




数据结构
缓存区: sk_buff
后续为了方便,将缓存区称为skb。
// 为了清晰,下面的内容删去了特性宏新增的字段
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
ktime_t tstamp;
struct net_device *dev;
// 路由结果
union {
struct dst_entry *dst;
struct rtable *rtable;
};
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48];
unsigned int len, // skb所有数据内容的总长度
data_len; // skb中frags片段数组长度+frag_list片段链表的长度
__u16 mac_len,
hdr_len;
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
__u8 local_df:1,
cloned:1, // 标记skb是否是克隆的,见下方“skb克隆”
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3, // 基于L2层帧目的地址的数据包类型,用于接收方向,取值如PACKET_HOST等
fclone:2, // 见下方的“skb克隆”
ipvs_property:1,
peeked:1,
nf_trace:1;
__be16 protocol; // 数据包所属L3层协议类型,接收过程中,设备接口层通过该字段确定L3层处理者
void (*destructor)(struct sk_buff *skb); // skb销毁时回调的函数,可选
int iif;
__u16 queue_mapping;
/* 0/13/14 bit hole */
__u32 mark;
__u16 vlan_tci;
sk_buff_data_t transport_header; // L4层报文首部指针
sk_buff_data_t network_header; // L3层报文首部指针
sk_buff_data_t mac_header; // L2层报文首部指针
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head, *data;
// skb真实占用的内存,在线性缓冲区的基础上增加了sk_buff本身占用的内存,
// 不过不清楚为何没有包含skb共享信息部分
unsigned int truesize;
atomic_t users; // sk_buff本身的引用计数
};
skb指针: sk_buff_data_t
根据编译选项的选择,sk_buff_data_t可以是偏移量,也可以是指针。如果是偏移量,代表的是相对head指针的偏移量。
#ifdef NET_SKBUFF_DATA_USES_OFFSET
typedef unsigned int sk_buff_data_t;
#else
typedef unsigned char *sk_buff_data_t;
#endif
协议头指针
transport_header、network_header、mac_header分别指向L4层报文首部、 L3层报文首部、 L2层报文首部。它们相关的操作函数如下:
// 返回transport_header指针
static inline unsigned char *skb_transport_header(const struct sk_buff *skb);
// reset让transport_header指向当前skb->data
static inline void skb_reset_transport_header(struct sk_buff *skb);
// 设置transport_header为skb->data + offset
static inline void skb_set_transport_header(struct sk_buff *skb,
const int offset);
// 获取transport_header和head指针之间的偏移量
static inline int skb_transport_offset(const struct sk_buff *skb);
static inline unsigned char *skb_network_header(const struct sk_buff *skb);
static inline void skb_reset_network_header(struct sk_buff *skb);
static inline void skb_set_network_header(struct sk_buff *skb, const int offset);
static inline u32 skb_network_header_len(const struct sk_buff *skb);
static inline unsigned char *skb_mac_header(const struct sk_buff *skb);
static inline void skb_set_mac_header(struct sk_buff *skb, const int offset);
static inline int skb_network_offset(const struct sk_buff *skb);
缓存区队列: sk_buff_head
