



 本文介绍了如何使用Excel公式提取单元格中括号内的内容。通过MID和FIND函数的组合,可以高效地从A列单元格提取括号内文字,并将其填充到B列。首先,在B2单元格输入公式,然后向下拖动填充,即可快速完成批量提取。此外,还提到了快速填充功能,适用于高版本Excel,只需在B2单元格输入起始内容,然后按Ctrl+E快捷键即可完成填充。
本文介绍了如何使用Excel公式提取单元格中括号内的内容。通过MID和FIND函数的组合,可以高效地从A列单元格提取括号内文字,并将其填充到B列。首先,在B2单元格输入公式,然后向下拖动填充,即可快速完成批量提取。此外,还提到了快速填充功能,适用于高版本Excel,只需在B2单元格输入起始内容,然后按Ctrl+E快捷键即可完成填充。
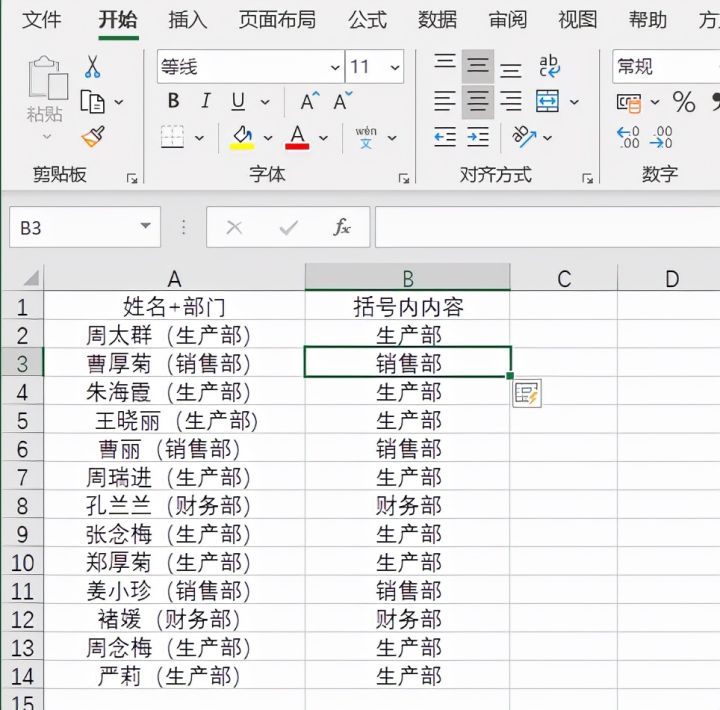
如下图,A列单元格中含有括号,现在想要将括号内内容提取到B列中
一、
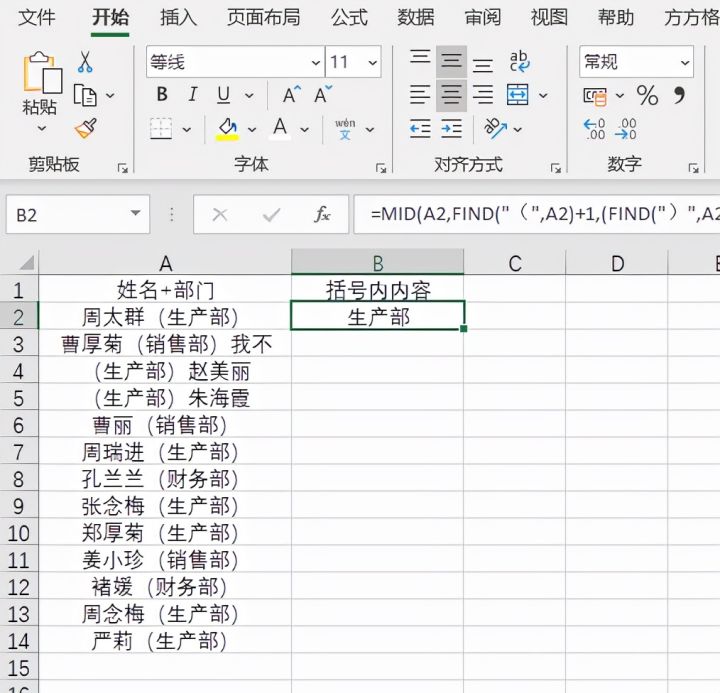
