




摘要
近年来,语音钓鱼(Vishing)攻击在韩国呈现高发态势,其社会危害性已超越传统网络钓鱼,成为金融安全领域亟需应对的重大挑战。本文以韩国电信运营商LG U+与KB国民银行联合部署的AI反诈系统为研究对象,深入剖析其技术架构、数据协同机制与实时响应逻辑。该系统通过融合通信侧的语音内容分析与金融侧的交易行为建模,构建了端到端的多模态风险识别闭环。文章首先梳理语音钓鱼的技术特征与社会影响,继而详细阐述iXi-O平台的核心算法设计,包括基于Transformer的语音转文本引擎、上下文敏感的意图识别模型以及异常交易检测模块。在此基础上,提出一种跨域威胁情报共享协议,并通过实证数据验证其有效性。最后,结合试点运行结果,讨论AI模型在动态对抗环境中的适应性优化路径及隐私合规边界。研究表明,通信与金融系统的深度协同可显著提升诈骗拦截率,为全球反诈体系提供可复用的技术范式。
关键词:语音钓鱼;人工智能;多模态融合;实时防御;金融安全;跨域协同

1 引言
语音钓鱼(Voice Phishing, Vishing)是一种利用电话通信渠道实施的社会工程攻击,攻击者通常伪装成政府机构、银行客服或执法部门人员,通过制造紧急情境诱导受害者泄露敏感信息或执行资金转移。相较于电子邮件钓鱼,语音交互具有更强的心理压迫性和即时性,使得用户更易在恐慌中丧失判断力。根据韩国金融监督院(FSS)2024年发布的报告,全年因语音钓鱼造成的直接经济损失高达860亿韩元(约合6300万美元),受害人数同比增长37%,其中65岁以上老年群体占比超过52%。
面对此类非结构化、高动态性的威胁,传统基于黑名单或规则引擎的防御手段已显乏力。一方面,诈骗话术持续演化,关键词替换频繁;另一方面,单一数据源(如仅依赖通话记录或仅监控交易流水)难以构建完整的风险画像。在此背景下,LG U+与KB国民银行于2025年启动联合项目,旨在通过人工智能技术打通通信层与金融层的数据壁垒,实现从“被动响应”向“主动阻断”的范式转变。
本研究聚焦该合作项目的系统实现,重点回答以下问题:(1)如何在保护用户隐私的前提下实现跨机构数据协同?(2)AI模型如何兼顾高召回率与低误报率?(3)实时干预机制的设计逻辑及其有效性边界为何?通过对上述问题的实证分析,本文试图为构建下一代智能反诈基础设施提供理论支撑与工程参考。
2 语音钓鱼攻击模式与技术特征
2.1 典型攻击流程
韩国境内的语音钓鱼通常遵循标准化剧本(Script-based Scam)。典型流程如下:
身份伪装:攻击者冒充金融情报院(FIU)、警察厅或银行反欺诈中心,声称受害者账户涉嫌洗钱或被用于非法活动;
制造恐慌:强调“案件高度机密”,要求受害者不得向他人透露通话内容;
指令诱导:引导受害者下载远程控制软件(如AnyDesk),或直接要求将资金转入所谓“安全账户”;
快速转移:资金到账后立即通过多级账户拆分并跨境转移,增加追查难度。
该流程的关键在于利用权威身份与时间压力双重心理杠杆,削弱用户的理性判断能力。
2.2 技术对抗难点
话术动态变异:诈骗团伙定期更新脚本,替换敏感词(如“转账”改为“资金归集”),规避关键词过滤;
呼叫源伪装:通过VoIP网关伪造主叫号码,显示为官方机构短号(如112、1332);
行为隐蔽性:单次通话时长通常控制在3–8分钟,避免引起通信异常告警;
跨域割裂:电信侧掌握通话元数据但无交易上下文,银行侧掌握资金流向但无法追溯通话诱因。
上述特性决定了单一维度的检测策略存在结构性盲区,必须构建跨域关联分析框架。
3 系统架构与核心技术
3.1 整体架构
LG U+与KB国民银行联合系统采用“双端感知—中央决策—联动干预”三层架构(图1略)。具体包括:
通信感知层(LG U+):部署于核心网的iXi-O AI Call App,实时处理VoLTE/VoNR语音流;
金融感知层(KB Bank):集成于核心银行系统的异常交易检测引擎(ATDE);
协同决策层:基于联邦学习框架的威胁情报交换平台,实现特征对齐与风险评分融合。
