



 本文分享了在Ubuntu和Windows环境下使用YoloV3进行目标检测模型训练的经验,包括配置环境、调整参数、解决常见问题及优化训练过程。
本文分享了在Ubuntu和Windows环境下使用YoloV3进行目标检测模型训练的经验,包括配置环境、调整参数、解决常见问题及优化训练过程。
数据集做好了以后,现在就要训练了,第一次因为没训练过看 都是GPU,我就VMWARE高了一下,废了很多的电费,发现几个小时过去了,训练了20次,果断半夜起来关了,NLP和GPU那么多大公司用GPU,太吃硬件了,体会到了,硬件加速的重要性
1.虚拟机: vmware14+ubuntu16.04
2.darknet :github 原版 AB版主要是WINDOWS训练
3 训练权重:darknet53.conv.74 这个需要下载
3.vs2015 社区版 注册就能用,不过安装过程4个小时,不知道为啥还是ISO的版,反正很少用 vs,
linux训练和windows训练主要流程是一样的:
LINUX版:
1.复制一个darknet中的yolov3.cfg文件改成自己的XX.CFG,主要是修改几部分:
1.注释掉test部分变成自己train部分
2. 修改每一个yolo模块的前一个卷积的 fitter: 变成自己的# 3*(classnum+5)-> 3*(10+5) =45,yolov3是 COCO 80 80 种 一共是255.
3.修改 classes =10 之前的是coco 的80类
2.cfg下面的xxx.data文件,网络训练的时候 知道的配置文件的位置
classes= 10
train = /home/flaty/darknet/train.txt
valid = /home/flaty/darknet/2019_test.txt
names = /home/flaty/darknet/data/nwpu.names
backup = backup
3. data下面的xxx.names文件,修改变成自己的类文件,这个不影响训练,影响训练测试,lable默认的就去显示别的了detect.c文件里面有 args的处理
4. 修改 Makefile文件,主要就是:
GPU=0 GPU执行训练或者测试
CUDNN=0 GPU对应的并行处理支持
OPENCV=0 这个我测试了一下,没有不影响训练,但是测试的时候不能显示窗体,目前没发现其他的作用,还有就是可以显示loss曲线,
OPENMP=0 CPU并行计算
DEBUG=0
./darknet detector test cfg/xxx.data cfg/yolov3-xxx.cfg backup/darknet53.conv.74 训练走起
我虚拟机除了CPU啥也没有,我没有单独安装OPENCV库就没有选择,DETECT.C需要阅读一下,知道各个参数,怎么回事以及便于出现错误的时候,可以初步的判断哪的问题,CFG文件的尺度,激活函数,损失函数等等问题,需要精雕细琢去学校理解的后续继续研究。虚拟机下基本上1个小时1次吧,,,,这个没100次会生成一个权重。
windos 版:
对于能够实现目标的预测,看windows也可以训练,就放心了,不然就放弃了,下载了AD版的darknetMaster,CUDA,CUDNN,OPENCV,着急得到数据集,就看了这个大神的,把linux下的复制过来 cfg data 权重文件弄过来就可以了
