







前言
这是我遇到的一个离奇的内核死锁问题,现象倒是不复杂,是一个常见的smp_call_function_many的软死锁。但在分析问题的过程中却越挖越深,解决一个问题后又冒出一个问题,顺藤摸瓜的揪出了最后的问题根源。过程中充分利用了内核分析工具,也学习到了不少新知识。下面就将问题的分析和定位过程跟大家分享一下,共同进步。因为过程有点长,准备以一个系列文章的形式来描述,请各位看官耐心。
1.第一现场
先交待一下问题的背景和环境。我的设备环境是使用Intel CPU的设备,属于服务器架构。操作系统是CentOS7,自己裁剪的内核,内核版本是4.9.25。运行过程中高概率的复现一个死锁问题,问题复现时系统日志中有出错信息,出现这个日志后概率出现系统没有反应(无法输入也没有输出,网络也不通)。
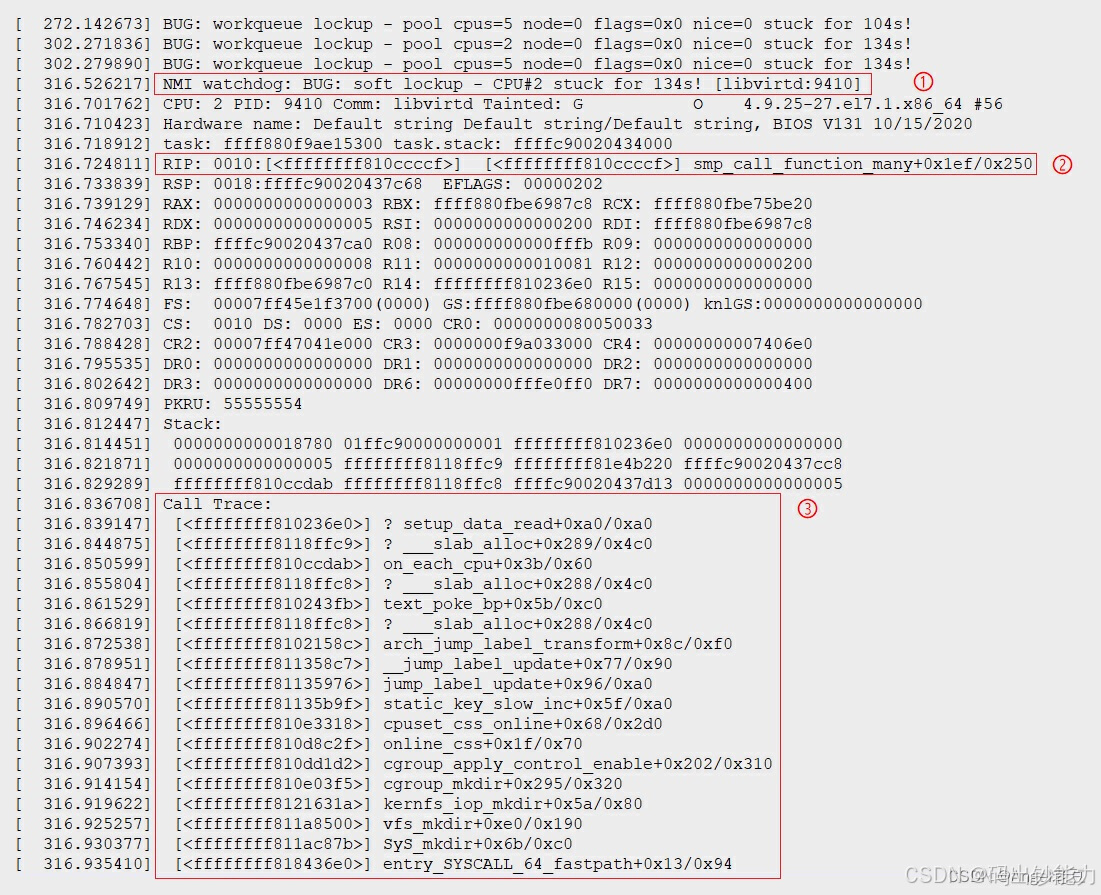
通常这类问题的分析都要从分析这个堆栈信息开始,首先要看的是错误类型和错误提示。可以确定这是一个soft lockup错误,也就是软死锁。出问题的进程是"libvirtd"。
NMI watchdog: BUG: soft lockup - CPU#2 stuck for 134s! [libvirtd:9410]
再进一步的可以看出现问题的函数:“smp_call_function_many”,这个函数在内核的"kernel\smp.c"文件中。
RIP: 0010:[<ffffffff810ccccf>] [<ffffffff810ccccf>] smp_call_function_many+0x1ef/0x250
第三步可以从堆栈信息中看到错误出现时的函数调用过程。在Call Trace中可以看到直接调用出问题的函数是:“on_each_cpu”。
至此现场信息已经看完了,随之而来的是一堆问题。
什么是“soft lockup”?
这个“smp_call_function_many”函数是做什么的,为什么会在这个函数里lockup?
这个lockup是否和这个Call Trace中显示的调用路径相关?
其中这第三个问题先按下不表,从前两个问题开始分析。
2.问题分析
2.1 问题背景知识
soft lockup
此章节参考Linux内核为什么会发生soft lockup?
