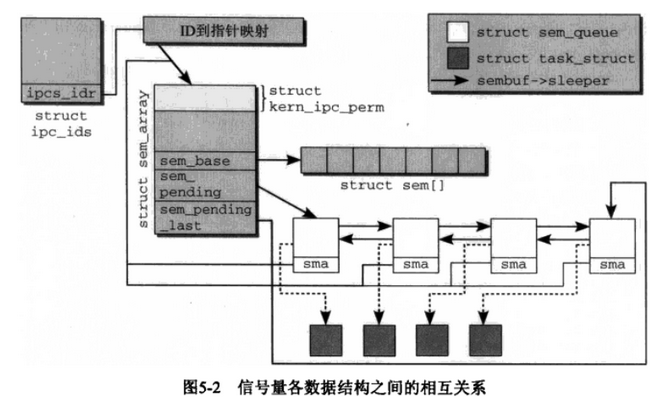
从 静态ipc_namespace对象的ipc_ids找到对应的ID到映射的指针,找到kern_ipc_perm实例,通过 结构->容器方法(container_of)找到该对象
所在容器对象的sem_array结构的首地址,sem_base保存了当前信号量的值和上一次访问它的进程id,sem_pending 指向sem_queue链表,而该sem_queue对象来之各个进程. 3.18内核已经改掉了这个关系图,以上作为理解参考。
获取ipc对象的系统调用关系图:
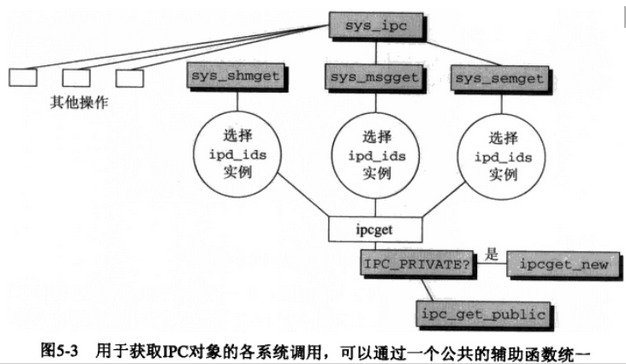
3.18 内核代码:

1 SYSCALL_DEFINE3(semget, key_t, key, int, nsems, int, semflg)
2 {
3 struct ipc_namespace *ns;
4 static const struct ipc_ops sem_ops = {
5 .getnew = newary, //创建新的sem ipc实例函数接口
6 .associate = sem_security,
7 .more_checks = sem_more_checks,
8 };
9 struct ipc_params sem_params;
10
11 ns = current->nsproxy->ipc_ns; //获取当前task_struct的ipc命名空间
12
13 if (nsems < 0 || nsems > ns->sc_semmsl)
14 return -EINVAL;
15
16 sem_params.key = key;
17 sem_params.flg = semflg;
18 sem_params.u.nsems = nsems;
19
20 return ipcget(ns, &sem_ids(ns), &sem_ops, &sem_params);
21 }
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params); //如果没有就创建一个ipc实例
else
return ipcget_public(ns, ids, ops, params); // 否则直接根据ipc_ids 查找到实例
}
static int newary(struct ipc_namespace *ns, struct ipc_params *params)
{
int id;
int retval;
struct sem_array *sma;
...
size = sizeof(*sma) + nsems * sizeof(struct sem);
sma = ipc_rcu_alloc(size); //创建新的sma实例
...
sma->sem_base = (struct sem *) &sma[1];
for (i = 0; i < nsems; i++) {
INIT_LIST_HEAD(&sma->sem_base[i].pending_alter); //将信号量集合sem_base 加入到链表中
INIT_LIST_HEAD(&sma->sem_base[i].pending_const);
spin_lock_init(&sma->sem_base[i].lock);
}
sma->complex_count = 0;
INIT_LIST_HEAD(&sma->pending_alter); //将待决信号量集合sem_base 加入到链表中
INIT_LIST_HEAD(&sma->pending_const);
INIT_LIST_HEAD(&sma->list_id);
sma->sem_nsems = nsems;
sma->sem_ctime = get_seconds();
id = ipc_addid(&sem_ids(ns), &sma->sem_perm, ns->sc_semmni); //初始化kern_ipc_perm 对象等.