需要时,可以通过skb队列简单的将skb以双向链表结构组织到一起。特别注意:由于skb队列和skb的前两个元素完全一样,所有有些代码中可以将二者直接传递。
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen; // 队列中有多少个skb
spinlock_t lock;
};
skb共享信息: skb_shared_info
/* To allow 64K frame to be packed as single skb without frag_list */
#define MAX_SKB_FRAGS (65536/PAGE_SIZE + 2)
struct skb_shared_info {
atomic_t dataref; // 共享信息所在内存块(即线性缓存区)的引用计数
unsigned short nr_frags; // 记录当前frags数组中的有效项个数
unsigned short gso_size;
/* Warning: this field is not always filled in (UFO)! */
unsigned short gso_segs;
unsigned short gso_type;
__be32 ip6_frag_id;
struct sk_buff *frag_list; // 可以指向一个skb链表
skb_frag_t frags[MAX_SKB_FRAGS]; // 最大共可以引用64KB内存
};
// 通过该宏可以引用skb的共享信息对象
#define skb_shinfo(SKB) ((struct skb_shared_info *)(skb_end_pointer(SKB)))
片段: skb_frag_t
片段代表了某个内存页中的一段连续的内存块,所以此片段并非指IP片段,二者并无关系。
typedef struct skb_frag_struct skb_frag_t;
struct skb_frag_struct {
struct page *page; // 片段引用的内存页指针
__u32 page_offset; // 片段引用的内存块起始地址在内存页中的偏移
__u32 size; // 片段引用的内存块大小
};
数据组织格式
一个最复杂的skb的内存布局如下图所示,下面通过介绍下图内容,解释上述数据结构中相关字段的含义。
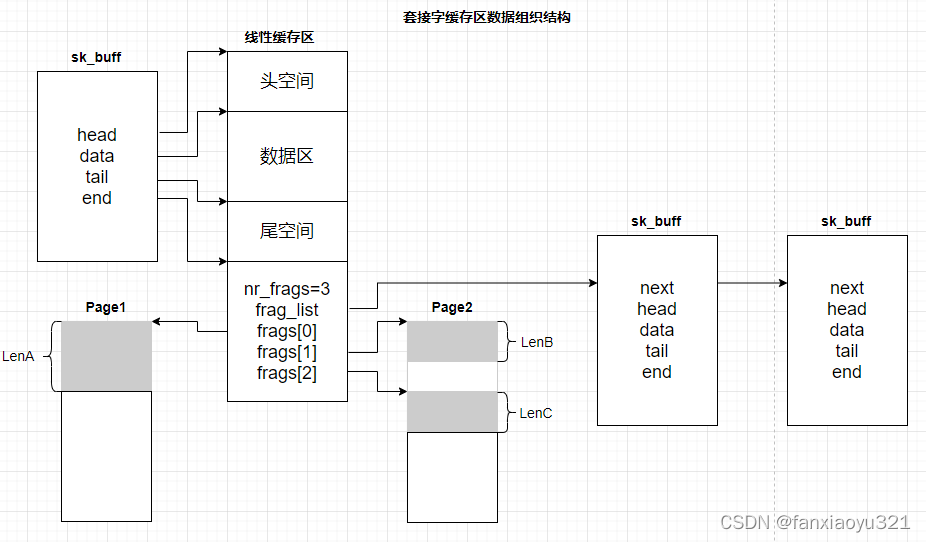
skb中有三个区域可以存储数据:
- 线性缓存区;
- frags片段数组;
- frag_list片段链表;
线性缓存区
线性缓存区的数据存储部分由“头空间”、“数据区”、“尾空间”三部分组成。如图所示:
- head和data指针之间的区域为头空间;data和tail之间的区域为数据区;tail和end之间的区域为尾空间;
- head和end指针在skb分配的时候就确定了,之后也不会再发生变化,通过改变data和tail的指向可以灵活的操作数据缓存区;
- 尾空间末尾就是前面提到的skb共享信息结构skb_shared_info,内存分配随着线性缓存区一起分配;
frags片段数组
通过frags片段数组,skb可以将内存上不连续的内容组织成一个数据包。如图所示,frags片段数组中各元素可以指向同一页的内存块,也可也指向不同页的内存块。
frag_list片段链表
通过frag_list片段链表,可以将多个skb组织成一个数据包。
线性skb与非线性skb
通常,称没有frags片段数组和frag_list片段链表的skb为线性skb,相反的叫做非线性skb。skb_is_nonlinear()用于判断skb是否是线性的。skb_linearize()可以将skb线性化,不可避免的,这个过程需要内存拷贝,会降低性能,但有时是必要的。
关于数据长度
如上图所示:
- skb->len = 数据区长度 + frags片段数组长度(lenA + lenB + lenC) + frags_list长度;
- skb->data_len = frags片段数组长度(lenA + lenB + lenC) + frags_list长度;
skb的分配
如上图所示,skb至少包含sk_buff和线性缓冲区两部分,在内存分配时也至少会分配两次。常用的分配函数有alloc_skb()和dev_alloc_skb()两个,后者主要由设备驱动程序在中断上下文中使用。
alloc_skb()
static inline struct sk_buff *alloc_skb(unsigned int size,
gfp_t priority)
{
return __alloc_skb(size, priority, 0, -1);
}
/**
* __alloc_skb - allocate a network buffer
* @size: size to allocate
* @gfp_mask: allocation mask
* @fclone: allocate from fclone cache instead of head cache
* and allocate a cloned (child) skb
* @node: numa node to allocate memory on
*
* Allocate a new &sk_buff. The returned buffer has no headroom and a
* tail room of size bytes. The object has a reference count of one.
