



 本文介绍了如何使用Python进行逆向工程,针对某狗音乐、某易音乐和某千音乐的加密参数进行解析,包括signature、params&encSecKey和sign。通过抓包和JS代码中的CryptoJS库实现数据加密解密过程,并展示如何用Python配合execjs调用JS函数获取API数据。
本文介绍了如何使用Python进行逆向工程,针对某狗音乐、某易音乐和某千音乐的加密参数进行解析,包括signature、params&encSecKey和sign。通过抓包和JS代码中的CryptoJS库实现数据加密解密过程,并展示如何用Python配合execjs调用JS函数获取API数据。
前言💥
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容💥
Python逆向爬虫入门教程01: 某狗音乐加密参数signature逆向解析
Python逆向爬虫入门教程02: 某易音乐加密参数 params & encSecKey 逆向解析
Python逆向爬虫入门教程03: 某千音乐加密参数 sign 逆向解析
数据来源分析💥
网站链接: aHR0cHM6Ly9zcGEyLnNjcmFwZS5jZW50ZXIvcGFnZS8y
电影数据包分析💥
- 正常流程抓包分析数据, 找到相关的数据
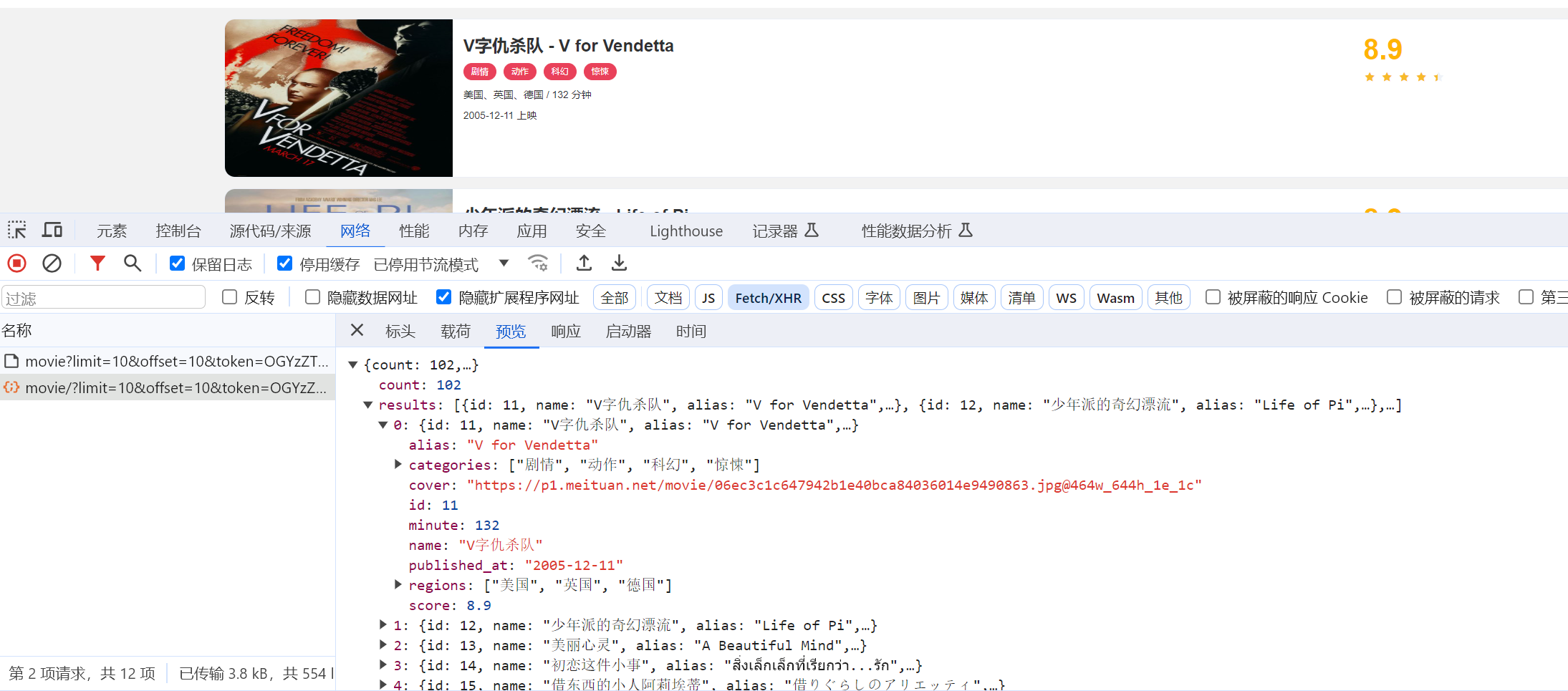
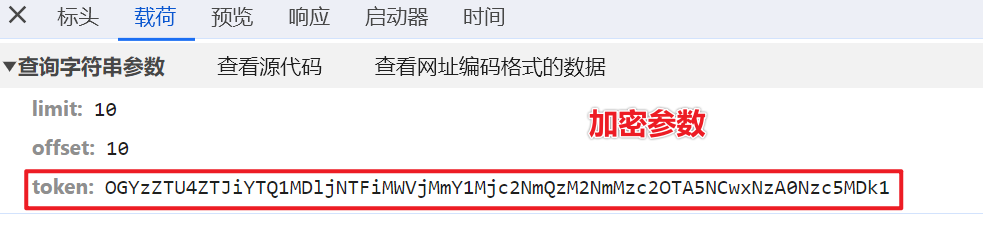