....
ns->used_sems += nsems; //信号量数目++
....
}
2、消息队列.
进程间交换消息,使用内核的消息队列机制实现。
产生消息,并把消息写入队列的进程称为发送者(sender) ,一个或者多个其他进程则从队列中获取消息,称为接收者(recevier)
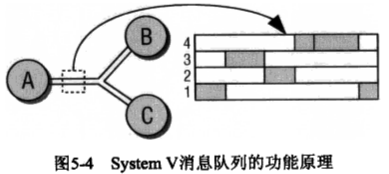
简图:进程A发生消息到msg_queue中,进程B,C从 msg_queue中获取消息.
数据结构:
struct msg_queue {
struct kern_ipc_perm q_perm;
time_t q_stime; /* last msgsnd time */
time_t q_rtime; /* last msgrcv time */
time_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
pid_t q_lspid; /* pid of last msgsnd */
pid_t q_lrpid; /* last receive pid */
struct list_head q_messages; // 消息本身内容链表
struct list_head q_receivers; // 由于管理睡眠的接受者
struct list_head q_senders; // 由于管理睡眠的发送者
};
q_messages 中各个消息封装在一个msg_msg实例中:
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security;
/* the actual message follows immediately */
};
q_senders 中链表元素是msg_sender 数据结构:
struct msg_sender {
struct list_head list;
struct task_struct *tsk;
};
q_receivers 中链表元素:
1 struct msg_receiver {
2 struct list_head r_list; //用于关联自身链表
3 struct task_struct *r_tsk; //指向对应进程的指针
4
5 int r_mode;
6 long r_msgtype;
7 long r_maxsize;
8
9 /*
10 * Mark r_msg volatile so that the compiler
11 * does not try to get smart and optimize
12 * it. We rely on this for the lockless
13 * receive algorithm.
14 */
15 struct msg_msg *volatile r_msg; //保持具体的消息内容.
16 };
消息队列涉及数据结构关系图:(省去睡眠的发生消息进程链表)
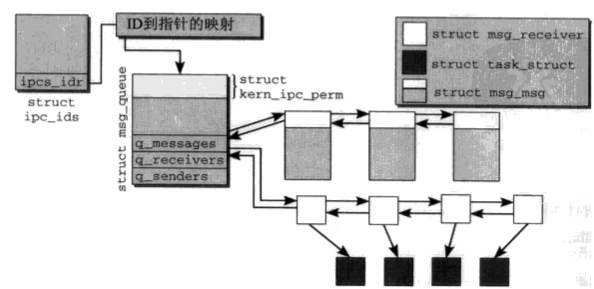
3.18 内核源代码分析
发送消息系统调用入口:
1 SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
2 int, msgflg)
3 {
4 long mtype;
5
6 if (get_user(mtype, &msgp->mtype))
7 return -EFAULT;
8 return do_msgsnd(msqid, mtype, msgp->mtext, msgsz, msgflg);
9 }
接收消息系统调用入口:
1 long do_msgsnd(int msqid, long mtype, void __user *mtext,
2 size_t msgsz, int msgflg)
3 {
4 struct msg_queue *msq;
5 struct msg_msg *msg;
6 int err;
7 struct ipc_namespace *ns;
8
9 ns = current->nsproxy->ipc_ns;
10
11 ...
12 for (;;) {
13 struct msg_sender s;
14
15 ...
16 ss_add(msq, &s); //添加s到msq->q_senders 队列
17
18 ...
19
20 ss_del(&s); //删掉 mss->list
21
22 ...
23 }
24 ...
25 if (!pipelined_send(msq, msg)) { // 发送
26 /* no one is waiting for this message, enqueue it */
27 list_add_tail(&msg->m_list, &msq->q_messages);
28 msq->q_cbytes += msgsz;
29 msq->q_qnum++;
30 atomic_add(msgsz, &ns->msg_bytes);
31 atomic_inc(&ns->msg_hdrs);
32 }
33
34 ...