先解释一下soft lockup,指的是发生的CPU上在一段时间内(默认是20秒)中没有发生调度切换。从上面的出错信息来看这个进程已经有134秒没有发生调度切换了。这里有可能是发生了死循环,或者是一种忙等,导致这个进程一直占据这个CPU(CPU#2)。
smp_call_function函数作用
这一类函数是内核中用于跨CPU的操作的函数,常用于的同步关键信息的操作。在SMP架构中不同的CPU核心之间通过这类函数对指定的CPU或多个CPU发IPI消息,目标CPU收到该消息进入中断处理函数,进而调用参数上的func函数指针执行指定操作。
上面信息中的smp_call_function_many函数就是,从CPU#2发送一个IPI消息给其他所有的其他CPU,让大家统一进行一个操作。
2.2 查找出错的代码行
要搞清楚为什么会在smp_call_function_many函数发生soft lockup,我们还是要回到代码来分析到底发生了什么?你可以在内核的"kernel\smp.c"文件中找到函数的代码。我这里并不准备深入分析内核的IPI实现机制,只是通过对代码分析来定位问题。如果对IPI机制的实现和运作有兴趣可以参考后面的参考阅读。
void smp_call_function_many(const struct cpumask *mask,
smp_call_func_t func, void *info, bool wait)
{
struct call_function_data *cfd;
int cpu, next_cpu, this_cpu = smp_processor_id();
/*
* Can deadlock when called with interrupts disabled.
* We allow cpu's that are not yet online though, as no one else can
* send smp call function interrupt to this cpu and as such deadlocks
* can't happen.
*/
WARN_ON_ONCE(cpu_online(this_cpu) && irqs_disabled()
&& !oops_in_progress && !early_boot_irqs_disabled);
/* Try to fastpath. So, what's a CPU they want? Ignoring this one. */
cpu = cpumask_first_and(mask, cpu_online_mask);
if (cpu == this_cpu)
cpu = cpumask_next_and(cpu, mask, cpu_online_mask);
/* No online cpus? We're done. */
if (cpu >= nr_cpu_ids)
return;
/* Do we have another CPU which isn't us? */
next_cpu = cpumask_next_and(cpu, mask, cpu_online_mask);
if (next_cpu == this_cpu)
next_cpu = cpumask_next_and(next_cpu, mask, cpu_online_mask);
/* Fastpath: do that cpu by itself. */
if (next_cpu >= nr_cpu_ids) {
smp_call_function_single(cpu, func, info, wait);
return;
}
cfd = this_cpu_ptr(&cfd_data);
cpumask_and(cfd->cpumask, mask, cpu_online_mask);
cpumask_clear_cpu(this_cpu, cfd->cpumask);
/* Some callers race with other cpus changing the passed mask */
if (unlikely(!cpumask_weight(cfd->cpumask)))
return;
for_each_cpu(cpu, cfd->cpumask) {
struct call_single_data *csd = per_cpu_ptr(cfd->csd, cpu);
csd_lock(csd);
if (wait)
csd->flags |= CSD_FLAG_SYNCHRONOUS;
csd->func = func;
csd->info = info;
llist_add(&csd->llist, &per_cpu(call_single_queue, cpu));
}
/* Send a message to all CPUs in the map */
arch_send_call_function_ipi_mask(cfd->cpumask);
if (wait) {
for_each_cpu(cpu, cfd->cpumask) {
struct call_single_data *csd;
csd = per_cpu_ptr(cfd->csd, cpu);
csd_lock_wait(csd);
}
}
}
这里我们首先再次利用第一现场的信息来定位出现问题的代码行。
这里可以看出在smp_call_function_many函数的偏移量0x1ef(十进制:495)处出现了问题。通过gdb内核debuginfo可以看到这个函数偏移量对应的代码行。
# gdb ./vmlinux
(gdb) l* smp_call_function_many+495
0xffffffff810ccccf is in smp_call_function_many (./include/linux/compiler.h:243).
238 ./include/linux/compiler.h: No such file or directory.
gdb给出的是一个头文件中compiler.h:243的宏定义:
static __always_inline
void __read_once_size(const volatile void *p, void *res, int size)
{
__READ_ONCE_SIZE;
}
gdb显示是__READ_ONCE_SIZE这一行。这个是被内联进函数中的一段代码,并不能直接看出在函数smp_call_function_many中的位置。我们需要在出错位置的周边来看看是否能直接找到对应的代码行。使用gdb反汇编函数,得到出问题偏移量周边的语句偏移量:
(gdb) disass smp_call_function_many
Dump of assembler code for function smp_call_function_many:
0xffffffff810ccae0 <+0>: callq 0xffffffff81844bd0 <__fentry__>
0xffffffff810ccae5 <+5>: push %rbp
0xffffffff810ccae6 <+6>: mov %rsp,%rbp
0xffffffff810ccae9 <+9>: push %r15
0xffffffff810ccaeb <+11>: mov %rdx,%r15
...
0xffffffff810cccc9 <+489>: test $0x1,%al
0xffffffff810ccccb <+491>: je 0xffffffff810cccd6 <smp_call_function_many+502>
0xffffffff810ccccd <+493>: pause
0xffffffff810ccccf <+495>: mov 0x18(%rcx),%eax
0xffffffff810cccd2 <+498>: test $0x1,%al
0xffffffff810cccd4 <+500>: jne 0xffffffff810ccccd <smp_call_function_many+493>
...