* The return is the buffer. On a failure the return is %NULL.
*
* Buffers may only be allocated from interrupts using a @gfp_mask of
* %GFP_ATOMIC.
*/
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int fclone, int node)
{
struct kmem_cache *cache;
struct skb_shared_info *shinfo;
struct sk_buff *skb;
u8 *data;
// 根据是否需要克隆,选择不同的高速缓存
cache = fclone ? skbuff_fclone_cache : skbuff_head_cache;
// 从高速缓存中分配sk_buff结构
skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node);
if (!skb)
goto out;
// 分配线性缓存区。实际分配的内存会在请求的基础上进行cache对齐,并且额外分配了skb共享信息
size = SKB_DATA_ALIGN(size);
data = kmalloc_node_track_caller(size + sizeof(struct skb_shared_info),
gfp_mask, node);
if (!data)
goto nodata;
/*
* Only clear those fields we need to clear, not those that we will
* actually initialise below. Hence, don't put any more fields after
* the tail pointer in struct sk_buff!
*/
// 如注释所述,只清零了tail指针之前的字段
memset(skb, 0, offsetof(struct sk_buff, tail));
skb->truesize = size + sizeof(struct sk_buff);
atomic_set(&skb->users, 1);
// 结合上图理解head、data、tail和end指针的位置,初始时data、tail指向线性缓存区开始,
// 这意味头空间和数据区都为0,尾空间大小为size
skb->head = data;
skb->data = data;
skb_reset_tail_pointer(skb);
skb->end = skb->tail + size;
// 初始化skb共享信息字段
shinfo = skb_shinfo(skb);
atomic_set(&shinfo->dataref, 1);
shinfo->nr_frags = 0;
shinfo->gso_size = 0;
shinfo->gso_segs = 0;
shinfo->gso_type = 0;
shinfo->ip6_frag_id = 0;
shinfo->frag_list = NULL;
// 如果也分配了克隆skb,初始化其sk_buff中的字段,见下面的“skb克隆”部分介绍
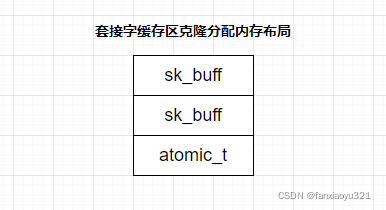
if (fclone) {
struct sk_buff *child = skb + 1;
atomic_t *fclone_ref = (atomic_t *) (child + 1);
skb->fclone = SKB_FCLONE_ORIG;
atomic_set(fclone_ref, 1);
child->fclone = SKB_FCLONE_UNAVAILABLE;
}
out:
return skb;
nodata:
kmem_cache_free(cache, skb);
skb = NULL;
goto out;
}
分配时如果已经知道之后有克隆场景,那么分配时的sk_buff内存布局如下图:
dev_alloc_skb()
/**
* dev_alloc_skb - allocate an skbuff for receiving
* @length: length to allocate
*
* Allocate a new &sk_buff and assign it a usage count of one. The
* buffer has unspecified headroom built in. Users should allocate
* the headroom they think they need without accounting for the
* built in space. The built in space is used for optimisations.
*
* %NULL is returned if there is no free memory. Although this function
* allocates memory it can be called from an interrupt.
