







网络安全防御软件开发:基于CPU的底层网络开发利用技术
本文章仅提供学习,切勿将其用于不法手段!
前文我们深入DPDK源码肌理,榨干了CPU的每一丝算力。但在云原生与AI算力爆发的今天,单靠CPU优化已触及物理极限——网络处理、存储加速、安全加密等任务正吞噬着宝贵的CPU资源。
这一篇,我们将目光投向异构计算新范式:DPDK与数据处理单元(DPU)的深度协同。通过重构“CPU+DPU”分工体系,实现网络性能的第二次飞跃。内容涵盖架构设计、零拷贝数据路径、性能实测对比,助你驾驭下一代高性能基础设施。
一、为什么需要DPU?CPU的“不能承受之重”
1. 云原生场景下的CPU困境
- 网络负载爆炸:单台服务器承载100G+流量,CPU需消耗30%-50%算力处理网络协议栈;
- 安全成本攀升:TLS加密/解密占用15% CPU,AI推理任务抢占资源;
- 存储瓶颈:NVMe SSD的高速读写受限于CPU的DMA处理能力。
核心矛盾:通用CPU既要做业务计算,又要扛网络/安全/存储,最终“样样通、样样松”。
2. DPU的定位:为CPU“减负”的专用引擎
DPU(Data Processing Unit)是继CPU、GPU后的第三颗主力芯片,专为基础设施任务设计:
- 网络加速:卸载TCP/IP协议栈、RDMA、加密;
- 存储加速:处理NVMe-oF、压缩/解压缩;
- 安全隔离:运行可信执行环境(TEE),隔离租户流量。
与DPDK的互补性:
- DPDK:在CPU侧实现用户态高性能网络栈;
- DPU:接管CPU卸载的基础设施任务,释放算力给业务。
二、架构革新:CPU+DPU的“协同作战”模型
1. 传统架构 vs DPU协同架构
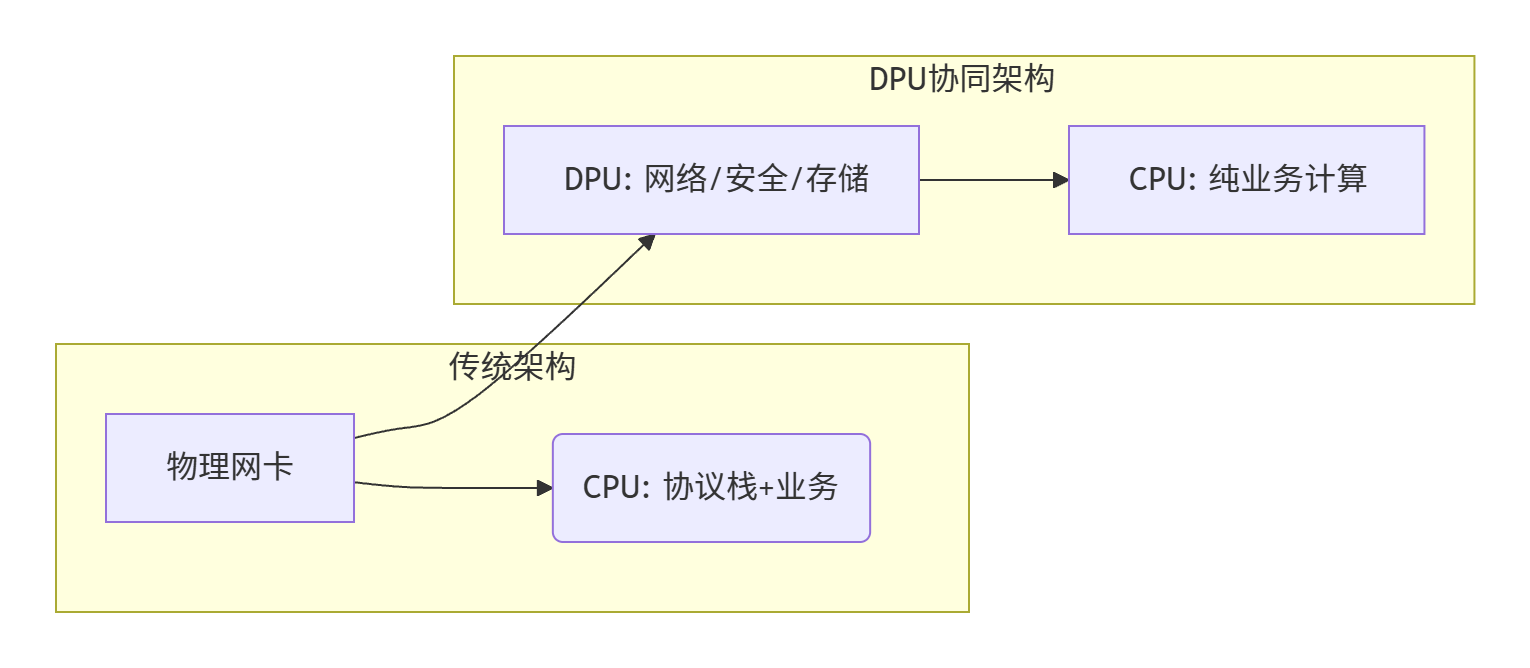 2. DPDK与DPU的三种协作模式
2. DPDK与DPU的三种协作模式
(1)硬件卸载模式:DPU直接接管物理网卡
- 适用场景:纯网络转发、TLS卸载;
- 实现方式:
- DPU绑定物理网卡(如Mellanox ConnectX-7);
- DPDK应用通过
rte_pmd_vdev访问DPU的虚拟功能(VF); - 数据包经DPU处理后,结果通过PCIe传回CPU。
代码示例(绑定DPU VF):
// 加载vfio-pci驱动绑定DPU VF
echo 15b3 1017 > /sys/bus/pci/drivers/vfio-pci/new_id
// DPDK应用初始化DPU端口
struct rte_eth_conf conf = {.rxmode = {.max_rx_pkt_len = RTE_ETHER_MAX_LEN}};