0xffffffff810ccd19 <+569>: mov %r12,%rsi
0xffffffff810ccd1c <+572>: mov %eax,%edi
0xffffffff810ccd1e <+574>: callq 0xffffffff8145a440 <cpumask_next_and>
0xffffffff810ccd23 <+579>: jmpq 0xffffffff810ccbaf <smp_call_function_many+207>
End of assembler dump.
(gdb)
再尝试获取函数在偏移量为493和491的代码行:
(gdb) l* smp_call_function_many+493
0xffffffff810ccccd is in smp_call_function_many (./arch/x86/include/asm/processor.h:584).
579 ./arch/x86/include/asm/processor.h: No such file or directory.
(gdb) l* smp_call_function_many+491
0xffffffff810ccccb is in smp_call_function_many (kernel/smp.c:96).
91 kernel/smp.c: No such file or directory.
可以看到smp_call_function_many+491的这个偏移量对应的是kernel/smp.c:96的代码行。这个就接近很多了,同样这也是一个内联函数:
static __always_inline void csd_lock_wait(struct call_single_data *csd)
{
smp_cond_load_acquire(&csd->flags, !(VAL & CSD_FLAG_LOCK));
}
在smp_call_function_many函数代码中最后调用了csd_lock_wait函数。
同时,还可以看到csd_lock_wait函数调用的smp_cond_load_acquire宏定义中包含了READ_ONCE,READ_ONCE这个宏最终会调用__read_once_size宏,就是第一现场中指示的偏移量smp_call_function_many+495引用的宏。
#define smp_cond_load_acquire(ptr, cond_expr) ({ \
typeof(ptr) __PTR = (ptr); \
typeof(*ptr) VAL; \
for (;;) { \
VAL = READ_ONCE(*__PTR); \
if (cond_expr) \
break; \
cpu_relax(); \
} \
smp_acquire__after_ctrl_dep(); \
VAL; \
})
这样基本可以确定出错时的代码行:smp_call_function_many内联的csd_lock_wait函数,这个函数再内联smp_cond_load_acquire再内联调用__read_once_size的这一句。
2.3 smp_call_function_many死循环
通过上面的分析,我们将注意力集中到smp_call_function_many函数的这几行代码:
在这里插入图片描述
这段代码告诉我们smp_call_function_many函数在这里遍历每个收到IPI消息CPU,并等待他们做出响应。再看smp_cond_load_acquire宏定义中,有一个for( ; ; )的无限循环一直读取变量。由此可以基本判断问题的现象就是由这个无限循环产生的。也就是等待的某个CPU响应一直没有回应。
3 初步结论
结合上面的背景知识和这段代码的分析,我们可以得到一个初步的结论:该问题是由CPU#2发起了一个smp_call_function请求,向其他的CPU发送IPI信息,接收到IPI消息的CPU根据函数中的func函数指针进行处理,处理完成的CPU将设置对应的csd结构以告知完成该请求;发起方的CPU#2会遍历所有的CPU的csd结构以确认请求都被执行;如果其中一个CPU没有完成,则循环等待其完成;如果某个CPU长时间的没有完成,就会导致发起者CPU#2的忙等操作出现soft lockup。
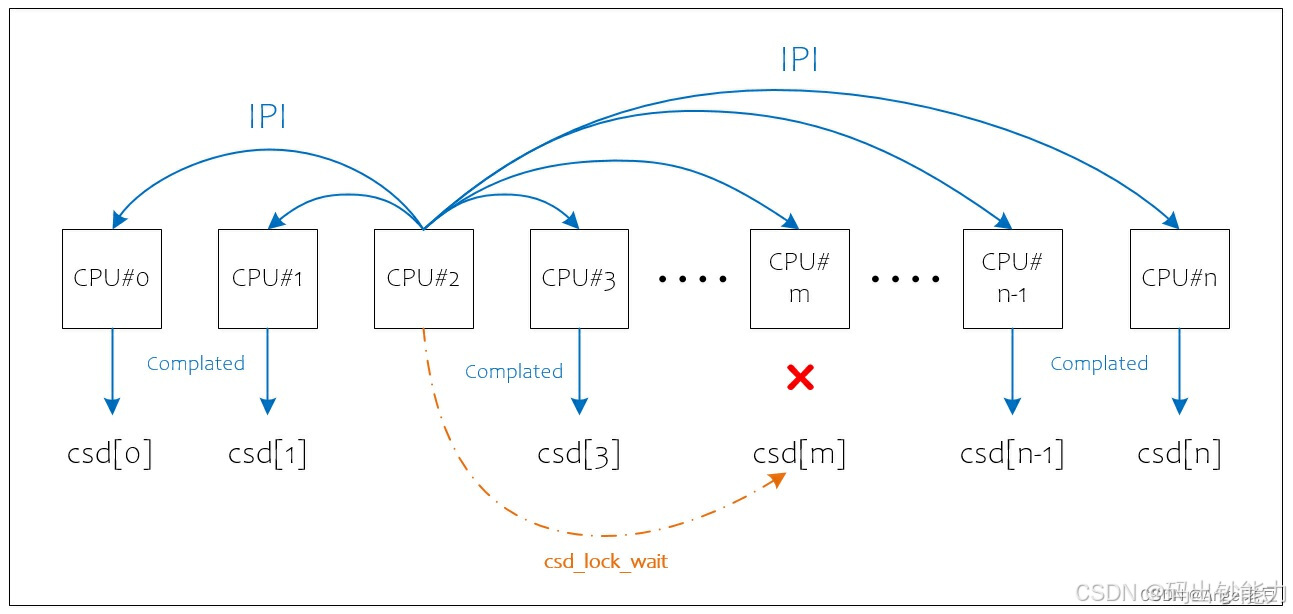
问题分析到这里并没有实质的进展,只是产生了更多的新问题。看到的出错信息和现象只是表象,或者说CPU#2出现的soft lockup也是受害者。为了进一步的分析该问题有两个方向可以继续努力:1)找到那个一直没有处理IPI的CPU,看看能否得知是什么原因引起;2)分析出错信息中的Call Trace看看具体是个什么样的任务需要大家一起完成,也就是IPI发送的信息是为了做什么。
4.找出没有响应IPI的CPU
上篇的现场分析的最后,我们将分析的重点放到错误信息出现的代码段上,在smp_call_function_many函数的这几行代码中,遍历接收到IPI消息的CPU,等待每个CPU的响应,当前正在等待的CPU编号为局部变量’cpu’。
if (wait) {
for_each_cpu(cpu, cfd->cpumask) {
struct call_single_data *csd;
csd = per_cpu_ptr(cfd->csd, cpu);
csd_lock_wait(csd);
}
}
