






大小端存储:
大端模式,是指数据的高字节保存在内存的低地址中,而低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,数据从高位往低位放。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
这里我们举例小段存储类型a=0x12345678
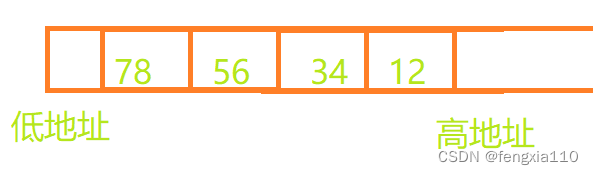
因为在一个字节中并不存在低地址或高地址,所以是按顺序存放
此处可以明显发现权重较小的在低地址处,权重较大的在高地址处。
小端存储则相反。
判断方法:
我们可以利用权重低的在低地址处存放的原理来进行判断;
如:a=1;
我们利用char* 指针访问低地址处的元素;
如果为1,为小端存储;为0,为大段存储。
代码:
#include<stdio.h>
int main()
{
int a = 1;
char* p = &a;
if (*p)
{
printf("小端存储\n");
}
else
{
printf("大端存储\n");
}
return 0;
}
结果展示:
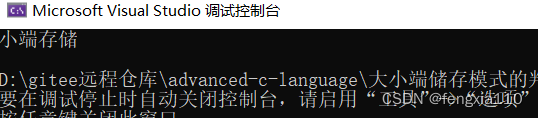
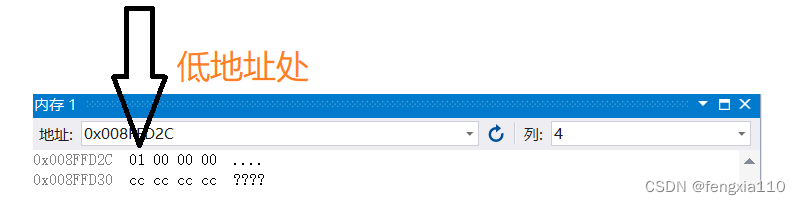
我们也可以看一下a在内存中的储存方式
结语:
希望大家多多支持,你的点赞是我创作的动力!

















 1045
1045


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








