




 本文深入解析MapReduce的核心机制——Shuffle过程,并通过对比关系型数据库操作,如数据去重、多表查询和倒排索引,阐述其在大数据处理中的应用。同时,介绍了MRUnit框架用于MapReduce的单元测试,以及Hadoop体系架构,包括HDFS和Yarn的组件功能。
本文深入解析MapReduce的核心机制——Shuffle过程,并通过对比关系型数据库操作,如数据去重、多表查询和倒排索引,阐述其在大数据处理中的应用。同时,介绍了MRUnit框架用于MapReduce的单元测试,以及Hadoop体系架构,包括HDFS和Yarn的组件功能。
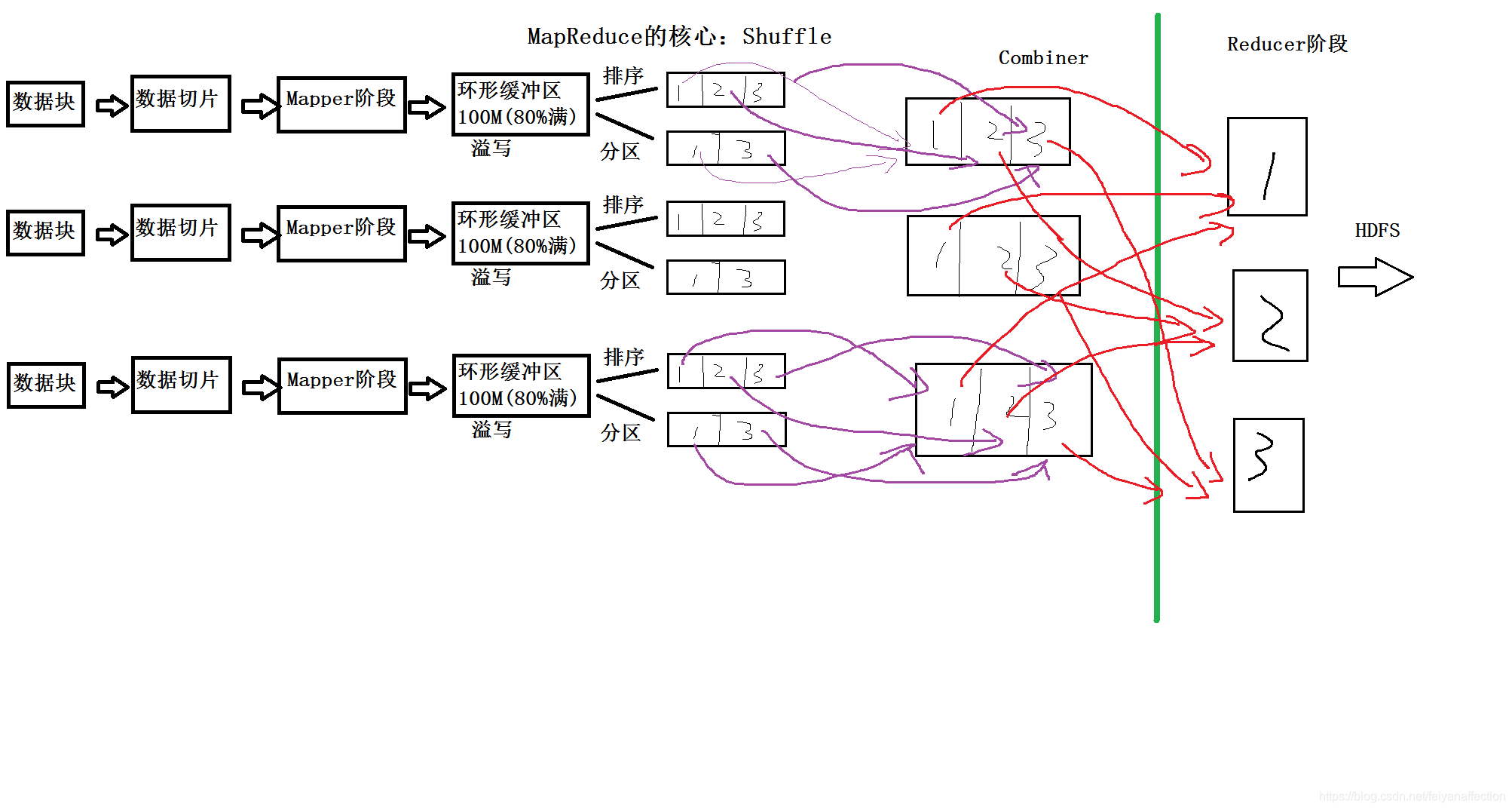
