




 本文深入探讨Python中字典(dict)和集合(set)的高效查询机制,解析散列表如何实现快速键值对查询,以及为何这些数据结构能够提供几乎与数据量无关的查询速度。同时,讨论了键和元素的散列要求,以及在迭代过程中修改字典或集合可能导致的问题。
本文深入探讨Python中字典(dict)和集合(set)的高效查询机制,解析散列表如何实现快速键值对查询,以及为何这些数据结构能够提供几乎与数据量无关的查询速度。同时,讨论了键和元素的散列要求,以及在迭代过程中修改字典或集合可能导致的问题。
本节你将看到关于字典dict和集合set更加深入的原理,尤其是关于散列在其中的作用,将回答以下问题:
- Python 里的 dict 和 set 的效率有多高?
- 为什么它们是无序的?
- 为什么并不是所有的 Python 对象都可以当作 dict 的键或 set 里的元素?
- 为什么 dict 的键和 set 元素的顺序是跟据它们被添加的次序而定的,
- 为什么不应该在迭代循环 dict 或是 set 的同时往里添加元素?
dict 和 set 的效率有多高
这里做了一个对比实验:对比容器的大小对 dict、set 或 list 的 in 运算符效率的影响。
实验的过程:创建了一个有 1000万个双精度浮点数的数组,名叫 haystack。另外还有一个包含了 1000 个浮点数的 needles数组,其中 500 个数字是从 haystack 里挑出来的,另外 500 个肯定不在 haystack 里。
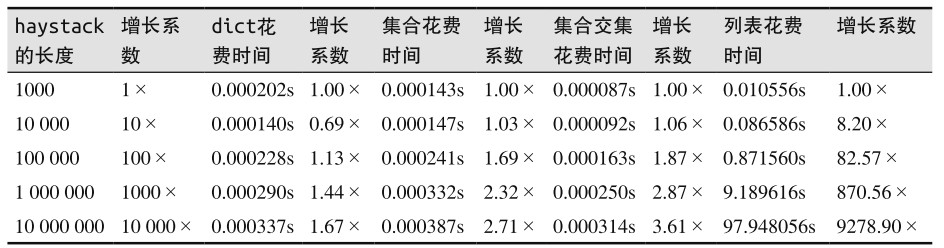
实验的结果:
- 最快的时间来自“集合交集花费时间”
- 最糟糕的表现来自“列表花费时间”这一列,由于列表背后没有散列支持in运算,所以每次搜索都需要完整的循环一遍.
- 不管查询有多少个元素的字典或集合,所耗费的时间都能忽略不计
为什么集合和字典查询如此之快?
import sys
import timeit
#SETUP='''
import array
selected = array.array('d')
with open('selected.arr','rb') as fp:
selected.fromfile(fp,{size})
if {container_tpye} is dict:
haystack = dict.fromkeys(selected,1)
else:
haystack = {container_tpye}(selected)
if {verbose}:
print(type(haystack),end=' ')
print('haystack:%10d' % len(haystack),end=' ')
needles = array.array('d')
with open('not_selected.arr','rb') as fp:
needles.fromfile(fp,500)
needles.extend(selected[::{size}//500])
if{verbose}:
print(' needles: %10d' % len(needles),end=' ')
#'''
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-0d4afc3d560e> in <module>
5 import array
6 selected = array.array('d')
----> 7 with open('selected.arr','rb') as fp:
8 selected.fromfile(fp,{size})
9 if {container_tpye} is dict:
FileNotFoundError: [Errno 2] No such file or directory: 'selected.arr'
字典中的散列表
散列表背后是什么
**散列表:**是一个稀疏数组
**稀疏数组:**总是有空白元素的数组
散列表里的单元通常叫作表元(bucket),就是最小的单元元素.
例如:dict字典散列表:每一个键值对就是一个表元,每个表元由两部分组成:
- 一个是对键的引用
- 一个是对值的引用
既然是引用那么每个表元的空间大小是一致的,可以通过偏移量来读取某个表元.
python中的一个原则:保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
散列表几个特性,如下
散列值和相等性
**散列值:**把一个对象放入散列表,那么首先要计算这个元素键的散列值,通过hash()来获得.
- 内置的 hash() 方法可以用于所有的内置类型对象。
- 如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。
- 如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真
散列表的算法
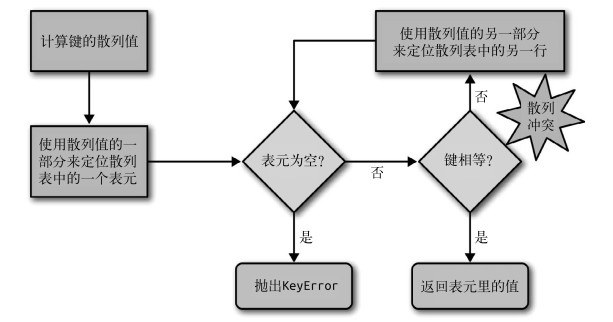
为了获取 my_dict[search_key] 背后的值,散列表的具体的算法的流程如下:
- Python 首先会调用 hash(search_key) 来计算search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。
- 若找到的表元是空的,则抛出 KeyError 异常。
- 若不是空的,则表元里会有一对 found_key:found_value。
a = 1
b = 1.0
c = 1.0001
d = 1.0002
print(hash(a))
print(hash(b))
print(hash(c))
print(hash(d))
1
1
230584300921345
461168601842689
散列表给dict带来的优缺点
键必须是可散列的
可散列的对象需要符合如下三个要求:
- 支持 hash() 函数,并且通过 hash() 方法所得到的散列值是不变的
- 支持通过 eq() 方法来检测相等性
- 若 a == b 为真,则 hash(a) == hash(b) 也为真
*所有由用户自定义的对象默认都是可散列的,因为它们的散列值由 id() 来获取
字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的.
键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。
键的次序取决于添加顺序
当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。
往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。
不要对字典同时进行迭代和修改。
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States'),
(62, 'Indonesia'),
(55, 'Brazil'),
(92, 'Pakistan'),
(880, 'Bangladesh'),
(234, 'Nigeria'),
(7, 'Russia'),
(81, 'Japan'),
]
d1 = dict(DIAL_CODES)
print('d1:',d1.keys())
d2 = dict(sorted(DIAL_CODES))
print('d2:',d2.keys())
# 数据元组的顺序是按照国家名字的英文拼写来决定的
d3 = dict(sorted(DIAL_CODES,key =lambda x:x[1]))
print('d3:',d3.keys())
#这些字典是相等的,因为它们所包含的数据是一样的
assert (d1 == d2 and d2 == d3)
d1: dict_keys([86, 91, 1, 62, 55, 92, 880, 234, 7, 81])
d2: dict_keys([1, 7, 55, 62, 81, 86, 91, 92, 234, 880])
d3: dict_keys([880, 55, 86, 91, 62, 81, 234, 92, 7, 1])
set的实现以及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用.
- 集合里的元素必须是可散列的。
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里已有元素的次序。
分享关于人工智能,机器学习,深度学习以及计算机视觉的好文章,同时自己对于这个领域学习心得笔记。想要一起深入学习人工智能的小伙伴一起结伴学习吧!扫码上车!


















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









