




 XLNet结合了自回归(AR)和自编码(AE)语言模型的优势,通过引入排列语言模型(PLM)和两流自我注意力机制,解决了AR模型无法利用双向信息及AE模型预训练与微调不一致的问题,实现了上下文双向信息的利用,同时避免了[MASK]token带来的训练不一致性。
XLNet结合了自回归(AR)和自编码(AE)语言模型的优势,通过引入排列语言模型(PLM)和两流自我注意力机制,解决了AR模型无法利用双向信息及AE模型预训练与微调不一致的问题,实现了上下文双向信息的利用,同时避免了[MASK]token带来的训练不一致性。
背景
我们先对现有的预训练语言模型做个分类讨论。
语言模型AR vs AE
按照预训练语言模型的学习目标,可以分为自回归语言模型(Autoregressive, AR)和自编码语言模型(Autoencoding, AE)两种。
Autoregressive LM
自回归语言模型(Autoregressive LM, AR), 通俗的来说就是单向语言模型,通过过去时刻已知的结果去预测下一个时刻(或者反向)。对于AR语言模型,给定一个序列
X
=
(
x
1
,
x
2
,
.
.
.
,
x
T
)
X = (x_1, x_2, ... ,x_T)
X=(x1,x2,...,xT), 其出现的概率
p
(
X
)
=
∏
t
=
1
T
p
(
x
t
∣
x
<
t
)
p(X) = \prod_{t=1}^T{p(x_t|x_{<t})}
p(X)=∏t=1Tp(xt∣x<t) 或者反向
p
(
X
)
=
∏
t
=
T
1
p
(
x
t
∣
x
>
t
)
p(X) =\prod_{t=T}^1{p(x_t|x_{>t})}
p(X)=∏t=T1p(xt∣x>t),目标是最大化概率
max
θ
l
o
g
p
θ
(
X
)
=
∑
t
=
1
T
l
o
g
(
p
θ
(
x
t
∣
x
<
t
)
)
=
∑
t
=
1
T
l
o
g
exp
(
h
θ
(
x
1
:
t
−
1
)
⊤
e
(
x
t
)
)
∑
x
′
exp
(
h
θ
(
x
1
:
t
−
1
)
⊤
e
(
x
′
)
)
\max \limits_{\theta} logp_{\theta}(X) = \sum_{t=1}^Tlog(p_{\theta}(x_t|x_{<t})) = \sum_{t=1}^Tlog\frac{\exp({h_{\theta}(x_{1:t-1})}^\top{e(x_t)})}{\sum_{x\prime}\exp({h_{\theta}(x_{1:t-1})}^\top{e(x\prime)})}
θmaxlogpθ(X)=t=1∑Tlog(pθ(xt∣x<t))=t=1∑Tlog∑x′exp(hθ(x1:t−1)⊤e(x′))exp(hθ(x1:t−1)⊤e(xt))
其中
e
(
x
)
e(x)
e(x)是x的embedding。比如之前的OpenAI-GPT和ELMo(虽然是双向的,但本质是两个单向的concat起来)都是属于AR语言模型
Autoencoding LM
自编码语言模型(Autoencoding LM, AE), 通俗的来说就是重构不完整(部分词被mask)的语料。同上,模型的目标是从mask的序列中预测被mask词,最大化其概率
max
θ
l
o
g
p
θ
(
x
ˉ
∣
x
^
)
≈
∑
t
=
1
T
m
t
l
o
g
p
θ
(
x
t
∣
x
^
)
=
∑
t
=
1
T
m
t
l
o
g
exp
(
H
θ
(
x
^
)
⊤
e
(
x
t
)
)
∑
x
′
exp
(
H
θ
(
x
^
)
⊤
e
(
x
′
)
)
\max \limits_{\theta} logp_{\theta}(\bar{x}|\hat{x}) \approx\sum_{t=1}^Tm_tlogp_{\theta}(x_t|\hat{x}) = \sum_{t=1}^Tm_tlog\frac{\exp({H_{\theta}(\hat{x})}^\top{e(x_t)})}{\sum_{x\prime}\exp({H_{\theta}(\hat{x})}^\top{e(x\prime)})}
θmaxlogpθ(xˉ∣x^)≈t=1∑Tmtlogpθ(xt∣x^)=t=1∑Tmtlog∑x′exp(Hθ(x^)⊤e(x′))exp(Hθ(x^)⊤e(xt))
其中,
x
^
\hat{x}
x^是被mask的序列,
x
ˉ
\bar{x}
xˉ是所有被mask的tokens,
m
t
=
1
m_t=1
mt=1表示t时刻的token即
x
t
x_t
xt被mask。代表模型有Word2Vec的CBOW和BERT。特别的,bert因为用mask进行了干扰,也可以说是 Denoising Auto-Encoding(DAE)。
AR vs AE
- 两者的目标不同,AE是为了重构不完整的序列,公式中的约等号是因为这里假设重构整个序列时和重构每个被mask的单词都是独立的(即all masked tokens x ˉ \bar{x} xˉ are separately reconstruct);而AR是对每个单词的概率做连乘,不存在这种假设
- AE引入了[MASK]的token,这个在fine-tune中没有,即预训练和微调不一致(pretrain-finetune discrepancy), AR没有这个缺陷
- AR模型预测概率只用了单向的信息而AE用了双向的信息,所以AE的预训练模型对文本上下文语义信息学的更好
- AR模型为单向语言模型,由前面的序列预测接下来的token,比较适合本文生成任务,AE就不太适合
Why XLNet comes in?
我们看到了AR和AE的优缺点:AE存在pretrain-finetune discrepancy,概率计算无法像AR连乘;AR无法利用双向信息。有没有一个模型能解决AE和AR缺陷呢? 答案就是XLNet(因为特征提取器采用的是Transformer-XL而命名),通过修改目标,不仅是优化单向序列的概率而是最大化所有排列组合的概率(因为单向也是所有排列组合中的一种,所以也叫广义上的AR模型)进行解决. 论文参考《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
XLNet
Permutation Language Model(PLM)
AR的缺陷是无法同时利用双向信息,因此采用排列语言模型解决这一问题。
Specifically, for a sequence x of length T, there are T! different orders to perform a valid autoregressive factorization
对于一个长度为T的序列,共有T!个排列组合,即T!个类似AR的连乘序列;如果每种排列方式共享同一模型参数,即可学到上下文双向的信息。
PLM其训练目标如下:

即对于一个序列T,sample某个排列组合,计算AR的目标,因为模型共享同一组参数,某个词
x
t
x_t
xt肯定看到过之前和之后的词,这样就能学到双向的信息,并且计算概率基于AR的连乘,也没有[MASK],因此没有AE的独立假设条件也没有训练微调不一致的问题。(需要注意的是这里计算position encoding还是用最开始的顺序,只是用mask来实现排列组合,因此和fine-tune的顺序一致)。
这里我们用一个长度为4的序列举个例子说明

假设要预测3, 排列组合共有4!=24种,例如图中的4种,我们可以发现,输入的顺序是1234,但是利用attention mask,可以屏蔽部分词,达到permutation的目的(比如3->2>4>1, mask所有的词,从memory得到3;2->4->3->1,mask 1, 只attend 2和4去预测3)。注意当句子长度过长的时候,不是计算所有排列组合,而是通过采样的方式进行。
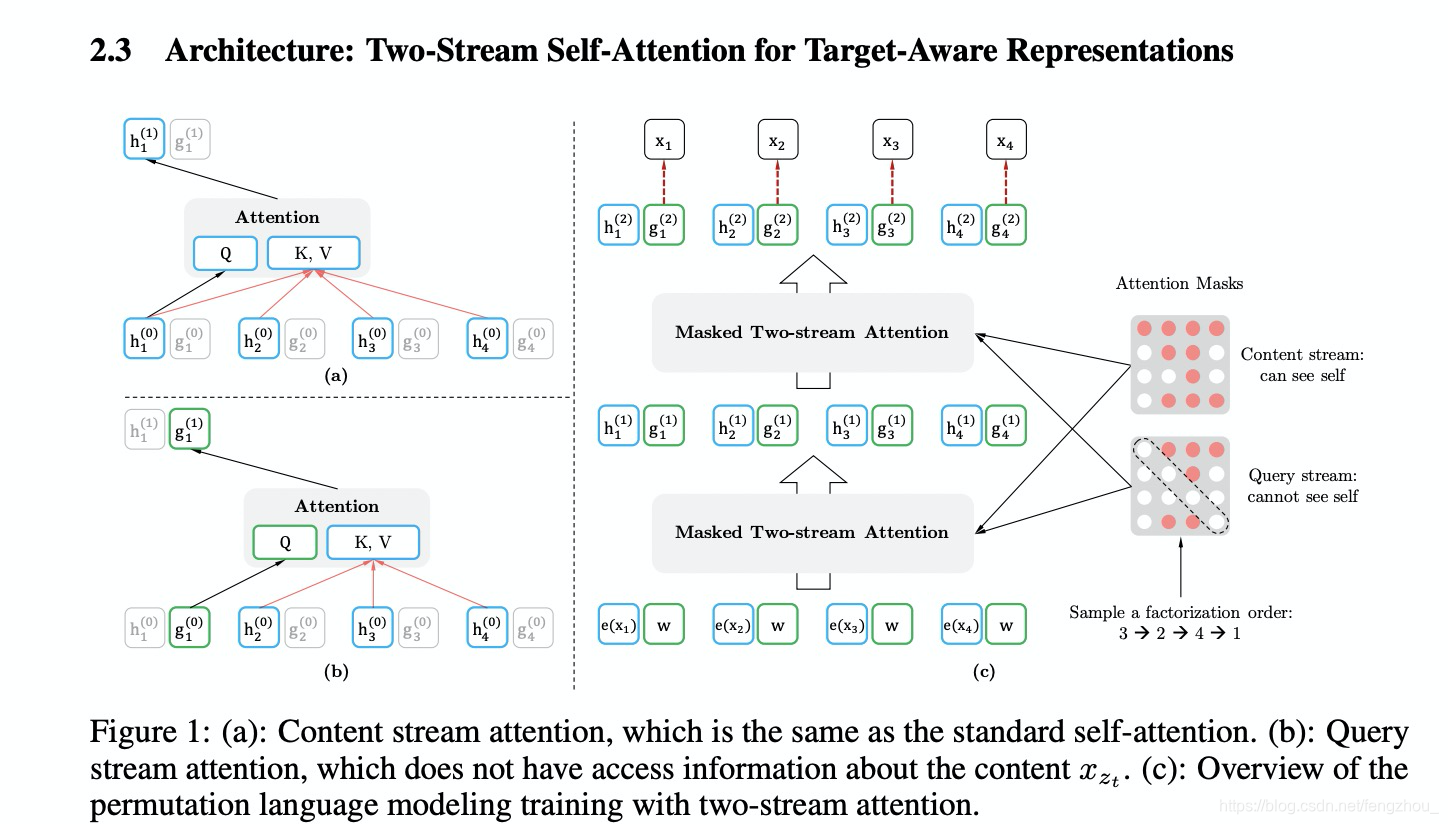
Two-Stream Self-Attention
上述排列组合的方式看似可行,实际存在一个问题。比如对1234的排列组合2->1->3->4和2->1->4->3,预测第三个位置的时的概率和当前的token内容无关。 因此这里引入了新的计算next token probility的方式:
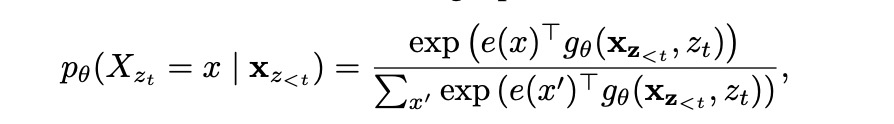
这里的
g
θ
g_{\theta}
gθ引入目标位置信息即
z
t
z_t
zt。
但是实际实现对传统的transform存在如下两个问题
(1) to predict the token xzt, gθ(xz<t , zt) should only use the position zt and not the content xzt, otherwise the objective becomes trivial;
(2) to predict the other tokens xzj with j > t, gθ(xz<t, zt) should also encode thecontent xzt to provide full contextual information
这里解释一下,对于传统的transformer,encoding包含了position和content信息,但是由于是permutation language model,当预测下一个词的时候我们只需要他的position信息(位置被打乱)但不能知道content信息,预测当前词的时候需要前面词的position和content;因此对于permutation language model,我们有时候需要知道position和content信息,有时候只需要知道position信息。因此这里引入了 two-stream self-attention,query stream就是只含position信息但不含content,content stream和原来transformer的一致(既有位置也又content)。

