




zlib 官方发布了多个补丁版本,以下是一些常见漏洞的补丁情况:
- CVE-2018-250321:
- 在该漏洞被发现后,官方发布了 zlib 1.2.12 版本来修复此漏洞。这个漏洞存在于 zlib 1.2.12 之前的版本中,如果输入数据经过特殊构造,在解压时可能会导致内存损坏,使应用程序崩溃。建议用户和开发者尽快更新到 zlib 1.2.12 或更高版本。
- CVE-2022-37434:
- 针对此漏洞,官方也发布了相应的补丁。该漏洞存在于 zlib 1.2.12 及之前的版本中,在特定情况下会出现基于堆的缓冲区越界读或缓冲区溢出问题。只有调用
inflategetheader的应用程序会受到影响。官方对该漏洞进行修复后,用户应及时更新 zlib 库以避免受到攻击。
- 针对此漏洞,官方也发布了相应的补丁。该漏洞存在于 zlib 1.2.12 及之前的版本中,在特定情况下会出现基于堆的缓冲区越界读或缓冲区溢出问题。只有调用
- CVE-2023-458535:
- 对于 zlib 库版本 1.3 中的
minizip组件存在的整数溢出和基于堆的缓冲区溢出漏洞,官方对其进行了修复。该漏洞是在minizip打开新文件时,对文件名、注释或额外字段的长度验证不严格导致的。受影响的项目如pyminizip等也需要及时更新以修复该漏洞。
- 对于 zlib 库版本 1.3 中的
总体而言,为了确保系统的安全和稳定,使用 zlib 库的用户和开发者应密切关注官方发布的漏洞信息,并及时更新到最新的、修复了已知漏洞的版本。
#include <iostream>
#include "/qt/3.3.6/src/3rdparty/zlib/zlib.h"
#define zlib_version zlibVersion()
#include <qapplication.h>
#include <iostream>
#include <cstring>
// 检查字符串是否为有效的UTF-8编码
bool isValidUTF8(const std::string& str) {
int num_bytes_to_check = 0;
for (size_t i = 0; i < str.size(); ++i) {
unsigned char c = (unsigned char)str[i];
if (num_bytes_to_check == 0) {
if (c >> 7 == 0) {
continue;
}
else if ((c >> 5) == 0x6) {
num_bytes_to_check = 1;
}
else if ((c >> 4) == 0xE) {
num_bytes_to_check = 2;
}
else if ((c >> 3) == 0x1E) {
num_bytes_to_check = 3;
}
else {
return false;
}
}
else {
if ((c >> 6) != 0x2) {
return false;
}
--num_bytes_to_check;
}
}
return num_bytes_to_check == 0;
}
// 将字符串规范化为标准的UTF-8编码(这里简单示例,实际可能更复杂)
std::string normalizeUTF8(const std::string& str) {
// 这里暂时直接返回原字符串,实际可能需要进行真正的规范化操作,比如处理非法编码字符等
return str;
}
// 将解压后的字节数据转换为UTF-8编码的字符串
std::string bytesToUTF8String(Bytef* data, uLongf size) {
return std::string((char*)data, size);
}
int main() {
// 原始测试数据,假设为UTF-8编码的字符串
std::string input = "This is a test string for zlib in C++.";
// 打印zlib版本信息
std::cout << "Using zlib version: " << zlib_version << std::endl;
// 检查并规范化原始数据的UTF-8编码(实际应用中更严谨处理)
if (!isValidUTF8(input)) {
input = normalizeUTF8(input);
}
// 计算原始数据长度(以字节为单位)
uLongf originalLength = input.length();
// 估算压缩后数据的最大可能大小
uLongf compressed_size = compressBound(originalLength);
// 分配用于存储压缩数据的缓冲区
Bytef* compressed_data = new Bytef[compressed_size];
