




 本文详细介绍了Java8 Stream API的使用,涵盖管道流转换、过滤、映射、分组、排序、匹配查找、归约、并行操作等多种功能。通过实例展示了如何对数组、集合和文本文件进行数据处理,以及如何进行多级分组、去重、排序和收集到各种集合类型。此外,还讲解了Stream的并行流处理和元素的合并器使用。
本文详细介绍了Java8 Stream API的使用,涵盖管道流转换、过滤、映射、分组、排序、匹配查找、归约、并行操作等多种功能。通过实例展示了如何对数组、集合和文本文件进行数据处理,以及如何进行多级分组、去重、排序和收集到各种集合类型。此外,还讲解了Stream的并行流处理和元素的合并器使用。
参考资料
- Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合
- 恕我直言你可能真的不会java系列
- 【java8分页排序】lambda的(多字段)分页和排序 comparing,thenComparing的区别
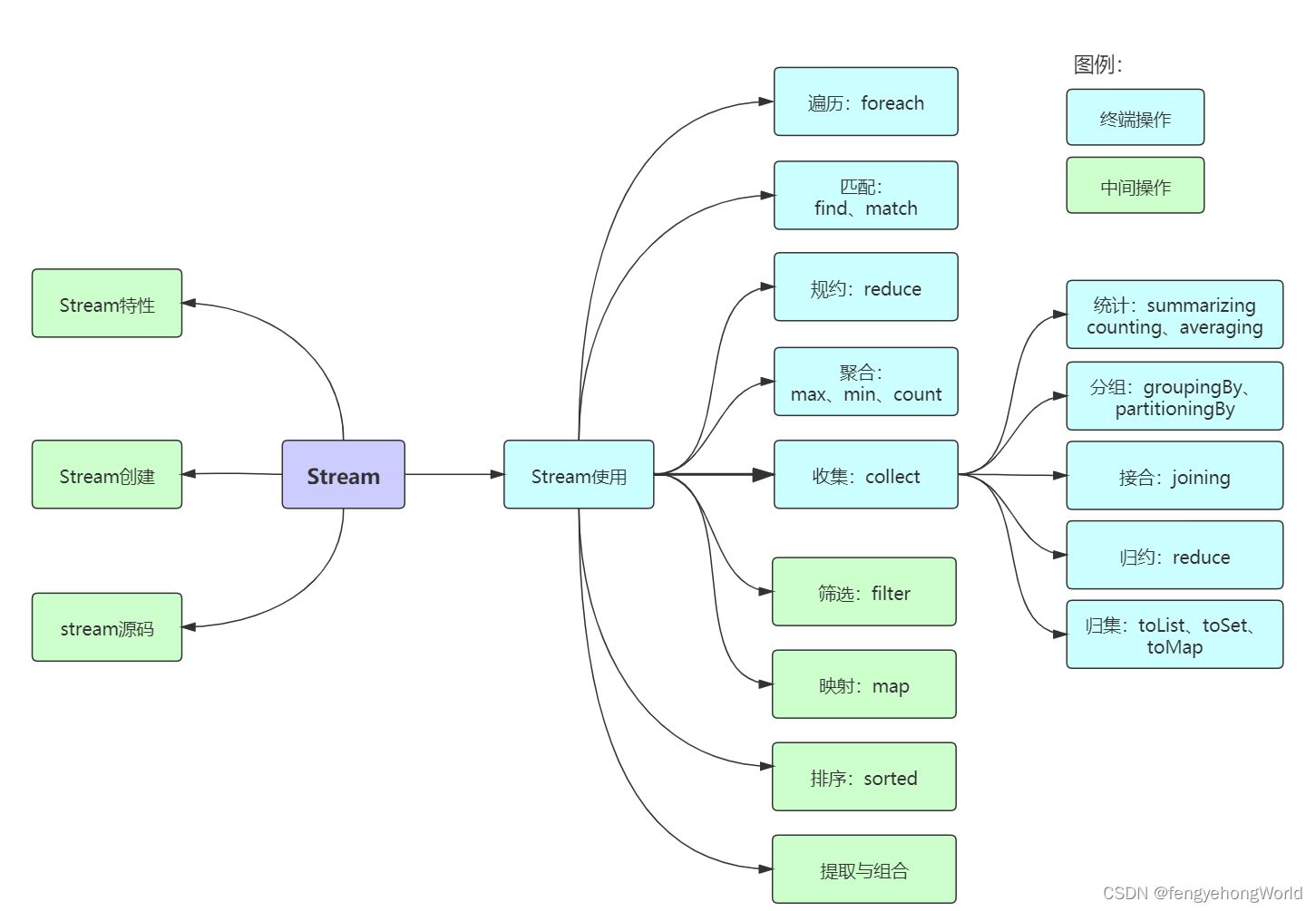
目录
一.管道流的转换
- Java Stream就是一个数据流经的管道,并且在管道中对数据进行操作,然后流入下一个管道。
- 管道的功能包括:Filter(过滤)、Map(映射)、sort(排序)等,集合数据通过Java Stream管道处理之后,转化为另一组集合或数据输出。
1.数组转换为管道流
-
使用
Stream.of()方法,将数组转换为管道流。 -
使用
Arrays.stream()方法,将数组转换为管道流。
String[] array = {
"Monkey", "Lion", "Giraffe", "Lemur"};
// 将数组转化为管道流
Stream<String> nameStrs2 = Stream.of(array);
Stream<String> nameStrs3 = Stream.of("Monkey", "Lion", "Giraffe", "Lemur");
String[] split = "hello".split("");
Stream<String> stream = Arrays.stream(split);
2.集合类对象转换为管道流
调用集合类的stream()方法,将集合类对象转换为管道流。
// List转换为管道流
List<String> list = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
Stream<String> streamFromList = list.stream();
// Set转换为管道流
Set<String> set = new HashSet<>(list);
Stream<String> streamFromSet = set.stream();
// Map转换到管道流
Map<String, Integer> codes = new HashMap<>();
codes.put("United States", 1);
Stream<Map.Entry<String, Integer>> stream = codes.entrySet().stream();
3.文本文件转换为管道流
通过Files.lines()方法将文本文件转换为管道流
Stream<String> lines = Files.lines(Paths.get("文本文件所在的路径"));
二.Stream的Filter与谓词逻辑
准备一个实体类Employee
import java.util.function.Predicate;
public class Employee {
private Integer id;
private Integer age;
private String gender;
private String firstName;
