



如下图所示想找出小数位数为2位的,先看我的动图演示吧,这里用到了正则表达式的操作
(方方格子插件)
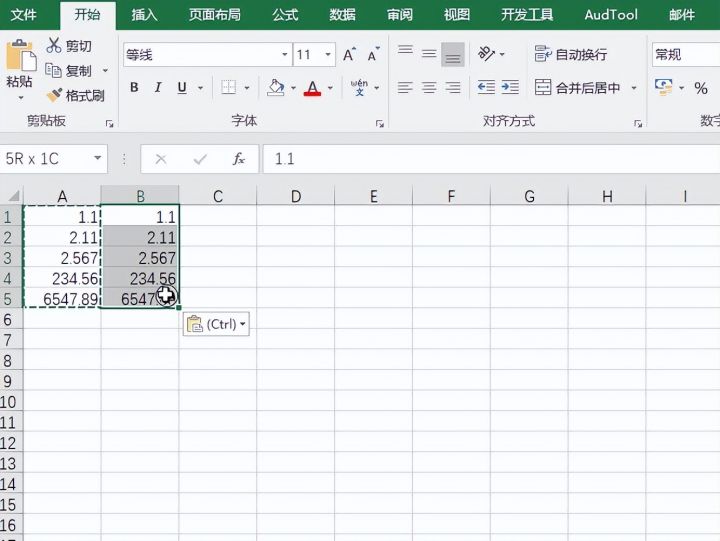
1.为了对比我们先复制一份内容出来
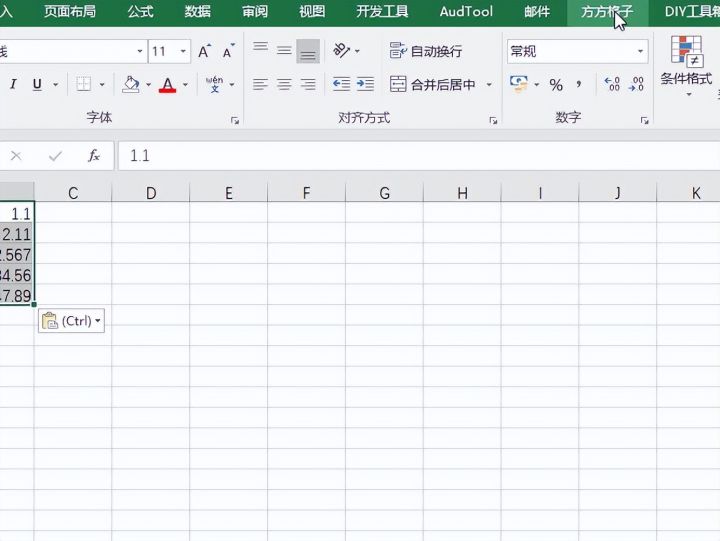
2.然后选择方方格子按钮
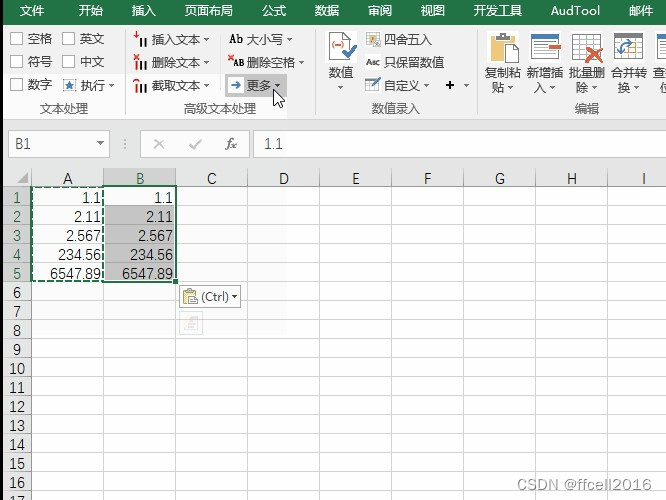
3.选择高级文本处理中的更多按钮
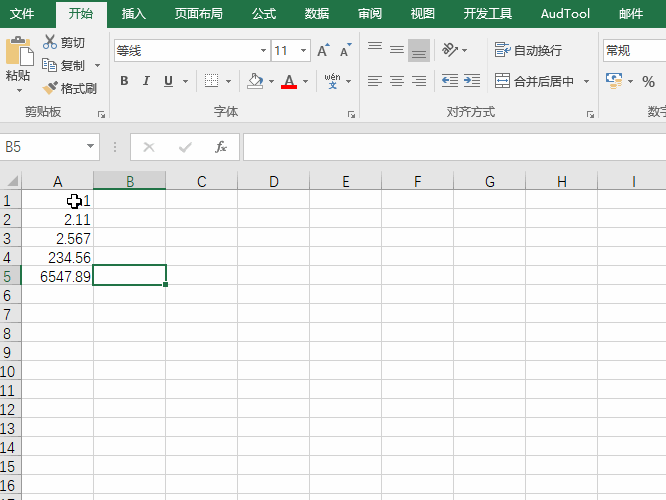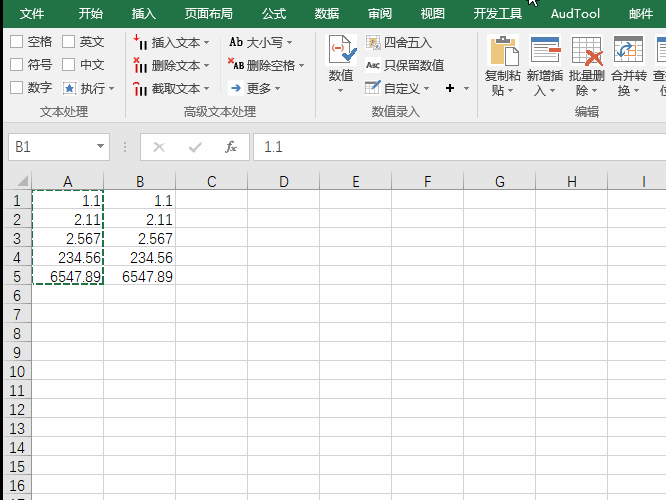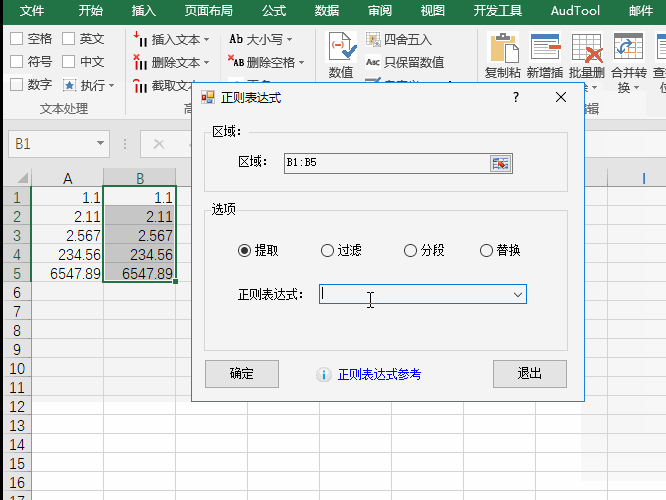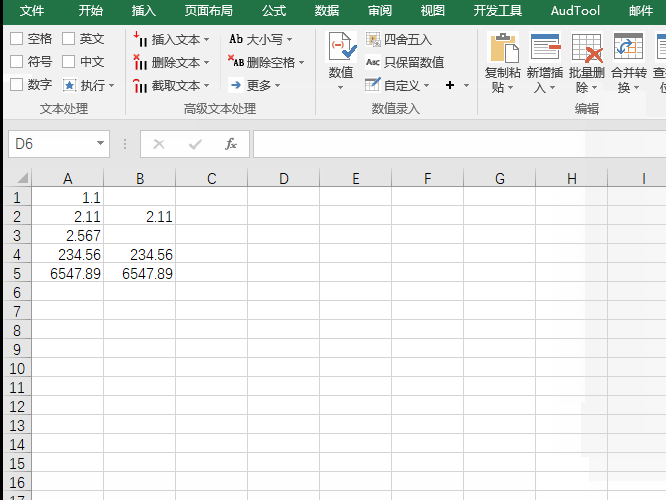
