




 本文介绍了如何使用Flume从MySQL进行准实时增量数据采集,并将这些数据发送到Kafka。配置中,source为MySQL,channel为memory,sink配置为Kafka。在MySQL的student表中插入数据后,通过Flume-kafka.conf配置文件启动Flume进程,数据成功传输到Kafka,并通过consumer观察到数据已被消费。
本文介绍了如何使用Flume从MySQL进行准实时增量数据采集,并将这些数据发送到Kafka。配置中,source为MySQL,channel为memory,sink配置为Kafka。在MySQL的student表中插入数据后,通过Flume-kafka.conf配置文件启动Flume进程,数据成功传输到Kafka,并通过consumer观察到数据已被消费。
Flume准实时增量采集MySQL的数据到Kafka,source为MySQL,channel为memory,sink为Kafka。关于Flume采集MySQL可以查看:Flume实战之准实时采集mysql数据到HBase和Hive的集成表,这里只需要在上一篇的基础上修改以下sink为Kafka,并做一些相关修改就可以了
MySQL中student表数据
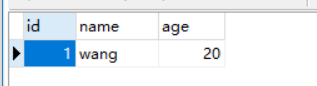
采集表数据时的元数据信息,表flume_meta
先来启动kafka
root@master:/opt/modules/kafka_2.11# bin/kafka-server-start.sh -daemon config/server.properties
创建一个topic
root@master:/opt/modules/kafka_2.11# bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test
Created topic test.
root@master:/opt/modules/kafka_2.11# bin/kafka-topics.sh --list --zookeeper master:2181
test
flu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6303
6303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