- 找到
token加密位置
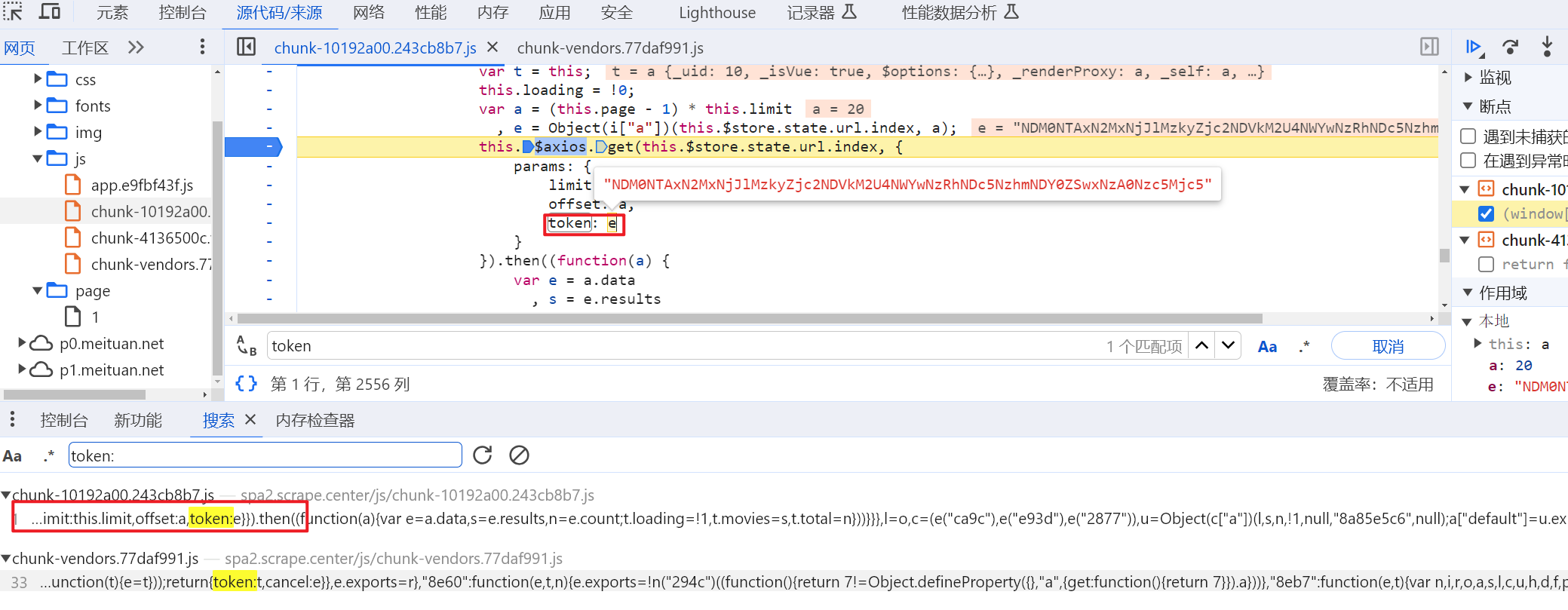
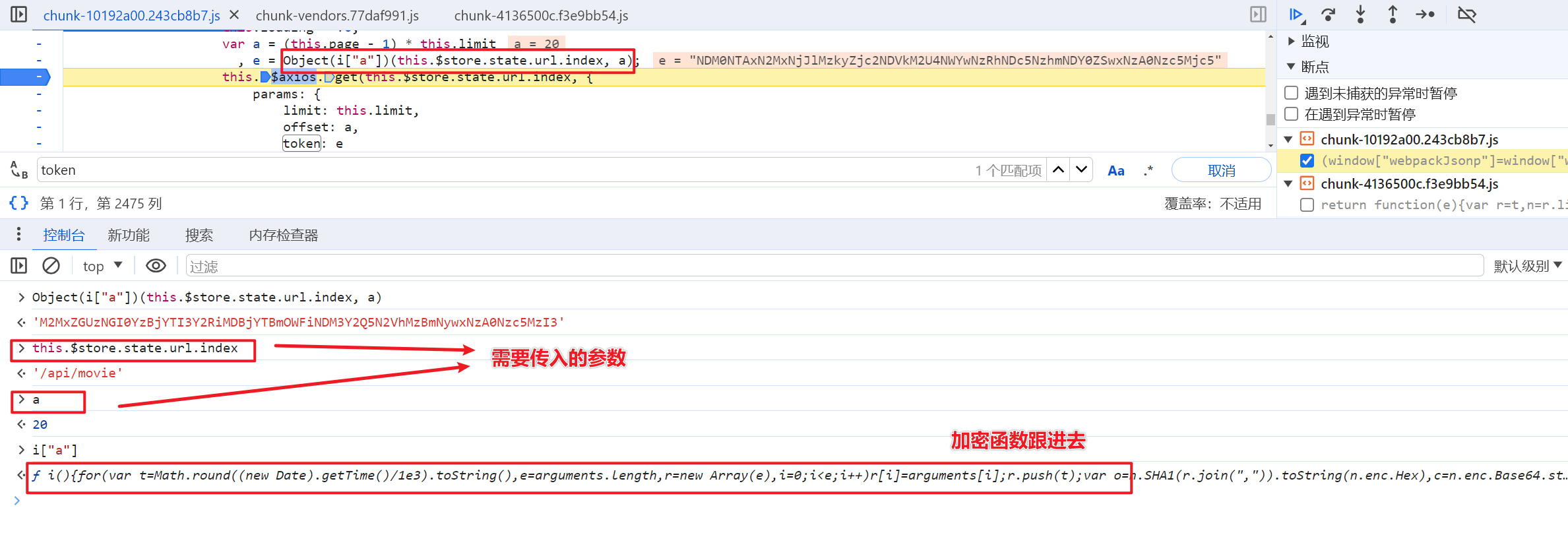

找到了token加密的位置, 直接扣代码, 扣出来之后会报错 n is not defined , n是一个标准的加密算法直接导入模块即可
JS代码💥
const CryptoJS = require('crypto-js')
function i() {
for (var t = Math.round((new Date).getTime() / 1e3).toString(), e = arguments.length, r = new Array(e), i = 0; i < e; i++)
r[i] = arguments[i];
r.push(t);
var o = CryptoJS.SHA1(r.join(",")).toString(CryptoJS.enc.Hex)
, c = CryptoJS.enc.Base64.stringify(CryptoJS.enc.Utf8.parse([o, t].join(",")));
return c
}
console.log(i("/api/movie", 20))
//
Python代码获取数据💥
import requests
import execjs
f = open('demo.js', encoding='utf-8').read()
js_code = execjs.compile(f)
for offset in range(0, 91, 10):
url = 'https://spa2.scrape.center/api/movie/'
token = js_code.call('i', '/api/movie', offset)
data = {
'limit': '10',
'offset': offset,
'token': token,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
json_data = response.json()
for index in json_data['results']:
print(index)
dit = {
'name': index['name'],
'alias': index['alias'],
'categories': ','.join(index['categories']),
'regions': ','.join(index['regions']),
'minute': index['minute'],
'published_at': index['published_at'],
'score': index['score'],
}
print(dit)


















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