那么这个函数中的局部变量’cpu’的当前值就是出现没有响应IPI的那个CPU的ID。怎样知道局部变量cpu的当前值呢?我们需要结合代码的反汇编信息和第一现场中的积存器值来得到。
首先,将内核的debuginfo信息中的kernel/smp.c文件的二进制文件smp.o进行反汇编(如果没有找到这个二进制文件,可以将整个内核的二进制文件vmlinux反汇编),从反汇编信息中找到smp_call_function_many函数对应的反汇编信息(信息过长,这里只展示和问题相关的部分):
# objdump -Sl smp.o
0000000000000660 <smp_call_function_many>:
smp_call_function_many():
void smp_call_function_many(const struct cpumask *mask,
smp_call_func_t func, void *info, bool wait)
{
660: e8 00 00 00 00 callq 665 <smp_call_function_many+0x5>
665: 55 push %rbp
666: 48 89 e5 mov %rsp,%rbp
669: 41 57 push %r15
...
811: 0f 84 b9 fe ff ff je 6d0 <smp_call_function_many+0x70>
cpumask_next():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/./include/linux/cpumask.h:193 (discriminator 1)
817: 83 c2 01 add $0x1,%edx
81a: be 00 02 00 00 mov $0x200,%esi
81f: 48 89 df mov %rbx,%rdi
822: 48 63 d2 movslq %edx,%rdx
825: e8 00 00 00 00 callq 82a <smp_call_function_many+0x1ca>
smp_call_function_many():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/kernel/smp.c:448 (discriminator 1)
for_each_cpu(cpu, cfd->cpumask) {
82a: 3b 05 00 00 00 00 cmp 0x0(%rip),%eax # 830 <smp_call_function_many+0x1d0>
830: 89 c2 mov %eax,%edx
832: 0f 8d 98 fe ff ff jge 6d0 <smp_call_function_many+0x70>
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/kernel/smp.c:451
struct call_single_data *csd;
csd = per_cpu_ptr(cfd->csd, cpu);
838: 48 98 cltq
83a: 49 8b 4d 00 mov 0x0(%r13),%rcx
83e: 48 03 0c c5 00 00 00 add 0x0(,%rax,8),%rcx
845: 00
__read_once_size():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/./include/linux/compiler.h:243
846: 8b 41 18 mov 0x18(%rcx),%eax
csd_lock_wait():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/kernel/smp.c:96
static __always_inline void csd_lock_wait(struct call_single_data *csd)
{
smp_cond_load_acquire(&csd->flags, !(VAL & CSD_FLAG_LOCK));
849: a8 01 test $0x1,%al
84b: 74 09 je 856 <smp_call_function_many+0x1f6>
rep_nop():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/./arch/x86/include/asm/processor.h:584
84d: f3 90 pause
__read_once_size():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/./include/linux/compiler.h:243
84f: 8b 41 18 mov 0x18(%rcx),%eax
csd_lock_wait():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/kernel/smp.c:96
852: a8 01 test $0x1,%al
854: 75 f7 jne 84d <smp_call_function_many+0x1ed>
856: eb bf jmp 817 <smp_call_function_many+0x1b7>
...
