



今天跟大家分享一下拆分excel成多个文件
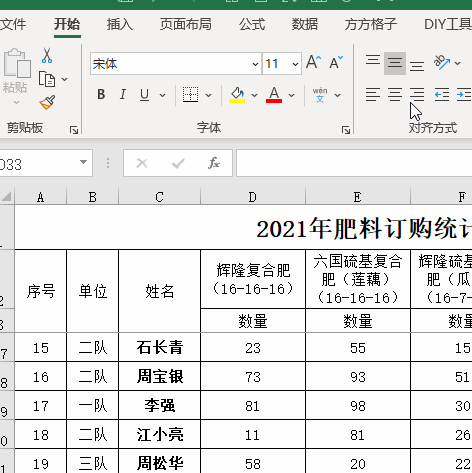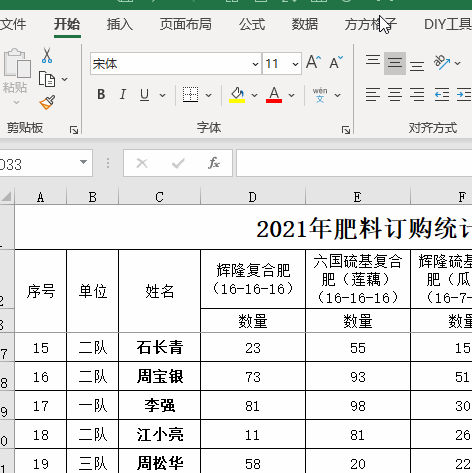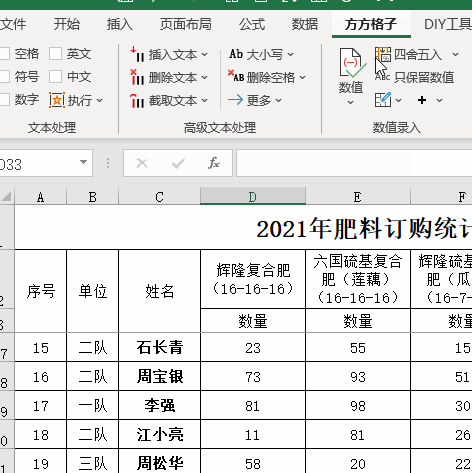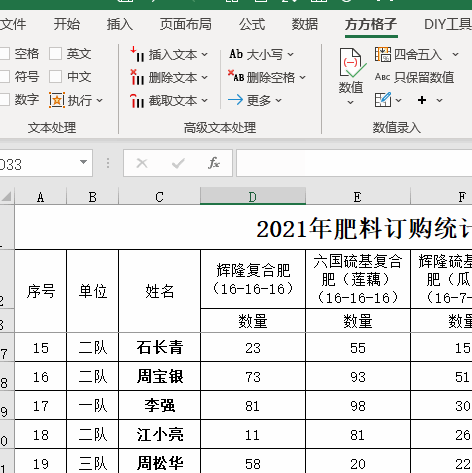
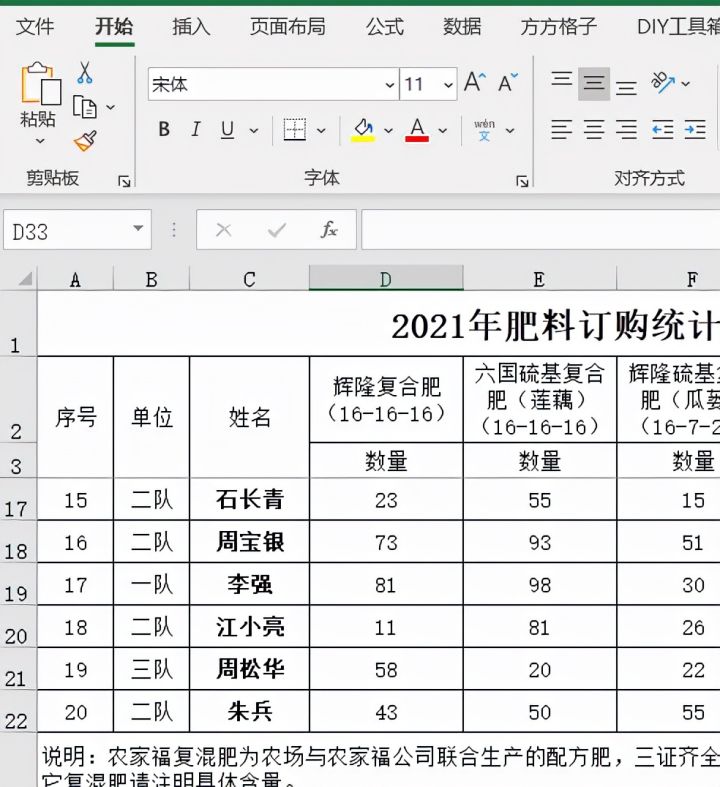
1.打开演示文件,如下图要求将表格数据拆分为多个工作表。
