




 本文深入探讨了Protobuf源码中的一些优秀实践,包括使用宏提高代码可读性,如CHARACTER_CLASS和PROTOBUF_DEFINE_ACCESSOR等;资源分配的lazy机制,如DescriptorPool的分层设计和GeneratedMessageFactory的延迟加载;内存复用策略,如RepeatedPtrFieldBase如何实现message的clear与复用;以及封装多种类型和模版参数的处理方式。通过对这些设计的学习,可以提升代码质量和效率。
本文深入探讨了Protobuf源码中的一些优秀实践,包括使用宏提高代码可读性,如CHARACTER_CLASS和PROTOBUF_DEFINE_ACCESSOR等;资源分配的lazy机制,如DescriptorPool的分层设计和GeneratedMessageFactory的延迟加载;内存复用策略,如RepeatedPtrFieldBase如何实现message的clear与复用;以及封装多种类型和模版参数的处理方式。通过对这些设计的学习,可以提升代码质量和效率。
使用宏来提高代码可读性(代码的美感)
例1.宏CHARACTER_CLASS
定义
tokenizer.cc文件中,需要判断某个character是属于哪种类型的字符,通过宏CHARACTER_CLASS来定义字符类型,并且定义static类型的InClass()接口来判断。
#define CHARACTER_CLASS(NAME, EXPRESSION) \
class NAME { \
public: \
static inline bool InClass(char c) { \
return EXPRESSION; \
} \
}
CHARACTER_CLASS(Whitespace, c == ' ' || c == '\n' || c == '\t' ||
c == '\r' || c == '\v' || c == '\f');
CHARACTER_CLASS(Unprintable, c < ' ' && c > '\0');
CHARACTER_CLASS(Digit, '0' <= c && c <= '9');
CHARACTER_CLASS(OctalDigit, '0' <= c && c <= '7');
CHARACTER_CLASS(HexDigit, ('0' <= c && c <= '9') ||
('a' <= c && c <= 'f') ||
('A' <= c && c <= 'F'));
CHARACTER_CLASS(Letter, ('a' <= c && c <= 'z') ||
('A' <= c && c <= 'Z') ||
(c == '_'));
CHARACTER_CLASS(Alphanumeric, ('a' <= c && c <= 'z') ||
('A' <= c && c <= 'Z') ||
('0' <= c && c <= '9') ||
(c == '_'));
CHARACTER_CLASS(Escape, c == 'a' || c == 'b' || c == 'f' || c == 'n' ||
c == 'r' || c == 't' || c == 'v' || c == '\\' ||
c == '?' || c == '\'' || c == '\"');
#undef CHARACTER_CLASS使用
使用时可以直接使用InClass():
template<typename CharacterClass>
inline bool Tokenizer::TryConsumeOne() {
if (CharacterClass::InClass(current_char_)) {
NextChar();
return true;
} else {
return false;
}
}例2.宏 PROTOBUF_DEFINE_ACCESSOR
FieldDescriptor类,因为可能类型是多样的,在实现对外暴露default数据的函数时,为了提高代码可读性,使用了如下宏的方式(文件descriptor.cc中):
定义
// These macros makes this repetitive code more readable.
#define PROTOBUF_DEFINE_ACCESSOR(CLASS, FIELD, TYPE) \
inline TYPE CLASS::FIELD() const { return FIELD##_; }使用
PROTOBUF_DEFINE_ACCESSOR(FieldDescriptor, default_value_int32 , int32 )
PROTOBUF_DEFINE_ACCESSOR(FieldDescriptor, has_default_value, bool)例3.宏BUILD_ARRAY
定义
BUILD_ARRAY宏定义如下,这里的INPUT是proto;OUTPUT是proto对应的descriptor;NAME是需要完成创建的成员;METHOD是创建descriptor成员时需要调用的函数;PARENT是发生嵌套时的上一级。
// A common pattern: We want to convert a repeated field in the descriptor
// to an array of values, calling some method to build each value.
