




 文章介绍了StarRocks如何实现OLAP分层引擎的统一,它作为MPP架构的分析型数据库,支持PB级别数据和高并发查询。镜舟基于StarRocks打造了商业产品,提供企业级服务,包括数据处理、高性能分析和湖仓一体解决方案。
文章介绍了StarRocks如何实现OLAP分层引擎的统一,它作为MPP架构的分析型数据库,支持PB级别数据和高并发查询。镜舟基于StarRocks打造了商业产品,提供企业级服务,包括数据处理、高性能分析和湖仓一体解决方案。
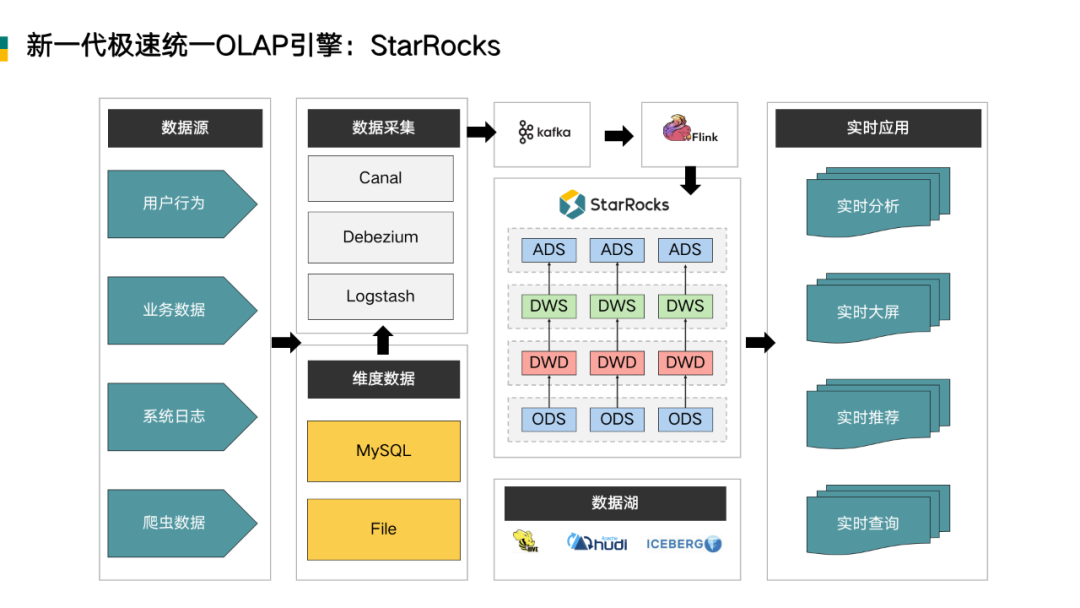
基于上述的痛点,镜舟引入 StarRocks 的理念,实现 OLAP 分层引擎的统一,与原有架构大致相同,数据通过上游的多种数据源和采集工具写入 Kafka 中,在 Flink 中进行 ETL 的转换,再实时写入到 StarRocks 中。在 StarRocks 中,我们可以使用宽星型(宽表及星型)或者预聚合模型灵活的做业务建模。
StarRocks 在大数据生态中的定位非常清晰,是一款 MPP 架构的分析型数据库。StarRocks 能够支撑 PB 级别的数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、位图索引、稀疏索引等优化手段,去建立极速统一的分析层数据存储系统。
StarRocks 也可以支持数据变更和高并发的业务查询,同时借助 Iceberg、 Hive 外表等功能,打造出新一代的湖仓一体的架构。Iceberg 或者 Hive 中有价值的数据可以流入 StarRocks 进行关联查询,StarRocks 里的隐藏价值数据或者价值不太高的数据,也可以流向 Iceberg 或者 Hive 中 ,以低成本的方式长久保存,供未来数据挖掘使用。
#02
从 StarRocks 到镜舟,持续迭代升级的产品力
接下来我会分享基于 StarRocks 社区开发出企业级产品的过程,包括镜舟如何做持续迭代的产品升级以及服务升级。“镜舟” 这个名字,来源于这样一个期待:以人为镜,以梦为舟,不负韶华,未来可期。
1、基于 StarRocks 的商业化产品镜舟
首先看我们所引入的 StarRocks 社区产品的一些表现。从社区来看,StarRocks 产品在近一两年之内还是取得了不少成就的。GitHub 的星数达到了 3500 多, PR 数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