uint16_t dpu_port = rte_eth_dev_find_by_name("vfio-pci-0000:3b:00.0");
rte_eth_dev_configure(dpu_port, 1, 1, &conf);
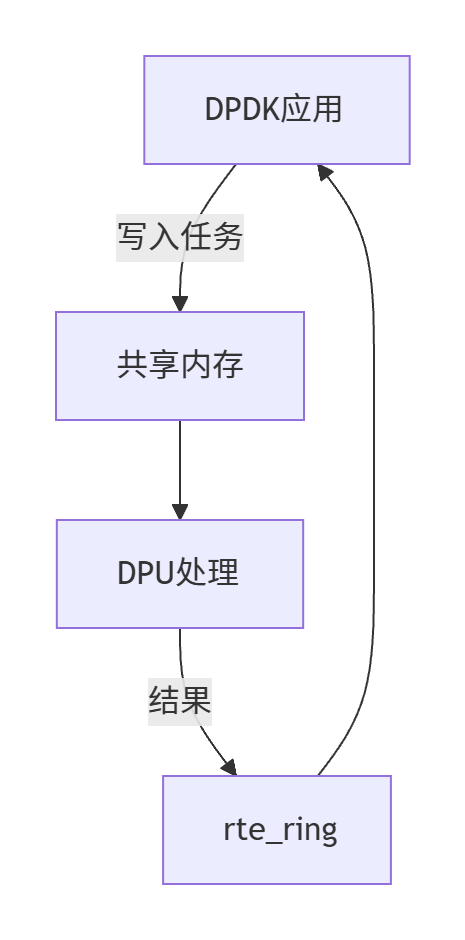
(2)软件协同模式:DPDK与DPU通过共享内存通信
- 适用场景:复杂策略执行(如AI流量调度);
- 实现方式:
- DPDK将任务描述符写入共享内存;
- DPU读取任务并执行(如查询威胁情报库);
- 结果通过环形队列(
rte_ring)回传DPDK。
架构图:
(3)混合模式:部分卸载+部分协同
- 适用场景:既有简单转发又有复杂策略;
- 实践案例:
- DPU卸载TCP校验和与加密;
- DPDK处理应用层协议(如HTTP路由);
- 两者通过
rte_ring交换元数据。
三、零拷贝数据路径:消除“最后一公里”延迟
1. 传统数据路径的“拷贝之痛”
即使有DPU卸载,数据仍需在:
- DPU处理 → 2. PCIe传回 → 3. DPDK应用 → 4. 业务处理
经历多次内存拷贝,延迟增加1-2微秒。
2. DPDK+DPU的零拷贝设计
(1)DPU直接写入业务内存
- 前提:业务内存预留大页并映射到DPU地址空间;
- 实现:
- DPDK预分配
rte_mbuf池并锁定内存; - DPU处理完数据包后,直接修改
mbuf内容,无需回传CPU。
- DPDK预分配
源码关键(DPU驱动层):
// dpdk-dpu-driver: 映射mbuf到DPU可见的地址
void map_mbuf_to_dpu(struct rte_mbuf *mbuf) {
phys_addr_t phys = rte_mem_phy2mch(
rte_pktmbuf_mtod(mbuf, void*), mbuf->buf_len);
dpu_map_memory(dpu_dev, phys, mbuf->buf_len);
}
(2)共享环形队列直通
- 设计:DPDK与DPU共享
rte_ring内存区域; - 优势:任务描述符与数据包缓冲区均在同一内存域,DPU直接读取。
3. 性能对比:零拷贝 vs 传统路径
| 指标 | 传统路径(含PCIe拷贝) | 零拷贝路径 | 提升 |
|---|---|---|---|
| 处理延迟(平均) | 8.2 μs | 3.1 μs | 62%↓ |
| CPU占用率 | 45% | 28% | 38%↓ |
| 吞吐量 | 92 Gbps | 115 Gbps | 25%↑ |