可以看到smp_call_function_many函数是从文件的偏移0x0000000000000660开始的,上一篇中讲到出错时指示的位置是smp_call_function_many+0x1ef,所以0x660+0x1ef=0x84f就是出错时对应的反汇编信息。可以看到和上一篇中找到的汇编信息是一致的。
__read_once_size():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/./include/linux/compiler.h:243
84f: 8b 41 18 mov 0x18(%rcx),%eax
那么要找到局部变量cpu的信息,就在出错的代码行前面找,找到变量cpu开始出现的地方:
smp_call_function_many():
/usr/src/kernels/linux-4.9.25-27.el7.1.x86_64/kernel/smp.c:448 (discriminator 1)
for_each_cpu(cpu, cfd->cpumask) {
82a: 3b 05 00 00 00 00 cmp 0x0(%rip),%eax # 830 <smp_call_function_many+0x1d0>
830: 89 c2 mov %eax,%edx
832: 0f 8d 98 fe ff ff jge 6d0 <smp_call_function_many+0x70>
变量cpu是在这个for_each_cpu宏中被使用和赋值,在内核代码中可以找到这个宏定义:
#define for_each_cpu(cpu, mask) \
for ((cpu) = -1; \
(cpu) = cpumask_next((cpu), (mask)), \
(cpu) < nr_cpu_ids;)
通过对比汇编和宏定义的代码,可以判定在这段汇编中%eax寄存器就是每次循环中cpu变量的值;在偏移量为0x830的一句汇编代码中( mov %eax, %edx ),%eax寄存器的值被保存到了%edx中。再看从偏移量0x830到偏移量0x84f之间的汇编代码,%eax寄存器在偏移量0x846的一句被重新赋值了,但是%edx在这段代码中没有被使用过,一直保存着变量cpu的当前值。
由此可以确定,在出现问题的现场信息中,寄存器%edx中的值就是当前局部变量cpu的值,也就是正在等待的那个CPU。在x86_64体系架构中,%edx是寄存器%rdx的低32位部分。
再来看第一现场中的寄存器信息,其中RDX寄存器中的值:
[ 316.724811] RIP: 0010:[<ffffffff810ccccf>] [<ffffffff810ccccf>] smp_call_function_many+0x1ef/0x250
[ 316.733839] RSP: 0018:ffffc90020437c68 EFLAGS: 00000202
[ 316.739129] RAX: 0000000000000003 RBX: ffff880fbe6987c8 RCX: ffff880fbe75be20
[ 316.746234] RDX: 0000000000000005 RSI: 0000000000000200 RDI: ffff880fbe6987c8
[ 316.753340] RBP: ffffc90020437ca0 R08: 000000000000fffb R09: 0000000000000000
[ 316.760442] R10: 0000000000000008 R11: 0000000000010081 R12: 0000000000000200
[ 316.767545] R13: ffff880fbe6987c0 R14: ffffffff810236e0 R15: 0000000000000000
[ 316.774648] FS: 00007ff45e1f3700(0000) GS:ffff880fbe680000(0000) knlGS:0000000000000000
[ 316.782703] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 316.788428] CR2: 00007ff47041e000 CR3: 0000000f9a033000 CR4: 00000000007406e0
[ 316.795535] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 316.802642] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
由此可以得到%edx的值是5,也就是没有响应IPI消息的CPU是5号。那么5号CPU现在正在做什么呢?
5.问题现象分析
找到了没有响应IPI信息的CPU并不能获知当前在做什么,要额外的信息来看在CPU#5上出了什么问题。通常情况下要获取一个CPU上当前运行信息可以通过top命令或ps命令,但是在问题出现时top信息中并没有显示CPU#5上运行的进程,同时在出现问题是时伴有无法输入和网络中断等问题也妨碍了获取信息的操作。于是只能通过获取内核crash转储信息来看了。
在获取信息之前要分析一下问题的现象。在问题出现之前CPU#2发出的IPI信息是以CPU核间中断的形式发送的,接收的CPU应该进入中断处理程序再调用对应的IPI消息处理函数。CPU#5没有响应IPI消息是否有可能是在某个禁止中断的流程中一直没有出来? 也就是说在一个禁止硬件中断的流程中发生了死循环。如果是这样就可以解释问题出现时的很多现象,如:导致多个CPU核上的soft lockup,导致输入没有响应,top信息中没有CPU#5的运行进程信息等。这种情况就是hard lockup。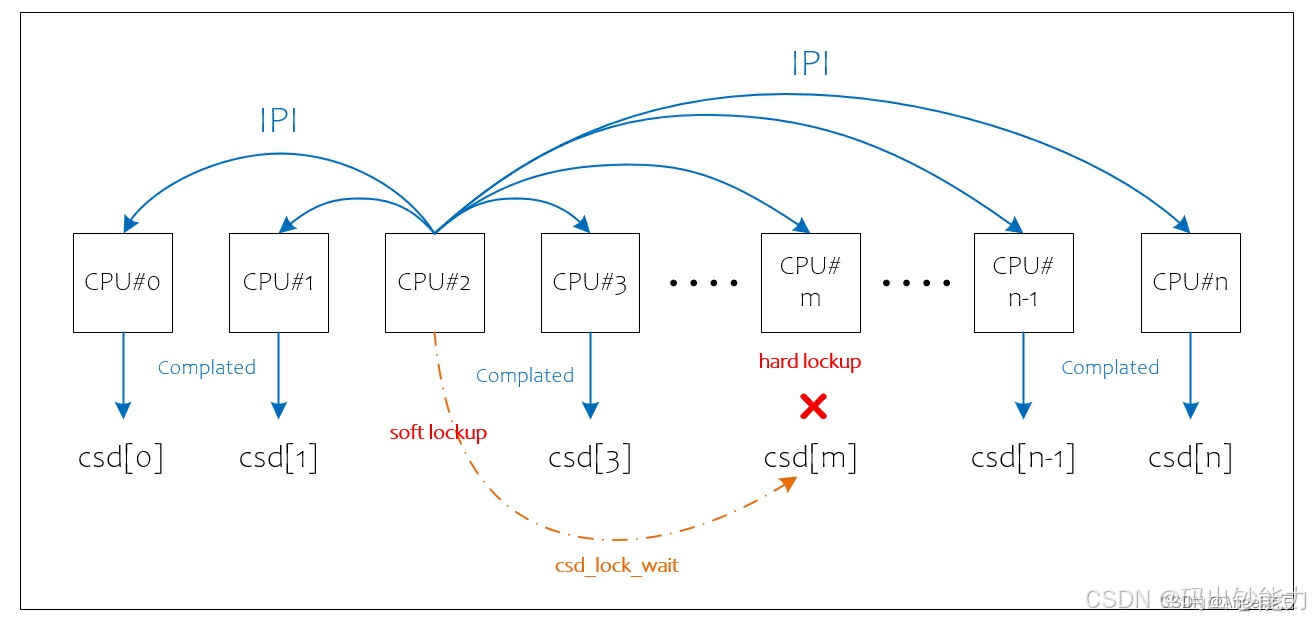
5.1 hard lockup
这里直接引用内核文档中的定义(在document\lockup-watchdog.txt文件中),“hardlockup 被定义为导致 CPU 在内核模式下循环超过 10 秒的错误,而不让其他中断有机会运行”。这个定义和上面现象分析中的描述是一致的。
为了分析问题的根源,我们要捕获hard lockup现场,就是当发生hard lockup时触发内核panic,从而进入kdump捕获内核crash。通常内核启动配置是没有对hard lockup进行捕获,有两种方式配置hard lockup捕获。
通过添加内核启动参数:nmi_watchdog=panic
通过设置sysctl参数,/usr/lib/sysctl.d:hardlockup_panic=1
同时还可以通过调整sysctl参数中的watchdog_thresh来控制lockup发生时间门限,默认是10秒。
