




 MLP-Mixer是Google提出的一种新的计算机视觉框架,用多层感知机替换传统CNN的卷积和Transformer的自注意力机制。模型包括Per-patch Fully-connected、Mixer Layer,通过MLP进行空间域和通道域的信息融合。虽然其结构简单,但在ImageNet上的性能接近SOTA。然而,MLP-Mixer的Per-patch Fully-connected可视为卷积操作,Mixer Layer则类似深度可分离卷积,引发是否真正摒弃卷积的争议。
MLP-Mixer是Google提出的一种新的计算机视觉框架,用多层感知机替换传统CNN的卷积和Transformer的自注意力机制。模型包括Per-patch Fully-connected、Mixer Layer,通过MLP进行空间域和通道域的信息融合。虽然其结构简单,但在ImageNet上的性能接近SOTA。然而,MLP-Mixer的Per-patch Fully-connected可视为卷积操作,Mixer Layer则类似深度可分离卷积,引发是否真正摒弃卷积的争议。
MLP-Mixer详解
1 主要思想
作为Google ViT团队最近刚提出的一种的CV框架,MLP-Mixer使用多层感知机(MLP)来代替传统CNN中的卷积操作(Conv)和Transformer中的自注意力机制(Self-Attention)。
MLP-Mixer整体设计简单,在ImageNet上的表现接近于近年最新的几个SOTA模型。
2 模型结构
MLP-Mixer主要包括三部分:Per-patch Fully-connected、Mixer Layer、分类器。
其中分类器部分采用传统的全局平均池化(GAP)+全连接层(FC)+Softmax的方式构成,故不进行更多介绍,下面主要针对前两部分进行解释。
2.1 Per-patch Fully-connected
FC相较于Conv,并不能获取局部区域间的信息,为了解决这个问题,MLP-Mixer通过Per-patch Fully-connected将输入图像转化为2D的Table,方便在后面进行局部区域间的信息融合。
具体来说,MLP-Mixer将输入图像相邻无重叠地划分为S个Patch,每个Patch通过MLP映射为一维特征向量,其中一维向量长度为C,最后将每个Patch得到的特征向量组合得到大小为S*C的2D Table。需要注意的时,每个Patch使用的映射矩阵相同,即使用的MLP参数相同。
实际上,Per-patch Fully-connected实现了**(W,H,C)的向量空间到(S,C)的向量空间**的映射。
例如,假设输入图像大小为240*240*3,模型选取的Patch为16*16,那么一张图片可以划分为(240*240)/(16*16)= 225个Patch。结合图片的通道数,每个Patch包含了16*16*3 = 768个值,把这768个值做Flatten作为MLP的输入,其中MLP的输出层神经元个数为128。这样,每个Patch就可以得到长度的128的特征向量,组合得到225*128的Table。MLP-Mixer中Patch大小和MLP输出单元个数为超参数。
2.2 Mixer Layer
观察Per-patch Fully-connected得到的Table会发现,Table的行代表了同一空间位置在不同通道上的信息,列代表了不同空间位置在同一通道上的信息。换句话说,对Table的每一行进行操作可以实现通道域的信息融合,对Table的每一列进行操作可以实现空间域的信息融合。
在传统CNN中,可以通过1*1 Conv来实现通道域的信息融合,如果使用更大一点的卷积核,可以同时实现空间域和通道域的信息融合。
在Transformer中,通过Self-Attention实现空间域的信息融合,通过MLP同时实现空间域和通道域的信息融合。
而在MLP-Mixer中,通过Mixer Layer使用MLP先后对列、行进行映射,实现空间域和通道域的信息融合。与传统卷积不同的是,Mixer Layer将空间域和通道域分开操作,这种思想与Xception和MobileNet中的深度可分离卷积相似。

根据上述内容,MLP-Mixer在Mixer Layer中使用分别使用**token-mixing MLPs(图中MLP1)和channel-mixing MLPs(图中MLP2)**对Table的列和行进行映射,与Per-patch Fully-connected相同,MLP1和MLP2在不同列、行中的映射过程中共享权重。除此之外,Mixer Layer还加入了LN和跳接来提高模型性能。
另外,MLP1和MLP2都采用了相同的结构,如下图。

2.3 整体结构

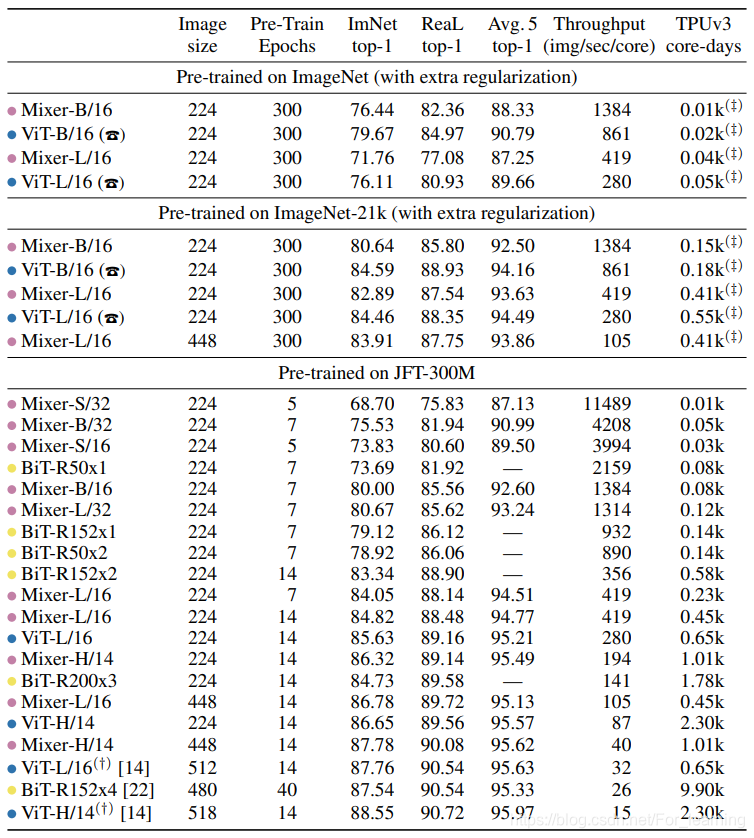
3 模型性能
文中使用MLP Mixer进行预训练,然后在ImageNet上进行fine-tune,性能较ViT略差。
具体调参过程和性能比较,可参考原文。
4 存在的争议
个人认为,MLP-Mixer的创新点在于使用了MLP代替了Conv和Self-Attention,这表明使用最基础的MLP的拟合能力足以构建一个相对性能较好的CV模型。
实际上,如果熟悉Conv操作的话会发现,MLP-Mixer中并非不存在Conv。
MLP-Mixer的第一步Per-patch Fully-connected实际上完全等价于对输入图像做了一个kenel为16*16、stride为16的卷积操作。
tf.keras.layers.Conv2D(C, (16, 16), stride=16, padding='vaild')
MLP-Mixer的Mixer Layer为共享权重的深度可分离卷积。
# 传统的深度可分离卷积,各通道卷积时不共享权重
tf.keras.layers.SperableConv2D()
这样看来,MLP-Mixer中的MLP可以看作是卷积操作的等价形式。

















 1986
1986







 到【灌水乐园】发言
到【灌水乐园】发言







