







Kettle中文名叫水壶,纯Java编写,可在Windows、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
核心组件
1、Spoon
可视化集成开发环境,通过图形接口,用于编辑作业和转换的桌面工具
2、Kitchen
作业的命令行运行程序,用于执行由Spoon编辑的作业
3、Pan
转换的命令运行程序,和Kitchen一样通过Shell脚本来调用
4、Carte
轻量级HTTP服务,接收远程调用,实现远程执行作业和转换。与Kitchen不同,Carte是一个后台运行服务,而Kitchen仅仅是一个执行命令,运行完一个作业后就退出。
Carte可用于搭建集群,将单个作业或转换进行分割,多节点上并行执行,最大化利用集群资源。其底层依赖Kitchen、Pan命令执行作业和转换
核心概念
Kettle中有两个核心概念:作业Job和转换Trans,其中作业完成整个工作流控制手段(串行),转换完成针对数据的基础转换(并发)
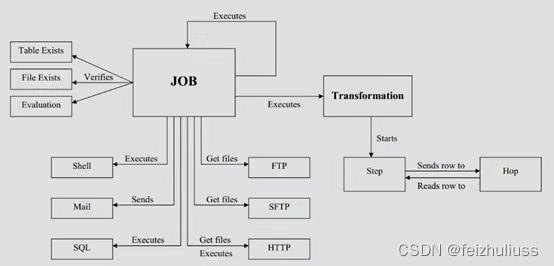
Kettle执行流程
1、转换
转换包含一个或多个步骤,步骤之间通过跳(Hop)来连接,跳定义了一个单向通道,允许数据从一个步骤流向另一个步骤。在Kettle中,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
1.1 步骤(Step)
步骤是转换的基本组成部分,步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。
步骤需要有一个名字,且这个名字在该转换中唯一。
在Kettle中,所有的步骤都以并发的方式执行,当转换启动后,所有的步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳中不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。
一个步骤的数据发送可设置为轮流发送(分发)和复制发送(复制),分发即将数据行依次发送给每一个输出跳;复制则是将全部数据行发送给所有的输出跳。
1.2 跳(Hop)
跳是步骤之间的连线,它定义了一个单向通道,允许数据从一个步骤向另一个步骤流动。跳实际上是两个步骤间被称为行集(rowset)的数据行缓存(行集大小可在转换的设置里进行自定义)。
当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集又有了可读的数据行(通过阻塞队列实现)。
1.3 数据行
数据行是数据的基本单位,数据行从一个步骤到另一个步骤的移动就形成了数据流。
一个数据行是零到多个字段的集合,以及该数据行的元数据信息(字段类型、字段顺序、字段精度等)
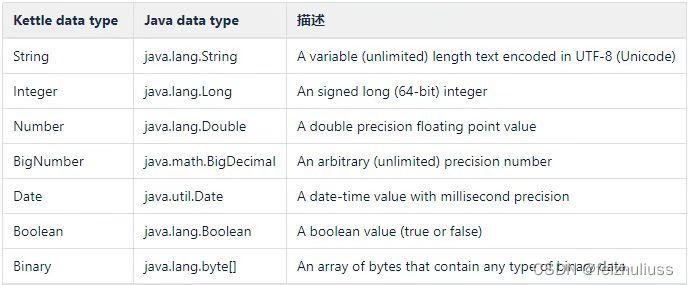
1.4 执行顺序
“转换中”无法定义执行顺序,因为所有的步骤都是并发执行。当转换启动后,所有步骤同时启动,从它们的输入跳读取数据,并把处理过的数据写到输出跳,直到输入跳没有需要处理的数据,就中止步骤的运行。当个所有的步骤都中止了,整个转换就中止了。
2、作业
Kettle中"转换"是以并发的方式执行的,那么就需要"作业"来处理串行场景

2.1 作业项(JobEntry)
作业包含一个或多个作业项,作业项之间串行执行。
2.2 作业跳
作业之间的连接称为作业跳,作业里每个作业项的不同运行结果决定了作业的不同执行路径
- 无条件执行:不论上一个作业项执行成功与否,下一个作业项都会执行。
- 当运行结果为true时执行
- 当运行结果为false时执行
3、资源库
资源库是存放转换和作业脚本的地方,非业务数据库。Kettle自带的资源库主要有两种:文件资源库和数据库资源库
3.1 文件资源库
文件资源库将脚本保存在本地创建的目录中,脚本文件是ktr和kjb文件形式(本质是xul文件),打开资源库可以管理所有脚本。
缺点:因脚本文件保存在本地计算机,故只能在本地运行,无法远程调用!
