






 本文详细介绍Hadoop集群的搭建过程,包括设置主机名、SSH免密登录、JDK及Hadoop安装步骤,并针对HDFS和YARN配置进行了具体说明。此外还介绍了HBase的安装配置方法。
本文详细介绍Hadoop集群的搭建过程,包括设置主机名、SSH免密登录、JDK及Hadoop安装步骤,并针对HDFS和YARN配置进行了具体说明。此外还介绍了HBase的安装配置方法。
1、设置主机名
sudo vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop007sudo hostnamectl set-hostname hadoop0072、设置免密
生成秘钥:
ssh-keygen -t rsa cd ~/.ssh/
cat id_rsa.pub >>authorized_keys
然后cat id_rsa.pub 内容 到主节点 authorized_keys,,同时主节点的cat id_rsa.pub 到新增节点的 authorized_keys,然后分发主节点的 authorized_keys到集群的其他几台机器。
3、jdk 安装
一般从其他节点copy压缩包,然后解压到/opt/server/jdk1.8.0_331/
然后cd /usr/java/
sudo ln -s /opt/server/jdk1.8.0_331/ jdk1.8.0_331
设置java 环境变量 vi /etc/profile.d/java.sh
export JAVA_HOME=/usr/java/jdk1.8.0_331
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
source /etc/profile 使环境变量生效
java -version
java version "1.8.0_331"
Java(TM) SE Runtime Environment (build 1.8.0_331-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.331-b09, mixed mode)
3、安装hadoop
1)从其他datanode节点copy hadoop,hbase 目录
2)配置文件修改
配置文件路径 /home/hadoop/hadoop/etc/hadoop/
hdfs-site.xml 改为硬盘比较大的分区路径
<property>
<name>dfs.data.dir</name>
<value>/opt/data/hdfs/dn</value>
</property>
yarn-site.xml 调整内存与核心数
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>174080</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
3)设置hadoop环境变量。
vi /etc/profile.d/hadoop.sh
# set hadoop path
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
# set hbase path
export HBASE_HOME=/home/hadoop/hbase
export PATH=$PATH:$HBASE_HOME/bin
# set hive path
export HIVE_HOME=/home/hadoop/hive
export PATH=$PATH:$HIVE_HOME/bin
#set sqoop path
export SQOOP_HOME=/home/hadoop/sqoop1
export PATH=$PATH:$SQOOP_HOME/bin
export SBIN_HOME=/home/hadoop/hadoop/sbin
export PATH=$PATH:$SBIN_HOME
# set mahout path
export MAHOUT_HOME=/home/hadoop/mahout
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
# set maven path
#export M2_HOME=/home/hadoop/maven