#define BUILD_ARRAY(INPUT, OUTPUT, NAME, METHOD, PARENT) \
OUTPUT->NAME##_count_ = INPUT.NAME##_size(); \
AllocateArray(INPUT.NAME##_size(), &OUTPUT->NAME##s_); \
for (int i = 0; i < INPUT.NAME##_size(); i++) { \
METHOD(INPUT.NAME(i), PARENT, OUTPUT->NAME##s_ + i); \
}使用
DescriptorBuilder::BuildFile()中,利用FileDescriptorProto& proto来构建对应的descriptor:
// Convert children.
BUILD_ARRAY(proto, result, message_type, BuildMessage , NULL);
BUILD_ARRAY(proto, result, enum_type , BuildEnum , NULL);
BUILD_ARRAY(proto, result, service , BuildService , NULL);
BUILD_ARRAY(proto, result, extension , BuildExtension, NULL);说明
各个Descriptor类中,使用count + 连续内存来保存成员,例如:
class LIBPROTOBUF_EXPORT FileDescriptor {
//省略其它代码
int message_type_count_;
Descriptor* message_types_;
//省略其它代码
}资源分配/处理的lazy机制
例1.类DescriptorPool数据分层设计
DescriptorPool的数据管理分为了多层(忽略了仅在protobuf内部使用 && 不推荐使用的underlay一层):
- 最顶层:
DescriptorPool::Tables tables_,保存name->descriptor; - 最底层:
DescriptorDatabase* fallback_database_,保存name->file_descriptor_proto(而不是直接的file_descriptor)
查找时,如果第一层tables_没找到,最终会到fallback_database_中找对应proto,并且调用临时构造的DescriptorBuilder::Build*()系列接口把生成的descriptor添加到tables_中,然后再从tables_中找。
这样数据分层设计的目的是:
- 用于定制地(on-demand)从某种”大”的database加载产生DescriptorPool。因为database太大,逐个调用
DescriptorPool::BuildFile()来处理原database中的每一个proto文件是低效的。
为了提升效率,使用DescriptorPool来封装DescriptorDatabase,并且只建立正真需要的descriptor。 - 针对编译依赖的每个proto文件,并不是在进程启动时,直接构建出proto中所包含的所有descriptor,而是hang on,直到某个descriptor真的被需要:
(1)用户调用例如descriptor(), GetDescriptor(), GetReflection()的方法,需要返回descriptor;
(2)用户从DescriptorPool::generated_pool()中查找descriptor;
可以看到descriptor的构建是hang-on的,只有需要使用某个descriptor时,才构建。适合依赖了很多的proto文件,但仅仅使用其中的少数proto的场景。
例2.类GeneratedMessageFactory映射关系加载
GeneratedMessageFactory类,管理的从Descriptor* -> Message*映射关系,并不是一开始就注册好的。仅仅在需要从descriptr查找message时(调用GeneratedMessageFactory::GetPrototype()),才会:
- 通过file_name找到注册函数;
- 调用注册函数,完成
Descriptor* -> Message*映射关系的注册; - 从
hash_map<const Descriptor*, const Message*> type_map_查找到对应Message*返回;
资源管理/内存复用
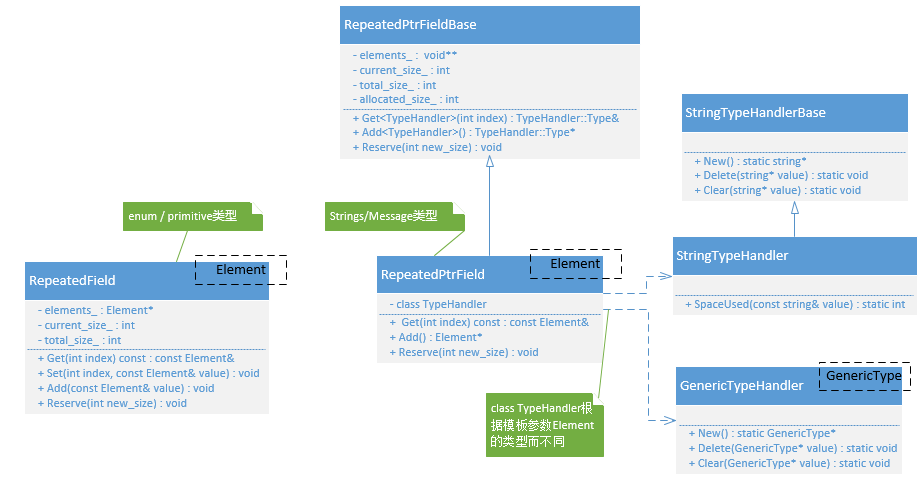
类RepeatedPtrFieldBase
RepeatedPtrFields的父类(不是模板类,提供了多个模板函数),本身保存/管理的数据类型为void*(message对象的实际地址,也是通过连续内存array来保存)。
