



 本文以IMDB电影评论情感分析为例,详细介绍如何使用TensorFlow 2.0和Keras进行文本分类任务,从数据预处理、模型构建、训练到模型保存的全过程。
本文以IMDB电影评论情感分析为例,详细介绍如何使用TensorFlow 2.0和Keras进行文本分类任务,从数据预处理、模型构建、训练到模型保存的全过程。
修改上版代码格式问题。Tensorflow2.0跟Keras紧密结合,相比于1.0版本,2.0可以更快上手,并且能更方便找到需要的api。本文中以IMDB文本分类为例,简单介绍了从数据下载、预处理、建模、训练到模型保存等等在2.0中的操作,可以让你从无到有快速入门。
实战系列篇章中主要会分享,解决实际问题时的过程、遇到的问题或者使用的工具等等。如问题分解、bug排查、模型部署等等。相关代码实现开源在:https://github.com/wellinxu/nlp_store
数据下载与处理
数据下载
重构词的索引
简单预处理
模型构建
sequential方式
subclass方式
模型训练与评估
模型的保存与加载
checkpoint方式
hdf5方式
saved_model
参考
数据下载与处理
数据下载
import tensorflow as tf
# 下载IMDB数据
vocab_size = 10000 # 保留词的个数
imdb = tf.keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=vocab_size)
print("train len:", len(train_data)) # [25000]
print("test len:", len(test_data)) # [25000]
IMDB数据集已经打包在tensorflow中,可以方便的下载,vocab_size是保留了训练数据中最常见的词,删除了一些低频词。
重构词的索引
# 一个将单词映射到整数索引的词典
word_index = imdb.get_word_index() # 索引从1开始
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
原来的索引是从1开始创建的,新建的索引将所有词的index都加了3,然后添加了4个新的词。
简单预处理
# 统一文本序列长度
train_data = tf.keras.preprocessing.sequence.pad_sequences(train_data, value=word_index["<PAD>"], padding="post", truncating="post", maxlen=256)
test_data = tf.keras.preprocessing.sequence.pad_sequences(test_data, value=word_index["<PAD>"], padding="post", truncating="post", maxlen=256)
因为文本有长有短,这个处理是将所有文本都处理成统一的长度,太长的截断,太短的补全。参数中,value是补全时用的值,padding是表示太短时在前面补还是后面补,truncating表示太长时在前面截断还是后面截断,maxlen表示统一的长度。
模型构建
使用的模型结构如下图所示,输入接入embedding层,然后是一层全局平均池化层,再接两层全连接即输出: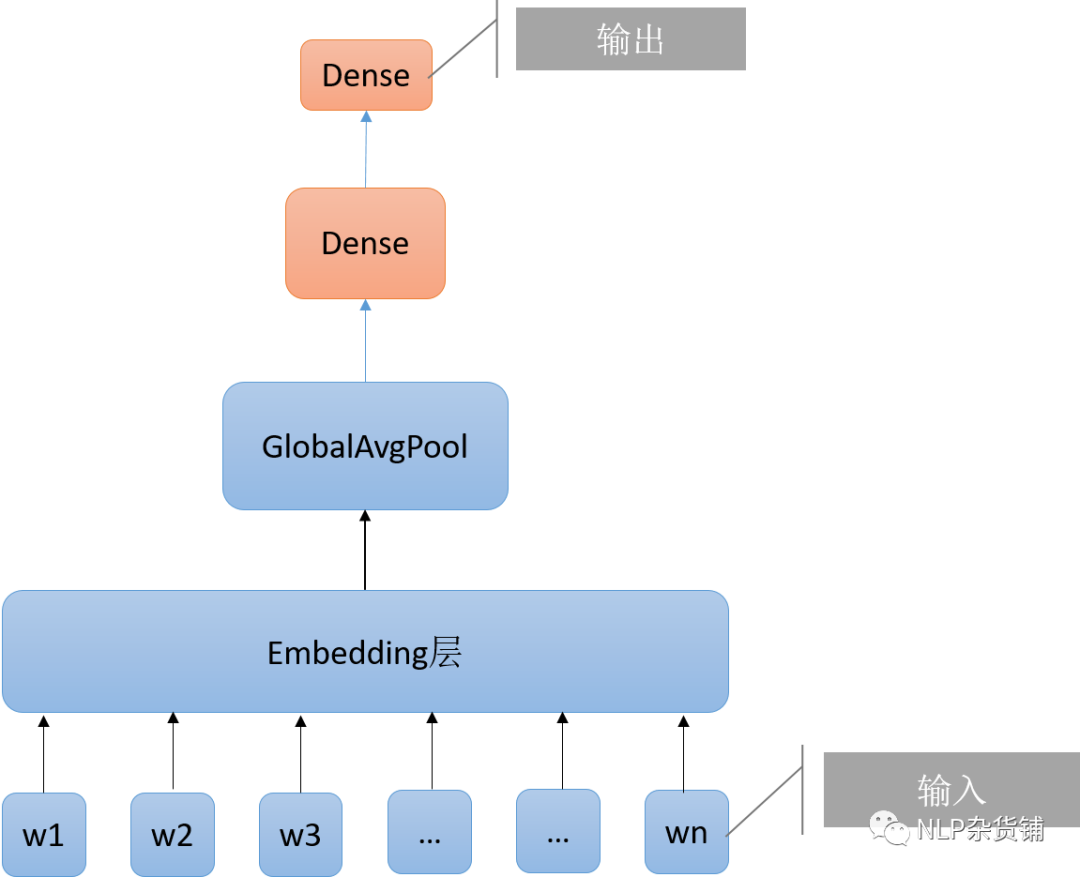
sequential方式