35 }
36
37 SYSCALL_DEFINE5(msgrcv, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz,
38 long, msgtyp, int, msgflg)
39 {
40 return do_msgrcv(msqid, msgp, msgsz, msgtyp, msgflg, do_msg_fill);
41 }
3、共享内存.
使得多个进程可以访问同一块内存空间, 是最快的可用IPC形式。 是针对其他通信机制运行效率低而设计的。 往往与其他通信机制, 如信号量结合使用, 来达到进程间的同步及互斥。
共享内存允许两个或多个进程共享一定的内存区, 因为不需要拷贝数据, 所以这是最快的一种IPC,binder机制就是使用共享内存的方式实现。
共享内存允许两个或多个进程共享一定的内存区, 因为不需要拷贝数据, 所以这是最快的一种IPC,binder机制就是使用共享内存的方式实现。
内核的实现和前面两种对象非常类似,与信号量和消息队列相比,共享内存没有本质区别,流程很类似.相关数据结构如下图:
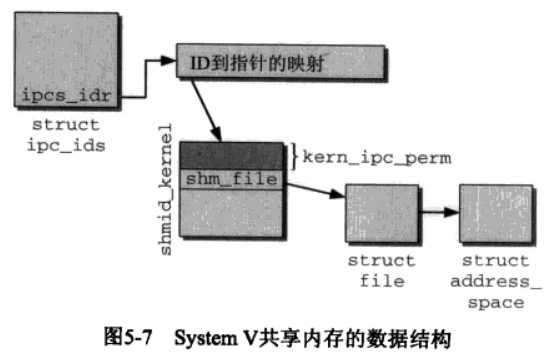
1、应用程序请求的IPC对象,可以通过魔数和当前的命名空间的内核ID访问;
2、对内存的访问可能受到权限系统的限制;
3、可以使用system call分配和IPC对象关联的内存,具备适当授权的所有进程都可以访问该内存.
以下是用户层接口:
#include <sys/ipc.h>
#include <sys/shm.h>
(1)创建或访问共享内存
* int shmget(key_t key,size_t size,int shmflg);
(2)附加共享内存到进程的地址空间
* void *shmat(int shmid,const void *shmaddr,int shmflg);//shmaddr通常为NULL, 由系统选择共享内存附加的地址;shmflg可以为
SHM_RDONLY
(3)从进程的地址空间分离共享内存
* int shmdt(const void *shmaddr); //shmaddr是shmat()函数的返回值
(4)控制共享内存
* int shmctl(int shmid,int cmd,struct shmid_ds *buf);
* struct shmid_ds{
struct ipc_perm shm_perm;
…
};
cmd的常用取值有:(a)IPC_STAT获取当前共享内存的shmid_ds结构并保存在buf中(2)IPC_SET使用buf中的值设置当前共享内存的
shmid_ds结构(3)IPC_RMID删除当前共享内存
#include <sys/ipc.h>
#include <sys/shm.h>
(1)创建或访问共享内存
* int shmget(key_t key,size_t size,int shmflg);
(2)附加共享内存到进程的地址空间
* void *shmat(int shmid,const void *shmaddr,int shmflg);//shmaddr通常为NULL, 由系统选择共享内存附加的地址;shmflg可以为
SHM_RDONLY
(3)从进程的地址空间分离共享内存
* int shmdt(const void *shmaddr); //shmaddr是shmat()函数的返回值
(4)控制共享内存
* int shmctl(int shmid,int cmd,struct shmid_ds *buf);
* struct shmid_ds{
struct ipc_perm shm_perm;
…
};
cmd的常用取值有:(a)IPC_STAT获取当前共享内存的shmid_ds结构并保存在buf中(2)IPC_SET使用buf中的值设置当前共享内存的
shmid_ds结构(3)IPC_RMID删除当前共享内存
4、管道、信号、套接字(socket
...

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