因为array中保存的是同一个descriptor对应的message,只是各个message中所包含的数据不一样,为了节省下message对象分配/释放的成本,所以message可以被clear(clear操作会将primitive类型的field设置为0,其余类型field调用自身的clear()接口处理,类似std::string::clear(),只清理数据并不回收内存)。
然后保留原有的内存地址在array中。下次需要从array中分配message时,优先使用这一批被clear的message(实现在RepeatedPtrFieldBase::AddFromCleared() ,参考GeneratedMessageReflection::AddMessage()中的调用方式)。
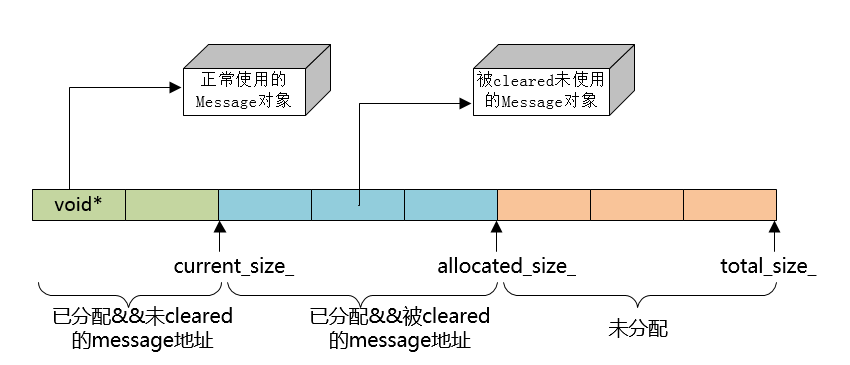
为了管理cleared状态的message指针,引入了多个游标来标记数据:
current_size_: 当前待处理的message地址;allocated_size_:已经分配message的数据,current_size_ <= allocated_size_,从current_size_到allocated_size_之间的message就是被cleared的;total_size_:elements_[]的长度,但从allocated_size_到total_size_之间的void*是无效的,并没有指向任何message;
对应内存分布如下图所示:
封装多种类型,统一对外的服务
针对数据/行为简单的类型,使用轻量级的方案(struct/enum/union/switch-case),来实现类型的封装,而不是采用继承方式来实现。
Symbol可能有多种类型,enum Type表示具体类型,union让多种类型都复用同一个内存地址:
struct Symbol {
enum Type {
NULL_SYMBOL, MESSAGE, FIELD, ENUM, ENUM_VALUE, SERVICE, METHOD, PACKAGE
};
Type type;
union {
const Descriptor* descriptor;
const FieldDescriptor* field_descriptor;
const EnumDescriptor* enum_descriptor;
const EnumValueDescriptor* enum_value_descriptor;
const ServiceDescriptor* service_descriptor;
const MethodDescriptor* method_descriptor;
const FileDescriptor* package_file_descriptor;
};
inline Symbol() : type(NULL_SYMBOL) { descriptor = NULL; }
…… //省略部分宏CONSTRUCTOR帮助提高代码可读性,来实现不同类型Symbol的构造函数:
#define CONSTRUCTOR(TYPE, TYPE_CONSTANT, FIELD) \
inline explicit Symbol(const TYPE* value) { \
type = TYPE_CONSTANT; \
this->FIELD = value; \
}宏CONSTRUCTOR的使用:
CONSTRUCTOR(Descriptor , MESSAGE , descriptor )
CONSTRUCTOR(FieldDescriptor , FIELD , field_descriptor )
CONSTRUCTOR(EnumDescriptor , ENUM , enum_descriptor )
CONSTRUCTOR(EnumValueDescriptor, ENUM_VALUE, enum_value_descriptor )
CONSTRUCTOR(ServiceDescriptor , SERVICE , service_descriptor )
CONSTRUCTOR(MethodDescriptor , METHOD , method_descriptor )
CONSTRUCTOR(FileDescriptor , PACKAGE , package_file_descriptor)
#undef CONSTRUCTOR具体应用时,根据type来区分处理:
const FileDescriptor* GetFile() const {
switch (type) {
case NULL_SYMBOL: return NULL;
case MESSAGE : return descriptor ->file();
case FIELD : return field_descriptor ->file();
case ENUM : return enum_descriptor ->file();
case ENUM_VALUE : return enum_value_descriptor->type()->file();