private String lastName;
// filter函数中lambda表达式为一次性使用的谓词逻辑。
// 若我们的谓词逻辑需要被多处、多场景、多代码中使用,通常将它抽取出来单独定义到它所限定的主语实体中。
public static Predicate<Employee> ageGreaterThan70 = x -> x.getAge() > 70;
public static Predicate<Employee> genderM = x -> x.getGender().equals("M");
// 省略构造方法,get,set方法,toString()方法
}
1.普通的filter函数过滤
List<Employee> employees = Arrays.asList("若干个Employee对象");
List<Employee> filtered = employees.stream()
// 由于使用了lambda表达式,此过滤逻辑只能在此处使用,如果想要在其他地方使用需要重新定义一遍
.filter(e -> e.getAge() > 70 && e.getGender().equals("M"))
.collect(Collectors.toList());
List<Person> filterList = persons.stream()
// 过滤出性别为1的person对象
.filter(p -> p.getSex().equals(1))
.collect(Collectors.toList());
2.谓词逻辑and的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.and(Employee.genderM))
.collect(Collectors.toList());
3.谓语逻辑or的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM))
.collect(Collectors.toList());
4.谓语逻辑negate(取反)的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM).negate())
.collect(Collectors.toList());
三.Stream的Map操作
map函数的作用就是针对管道流中的每一个数据元素进行转换操作。
1.集合元素转换成大写
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
// 使用Stream管道流
List<String> collect = alpha
.stream()
// 使用map将集合中的每一个元素都转换为大写
.map(String::toUpperCase)
.collect(Collectors.toList());
// 上面使用了方法引用,和下面的lambda表达式语法效果是一样的
List<String> collect = alpha
.stream().map(s -> s.toUpperCase())
.collect(Collectors.toList());
2.集合元素类型的转换
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
List<Integer> lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); // [6, 4, 7, 5]
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);
// 将0和1的List转换为Boolean的List
List<String> alpha = Arrays.asList("1", "0", "0", "1");
