




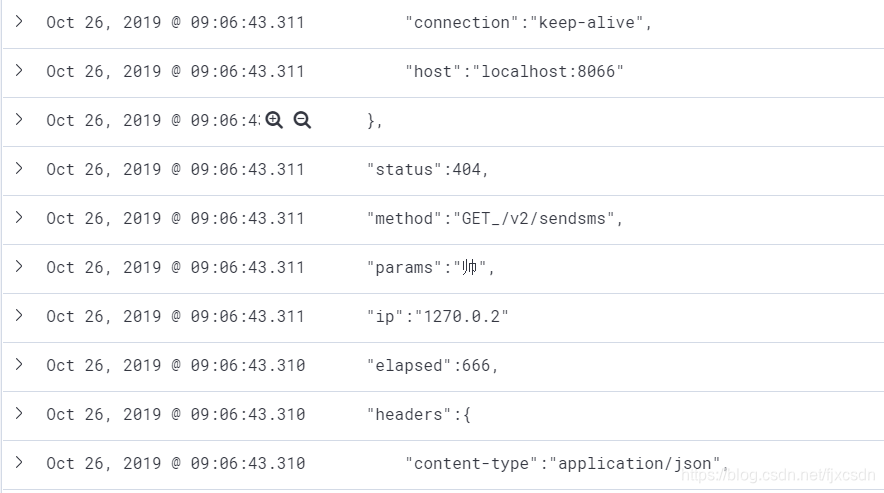
问题描述:filebeat推送一个json对象到es中,一个json对象被拆分了多个对象。在kibana中显示如下图所示:
解决过程:
① 首先判断自己的json对象是否有效(https://www.json.cn/)
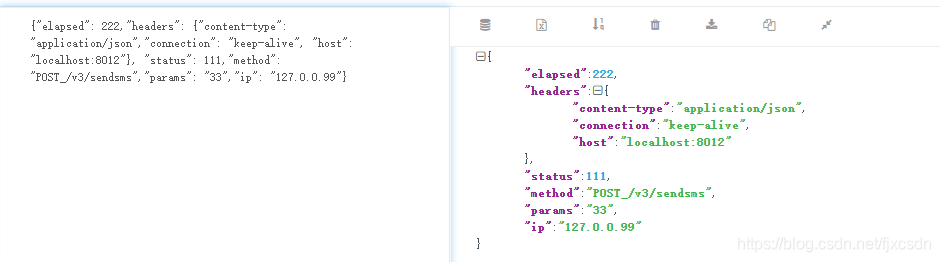
②查看filebeat的拿取json数据的格式(如果是下图多行的形式,在es中会将每一行都看成一个json对象,在kibana中显示的也将是多个json对象)

③将一个json对象写在一行,避免上面的日志结构形式

在kibana中显示效果
 本文介绍了在使用Filebeat将JSON对象推送到ES时遇到的问题,即JSON对象被拆分为多个独立对象。通过验证JSON有效性、检查Filebeat获取数据的格式,发现原因是JSON对象分布在多行。解决方案是确保每个JSON对象占用一行,以确保ES能正确建立索引。
本文介绍了在使用Filebeat将JSON对象推送到ES时遇到的问题,即JSON对象被拆分为多个独立对象。通过验证JSON有效性、检查Filebeat获取数据的格式,发现原因是JSON对象分布在多行。解决方案是确保每个JSON对象占用一行,以确保ES能正确建立索引。
问题描述:filebeat推送一个json对象到es中,一个json对象被拆分了多个对象。在kibana中显示如下图所示:
解决过程:
① 首先判断自己的json对象是否有效(https://www.json.cn/)
②查看filebeat的拿取json数据的格式(如果是下图多行的形式,在es中会将每一行都看成一个json对象,在kibana中显示的也将是多个json对象)
③将一个json对象写在一行,避免上面的日志结构形式
在kibana中显示效果
 3005
6131
3005
6131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