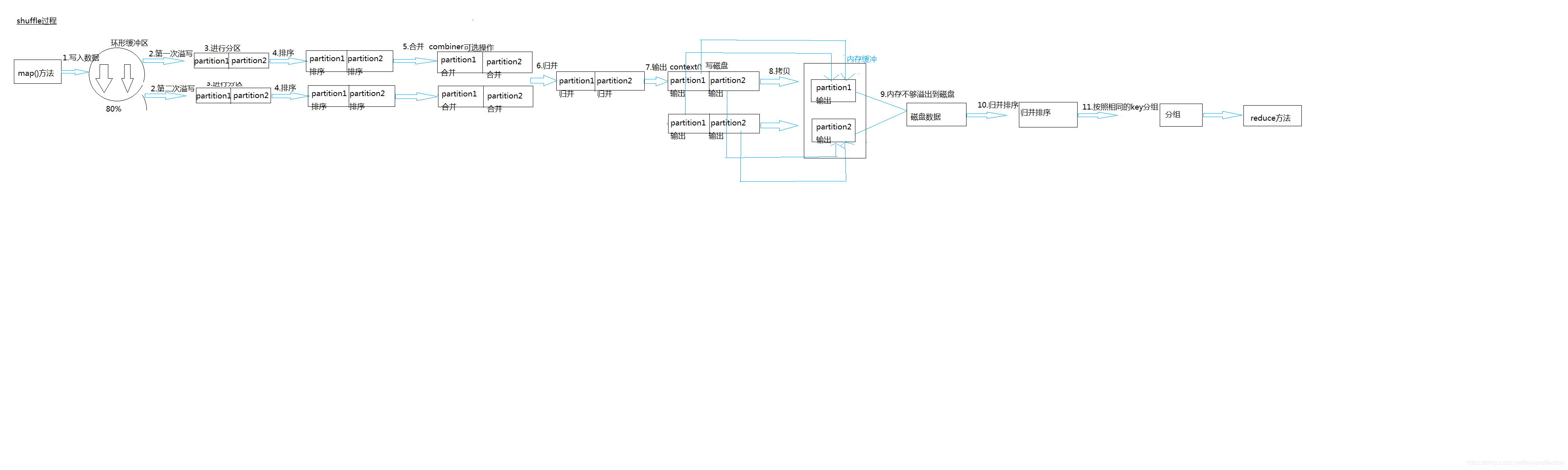
一、MapReduce的核心:Shuffle
1、Hadoop 3.x以前: 会有数据落地(产生I/O操作)
二、MapReduce编程案例:复习关系型数据库的相关知识(SQL等等)
1、数据去重
()复习SQL:distinct实现去重,作用于后面所有的列
一个列:
select job from emp;
select distinct job from emp;
多个列:
select distinct deptno,job from emp;
()使用MapReduce实现
(*)思考题:如何使用MR实现多个列的数据去重?
