




 本文深入解析朴素贝叶斯分类方法,阐述其基于贝叶斯定理与特征条件独立假设的基本原理,以及如何通过训练数据学习联合概率分布进行分类预测。文章详细介绍了朴素贝叶斯法的参数估计方法,包括极大似然估计与贝叶斯估计,并提供了一个具体的实例说明。
本文深入解析朴素贝叶斯分类方法,阐述其基于贝叶斯定理与特征条件独立假设的基本原理,以及如何通过训练数据学习联合概率分布进行分类预测。文章详细介绍了朴素贝叶斯法的参数估计方法,包括极大似然估计与贝叶斯估计,并提供了一个具体的实例说明。
朴素贝叶斯介绍
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。之所以叫朴素,是因为朴素贝叶斯法对条件概率分布作了条件独立性的假设。朴素贝叶斯法是典型的生成学习方法。生成方法由训练数据学习联合概率分布P(X,Y),然后求得后验概率分布P(X|Y)。
具体来说,利用训练数据学习P(X|Y)和P(Y)的估计,得到联合概率分布:
P(X,Y)=P(X)P(X|Y)
概率估计方法可以是极大极大似然估计或贝叶斯估计。
基本原理
设输入空间X⊆RnX\subseteq R ^{n}X⊆Rn为n维向量的集合,输出空间为类标记集合Y={c1,c2,…,ck}Y=\left\{ c_{1},c_{2},\ldots ,c_{k}\right\}Y={c1,c2,…,ck},输入特征向量x∈X,输出类标记为 y∈Y,P(X,Y)是X和Y的联合概率分布。
训练数据集为T={(x1,y1),(x2,y2),…,(xn,yn)}T=\left\{ \left( x_{1},y_{1}\right) ,\left( x_{2},y_{2}\right) ,\ldots ,\left( x_{n},y_{n}\right) \right\}T={(x1,y1),(x2,y2),…,(xn,yn)}由P(X,Y)独立同分布产生。
朴素贝叶斯法就是通过训练集来学习联合概率分布P(X,Y),和先验概率分布P(X),进而可以算出最大后验概率。
条件概率分布P(X=x|Y=ckc_kck)有指数级数量的参数,其估计实际不可能行的。所以,朴素贝叶斯对条件概率分布作了条件独立性的假设。
条件独立性假设是:
P(X=x∣Y=ck)=P(X(1)=x(1),…,X(n)=x(n)∣Y=ck)=∏j=1np(X(j)=x(j)∣Y=ck)\begin{aligned}P(X=x|Y=c_k)=P(X^{\left( 1\right) }=x^{\left( 1\right) },\ldots ,X^{\left( n\right) }=x^{\left( n\right) }|Y=c_k) \\ =\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right) \end{aligned}P(X=x∣Y=ck)=P(X(1)=x(1),…,X(n)=x(n)∣Y=ck)=j=1∏np(X(j)=x(j)∣Y=ck)
条件独立假设等于是说用于分类的特征在类确定的条件下都是条件独立的。这一假设使朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
朴素贝叶斯法分类时,对给定的输入x,通过学习到的模型计算后验概率分布P(Y=ck∣X=x)P(Y=c_k|X=x)P(Y=ck∣X=x),将后验概率最大的类作为x的类输出。
后验概率计算根据贝叶斯定理算出:
P(Y=ck∣X=x)=P(X=x∣Y=ck)P(Y=ck)∑kP(X=x∣Y=ck)P(Y=ck)P(Y=c_k|X=x)=\dfrac {P(X= x| Y= c_{k}) P( Y= c_{k})}{\sum _{k}P(X= x| Y= c_{k})P(Y= c_{k})}P(Y=ck∣X=x)=∑kP(X=x∣Y=ck)P(Y=ck)P(X=x∣Y=ck)P(Y=ck)
将条件独立假设代入,可得:
P(Y=ck∣X=x)=P(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)∑kP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck),k=1,2,⋅⋅⋅,KP(Y=c_k|X=x)=\dfrac {P( Y= c_{k})\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right) } {\sum _{k}P( Y= c_{k})\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right) },k=1,2,···,KP(Y=ck∣X=x)=∑kP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)P(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck),k=1,2,⋅⋅⋅,K
于是,朴素贝叶斯分类器可以表示为:
y=f(x)=argmaxckP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)∑kP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)y=f(x)=\arg \max _{c_k}\dfrac {P( Y= c_{k})\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right) } {\sum _{k}P( Y= c_{k})\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right) }y=f(x)=argmaxck∑kP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)P(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)
因为分母对所有ckc_kck都是相同的,所以可以将分母省略,最终得到:
y=f(x)=argmaxckP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)y=f(x)=\arg \max _{c_k}P( Y= c_{k})\prod ^{n}_{j=1}p\left( X^{\left( j\right) }=x^{\left( j\right) }|Y=c_k\right)y=f(x)=argmaxckP(Y=ck)∏j=1np(X(j)=x(j)∣Y=ck)
朴素贝叶斯法的参数估计
在朴素贝叶斯法中,我们需要先知道P(Y=ck)P(Y=c_k)P(Y=ck)和P(X(j)=x(j)∣Y=ck)P(X^{\left( j\right) }=x^{\left( j\right) }|Y={c_k})P(X(j)=x(j)∣Y=ck)
就这意味着我们需要通过学习估计出P(Y=ck)P(Y=c_k)P(Y=ck)和P(X(j)=x(j)∣Y=ck)P(X^{\left( j\right) }=x^{\left( j\right) }|Y={c_k})P(X(j)=x(j)∣Y=ck)
我们可以通过极大似然估计和贝叶斯估计,估计出参数
极大似然估计
先验概率P(Y=ck)P(Y=c_k)P(Y=ck)的极大似然估计:
P(Y=ck)=∑i=1NI(yi=ck)N,k=1,2,...,KP(Y=c_k)=\dfrac {\sum ^{N}_{i=1}I(y_i=c_k)} {N},k=1,2,...,KP(Y=ck)=N∑i=1NI(yi=ck),k=1,2,...,K
设第j个特征x(j)x^{(j)}x(j)可能取值的集合为{aj1,aj2,…,ajSj}\left\{a_{j1},a_{j2},…,a_{jS_{j}}\right\}{aj1,aj2,…,ajSj},条件概率P(X(j)=ajl∣Y=ck)P(X^{(j)}=a_{jl}|Y=c_k)P(X(j)=ajl∣Y=ck)的极大似然估计是:
P(X(j)=ajl∣Y=ck)=∑i=1NI(xi(j)=ajl,yi=ck)∑i=1NI(yi=ck)P(X^{(j)}=a_{jl}|Y=c_k)=\dfrac {\sum ^{N}_{i=1}I(x^{\left( j\right) }_{i}=a_{jl},y_i=c_k)} {\sum ^{N}_{i=1}I(y_i=c_k)}P(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)∑i=1NI(xi(j)=ajl,yi=ck)
其中,j=1,2,…,n;l=1,2,…,Sj;k=1,2,…,Kj=1,2,…,n; l=1,2,…,S_j; k=1,2,…,Kj=1,2,…,n;l=1,2,…,Sj;k=1,2,…,K
xi(j)x^{\left( j\right) }_{i}xi(j)是第i个样本的第j个特征,ajla_{jl}ajl是第j个特征可能取的第lll个值,III为指示函数。
贝叶斯估计
用极大似然估计可能会出现所要估计的概率值为0的情况。这会影响到后验概率的计算结果,使分类产生偏差。解决这一问题的方法是采用贝叶斯估计。
条件概率的贝叶斯是:
Pλ(X(j)=ajl∣Y=ck)=∑i=1NI(xi(j)=ajl,yi=ck)+λ∑i=1NI(yi=ck)+SjλP_λ(X^{(j)}=a_{jl}|Y=c_k)=\dfrac {\sum ^{N}_{i=1}I(x^{\left( j\right) }_{i}=a_{jl},y_i=c_k)+λ} {\sum ^{N}_{i=1}I(y_i=c_k)+S_jλ}Pλ(X(j)=ajl∣Y=ck)=∑i=1NI(yi=ck)+Sjλ∑i=1NI(xi(j)=ajl,yi=ck)+λ
其中λ≥0.
等价于在随机变量各个取值的频数上赋予一个正数λ>0.当λ=0时就是极大似然估计.
常取λ=1,这时称为拉普拉斯平滑。
显然,对于任何的l和kl和kl和k,都有:
Pλ(X(j)=ajl∣Y=ck)>0P_λ(X^{(j)}=a_{jl}|Y=c_k)>0Pλ(X(j)=ajl∣Y=ck)>0
∑l=1SjP(X(j)=ajl∣Y=ck)=1\sum ^{S_j}_{l=1}P(X^{(j)}=a_{jl}|Y=c_k)=1∑l=1SjP(X(j)=ajl∣Y=ck)=1
先验概率的贝叶斯估计为:
Pλ(Y=ck)=∑i=1NI(yi=ck)+λN+KλP_λ(Y=c_k)=\dfrac {\sum ^{N}_{i=1}I(y_i=c_k)+λ} {N+Kλ}Pλ(Y=ck)=N+Kλ∑i=1NI(yi=ck)+λ
例子
下面的是《统计学习方法》中的例题:

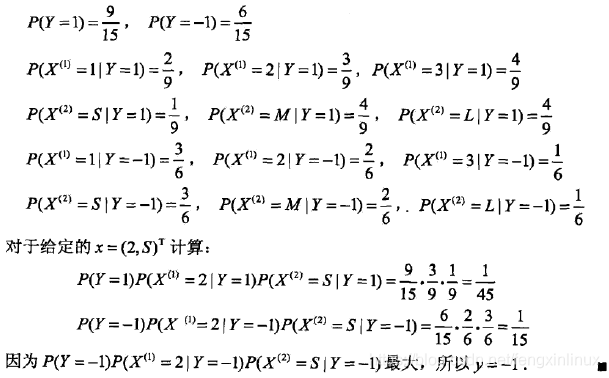

















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









