应用层
http协议
http请求报文
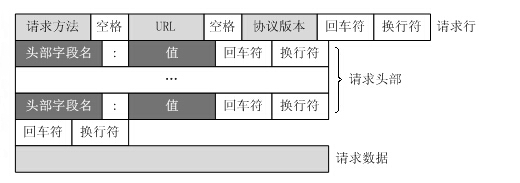
第一部分:请求行,用来说明请求类型(
POST
),要访问的资源以及所使用的
HTTP
版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息(
Content-Type
,字符集等等)。
第三部分:空行,请求头部后面的空行是必须的。
第四部分:请求数据也叫主体,可以添加任意的其他数据。
http响应报文
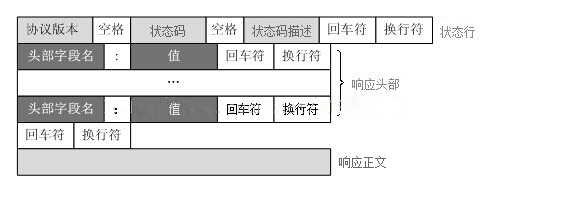
第一部分:状态行,由
HTTP
协议版本号,状态码,状态消息三部分组成。
第二部分:消息报头,用来说明客户端要使用的一些附加信息。
第三部分:空行,消息报头后面的空行是必须的。
第四部分:响应正文,服务器返回给客户端的文本信息。
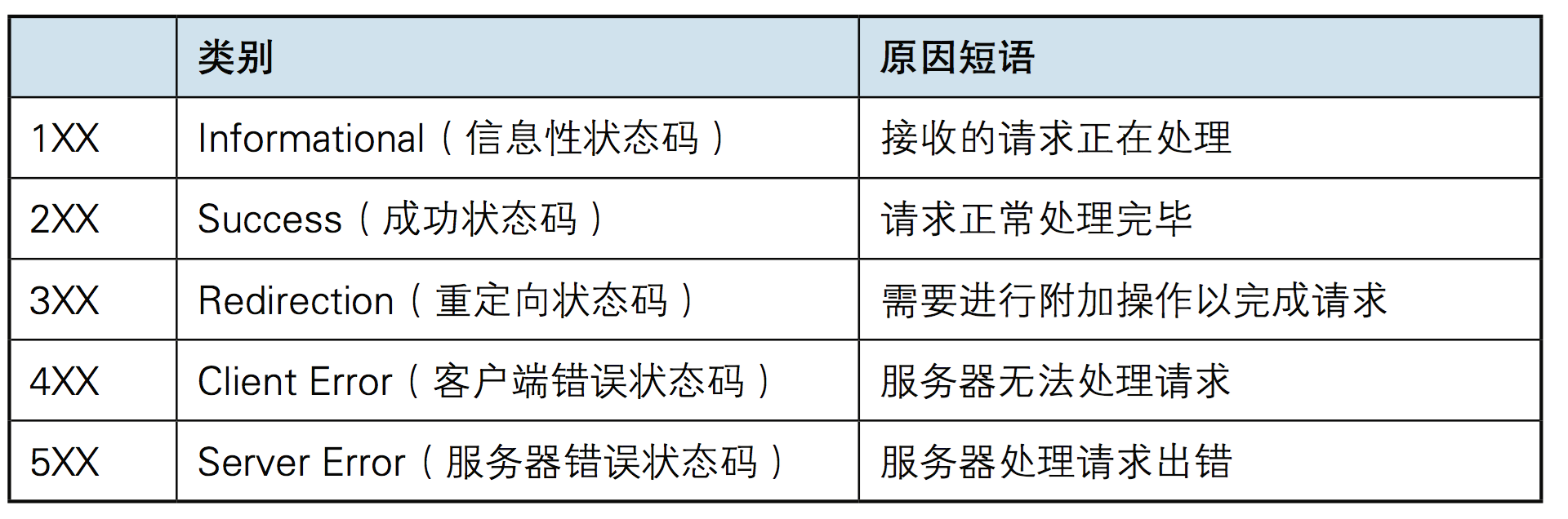
http状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx
:指示信息
--
表示请求已接收,继续处理(某个操作的第一步,需配合第二步);
2xx
:成功
--
表示请求已被成功接收、理解、接受(第二步);
3xx
:重定向
--
要完成请求必须进行更进一步的操作;
4xx
:客户端错误
--
请求有语法错误或请求无法实现;
5xx
:服务器端错误
--
服务器未能实现合法的请求。
如果客户端发送了一个带条件的GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个304状态码。简单的表达就是:服务端已经执行了GET,但文件未变化。
http请求方法 post和get、Head
GET 向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD 与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
POST 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
1
:
GET
交互方式是从服务器上获取数据,而并非修改数据,所以
GET
交互方式是安全的。
2
:
POST
交互是可以修改服务器数据的一种方式,涉及到信息的修改,就会有安全问
题。
格式区别,处理方式区别,用途区别 ,安全性区别
get 参数通过
url
传递,
post
放在
request body
中。
get 请求在
url
中传递的参数是有长度限制的,而
post
没有。
get 比
post
更不安全,因为参数直接暴露在
url
中,所以不能用来传递敏感信
息。
1:
get
请求只能进行
url
编码,而
post
支持多种编码方式;
2
:
get
请求会浏览器
主动
cache
,而
post
支持多种编码方式。
3:
get
请求参数会被完整保留在浏览历
史记录里,而
post
中的参数不会被保留。
GET
和
POST
本质上就是
TCP
链接,并无差别。但是由于
HTTP
的规定和浏览
器
/
服务器的限制,导致他们在应用过程中体现出一些不同。
GET 产生一个
TCP
数据包;
POST
产生两个
TCP
数据包。
对于 GET
方式的请求,浏览器会把
http header
和
data
一并发送出去,服务器响应200
(返回数据);
而对于 POST
,浏览器先发送
header
,服务器响应
100 continue
,浏览器再发送data
,服务器响应
200 ok(返回数据)。
HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
1.协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
2.域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
3.端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
4.虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
5.文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
6.锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
7.参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
http1.0 http1.1 和http2.0
HTTP 1.0 需要使用 keep-alive 参数来告知服务器端要建立一个长连接,而 HTTP1.1 默认支持长连接。
HTTP 1.1 支持只发送
header
信息
(
不带任何
body
信息
)
,如果服务器认为客户端有权
限请求服务器,则返回 100
,否则返回
401
。客户端如果接受到
100
,才开始把请求 body
发送到服务器。
这样当服务器返回 401 的时候,客户端就可以不用发送请求 body 了,节约了带宽。另外 HTTP 还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。
HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。此外,服务器应该接受以绝对路径标记的资源请求。
参考资料:https://www.cnblogs.com/heluan/p/8620312.html
多路复用
HTTP2.0 使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比
HTTP1.1
大了好几个数量级。
数据压缩
HTTP1.1 不支持
header
数据的压缩,
HTTP2.0
使用
HPACK
算法对
header
的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
服务器推送
当我们对支持 HTTP2.0
的
web server
请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种 方式非常合适加载静态资源。
https
安全套接字层超文本传输协议
HTTPS
,为了数据传输的安全,
HTTPS
在
HTTP
的基础上加入了
SSL
协议,
SSL
依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信
加密。
HTTPS
和
HTTP
的区别主要如下:
(
1
)
HTTPS
协议需要到
CA
申请证书
,一般免费证书较少,因而需要一定费用。
(
2
)
HTTP
是超文本传输协议,信息是明文传输
,
HTTPS
则是具有安全性的
SSL
加密传输协议。
(
3
)
HTTP
和
HTTPS
使用的是完全不同的连接方式,用的端口不一样
,前者是
80
,后者是
443
。
session和cookie
Cookie
通过在客户端记录信息确定用户身份,
Session
通过在服务器端记录信息确定用户身份。
Cookie:
Cookie
实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户
状态,就使用
response
向客 户端浏览器颁发一个
Cookie
。客户端浏览器会把
Cookie
保存
起来。当浏览器再请求该网站时,浏览器把请求的网址连同该
Cookie
一同提交给服务器。
服务器检查该
Cookie
,以此来辨认用户状态。服务器还可以根据需要修改
Cookie
的内容。
Session
:
Session
是另一种记录客户状态的机制,不同的是
Cookie
保存在客户端浏览器中,而Session
保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形
式记录在服务器上。这就是
Session
。客户端浏览器再次访问时只需要从该
Session
中查找
该客户的状态就可以了。
如果说 Cookie
机制是通过检查客户身上的
“
通行证
”
来确定客户身份的话,那么
Session
机制就是通过检查服务器上的
“
客户明细表
”
来确认客户身份。
Session
相当于程序在服务器
上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
一次完整的 http 请求
1.对 www.baidu.com 这个网址进行 DNS 域名解析,得到对应的 IP 地址
2.根据这个 IP,找到对应的服务器,发起 TCP 的三次握手
3.建立 TCP 连接后发起 HTTP 请求
4.服务器响应 HTTP 请求,浏览器得到 html 代码
5.浏览器解析 html 代码,并请求 html 代码中的资源(如 js、css 图片等)(先得到 html 代码,才能去找这些资源)
6.浏览器对页面进行渲染呈现给用户
http协议的幂等性
在HTTP/1.1规范中幂等性的定义是:
Methods can also have the property of "idempotence" in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
从定义上看,HTTP方法的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。幂等性属于语义范畴,正如编译器只能帮助检查语法错误一样,HTTP规范也没有办法通过消息格式等语法手段来定义它,这可能是它不太受到重视的原因之一。但实际上,幂等性是分布式系统设计中十分重要的概念,而HTTP的分布式本质也决定了它在HTTP中具有重要地位。
幂等性原本是数学上的概念,即使公式:f(x)=f(f(x)),表达的是N次变换与1次变换的结果相同





 本文深入解析HTTP协议的工作原理,包括请求与响应过程、状态码含义、GET与POST方法的区别,以及HTTP1.0到HTTP2.0的演进。同时探讨了HTTPS的安全机制,对比HTTP与HTTPS的不同之处,最后讲解了Session和Cookie的使用场景与区别。
本文深入解析HTTP协议的工作原理,包括请求与响应过程、状态码含义、GET与POST方法的区别,以及HTTP1.0到HTTP2.0的演进。同时探讨了HTTPS的安全机制,对比HTTP与HTTPS的不同之处,最后讲解了Session和Cookie的使用场景与区别。

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