1.在B2单元格输入公式=MID(A2,FIND("(",A2)+1,(FIND(")",A2)-FIND("(",A2))-1) 即可将A2单元格括号内内容提取出来。(使用时要注意公式引号内括号要与A列单元格括号相同,即A列单元格为中文括号,公式中也要为中文括号)
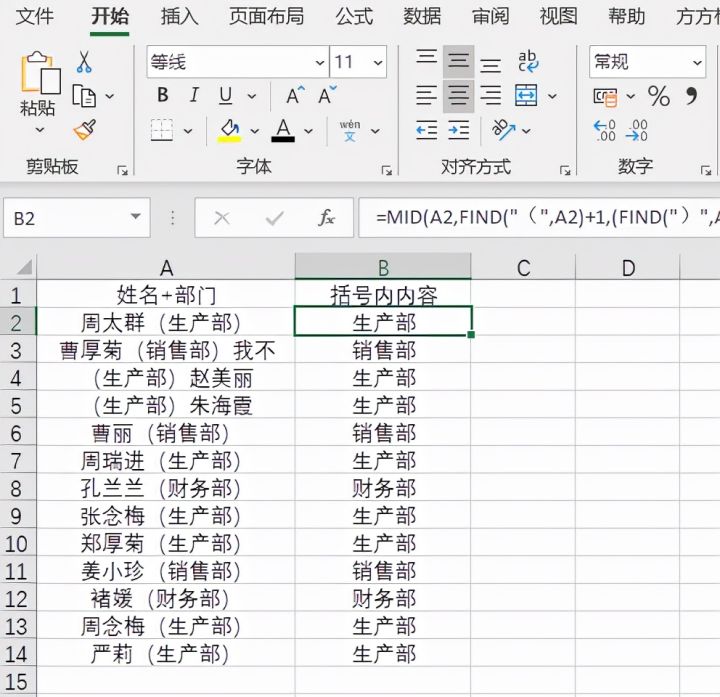
2.将B2单元格公式下拉填充即可将A列单元格全部括号内容提取出来。
3.下面跟大家简单介绍一下这个公式,首先是mid函数,是Excel中的一个字符串函数,作用是从一个字符串中截取出指定数量的字符。语法结构是=MID(text, start_num, num_chars)。在本文中它的作用是从A列单元格中括号内第一个字符开始提取括号内字符个数个字符,即将括号内字符提取出来。

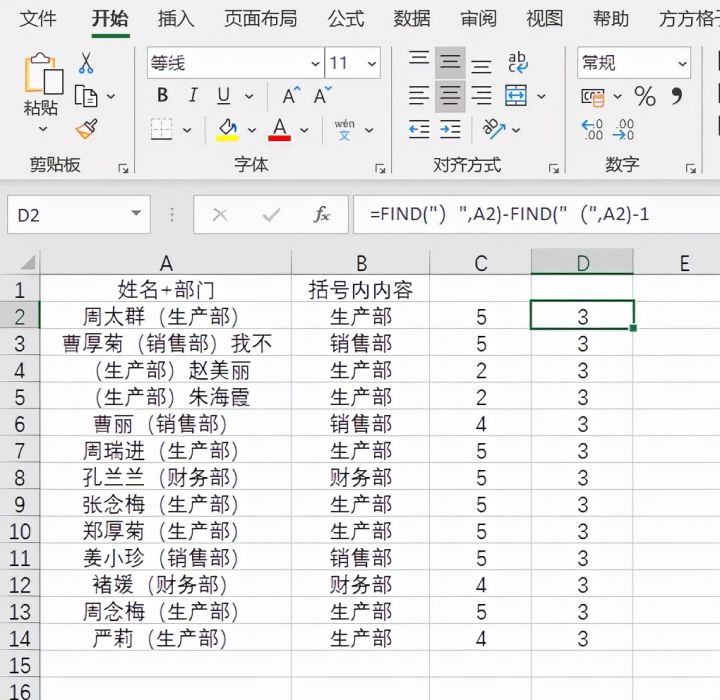
4.Find函数用来对原始数据中某个字符串进行定位,以确定其位置。因此公式中【FIND("(",A2)+1】作用是查找左括号在文本中的位置,然后用这个位置加一即可得出括号内第一个字符的位置。为了方便大家理解在单元格中输入公式FIND("(",A2)+1,结果如下图。