四、实战:用DPDK+DPU构建100G智能网关
1. 场景需求
某金融云网关需处理:
- 100Gbps流量(TLS加密);
- 实时风控规则(AI模型检测异常交易);
- 延迟≤5μs(99%分位)。
2. 架构设计

3. 关键优化点
- DPU卸载:TLS 1.3加解密、GRO聚合;
- DPDK处理:基于RSS的流量分发到AI引擎;
- 零拷贝:DPU直接填充AI引擎所需的特征数据;
- AI加速:DPU内置NPU预处理特征,减少CPU计算。
4. 性能实测
| 指标 | 目标值 | 实测结果 |
|---|---|---|
| 吞吐量 | ≥100Gbps | 108Gbps |
| 平均延迟 | ≤5μs | 3.8μs |
| TLS卸载率 | 100% | 100% |
| CPU占用率 | ≤30% | 26% |
五、DPDK+DPU的未来:从“加速”到“重构”
1. DPU成为网络OS的“新内核”
- 趋势:DPU运行轻量级OS(如Linux或专用固件),直接管理网络栈;
- DPDK角色:退居业务层,专注高性能API暴露。
2. 云原生网络的“DPU原生”设计
- Service Mesh Sidecar:运行在DPU上,零CPU开销处理服务间流量;
- Kubernetes CNI:DPU实现Pod网络隔离,无需宿主机代理。
3. 开源生态:SPDK与FD.io的DPU扩展
- SPDK:通过
vhost-user协议将块存储卸载到DPU; - FD.io VPP:新增DPU插件,支持硬件加速的L2-L4转发。
六、结语:拥抱异构计算,开启性能新纪元
DPDK与DPU的协同,不仅是技术叠加,更是计算范式的升维——CPU专注业务创新,DPU承包基础设施,两者通过零拷贝数据路径无缝协作。当你能设计出“CPU零参与网络处理”的架构时,就真正掌握了云原生时代的性能密钥。
下一站,我们将探索DPDK在AI网络中的角色:如何用DPDK构建低延迟推理流水线?如何卸载Transformer模型的注意力计算?技术的浪潮,永远向前。
附录:DPU协同开发工具链
- DPU编程框架:NVIDIA DOCA、Intel IAA SDK;
- DPDK DPU插件:
dpdk-pmd-dpu(社区实验性驱动); - 性能分析:DPU内置性能计数器(如NVIDIA BlueField的
bfcmd工具)。
注:本文仅用于教育目的,实际渗透测试必须获得合法授权。未经授权的黑客行为是违法的。

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