# model = tf.keras.Sequential()
# model.add(tf.keras.layers.Embedding(vocab_size, 16)) # [batch_size, seq_len, 16]
# model.add(tf.keras.layers.GlobalAveragePooling1D()) # [batch_size, 16]
# model.add(tf.keras.layers.Dense(16, activation='relu')) # [batch_size, 16]
# model.add(tf.keras.layers.Dense(1, activation='sigmoid')) # [batch_size, 1]
# 上下这两种方式是完全等价的
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 16), # [batch_size, seq_len, 16]
tf.keras.layers.GlobalAveragePooling1D(), # [batch_size, 16]
tf.keras.layers.Dense(16, activation='relu'), # [batch_size, 16]
tf.keras.layers.Dense(1, activation='sigmoid') # [batch_size, 1]
])
model.summary() # 打印网络结构概览
代码中注释的部分跟下面部分是完全等价的,tf2.0中,可以在tf.keras.layers里方便地找到各种已经实现好的层。sequential方式顾名思义就是将模型当作一个序列,一层一层地叠加在一起就可以构建出简单的模型。其优点是简单易用,缺点是缺少灵活性。上面网络结构图的打印结果是: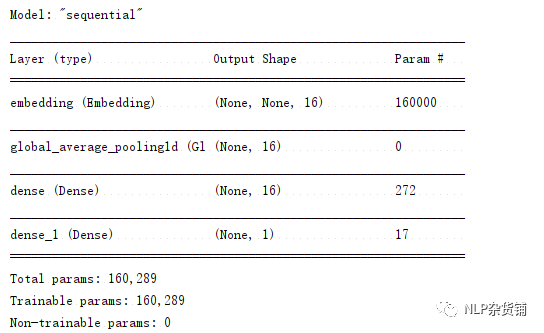
subclass方式
class MyModel(tf.keras.models.Model):
def __init__(self):
super(MyModel, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, 16)
self.g_avg_pool = tf.keras.layers.GlobalAveragePooling1D()
self.d1 = tf.keras.layers.Dense(16, activation="relu")
self.d2 = tf.keras.layers.Dense(1, activation="sigmoid")
def call(self, inputs, training=None, mask=None):
# inputs: [batch_size, seq_len]
x = self.embedding(inputs) # [batch_size, seq_len, 16]
x = self.g_avg_pool(x) # [batch_size, 16]
x = self.d1(x) # [batch_size, 16]
x = self.d2(x) # [batch_size, 1]]
return x
model = MyModel()
通过继承tf.keras.models.Model类来实现自己的模型类,可以在__init__方法中初始化各个层,在call方法实现从输入到输出的流程计算。此方法可以实现相对复杂的网络结构,后续文章会讲到的自定义层跟这种形式也非常类似。
模型训练与评估
# 配置模型训练参数
# model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.BinaryCrossentropy(), metrics=[tf.keras.metrics.BinaryAccuracy()])
# 训练模型
history = model.fit(train_data, train_labels, epochs=40, batch_size=512)
# 评估测试集
model.evaluate(test_data, test_labels, verbose=2)
首先要对模型进行编译,也就是给模型制定优化器、loss、指标计算方式等等,这三个都可以方便地在tf.keras.optimizers/tf.keras.losses/tf.keras.metrics里找到已实现好的类。