复习:关系型数据库中的多表查询(子查询:在Oracle中,绝大部分的子查询都是转换成多表查询来执行)
(1) 笛卡尔积: 列数相加、行数相乘
(2) 根据连接条件的不同:
()等值连接
()不等值连接
()外链接
()自连接
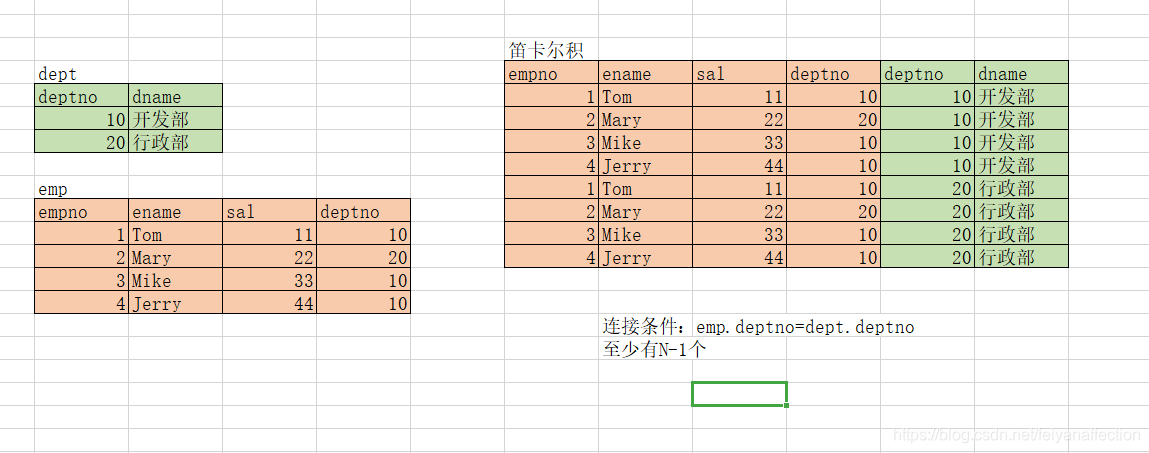
2、多表查询:等值连接
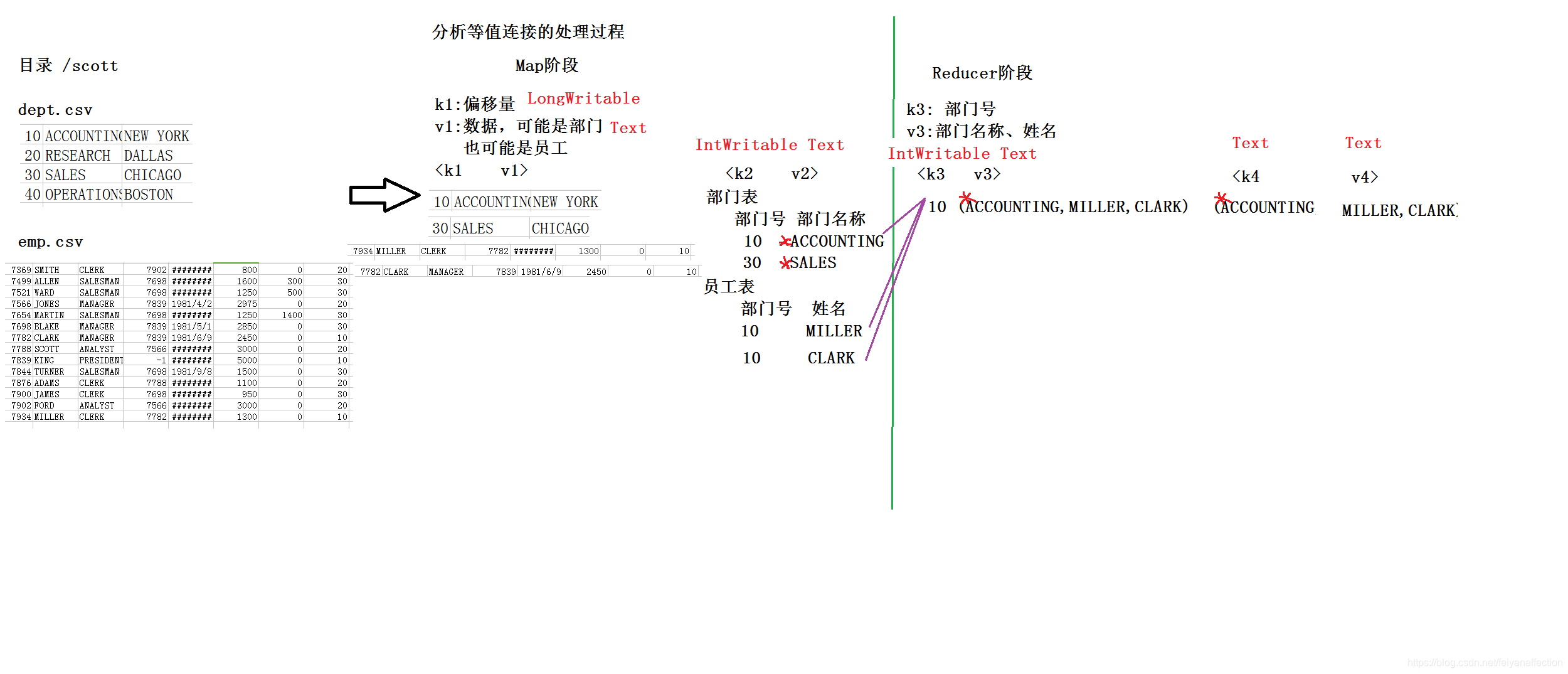
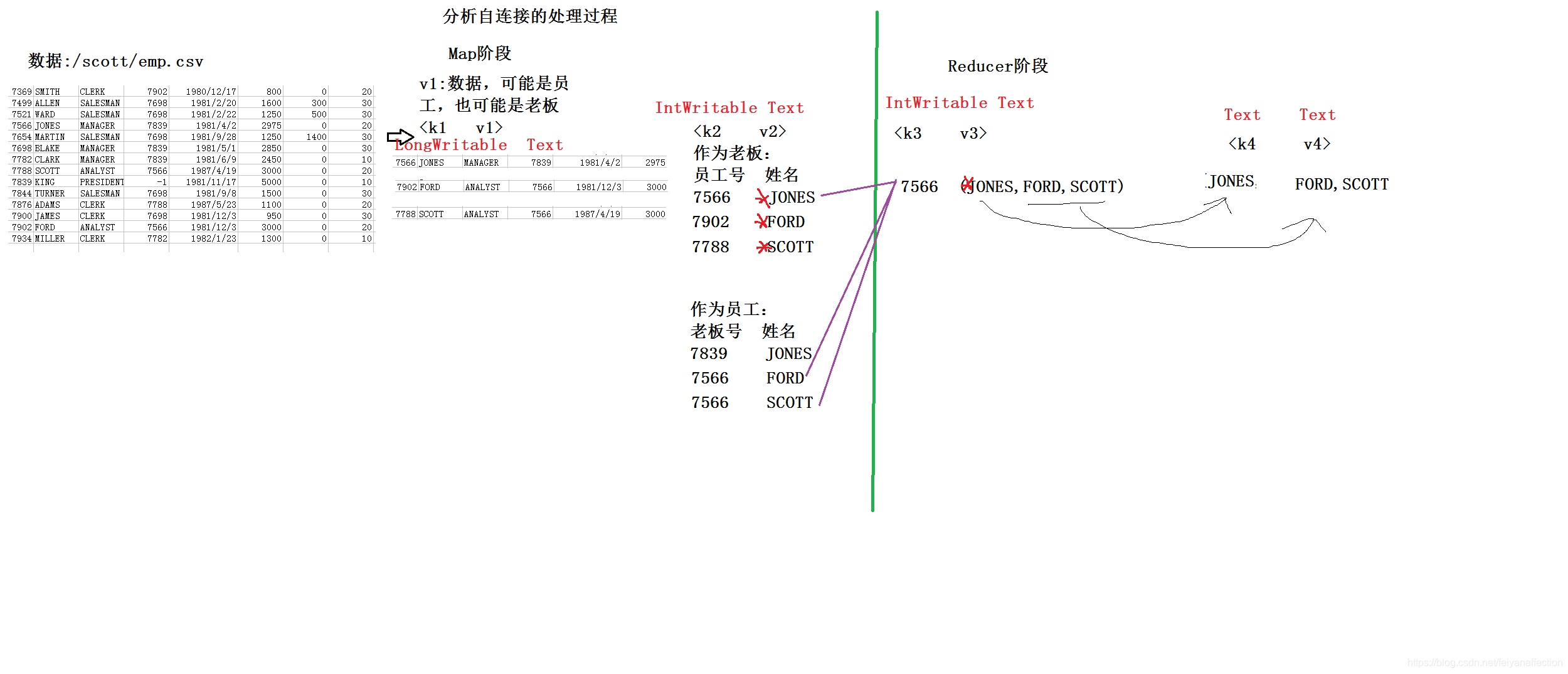
3、多表查询:自连接,通过表的别名,将同一张表视为多张表
()就是一张表的链接操作
() 举例:查询员工信息,要求显示:员工老板的名字 员工的名字
select b.ename,e.ename
from emp b,emp e
where b.empno=e.mgr;
在oracle中,当查询的数据满足是一棵树的时候,可以使用层次查询来取代自连接
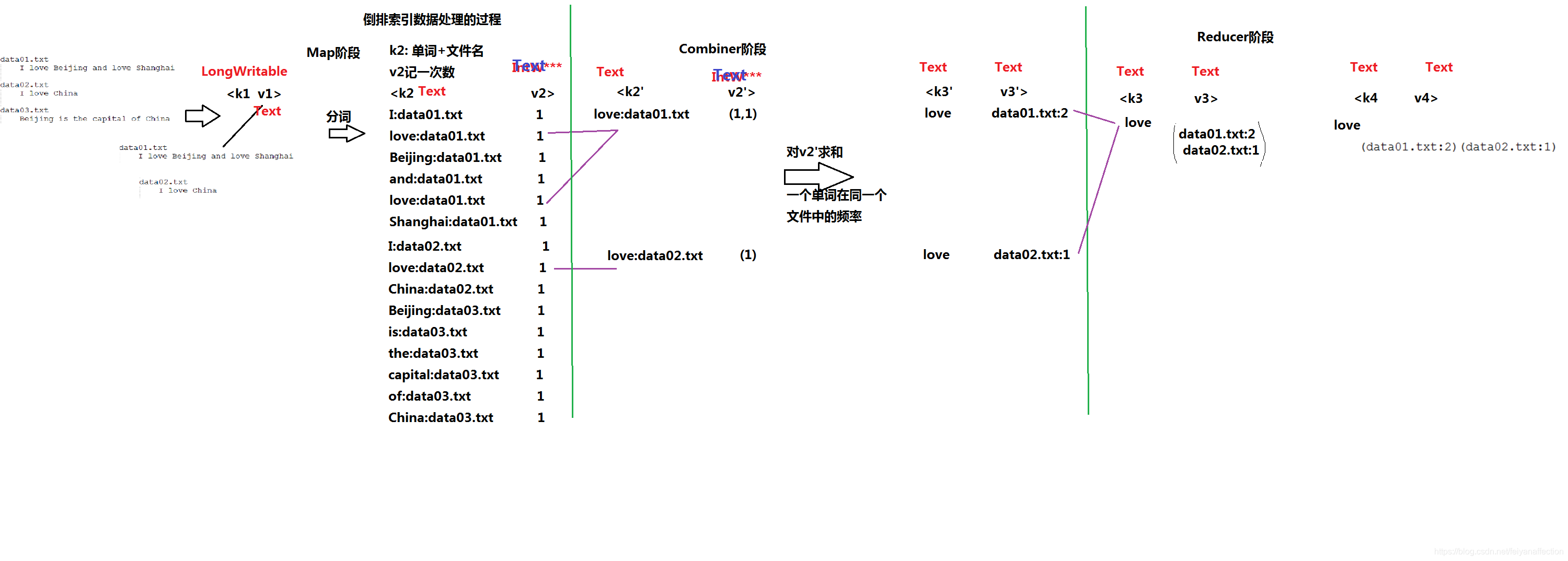