我们选择了第二种方式,配置好sysctl参数,开启kdump服务,重启系统生效。接下来就是继续复现问题了,好在该问题能较高概率的复现,很快hard lockup出现成功触发kernel crash。于是新的错误信息在crash的日志文件(vmcore-dmesg.txt)中被发现了:
[ 303.896370] NMI watchdog: Watchdog detected hard LOCKUP on cpu 7\x01d
[ 303.896371] CPU: 7 PID: 1 Comm: systemd Tainted: G O 4.9.25-27.el7.1.x86_64 #56
[ 303.896371] Hardware name: Default string Default string/Default string, BIOS V131 10/15/2020
[ 303.896372] task: ffff880fb25c0000 task.stack: ffffc90000034000
[ 303.896372] RIP: 0010:[<ffffffff818445f0>] \x01c [<ffffffff818445f0>] int3+0x0/0x60
[ 303.896373] RSP: 0018:ffff880fbe7c7fd8 EFLAGS: 00000082
[ 303.896373] RAX: 0000000000000000 RBX: 0000000000000002 RCX: 00000000000003e8
[ 303.896373] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
[ 303.896374] RBP: ffffc90000037aa0 R08: 0000000000000000 R09: 0000000000000001
[ 303.896374] R10: 0000000000000002 R11: 000055bbcf553274 R12: ffff880fffff8700
[ 303.896374] R13: 00000000025106c0 R14: ffff880fba007400 R15: ffff880fba000d40
[ 303.896375] FS: 00007fb6229d8940(0000) GS:ffff880fbe7c0000(0000) knlGS:0000000000000000
[ 303.896375] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 303.896376] CR2: 000055bbcf5d44b0 CR3: 0000000f9a56d000 CR4: 00000000007406e0
[ 303.896376] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 303.896376] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[ 303.896376] PKRU: 55555554
[ 303.896377] Stack:
[ 303.896377] ffffffff81190033\x01c 0000000000000010\x01c 0000000000000082\x01c ffffc900000379e0\x01c
[ 303.896377] 0000000000000018\x01c
[ 303.896378] Call Trace:
[ 303.896378] <#DB> \x01d [<ffffffff81190033>] ? ___slab_alloc+0x2f3/0x4c0
[ 303.896378] <EOE> \x01d [<ffffffff816d28fe>] ? __alloc_skb+0x7e/0x280
[ 303.896379] [<ffffffff81087070>] ? check_preempt_curr+0x70/0x90
[ 303.896379] [<ffffffff8119871d>] ? __slab_alloc+0x12/0x17
[ 303.896380] [<ffffffff811937af>] ? __kmalloc_node_track_caller+0xbf/0x200
[ 303.896380] [<ffffffff816d28fe>] ? __alloc_skb+0x7e/0x280
[ 303.896380] [<ffffffff816d0be1>] ? __kmalloc_reserve.isra.38+0x31/0x90
[ 303.896381] [<ffffffff816d28ce>] ? __alloc_skb+0x4e/0x280
[ 303.896381] [<ffffffff816d28fe>] ? __alloc_skb+0x7e/0x280
[ 303.896381] [<ffffffff816d2b5a>] ? alloc_skb_with_frags+0x5a/0x1c0
[ 303.896382] [<ffffffff816ce00e>] ? sock_alloc_send_pskb+0x19e/0x200
[ 303.896382] [<ffffffff817ae0e5>] ? wait_for_unix_gc+0x35/0x90
[ 303.896382] [<ffffffff817ab7ac>] ? unix_stream_sendmsg+0x25c/0x3a0
[ 303.896383] [<ffffffff816c97c8>] ? sock_sendmsg+0x38/0x50
[ 303.896383] [<ffffffff816ca09c>] ? ___sys_sendmsg+0x26c/0x280
[ 303.896383] [<ffffffff811387f1>] ? unlock_page+0x31/0x40
[ 303.896384] [<ffffffff811657e5>] ? do_wp_page+0x125/0x680
[ 303.896384] [<ffffffff81168334>] ? handle_mm_fault+0x534/0xaf0
[ 303.896384] [<ffffffff816ca945>] ? __sys_sendmsg+0x45/0x80
[ 303.896385] [<ffffffff816ca992>] ? SyS_sendmsg+0x12/0x20
[ 303.896385] [<ffffffff818436e0>] ? entry_SYSCALL_64_fastpath+0x13/0x94