模型训练只要简单地调用fit方法就可以实现,可以制定迭代轮次,batch大小,验证集,回调函数等等。返回值history里面包含了训练过程中的loss跟指标的值。fit方法封装得很好,但也因此失去了灵活性,模型训练也可以用更细致的方式,具体的后续文章再介绍。
上面运行的结果是:
模型的保存与加载
checkpoint方式
# 保存权重
model.save_weights("checkpoint/my_checkpoint")
# 加载权重
new_model = create_model_by_subclass()
# 预测之前需要先编译
new_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
new_model.load_weights("checkpoint/my_checkpoint")
# 评估测试集
new_model.evaluate(test_data, test_labels, verbose=2)
checkpoint方式只保留了模型的权重,并没有保留模型结构。优点是保存的模型较小,缺点是不知道模型结构的时候就不好用。因为只保存了权重,所以在加载过程中,需要先构建模型(并编译),然后才能使用。
hdf5方式
"""只能用于Functional model or a Sequential model,目前不能用于subclassed model,2020-06"""
# 保存模型
model.save("h5/my_model.h5")
# 加载模型
# 重新创建完全相同的模型,包括其权重和优化程序
new_model = tf.keras.models.load_model('h5/my_model.h5')
# 显示网络结构
new_model.summary()
# 评估测试集
new_model.evaluate(test_data, test_labels, verbose=2)
hdf5方式既保留了模型权重也保留了模型结构,但目前只能保存用sequential方式构建的模型,subclass方式构建的模型则不能保存为hdf5模型。因为其保留了模型结构,所以模型加载后就可以直接使用,也方便移植到其他环境中使用。
saved_model
# 保存模型
tf.saved_model.save(model, "saved_model/1")
# 加载模型
new_model = tf.saved_model.load("saved_model/1")
# 预测结果
result = new_model(test_data)
saved_model方式跟hdf5一样将整个模型都保留下来了,这种格式可以保存各种方法构建的模型。saved_model格式常用于预测或部署时,跟前两种情况不同,这种格式加载后的模型,已经不具备Model(sequential或subclass方式构建的模型)的一些特性,比如没有了fit,evaluate方法,但可以用来直接进行预测。这种格式常用在tensorflow serving中。
参考
https://tensorflow.google.cn/tutorials/quickstart/beginner?hl=zh_cn
https://tensorflow.google.cn/tutorials/quickstart/advanced?hl=zh_cn
https://tensorflow.google.cn/tutorials/keras/text_classification?hl=zh_cn
https://tensorflow.google.cn/tutorials/keras/save_and_load?hl=zh_cn

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085。加入微信群请扫码进群:


















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