5.而【FIND(")",A2)-FIND("(",A2))-1】的作用是返回括号内容字符个数。在单元格输入公式FIND(")",A2)-FIND("(",A2))-1结果如下图。
6.得知括号内容第一个字符的位置,也知道括号内容的字符个数。即可利用mid函数将括号内容提取出来。
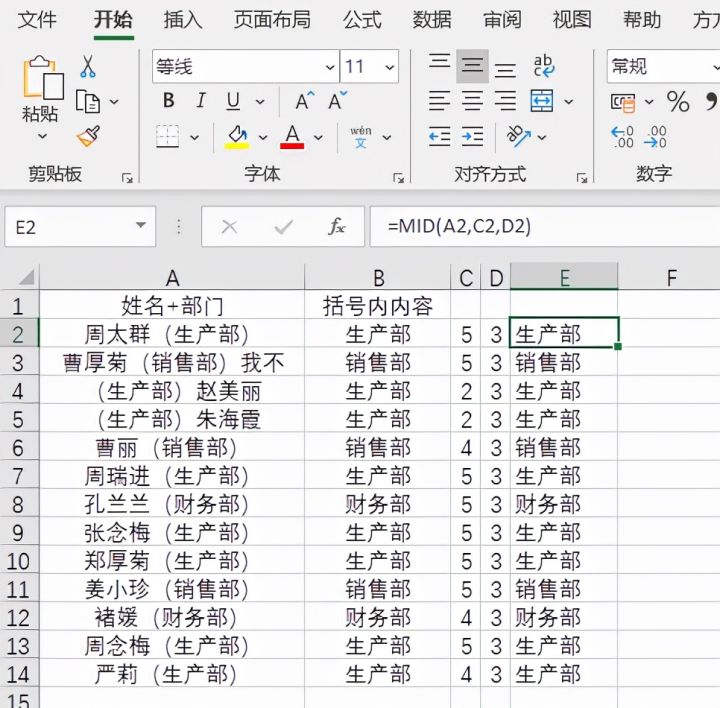
二、
1.下面跟大家分享填充法如何提取括号内容。需要注意的是快速填充是高版本Excel才有的功能,低版本无此功能,另外使用时最好单元格格式固定,括号位置统一。如下图
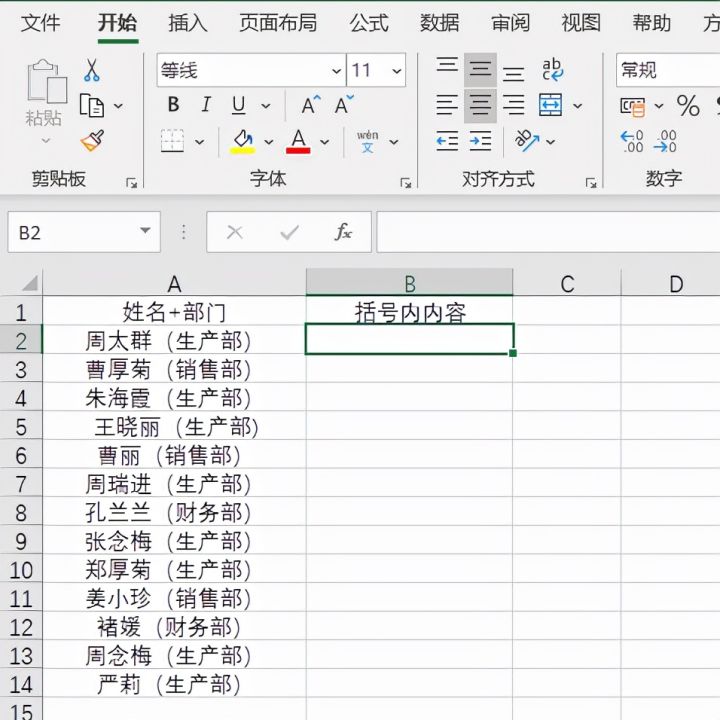
2.在B2单元格输入生产部
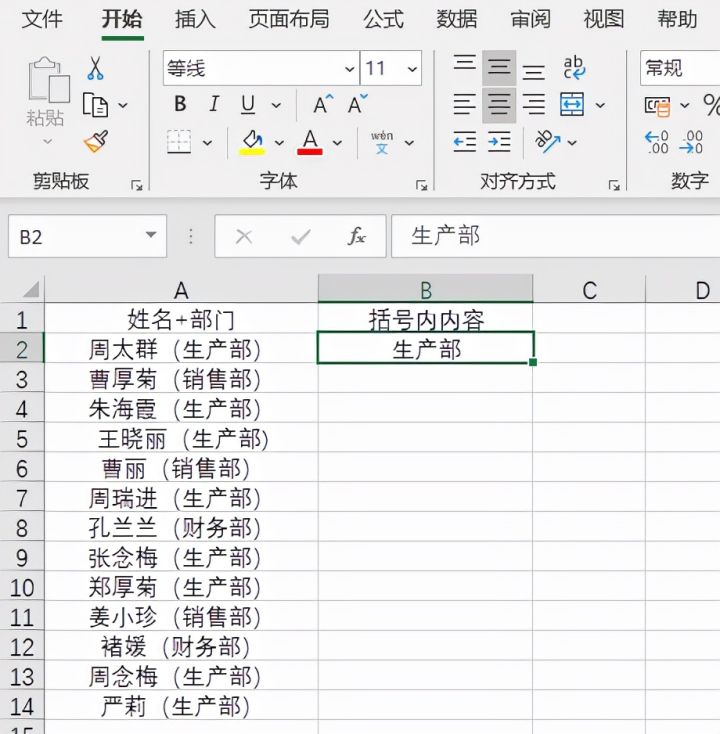
3.鼠标点击B3单元格
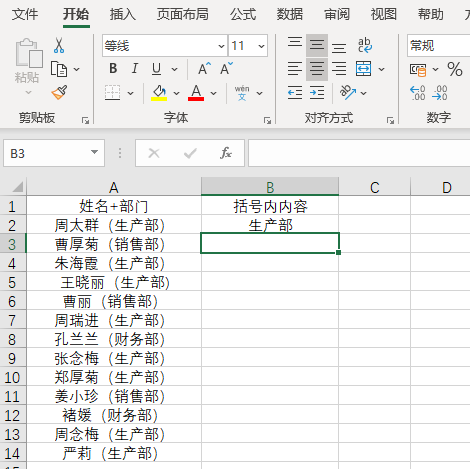
4.按下Ctrl+E即可完成。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