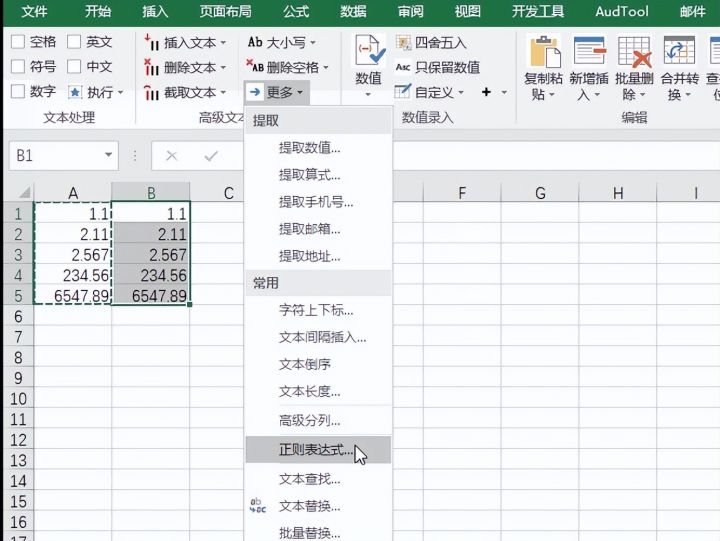
4.选择正则表达式按钮^(([1-9]{1}\d*)|(0{1}))(\.\d{2})$
5.选择提取按钮,并输入正则表达式
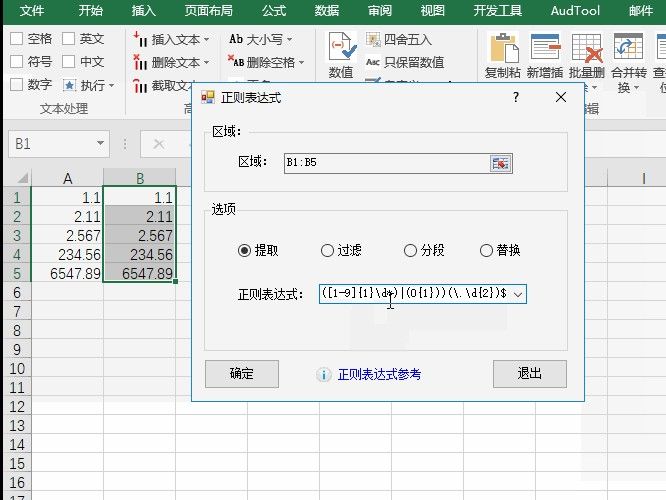
6.确定后即可看到结果
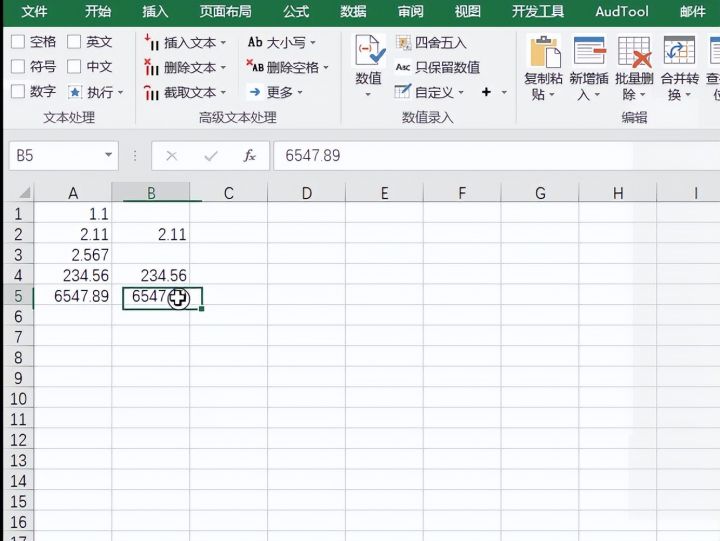
如果经验帮到了你,请记得分享!
 这篇博客介绍了如何利用正则表达式在文本中查找并提取所有小数位数为2位的数字。通过方方格子插件的高级文本处理功能,演示了具体的步骤,包括选择正则表达式模式`^(([1-9]{1}
这篇博客介绍了如何利用正则表达式在文本中查找并提取所有小数位数为2位的数字。通过方方格子插件的高级文本处理功能,演示了具体的步骤,包括选择正则表达式模式`^(([1-9]{1}
如下图所示想找出小数位数为2位的,先看我的动图演示吧,这里用到了正则表达式的操作
(方方格子插件)
1.为了对比我们先复制一份内容出来
2.然后选择方方格子按钮
3.选择高级文本处理中的更多按钮
4.选择正则表达式按钮^(([1-9]{1}\d*)|(0{1}))(\.\d{2})$
5.选择提取按钮,并输入正则表达式
6.确定后即可看到结果
如果经验帮到了你,请记得分享!
 870
1832
1106
870
1832
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