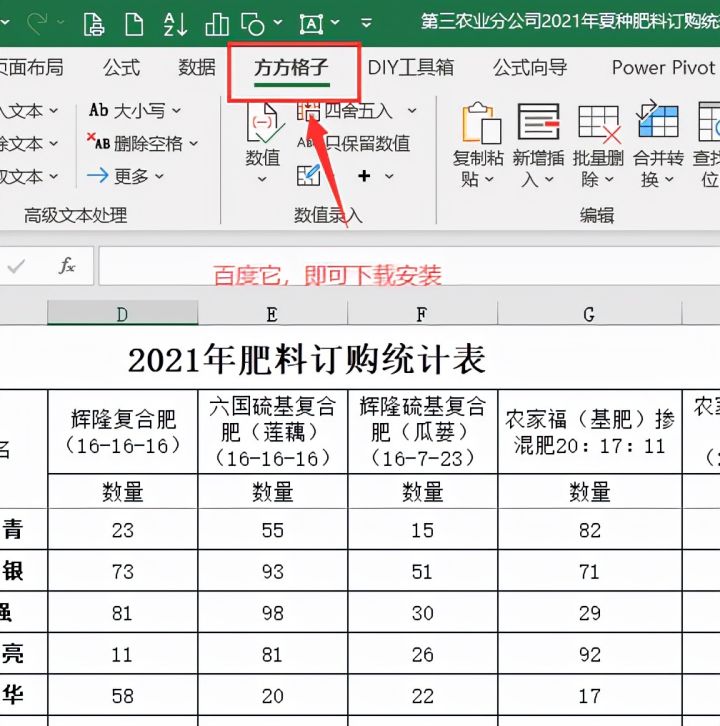
2.首先我们点击下图选项
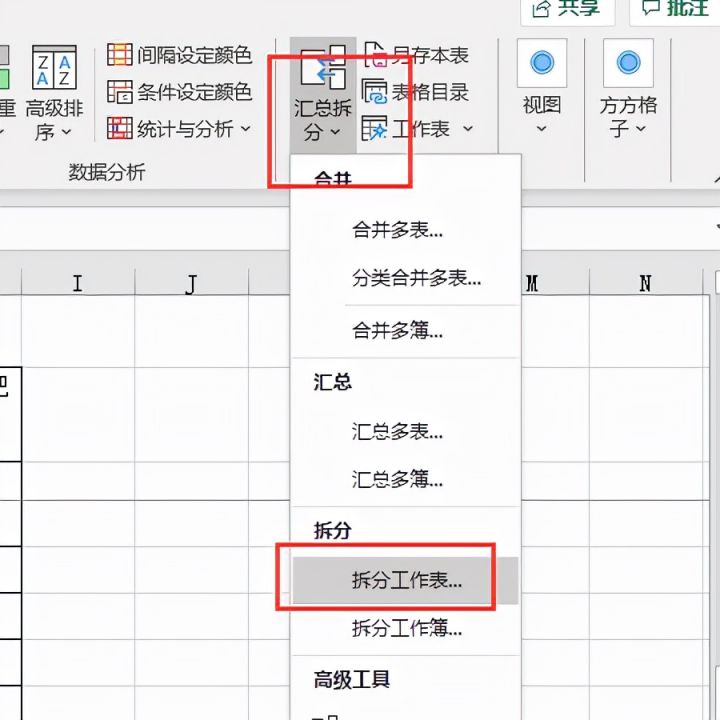
3.点击【汇总拆分】-【拆分工作表】
4.接着我们进行如下图操作
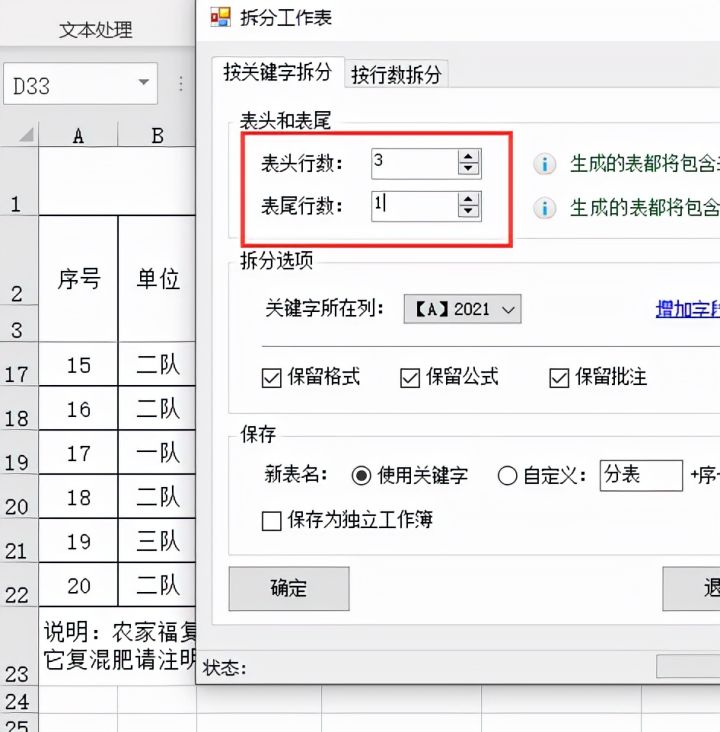
5.【关键词所在列】设置为B
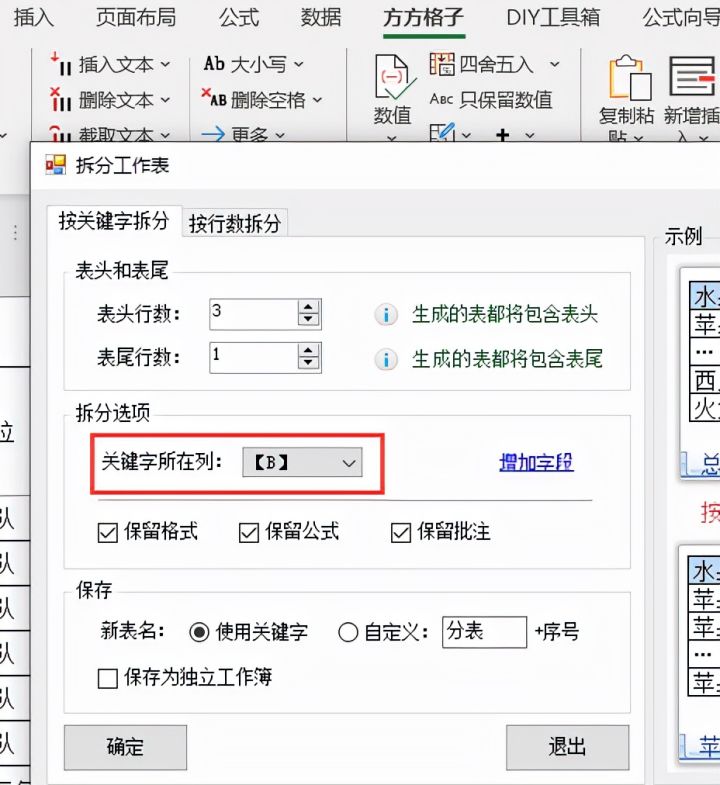
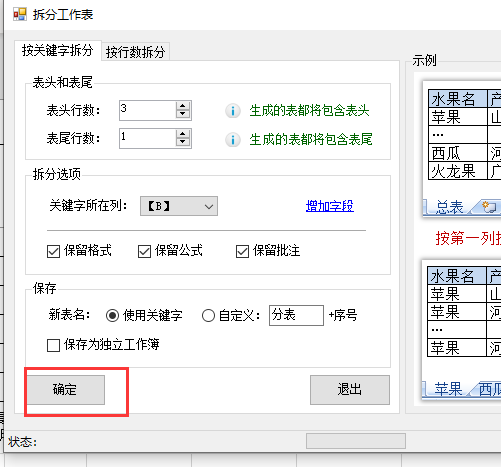
6.最后点击【确定】即可完成
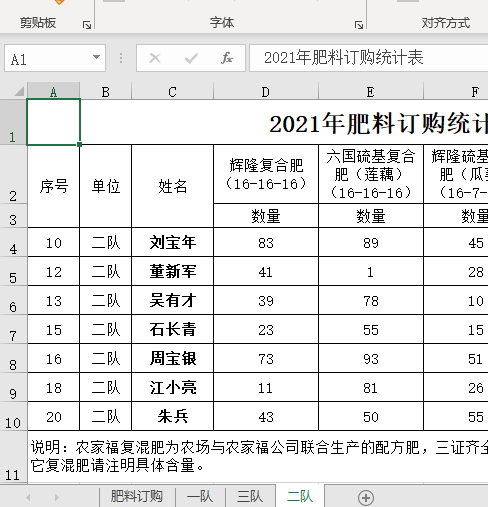
7.完成效果如下图
今天跟大家分享一下拆分excel成多个文件
1.打开演示文件,如下图要求将表格数据拆分为多个工作表。
2.首先我们点击下图选项
3.点击【汇总拆分】-【拆分工作表】
4.接着我们进行如下图操作
5.【关键词所在列】设置为B
6.最后点击【确定】即可完成
7.完成效果如下图
 5662
5662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























