



 本文详细解析了HTTP请求中的GET与POST方式的区别,包括数据提交方式、接收方式及适用场景,帮助理解何时选择哪种请求方式。
本文详细解析了HTTP请求中的GET与POST方式的区别,包括数据提交方式、接收方式及适用场景,帮助理解何时选择哪种请求方式。
我们知道浏览器向服务器发送数据的方式有两种,分别是Get请求和Post请求,那么这两种请求有什么区别么?我们什么时候用Get请求,什么时候用Post请求?
一. Get请求
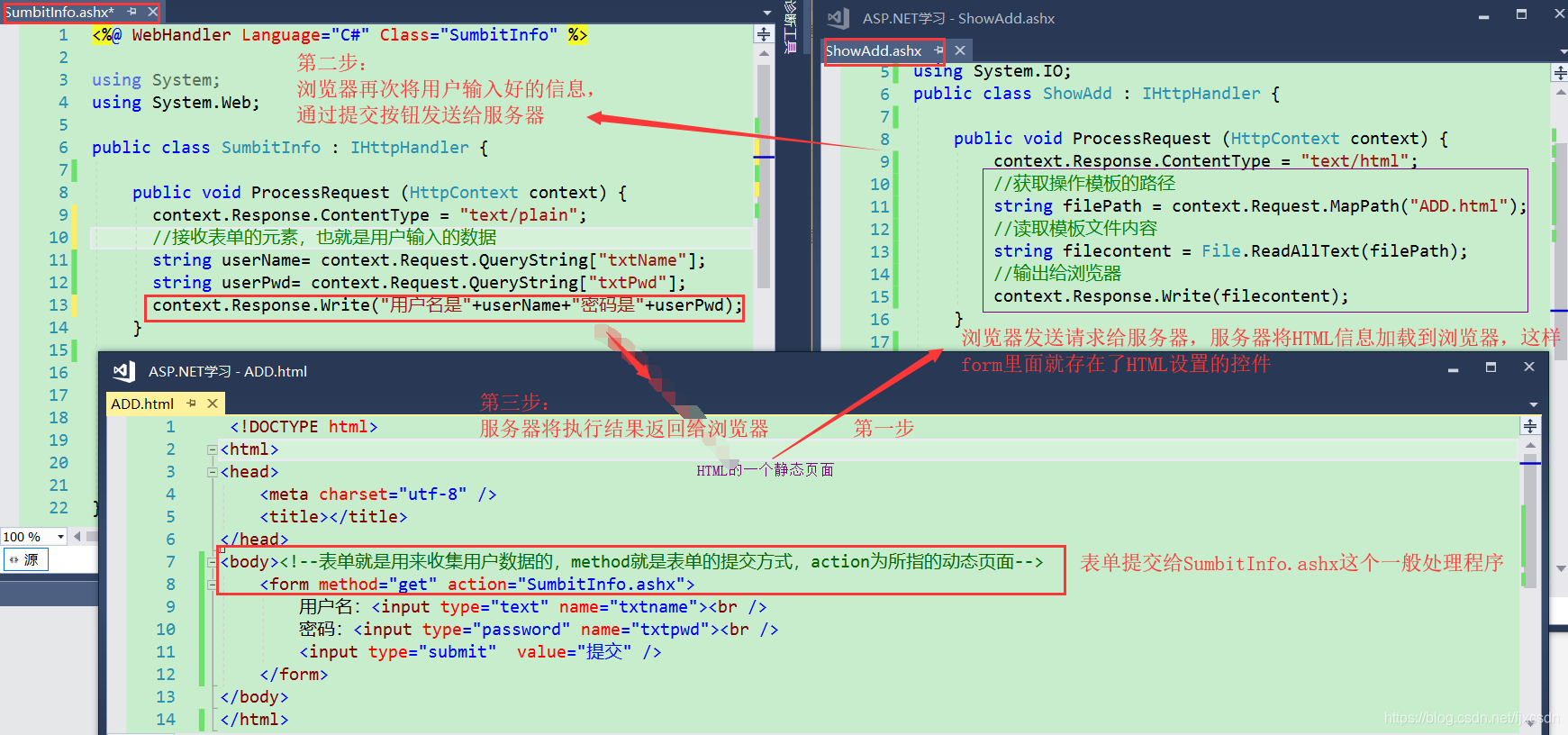
发现了什么?

