




上篇文章安装了Crawlab,现在开始使用。
0.6.0beta目前有问题,建议稳定版出了再用,所以本文用截止发布文章时的最新稳定版0.5.1。
本文最核心的内容在文档-SDK-Python和文档-爬虫集成中,即配置scrapy爬虫和单个py文件爬虫所需的设置。
先说一下,如果在Crawlab中运行爬虫时提示没有库,看文档。
scrapy爬虫
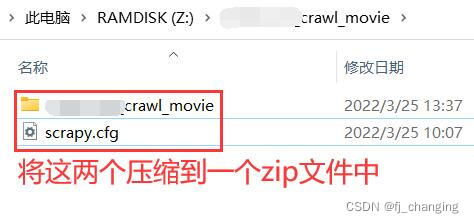
将上图压缩后的zip文件上传,上传时开启是否为Scrapy。另外,上传时有提示要从根目录下开始压缩爬虫文件,
 本文详细介绍了如何在Crawlab中配置和运行Scrapy爬虫及单个Python文件爬虫。对于Scrapy爬虫,需上传压缩后的zip文件,开启Scrapy标识,并在settings.py中添加Crawlab的MongoPipeline。对于单文件爬虫,使用save_item方法保存结果。此外,还讲解了如何处理命令行参数以及设置定时任务,并提供了Cron表达式的验证链接。
本文详细介绍了如何在Crawlab中配置和运行Scrapy爬虫及单个Python文件爬虫。对于Scrapy爬虫,需上传压缩后的zip文件,开启Scrapy标识,并在settings.py中添加Crawlab的MongoPipeline。对于单文件爬虫,使用save_item方法保存结果。此外,还讲解了如何处理命令行参数以及设置定时任务,并提供了Cron表达式的验证链接。
上篇文章安装了Crawlab,现在开始使用。
0.6.0beta目前有问题,建议稳定版出了再用,所以本文用截止发布文章时的最新稳定版0.5.1。
本文最核心的内容在文档-SDK-Python和文档-爬虫集成中,即配置scrapy爬虫和单个py文件爬虫所需的设置。
先说一下,如果在Crawlab中运行爬虫时提示没有库,看文档。
将上图压缩后的zip文件上传,上传时开启是否为Scrapy。另外,上传时有提示要从根目录下开始压缩爬虫文件,
 1万+
2726
1万+
2726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























