



 本文探讨了HadoopDB作为弱关系型数据仓库解决方案的特点,并将其与GreenPlum进行了对比。介绍了HadoopDB如何结合PostgreSQL和MapReduce技术,并讨论了其SQL到MapReduce转换的挑战。同时,提到了Facebook的Hive项目以及这些解决方案在Share-Nothing架构中的应用。
本文探讨了HadoopDB作为弱关系型数据仓库解决方案的特点,并将其与GreenPlum进行了对比。介绍了HadoopDB如何结合PostgreSQL和MapReduce技术,并讨论了其SQL到MapReduce转换的挑战。同时,提到了Facebook的Hive项目以及这些解决方案在Share-Nothing架构中的应用。
首先思考一个问题:针对弱关系型数据的数据仓库解决方案会是怎样的?
耶鲁大学的这个 HadoopDB 研究项目挺有意思。这是个并行 DBMS(PostgreSQL) 技术和 MapReduce 的结合的产物。
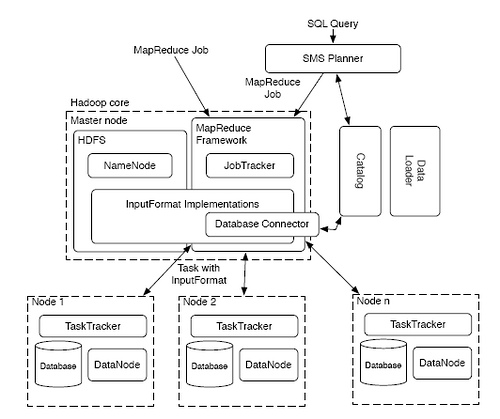
(上图来源)
上图中的 SMS 是 “SQL to MapReduce to SQL” 的缩写。这是 HadoopDB 的一个设计难点。经过了两层转换,对于 SQL 执行的效率多少会是个问题。
也可以对比一下 Facebook 的 Hive :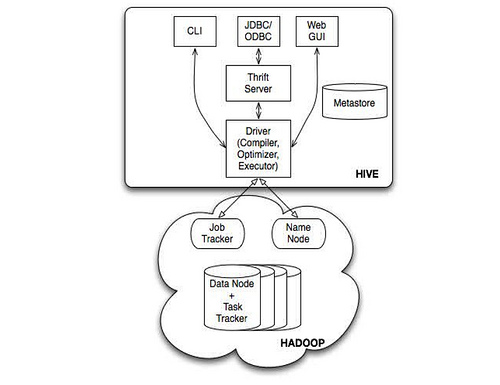
说起 DBMS 和 MapReduce 结合,自然要提起 GreenPlum, 原来是 Hadoop 的间接竞争对手,现在变成直接的了。相比来说,GreenPlum 要更成熟一些。HadoopDB 毕竟是学院派的东西。
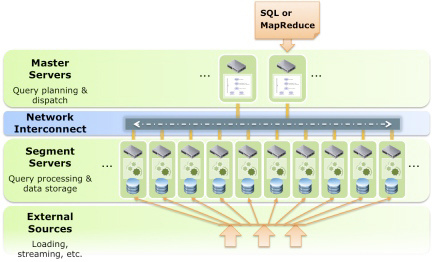
二者都是典型的 Share-Nothing 结构。类似 Oracle 集群的 Share-Storage 的模式现在已经有点过时了。更多混搭出来的技术解决方案让人喜忧参半,喜的是有很多东西可以选择,忧的是你不知道哪个项目生命期更长久。
–EOF–
Google+

















 4316
4316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