3.2 数据库资源库
数据库资源库将脚本保存数据库中,Kettle通过JDBC连接资源库,数据库可以是本地计算机,也可以是远程计算机,实现统一管理脚本。
优点:数据库连接信息保存在数据库中,当信息变更的时候,在资源库【连接】标签中修改后,所有脚本使用的该数据库连接信息自动更新。
事务控制
1、局部事务
数据库连接只在执行作业或转换时使用。在作业中,每个作业项都打开和关闭一个独立的数据库连接,转换步骤亦是如此。
2、全局事务
为解决打开多个连接而产生的事务问题,Kettle可在一个事务中完成所有转换,在转换设置的对话框的杂项中,勾选使用唯一连接,可完成此功能。
尽管这样,使用全局事务带来的性能损耗也是非常大。
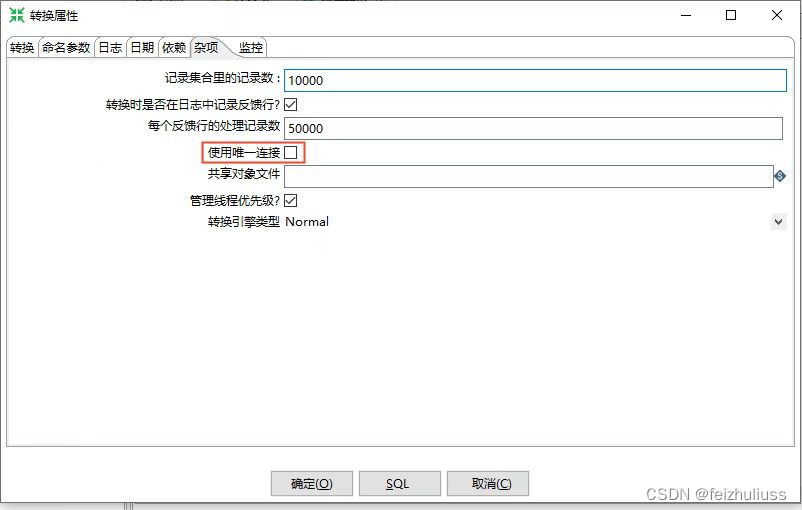
当选中这个选项,所有步骤里的数据库连接都使用同一个数据库连接,只有所有步骤都正确执行完,事务才会提交,任一步骤出错都会回滚事务!
并发限流
1、限流
记录集合里的记录数
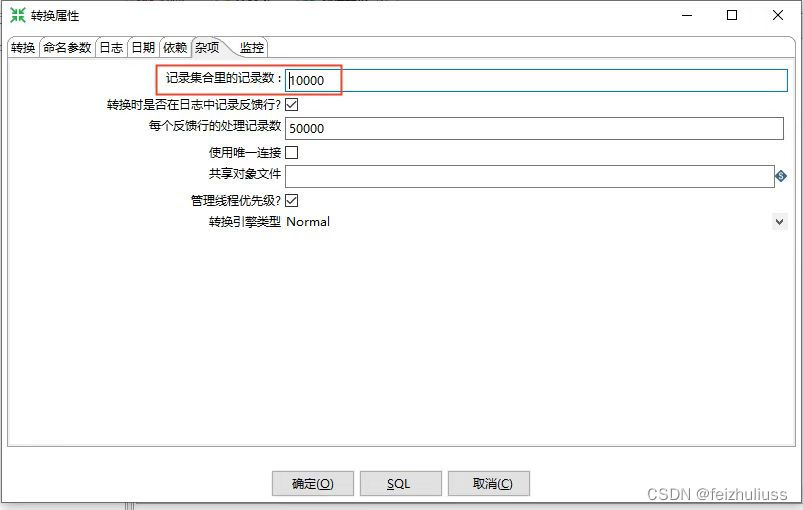
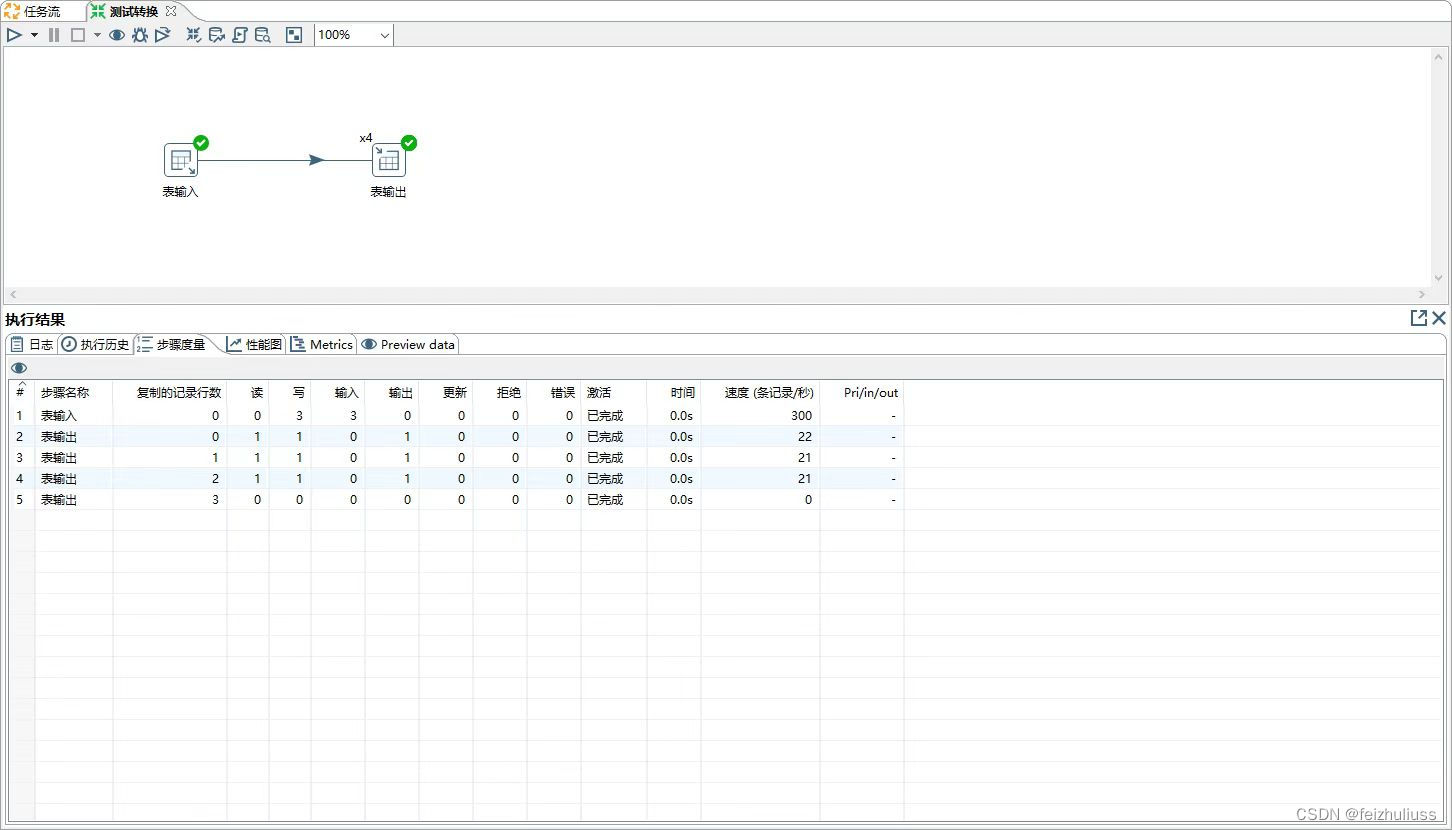
2、并发
单机:改变开始复制数量
集群:

















 3820
3820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









