



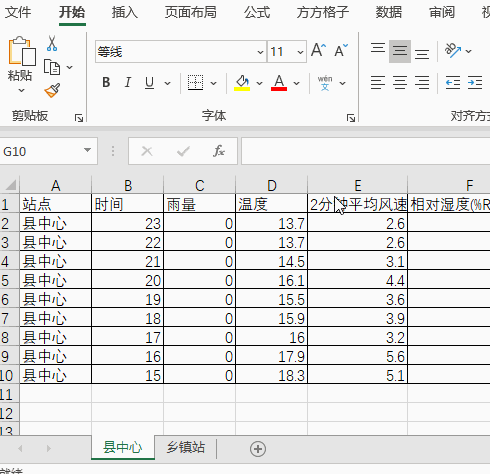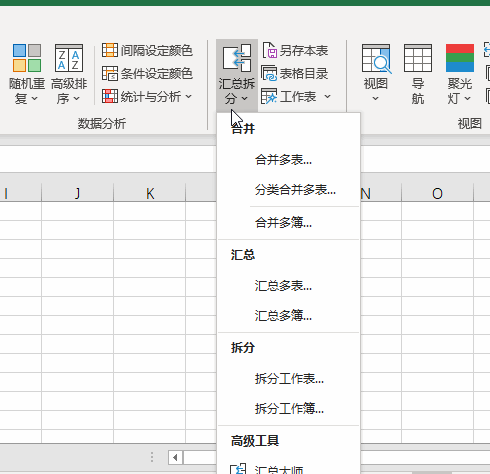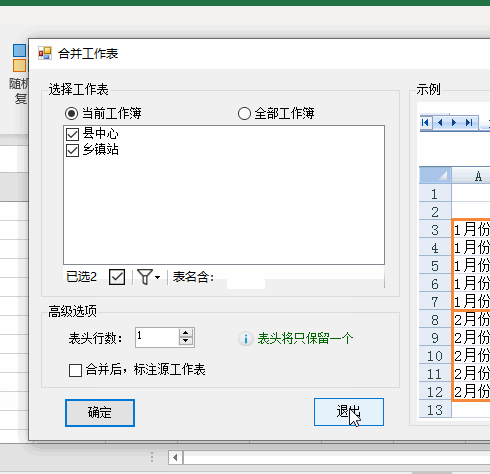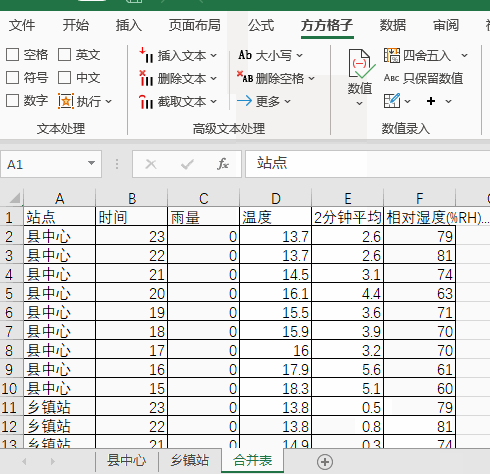
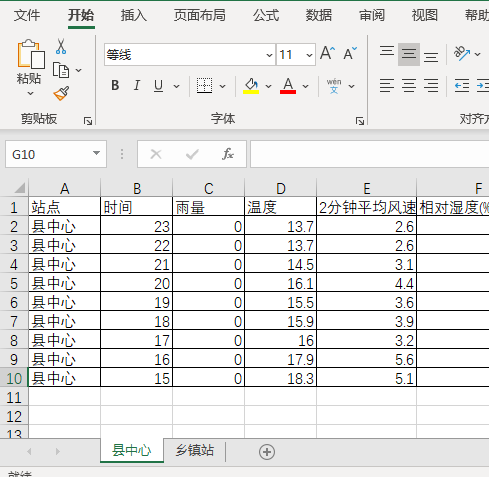
1.如下图分别是某地区两个气象观测站数据表,现在想要将这两个表格数据合并到一个表中。
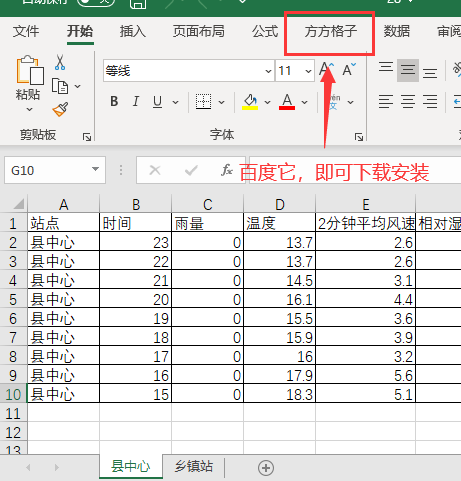
2.点击下图选项(Excel工具箱,百度即可了解详细下载安装信息,本文这里就不做详细解说。)
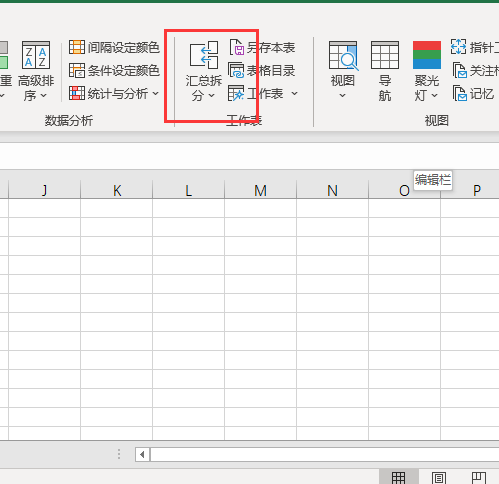
3.点击【汇总拆分】