二、Post方式提交
我们将HTML中的提交方式method="post" 地址栏发生了什么变化
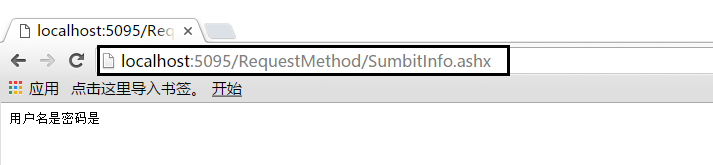
第一个疑点:地址栏中,用户输入的数据没有了?
第二个疑点:明明输入了数据,可是服务器并没有将数据返回浏览器,进一步说明服务器根本没有接收到用户输入的数据。
下图是接收数据用户输入的数据方式,说明通过该方式(QueryString)

当我们打开浏览器与服务器的传送的报文的时候,发现用户输入的信息在请求体中,也就是说Post 方式是通过请求体,发送给服务器的。——第一个疑点已经解决。
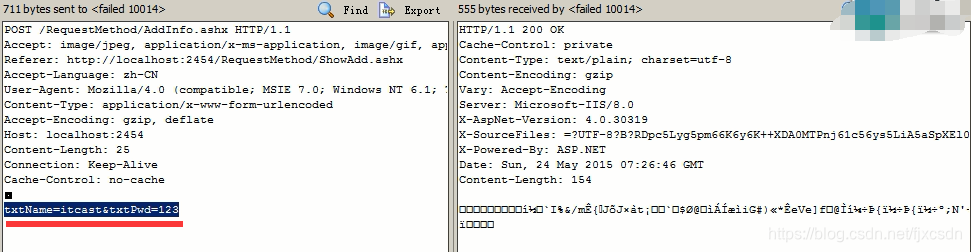
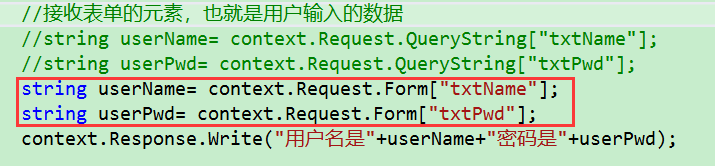
改变接收提交方式后,成功显示返回的信息,那么第二个疑问解决了,也就说明了Post方式接收用户数据方式使用的是Form

三、两者的区别
1.两者提交的方式
get方式使通过浏览器地址栏将数据提交给服务器的。
post方式使通过报文中的请求体发送给服务器的。
2.两者的接收方式
get请求是通过QueryString,接收用户输入的数据的
post 请求是通过Form,接收用户输入的数据的
3.综合考虑,什么时候用get请求,什么时候用Post请求?
1. 表单提交,提交用户个人信息,如果通过get方式提交,信息将全部显示信息栏,将泄露用户信息。
2.地址栏就是一个长方形的框,输入的信息是有限的,无法提交大量的信息。可见post方式会更加安全,提交数据的量更大。
分析,既然post那么好,为什么还用get请求呢?什么时候用呢?
我们搜索信息的时候用get请求比较好,例如我想查询一个特定东西,并且分享给大家,当看到地址栏里面的信息的时候,很容易辨别地址栏中的信息内容。也有利于网站的推广。
直接在地址栏输入网址信息、点击超链接都属于get请求,只有表单的提交,这种比较私密的信息,采用post请求。
关于两种请求方式就先分享到这里,如果本篇博客对您有所帮助,记得点赞哦!

















 1422
1422










 到【灌水乐园】发言
到【灌水乐园】发言