*/
struct sk_buff *dev_alloc_skb(unsigned int length)
{
// 以GFP_ATOMIC方式分配内存,所以可以在中断上下文调用
return __dev_alloc_skb(length, GFP_ATOMIC);
}
static inline struct sk_buff *__dev_alloc_skb(unsigned int length,
gfp_t gfp_mask)
{
// 在请求的内存基础上多分配了16字节,并且为首部预留了这部分内存,便于填充mac首部
struct sk_buff *skb = alloc_skb(length + NET_SKB_PAD, gfp_mask);
if (likely(skb))
skb_reserve(skb, NET_SKB_PAD);
return skb;
}
skb的释放
skb的释放接口就是kfree_skb(),不过为了和dev_alloc_skb()对应,也定义了宏dev_kfree_skb(),不过该宏实际上就是kfree_skb()。
/**
* kfree_skb - free an sk_buff
* @skb: buffer to free
*
* Drop a reference to the buffer and free it if the usage count has
* hit zero.
*/
void kfree_skb(struct sk_buff *skb)
{
if (unlikely(!skb))
return;
// 如果skb的引用计数大于1,仅仅是递减引用计数,否则调用__kree_skb()真正的释放内存
if (likely(atomic_read(&skb->users) == 1))
smp_rmb();
else if (likely(!atomic_dec_and_test(&skb->users)))
return;
__kfree_skb(skb);
}
void __kfree_skb(struct sk_buff *skb)
{
// 释放skb对应的数据部分
skb_release_all(skb);
// 释放sk_buff部分
kfree_skbmem(skb);
}
skb_release_all()
/* Free everything but the sk_buff shell. */
static void skb_release_all(struct sk_buff *skb)
{
// 释放skb对其它数据结构的引用,比如dst等
skb_release_head_state(skb);
// 释放skb的数据部分
skb_release_data(skb);
}
skb_release_head_state()
static void skb_release_head_state(struct sk_buff *skb)
{
dst_release(skb->dst); // 释放对路由缓存的引用
if (skb->destructor) { // 如果由销毁回调,则调用它
WARN_ON(in_irq());
skb->destructor(skb);
}
}
skb_release_data()
static void skb_release_data(struct sk_buff *skb)
{
if (!skb->cloned ||
!atomic_sub_return(skb->nohdr ? (1 << SKB_DATAREF_SHIFT) + 1 : 1,
&skb_shinfo(skb)->dataref)) {
// 释放frags片段数组
if (skb_shinfo(skb)->nr_frags) {
int i;
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++)
put_page(skb_shinfo(skb)->frags[i].page);
}
// 释放frag_list片段链表
if (skb_shinfo(skb)->frag_list)
skb_drop_fraglist(skb);
// 释放线性缓存区和skb共享信息
kfree(skb->head);
}
}
数据预留和对齐
数据预留对齐是指skb_reserve()、skb_put()、skb_push()、skb_pull()这4个函数。当skb在各个协议层之间传递时,通过这些函数调整skb->tail和skb->tail指针,实现数据包首部、尾部的解析和封装,并且避免了大量的数据复制,从而提高效率。
skb_reserve()
reserve操作将data和tail指针加上指定的大小,效果就是增大了线性缓存区的头空间。通常高层协议在分配skb后通过该函数为底层协议预留首部空间。
/**
* skb_reserve - adjust headroom
* @skb: buffer to alter
* @len: bytes to move
*
* Increase the headroom of an empty &sk_buff by reducing the tail
* room. This is only allowed for an empty buffer.
*/
static inline void skb_reserve(struct sk_buff *skb, int len)
{
skb->data += len;
skb->tail += len;
}
skb_push()
push操作将data指针减去指定的值,并且增加skb->len的值。实现的效果就是线性缓存区数据区向头空间方向增加了指定字节。高层协议在添加自己的报文头部时会使用该函数。
/**
* skb_push - add data to the start of a buffer
* @skb: buffer to use
* @len: amount of data to add
*
* This function extends the used data area of the buffer at the buffer
* start. If this would exceed the total buffer headroom the kernel will
* panic. A pointer to the first byte of the extra data is returned.