if (compressed_data == nullptr) {
std::cerr << "Failed to allocate memory for compressed data." << std::endl;
return -1;
}
// 对原始数据进行压缩
int compress_result = compress(compressed_data, &compressed_size, (const Bytef*)input.c_str(), originalLength);
if (compress_result != Z_OK) {
std::cerr << "Compression failed with error code: " << compress_result << std::endl;
delete[] compressed_data;
return -1;
}
std::cout << "Compression successful. Compressed size: " << compressed_size << std::endl;
// 分配用于存储解压后数据的缓冲区,初始化为0,避免残留脏数据
uLongf uncompressed_size = originalLength;
Bytef* uncompressed_data = new Bytef[uncompressed_size];
if (uncompressed_data == nullptr) {
std::cerr << "Failed to allocate memory for uncompressed data." << std::endl;
delete[] compressed_data;
return -1;
}
memset(uncompressed_data, 0, uncompressed_size);
// 对压缩数据进行解压
int uncompress_result = uncompress(uncompressed_data, &uncompressed_size, compressed_data, compressed_size);
if (uncompress_result != Z_OK) {
std::cerr << "Decompression failed with error code: " << uncompress_result << std::endl;
delete[] compressed_data;
delete[] uncompressed_data;
return -1;
}
// 将解压后的字节数据转换为UTF-8编码的字符串
std::string decompressedData = bytesToUTF8String(uncompressed_data, uncompressed_size);
// 比较解压后的数据和原始数据是否一致(比较UTF-8编码的字符串)
if (decompressedData == input) {
std::cout << "Decompression successful and data matches original." << std::endl;
}
else {
std::cout << "Decompression successful but data does not match original." << std::endl;
// 可以添加打印十六进制数据的代码,方便查看具体差异
std::cout << "Hexadecimal representation of uncompressed data: ";
for (size_t i = 0; i < decompressedData.length(); ++i) {
printf("%02x ", (unsigned char)decompressedData[i]);
}
std::cout << std::endl;
std::cout << "Hexadecimal representation of input: ";
for (size_t i = 0; i < input.length(); ++i) {
printf("%02x ", (unsigned char)input[i]);
}
std::cout << std::endl;
}
// 释放分配的内存空间
delete[] compressed_data;
delete[] uncompressed_data;
return 0;
}
执行后输出如下: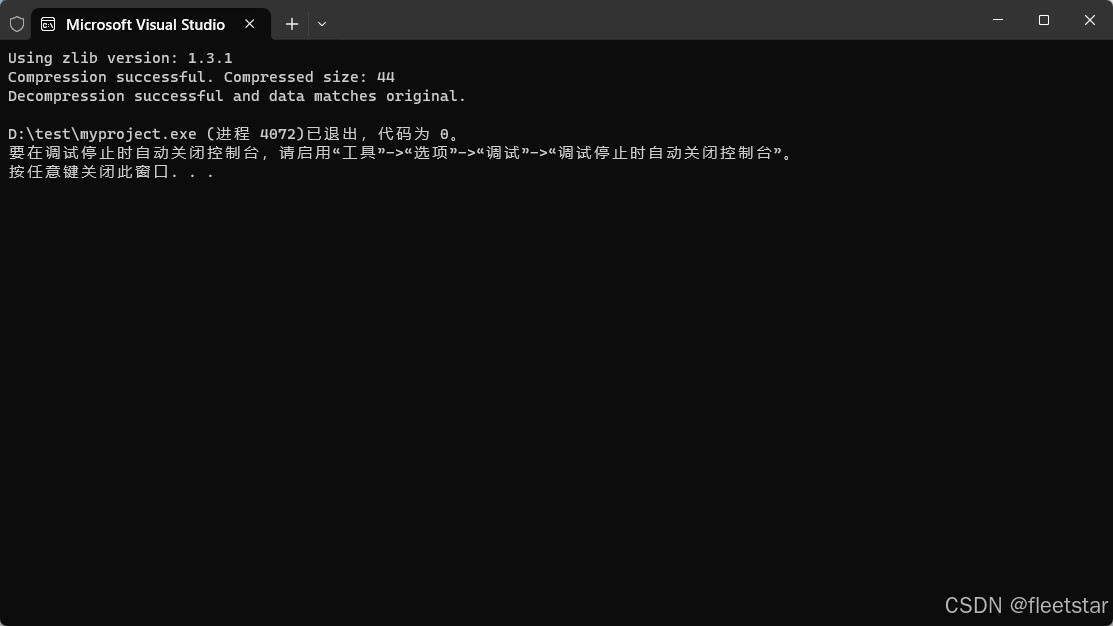


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