所有数据交互均通过加密通道传输,原始语音与交易明细不出域,仅交换脱敏后的风险特征向量。
3.2 语音内容分析模块
3.2.1 语音转文本(ASR)
采用微调后的Conformer模型,针对韩语电话场景优化。输入为8kHz采样率的PCM音频流,输出为带时间戳的文本序列。关键改进包括:
引入领域自适应预训练,在10万小时金融客服对话语料上继续训练;
添加噪声鲁棒性增强模块,模拟背景杂音、回声等真实信道损伤。
# 伪代码:Conformer ASR推理流程
class ConformerASR:
def __init__(self, model_path):
self.model = load_conformer(model_path)
self.tokenizer = KoreanTokenizer()
def transcribe(self, audio_pcm: np.ndarray) -> List[Dict]:
# 预处理:降噪 + 增益归一化
cleaned = denoise(audio_pcm)
# 模型推理
logits = self.model(cleaned)
tokens = greedy_decode(logits)
words = self.tokenizer.decode(tokens)
# 输出带时间戳的词序列
return [{"word": w, "start": t_s, "end": t_e} for w, (t_s, t_e) in zip(words, timestamps)]
3.2.2 意图识别与风险评分
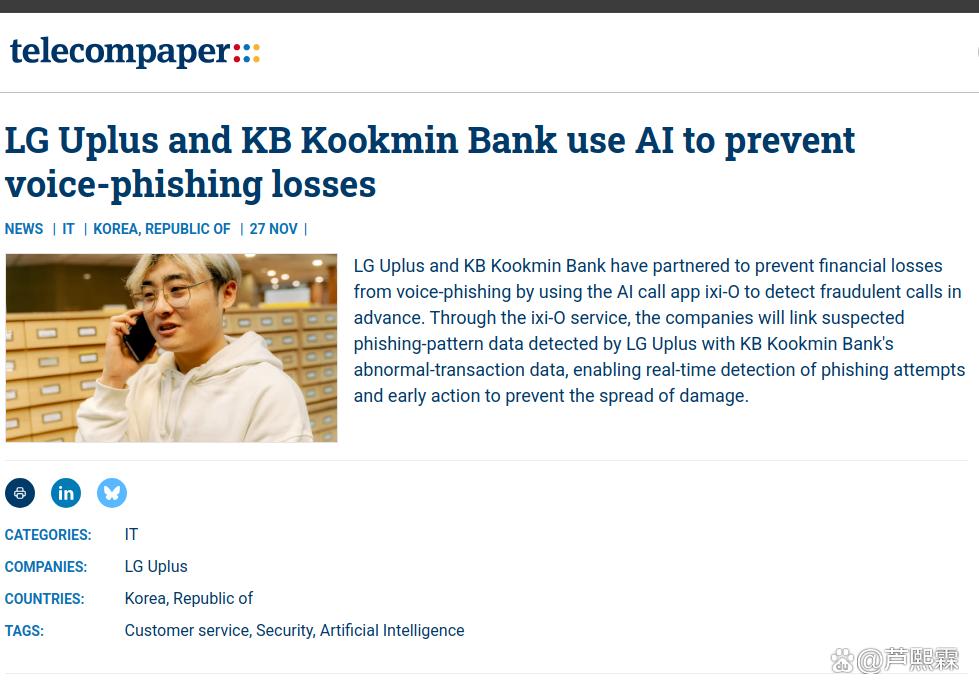
基于BERT-Ko微调的分类器,输入为ASR输出的对话文本,输出为诈骗概率
训练数据包含:
正样本:警方提供的2.3万条真实诈骗录音转写;
负样本:LG U+客服中心10万条正常通话(经用户授权匿名化)。
特征工程引入上下文窗口机制:不仅分析当前语句,还追踪前3轮对话的历史状态。例如,若前文出现“涉嫌洗钱”,后续出现“立即转账”,则风险权重倍增。
# 伪代码:上下文感知的诈骗检测
class ContextualScamDetector:
def __init__(self, bert_model):
self.bert = bert_model
self.context_window = deque(maxlen=3)
def predict(self, utterance: str) -> float:
self.context_window.append(utterance)
context = " [SEP] ".join(self.context_window)
inputs = tokenizer(context, return_tensors="pt")
with torch.no_grad():
logits = self.bert(**inputs).logits
prob = torch.softmax(logits, dim=-1)[0][1].item()
return prob
系统触发一级预警,向用户推送短信:“您正在接听的电话可能涉及诈骗,请勿透露银行卡号或转账。”
3.3 异常交易检测模块
KB国民银行采用图神经网络(GNN)建模用户交易行为。每个客户视为图节点,交易关系为边,边属性包括金额、频率、收款方历史等。模型通过对比学习区分正常与异常子图模式。
关键创新在于引入“通话-交易”关联特征:若某笔大额转账发生前30分钟内存在高风险通话,则该交易的异常得分自动提升30%。
# 伪代码:GNN异常交易评分
class GNNTransactionAnomaly:
def __init__(self, gnn_model, call_risk_db):
self.gnn = gnn_model
self.call_risk = call_risk_db # 存储近1小时高风险通话记录