4、倒排索引
5、框架MRUnit:单元测试MapReduce
加入maven依赖:
<dependency>
<groupId>org.apache.mrunit</groupId>
<artifactId>mrunit</artifactId>
<version>${mrunit.version}</version>
<classifier>hadoop2</classifier>
</dependency>
四、第一阶段小结
(一)大数据的背景知识
1、什么是大数据?
举例:(1)商品推荐
(2)天气预报
核心:数据的存储:HDFS(分布式的文件系统)
数据的计算:MapReduce(分布式的计算模型)
2、什么是数据仓库?
(*)Hadoop和Spark都可以看成是数据仓库的一种实现方式
3、Google的三篇论文
(*)GFS:Google File System
(*)MapReduce:问题来源是PageRank
(*)BigTable:大表 ----> HBase
(二)Hadoop的体系架构:都是主从架构(只要是主从架构都有单点故障的问题)
1、HDFS
()NameNode
()DataNode
(*)SecondaryNameNode
2、Yarn
(*)ResourceManager
(*)NodeManager
3、安装配置
(*)本地模式
(*)伪分布模式
(*)全分布模式
(三)HDFS
1、基本操作:命令行、Java API、Web Console
2、原理:上传、下载
RPC、代理对象
3、高级特性:回收站、快照、安全模式等等
4、后面讲:NameNode联盟(Federation)
(四)MapReduce
1、掌握:数据处理流程分析(以WordCount为例)
2、功能:序列化
排序
分区
合并
3、核心:洗牌Shuffle
4、案例


















 7403
7403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