#export PATH=$M2_HOME/bin:$PATH
# set kylin path
export KYLIN_HOME=/home/hadoop/kylin
export PATH=$KYLIN_HOME/bin:$PATH
#set java
#export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# set history time
export HISTTIMEFORMAT="%F %T `whoami` "
4)主节点slaves 添加 新增节点的主机名:hadoop007
然后分发到集群所有节点
查看进程并查看日志
4、启动hdfs yarn
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanger
查看进程并查看日志
有错误日志如下:
2022-07-01 00:10:50,622 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-585357159-10.0.0.153-1427075743287 (Datanode Uuid 3cb9deed-b682-41fa-b005-2ea5003a2893) service to hd.m1/10.0.0.123:8020 Datanode denied communication with namenode because the host is not in the include-list: DatanodeRegistration(10.0.0.154, datanodeUuid=3cb9deed-b682-41fa-b005-2ea5003a2893, infoPort=50075, ipcPort=50020, storageInfo=lv=-56;cid=CID-9bf6c3f9-da79-41f1-b511-88b6c8de3db4;nsid=119689889;c=0)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:896)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:4836)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:1038)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:92)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:26378)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:587)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1026)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)
5、在主节点刷新节点
hdfs dfsadmin -refreshNodes
standby节点 hdfs dfsadmin -fs hdfs://xx.xxx.x.xxx:8020 -refreshNodes 其中hdfs://xx.xxx.x.xxx:8020 为staandby节点的ip或者主机名
然后可以在页面查看新增的节点已经显示
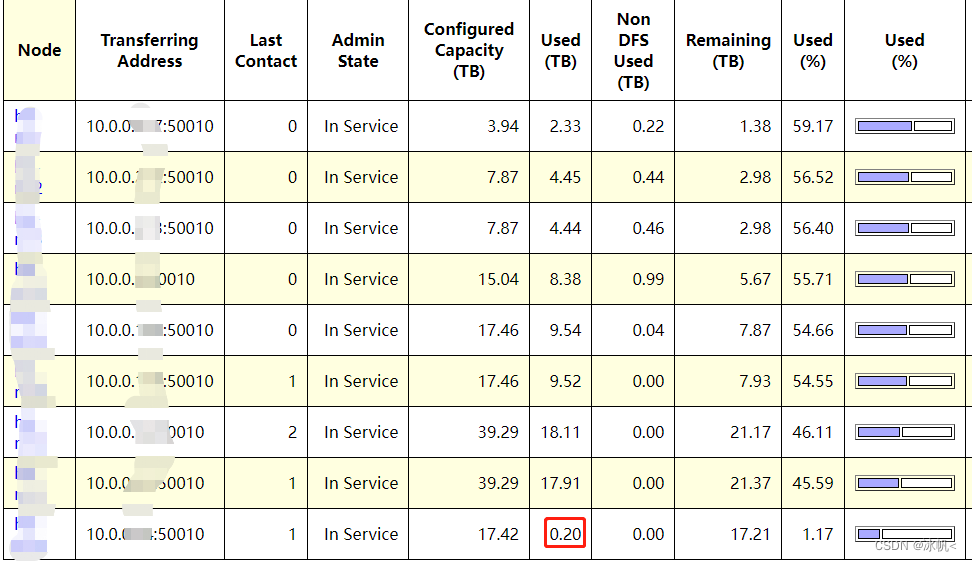
6.在主节点启动
./start-balancer.sh -threshold 5
让其慢慢均衡即可
7、hbase 安装
修改hbase-site.xml 从其他region节点copy 不需要修改
regionservers 文件添加新增的主机名 ,然后分发到其他的region和master节点
命令启动:hbase-daemon.sh start regionserver
查看进程jps : 存在 HRegionServer 表示ok
可以在hbase 页面上查看:
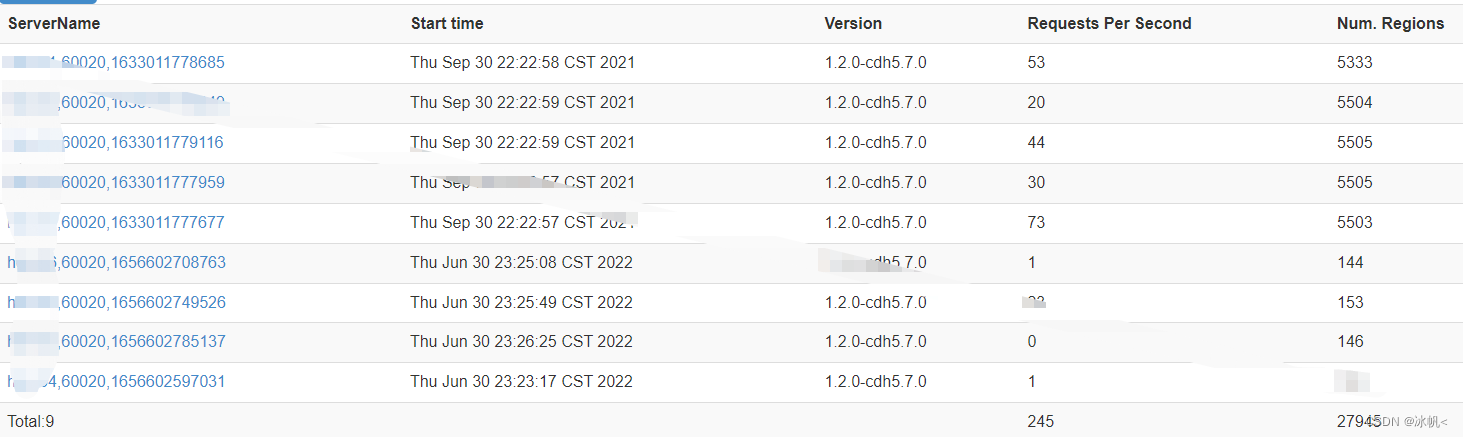
已全部显示。



















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