4.选择【合并多表】
5.将【表头行数】设置为1
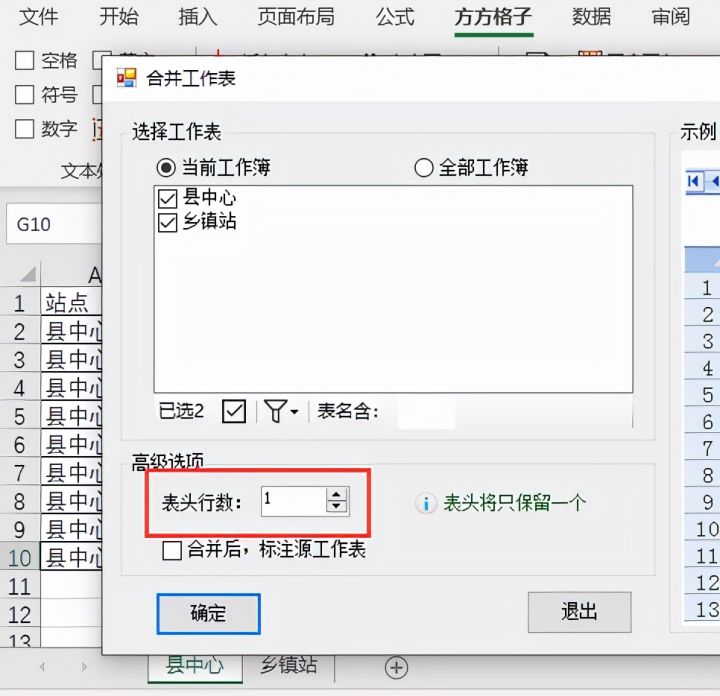
6.最后点击【确定】即可完成
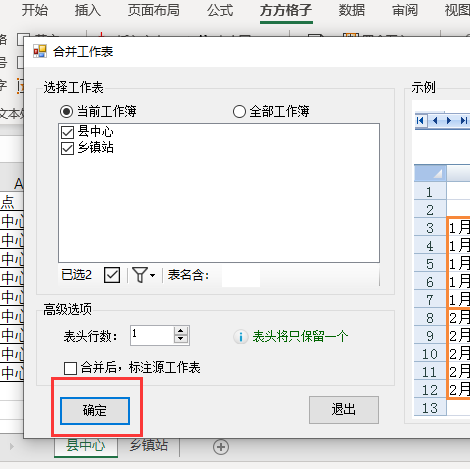
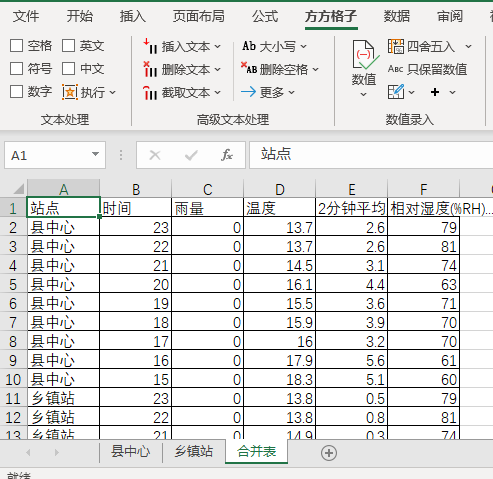
7.完成效果如下图所示
1.如下图分别是某地区两个气象观测站数据表,现在想要将这两个表格数据合并到一个表中。
2.点击下图选项(Excel工具箱,百度即可了解详细下载安装信息,本文这里就不做详细解说。)
3.点击【汇总拆分】
4.选择【合并多表】
5.将【表头行数】设置为1
6.最后点击【确定】即可完成
7.完成效果如下图所示

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 7302
7302