case SERVICE : return service_descriptor ->file();
case METHOD : return method_descriptor ->service()->file();
case PACKAGE : return package_file_descriptor;
}
return NULL;
}
};不同的类作为模版参数时,提供类独有的类型
类GenericTypeHandler和类StringTypeHandler 需要作为模版类型参数(typehandler),在子类RepeatedPtrField在调用父类RepeatedPtrFieldBase的模板函数时,通过模板参数直接传入父类RepeatedPtrFieldBase,这里需要根据不同的typehandler,返回对应不同的类型:
template <typename TypeHandler>
inline const typename TypeHandler::Type&
RepeatedPtrFieldBase::Get(int index) const {
GOOGLE_DCHECK_LT(index, size());
return *cast<TypeHandler>(elements_[index]);
}所以有如下方式,在不同模版参数类型中通过typedef方式来实现类型名称的统一,因为对于模版来说,关键点就是有统一的名称。
GenericTypeHandler
template <typename GenericType>
class GenericTypeHandler {
public:
typedef GenericType Type;
static GenericType* New() { return new GenericType; }
static void Delete(GenericType* value) { delete value; }
static void Clear(GenericType* value) { value->Clear(); }
static void Merge(const GenericType& from, GenericType* to) {
to->MergeFrom(from);
}
static int SpaceUsed(const GenericType& value) { return value.SpaceUsed(); }
};StringTypeHandler
// HACK: If a class is declared as DLL-exported in MSVC, it insists on
// generating copies of all its methods -- even inline ones -- to include
// in the DLL. But SpaceUsed() calls StringSpaceUsedExcludingSelf() which
// isn't in the lite library, therefore the lite library cannot link if
// StringTypeHandler is exported. So, we factor out StringTypeHandlerBase,
// export that, then make StringTypeHandler be a subclass which is NOT
// exported.
// TODO(kenton): There has to be a better way.
class LIBPROTOBUF_EXPORT StringTypeHandlerBase {
public:
typedef string Type;
static string* New();
static void Delete(string* value);
static void Clear(string* value) { value->clear(); }
static void Merge(const string& from, string* to) { *to = from; }
};
class LIBPROTOBUF_EXPORT StringTypeHandler : public StringTypeHandlerBase {
public:
static int SpaceUsed(const string& value) {
return sizeof(value) + StringSpaceUsedExcludingSelf(value);
}
};对应类的关系图:
低配版release来节省资源
在proto文件中增加配置,产出不支持reflection/descriptor的MessageLite子类,而不是Message子类。
option optimize_for = LITE_RUNTIME
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