环境: CUDA 10.1 CUDNN 7.6 OPENCV3.4.0 (这个是必须的) vs2015
初步打开这个工程,里面乱的和“屎粑粑”一样,就是很多测试过的cfg,data,names文件很多很多。还有MAKEFILE文件,但是大神已经把这个工程弄好了VS的,包括CUDA,OPENCV的环境变量都好了,节省了很多的时间,
第1步,opencv解压到C盘底下名称改为c:\opencv_3.0里面 这原因就是工程里面的环境变量是这个路径,免得该工程了
第2步,安装CUDA CUDNN,这部分很多的文章是9.1 的 其实 这个地方关键的是 CUDA CUDNN GTX的显卡驱动必须是一个版本的,我们自己的电脑驱动 360早已经不断更新最新的了,我第一次用9.1发现 提示:CUDA: 参数错误。下载了最新的10.1就好了,CUDNN根据官网对应的是7.6的 FOR WIN7版,nvida下载速度还是可以的,比windows狗强太多了,CUDA默认安装好了以后,需要CUDNN的对应文件放到CUDA的 lib,include,bin,这部分还是为了满足 大神的工程。
第3步,进入build里面修改 一个vs工程配置文件vxproj的东西,主要是要修改cuda,之前的是9.1 搜索改为10.1,我还修改了一个地方,compute_61,sm_61 算力参数,我的是1060显卡是这个。
第4步, 打开darknet.sln,进入vs ,这个过程中,vs会根据安装环境生成项目,这个过程或许会下载更新一些模块,主要是大神用的小版本号和我们可能有区别吧,完成这个以后,就可以生成darknet.exe了
其他步骤和linux 一样,cfg,data,权重复制过来,包括数据集,放到对应的目录,这时候需要修改data和train.txt里面的文件,是因为文件系统不一样 绝对路径步一样,改成自己的就可以了。还有一个重点 数据集的 图片和lables里面的txt文件 要放在一个路径下面了,抽时间看一下detect.c这个文件 windows下最好路径都写成绝对路径 不然会出现找不到的问题,我遇到了。
训练中出现了 cuda:memory out的问题 主要就是cfg文件 里面batch 是64 sub是16,这样的话,显存训练到300多的时候就扛不住了,随着尺度的变换,溢出了, 半夜起来上厕所 发现停了,就赶紧度娘找问题,明白了,一次加载64个图片,分成16次算,然后合并,还是太大了,我就把SUB 变成64了,发现好了,就开始训练了,这个可以输出loss曲线图,如下:
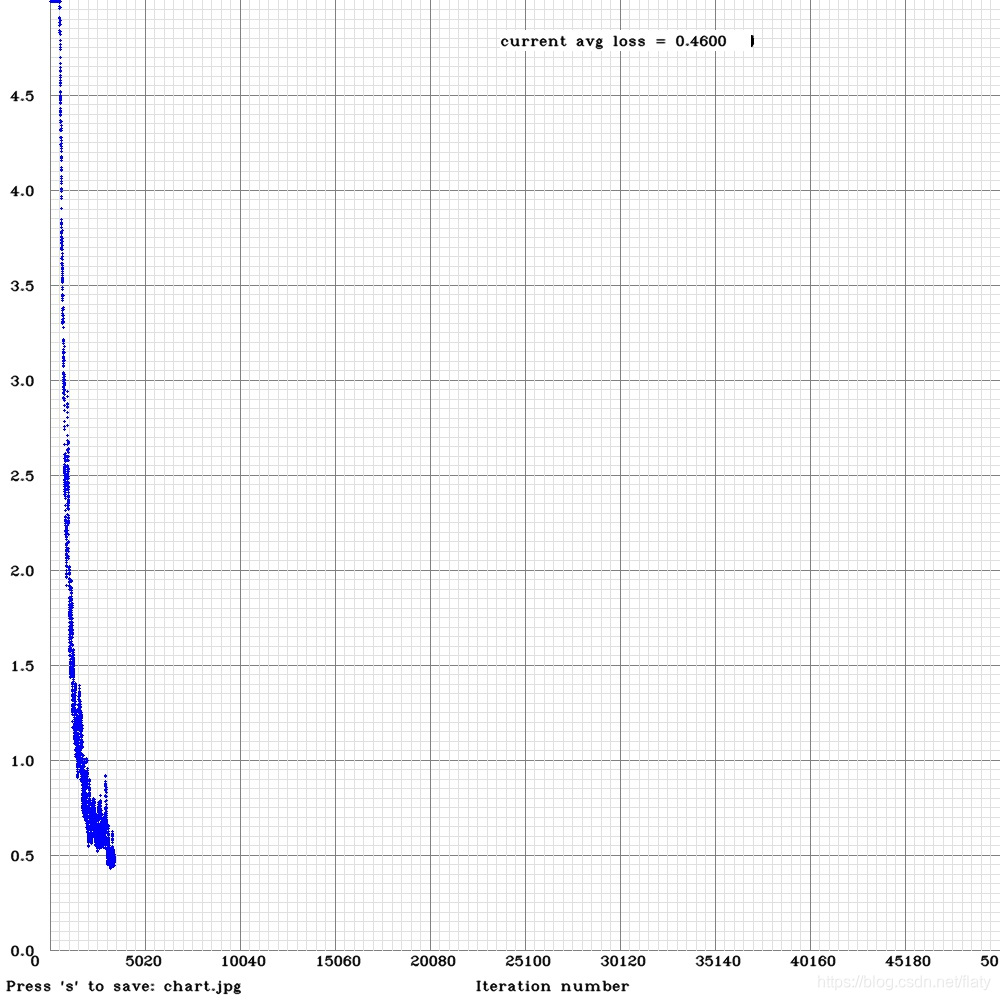
期初的时候 每一轮训练后的 AVG -LOSS 比较大,随着训练基本下来了,我这次训练了34000次,发现 出现很多NAN的时候,就停止了,测试了一下 2000的weigths的最理想,后面基本就飞了,不在收敛了,0.5左右就不收敛了,抽时间再训练一下,
测试了 在之前的OPENCV.DNN下也是可以用的,还不错。


















 4551
4551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