content stream的计算和原来transformer的attention一致,但query stream
即在计算g的时候用上一课的g作为Q,上一时刻的h作为K和V进行self-attentionn计算;但计算h的时候,用上一时刻的h作为Q,上一时刻的h作为K和V。这种方式保证了在fine-tune的一致性,即fine-tune的时候可以忽略g,直接计算h。h初始化为word embedding, g是随机初始化可训练的vector
Partial Prediction
对于长度为N的序列,排列组合个数为N!。因此为了降低计算复杂度,对于长度L=N的序列设置了一个cutting point, c;我们只对大于C以后的token进行predict, 因此模型的训练目标为
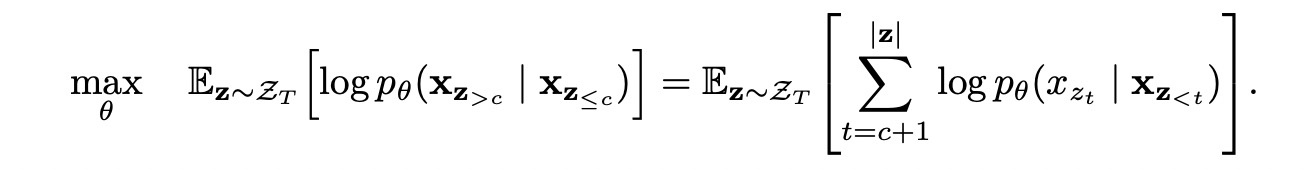
其他
其它和BERT几乎一致,在此参考BERT
模型同时用到了Transformer-XL的ideas,关于Transformer-XL的介绍见Transformer-XL解读
总结
XLNet融合了AR和AE的优点。
如论文标题所说,XLNet是广义上的AR语言模型,依旧采用单向语言模型的目标,但是为了和AEi一样利用上下文双向的信息,同时又不引起因为[MASK]token导致预训练和微调的不一致性,所以引入Permutation Language model代替BERT的Masked Language Model,达到了 state-of-the-art的效果。

















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