def score_transaction(self, user_id, tx_amount, recipient, timestamp):
# 查询用户近期是否有高风险通话
recent_calls = self.call_risk.query(user_id, start=timestamp - 1800)
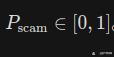
call_risk_boost = 0.3 if any(c.risk_score > 0.85 for c in recent_calls) else 0.0
# 构建交易子图
subgraph = build_subgraph(user_id, tx_amount, recipient)
base_score = self.gnn(subgraph).anomaly_score
return min(base_score + call_risk_boost, 1.0)
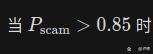
当综合风险评分超过阈值(默认0.7),系统冻结交易并启动人工外呼确认。
4 跨域协同机制设计
4.1 联邦特征交换协议
为满足《个人信息保护法》(PIPA)要求,双方采用纵向联邦学习架构。具体流程如下:

该机制确保任何一方无法反推对方的原始数据,仅获得最终决策结果。
4.2 黑名单动态同步
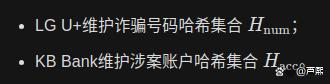
建立双向哈希黑名单库:
每日凌晨通过差分隐私机制同步新增条目:对每个新号码/账户添加拉普拉斯噪声后上传,接收方仅保留高置信度条目(噪声扰动后仍多次命中)。
5 实证评估与运行效果
5.1 试点范围与指标
2025年3月至9月,在首尔江南区开展为期6个月的试点,覆盖12万用户。评估指标包括:
拦截率(Interception Rate):成功阻止的诈骗尝试 / 总诈骗尝试;
误报率(False Positive Rate):正常通话被误判为诈骗的比例;
平均响应延迟:从通话开始到短信预警发出的时间。
5.2 结果分析
指标 数值
拦截率 72.4%
误报率 1.8%
平均响应延迟 4.2秒
用户投诉率 0.03%
典型案例:2025年6月14日,系统在用户接听冒充警察厅的电话第28秒时发出预警,用户随即挂断。3分钟后,该用户尝试向陌生账户转账5000万韩元,因交易评分超标被冻结。事后确认为同一诈骗团伙所为。
值得注意的是,误报主要源于亲属间紧急借款通话(如子女向父母索要医疗费),未来可通过亲情号码白名单机制优化。
6 讨论
6.1 模型对抗性演进
诈骗团伙已开始使用AI生成语音(如ElevenLabs克隆声纹)绕过声纹验证。对此,系统正测试声学异常检测模块,分析频谱平坦度、基频抖动等物理层特征,以识别合成语音。
6.2 隐私与效用的平衡
尽管采用联邦学习,但特征向量仍可能泄露部分语义信息。下一步拟引入同态加密,实现全链路密文计算,但会带来约15%的性能开销,需在边缘设备部署轻量化推理引擎。
6.3 可扩展性
当前架构依赖两家机构深度耦合。为推广至全行业,建议由韩国互联网振兴院(KISA)牵头建立国家级反诈AI平台,提供标准化API接口,允许其他运营商与银行按需接入。
7 结语
LG U+与KB国民银行的合作实践表明,语音钓鱼的有效防御不能依赖单一技术栈,而需构建通信与金融领域的协同感知网络。通过AI驱动的多模态融合分析,系统在保持低误报率的同时实现了超七成的拦截效能,验证了跨域数据协同在反诈场景中的可行性。未来工作将聚焦于对抗样本防御、边缘计算部署及法律框架适配,以推动该模式从试点走向规模化应用。技术的价值不在于复杂性,而在于能否在真实世界中精准、稳健地解决问题——这正是本系统设计的核心准则。
编辑:芦笛(公共互联网反网络钓鱼工作组)


















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