[ 303.896386] Code: \x01c50 \x01c01 \x01c00 \x01c00 \x01c10 \x01c00 \x01c00
[ 303.896386] Kernel panic - not syncing: Hard LOCKUP
[ 303.896387] CPU: 7 PID: 1 Comm: systemd Tainted: G O 4.9.25-27.el7.1.x86_64 #56
[ 303.896387] Hardware name: Default string Default string/Default string, BIOS V131 10/15/2020
[ 303.896388] ffff880fbe7c5b68\x01c ffffffff8145a666\x01c ffff880fb1230000\x01c ffffffff81c7d4cc\x01c
[ 303.896388] ffff880fbe7c5be0\x01c ffffffff811365ef\x01c ffff880f00000010\x01c ffff880fbe7c5bf0\x01c
[ 303.896388] ffff880fbe7c5b90\x01c 0000000000000000\x01c ffffffff81c52721\x01c 0000000000000007\x01c
[ 303.896389] Call Trace:
[ 303.896389] <NMI> [<ffffffff8145a666>] dump_stack+0x4d/0x67
[ 303.896389] [<ffffffff811365ef>] panic+0xd5/0x21d
[ 303.896390] [<ffffffff8105db2f>] nmi_panic+0x3f/0x40
[ 303.896390] [<ffffffff810f6344>] watchdog_overflow_callback+0xf4/0x100
[ 303.896390] [<ffffffff81128d4f>] __perf_event_overflow+0x7f/0x1b0
[ 303.896391] [<ffffffff81132954>] perf_event_overflow+0x14/0x20
[ 303.896391] [<ffffffff8100a97b>] intel_pmu_handle_irq+0x1db/0x500
[ 303.896391] [<ffffffff8100445d>] perf_event_nmi_handler+0x2d/0x50
[ 303.896392] [<ffffffff8101fecd>] nmi_handle+0x6d/0x130
[ 303.896392] [<ffffffff81020454>] default_do_nmi+0x44/0x120
[ 303.896392] [<ffffffff8102060d>] do_nmi+0xdd/0x140
[ 303.896393] [<ffffffff81844a07>] end_repeat_nmi+0x1a/0x1e
[ 303.896393] [<ffffffff818445f0>] ? debug+0x60/0x60
[ 303.896393] [<ffffffff818445f0>] ? debug+0x60/0x60
[ 303.896394] [<ffffffff818445f0>] ? debug+0x60/0x60
[ 303.896394] <EOE> <#DB> [<ffffffff81190033>] ? ___slab_alloc+0x2f3/0x4c0
[ 303.896394] <EOE> [<ffffffff816d28fe>] ? __alloc_skb+0x7e/0x280
[ 303.896395] [<ffffffff81087070>] ? check_preempt_curr+0x70/0x90
[ 303.896395] [<ffffffff8119871d>] __slab_alloc+0x12/0x17
[ 303.896395] [<ffffffff811937af>] __kmalloc_node_track_caller+0xbf/0x200
[ 303.896396] [<ffffffff816d28fe>] ? __alloc_skb+0x7e/0x280
[ 303.896396] [<ffffffff816d0be1>] __kmalloc_reserve.isra.38+0x31/0x90
[ 303.896396] [<ffffffff816d28ce>] ? __alloc_skb+0x4e/0x280
[ 303.896397] [<ffffffff816d28fe>] __alloc_skb+0x7e/0x280
[ 303.896397] [<ffffffff816d2b5a>] alloc_skb_with_frags+0x5a/0x1c0
[ 303.896397] [<ffffffff816ce00e>] sock_alloc_send_pskb+0x19e/0x200
[ 303.896398] [<ffffffff817ae0e5>] ? wait_for_unix_gc+0x35/0x90
[ 303.896398] [<ffffffff817ab7ac>] unix_stream_sendmsg+0x25c/0x3a0
[ 303.896398] [<ffffffff816c97c8>] sock_sendmsg+0x38/0x50
[ 303.896399] [<ffffffff816ca09c>] ___sys_sendmsg+0x26c/0x280
[ 303.896399] [<ffffffff811387f1>] ? unlock_page+0x31/0x40
[ 303.896399] [<ffffffff811657e5>] ? do_wp_page+0x125/0x680
[ 303.896400] [<ffffffff81168334>] ? handle_mm_fault+0x534/0xaf0
[ 303.896400] [<ffffffff816ca945>] __sys_sendmsg+0x45/0x80
[ 303.896400] [<ffffffff816ca992>] SyS_sendmsg+0x12/0x20
[ 303.896401] [<ffffffff818436e0>] entry_SYSCALL_64_fastpath+0x13/0x94
6.crash信息分析
能够捕获到crash,且信息中明确的出现了NMI watchdog: Watchdog detected hard LOCKUP on cpu 7,证明了之前的判断是正确的。只是这次的hard lockup发生在了CPU#7。使用crash命令可以给我提供更多有用的信息。首先就来看看这次hard lockup发生的back trace和发生的代码位置:
# crash vmcore vmlinux
crash> bt
PID: 1 TASK: ffff880fb25c0000 CPU: 7 COMMAND: "systemd"
#0 [ffff880fbe7c5a58] machine_kexec at ffffffff810469f5
#1 [ffff880fbe7c5aa8] __crash_kexec at ffffffff810d5e93
#2 [ffff880fbe7c5b70] panic at ffffffff811365ff
#3 [ffff880fbe7c5be8] nmi_panic at ffffffff8105db2f
#4 [ffff880fbe7c5bf8] watchdog_overflow_callback at ffffffff810f6344
#5 [ffff880fbe7c5c10] __perf_event_overflow at ffffffff81128d4f
#6 [ffff880fbe7c5c48] perf_event_overflow at ffffffff81132954
#7 [ffff880fbe7c5c58] intel_pmu_handle_irq at ffffffff8100a97b
#8 [ffff880fbe7c5e38] perf_event_nmi_handler at ffffffff8100445d
#9 [ffff880fbe7c5e58] nmi_handle at ffffffff8101fecd
#10 [ffff880fbe7c5eb0] default_do_nmi at ffffffff81020454
#11 [ffff880fbe7c5ed0] do_nmi at ffffffff8102060d
#12 [ffff880fbe7c5ef0] end_repeat_nmi at ffffffff81844a07
[exception RIP: int3]
RIP: ffffffff818445f0 RSP: ffff880fbe7c7fd8 RFLAGS: 00000082
RAX: 0000000000000000 RBX: 0000000000000002 RCX: 00000000000003e8
RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
RBP: ffffc90000037aa0 R8: 0000000000000000 R9: 0000000000000001
R10: 0000000000000002 R11: 000055bbcf553274 R12: ffff880fffff8700
R13: 00000000025106c0 R14: ffff880fba007400 R15: ffff880fba000d40
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
--- <NMI exception stack> ---
#13 [ffff880fbe7c7fd8] int3 at ffffffff818445f0
[exception RIP: ___slab_alloc+0x2f3]
RIP: ffffffff81190033 RSP: ffffc900000379e0 RFLAGS: 00000082
RAX: ffff880fffff8720 RBX: 0000000000000002 RCX: 00000000000003e8
RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
RBP: ffffc90000037aa0 R8: 0000000000000000 R9: 0000000000000001
R10: 0000000000000002 R11: 000055bbcf553274 R12: ffff880fffff8720
R13: 00000000025106c0 R14: ffff880fba007400 R15: ffff880fba000d40
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
--- <DEBUG exception stack> ---
#14 [ffffc900000379e0] ___slab_alloc at ffffffff81190033
#15 [ffffc90000037aa8] __slab_alloc at ffffffff8119871d
#16 [ffffc90000037ac0] __kmalloc_node_track_caller at ffffffff811937af
#17 [ffffc90000037b10] __kmalloc_reserve at ffffffff816d0be1
#18 [ffffc90000037b50] __alloc_skb at ffffffff816d28fe
#19 [ffffc90000037b98] alloc_skb_with_frags at ffffffff816d2b5a
从back trace中可以看到出错的代码位置为:
[exception RIP: ___slab_alloc+0x2f3]
这里___slab_alloc+0x2f3是内核中slub中的代码,可以在内核文件mm\slub.c中找到。看到这里一个更大的问题就浮现出来,然道说内核slub分配器有BUG?如果真的有错误什么情况下会触发呢?
7.阶段小结
通过对现场信息和现象的综合分析,判断了问题的进一步根源在于hard lockup,并捕获hard lockup的crash得到了slub分配器中出现了问题。这里可以得到一个经验:如果出现smp_call_function_many的soft lockup,可以考虑是由于hard lockup引起的,通过捕获hard lockup就可以确定真实的死锁原因了。在大部分情况下,通过获取hard lockup的crash信息基本上可以确定真实的死锁原因。在这个问题中为什么是在slub中发生了死锁呢?有机会再写后续篇将结合slub的分配器的整体原理和crash信息分析,进一步摸索这个hard lockup发生的原因。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.youkuaiyun.com/willhq/article/details/124897053


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