List<Boolean> collect = alpha.stream()
.map(ele -> "1".equals(ele))
.collect(Collectors.toList());
3.对象数据格式转换
public static void main(String[] args){
// 准备一个List对象
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
// map的方式进行处理
List<Employee> maped = employees.stream()
.map(e -> {
// 将年龄全部+1
e.setAge(e.getAge() + 1);
// 对性别进行判断
e.setGender(e.getGender().equals("M") ? "male" : "female");
// 将处理后的对象返回
return e;
}).collect(Collectors.toList());
// peek的方式进行处理
List<Employee> maped = employees.stream()
// peek函数是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}
4. Stream::ofNullable 过滤空值
- 通过
Stream::ofNullable过滤出null的数据
// 含有null值的List集合
List<String> nameList = Arrays.asList("张三", null, "李四", null, "王五", null);
// 通过 Stream::ofNullable 过滤出null的数据
List<String> names = nameList.stream().flatMap(Stream::ofNullable).toList();
System.out.println(names); // [张三, 李四, 王五]
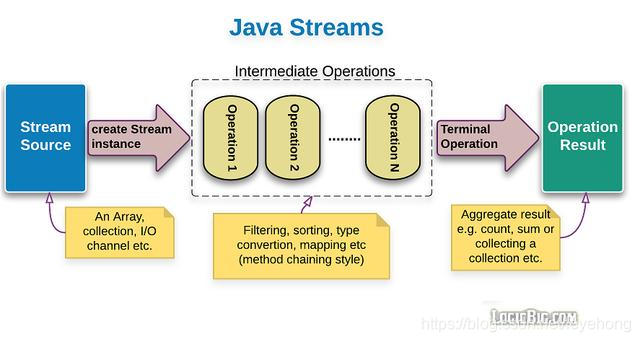
四.Stream的状态与并行操作
- 源操作:可以将数组、集合类、行文本文件转换成管道流Stream进行数据处理。
- 中间操作:对Stream流中的数据进行处理,比如:过滤、数据转换等等。
- 终端操作:作用就是将Stream管道流转换为其他的数据类型。
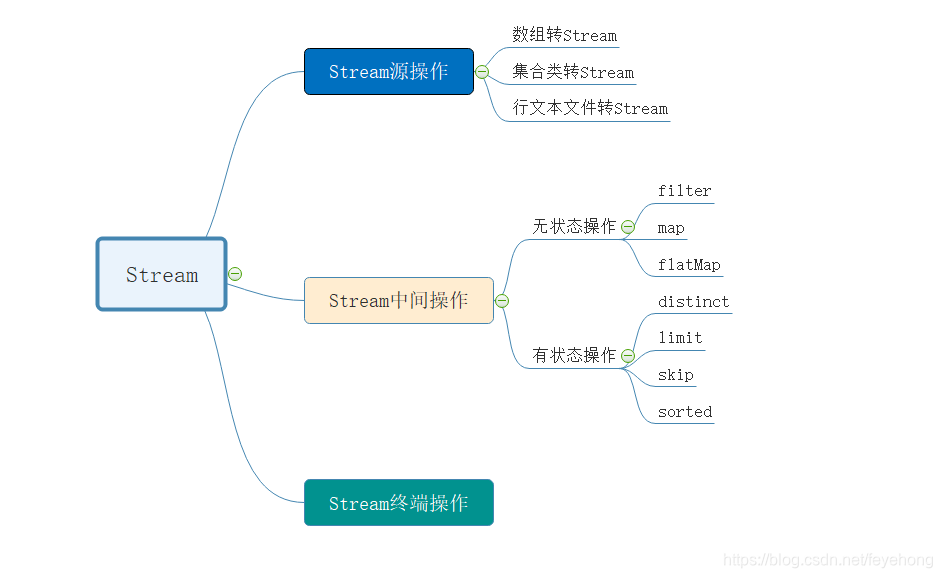
Stream中间操作
-
无状态:
filter与map操作,不需要管道流的前面后面元素相关,所以不需要额外的记录元素之间的关系。输入一个元素,获得一个结果。就像班级点名就是无状态的,喊到你你就答到就可以了。
-
有状态:
sorted是排序操作、distinct是去重操作。像这种操作都是和别的元素相关的操作,我自己无法完成整体操作。如果是班级同学按大小个排序,那就不是你自己的事了,你得和周围的同学比一下身高并记住,你记住的这个身高比较结果就是一种“状态”。所以这种操作就是有状态操作。
4.1.Limit与Skip管道数据截取
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
// limt方法传入一个整数n,用于截取管道中的前n个元素。
.limit(2)
.collect(Collectors.toList());
limitN.forEach(System.out::println); // [Monkey, Lion]
List<String> skipN = < 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2068
2068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