*/
static inline unsigned char *skb_push(struct sk_buff *skb, unsigned int len)
{
skb->data -= len;
skb->len += len;
if (unlikely(skb->data < skb->head))
skb_under_panic(skb, len, current_text_addr());
return skb->data;
}
skb_put()
put操作将tail指针增加指定的值,并且增加skb->len的值。实现的效果就是线性缓存区的数据区向尾空间方向增加了指定字节。协议在数据包尾部增加内容时会使用该函数。
/**
* skb_put - add data to a buffer
* @skb: buffer to use
* @len: amount of data to add
*
* This function extends the used data area of the buffer. If this would
* exceed the total buffer size the kernel will panic. A pointer to the
* first byte of the extra data is returned.
*/
static inline unsigned char *skb_put(struct sk_buff *skb, unsigned int len)
{
unsigned char *tmp = skb_tail_pointer(skb);
SKB_LINEAR_ASSERT(skb);
skb->tail += len;
skb->len += len;
if (unlikely(skb->tail > skb->end))
skb_over_panic(skb, len, current_text_addr());
return tmp;
}
skb_pull()
pull操作将data指针增加指定值,并且减少skb->len的值。实现的效果就是线性缓存区的头空间向数据区方向增加了指定字节。通常协议栈在从下往上传递数据过程中使用该接口剥掉底层协议的首部。
static inline unsigned char *__skb_pull(struct sk_buff *skb, unsigned int len)
{
skb->len -= len;
BUG_ON(skb->len < skb->data_len);
return skb->data += len;
}
/**
* skb_pull - remove data from the start of a buffer
* @skb: buffer to use
* @len: amount of data to remove
*
* This function removes data from the start of a buffer, returning
* the memory to the headroom. A pointer to the next data in the buffer
* is returned. Once the data has been pulled future pushes will overwrite
* the old data.
*/
static inline unsigned char *skb_pull(struct sk_buff *skb, unsigned int len)
{
return unlikely(len > skb->len) ? NULL : __skb_pull(skb, len);
}
skb的克隆与拷贝
如前面介绍的,skb在内存上分为sk_buff和缓存区两部分,控制部分(尤其是指针)保存在sk_buff中,数据部分保存在缓存区中。有时候,可能只是想要有复制sk_buff,但是不想复制缓存区,这就是“克隆”。类似的,如果既想复制sk_buff,又想复制缓存区,那么就是“拷贝”。
skb克隆: skb_clone()
在介绍克隆之前,首先介绍下skb->fclone标记的使用。
enum {
SKB_FCLONE_UNAVAILABLE, // 标记相邻的两个skb中的第二个skb->fclone,表示其还未被克隆使用
SKB_FCLONE_ORIG, // 标记skb后面还有一个相邻的skb
SKB_FCLONE_CLONE, // 标记skb被克隆
};
如果一个skb在分配的时候,就知道它后面会被克隆,那么可以在调用alloc_skb()时指定第三个参数为1,这时会一次分配两个sk_buff,它们在内存上是连续的,并且会将第一个skb->fclone设置成SKB_FCLONE_ORIG,把第二个skb->fclone设置成SKB_FCLONE_UNAVAILABLE。
/**
* skb_clone - duplicate an sk_buff
* @skb: buffer to clone
* @gfp_mask: allocation priority
*
* Duplicate an &sk_buff. The new one is not owned by a socket. Both
* copies share the same packet data but not structure. The new
* buffer has a reference count of 1. If the allocation fails the
* function returns %NULL otherwise the new buffer is returned.
*
* If this function is called from an interrupt gfp_mask() must be
* %GFP_ATOMIC.
*/
struct sk_buff *skb_clone(struct sk_buff *skb, gfp_t gfp_mask)
{
struct sk_buff *n;
n = skb + 1;
if (skb->fclone == SKB_FCLONE_ORIG &&
n->fclone == SKB_FCLONE_UNAVAILABLE) {
// 源skb有相邻的skb还未被克隆使用,直接使用该sk_buff即可,无需重新分配
atomic_t *fclone_ref = (atomic_t *) (n + 1);
n->fclone = SKB_FCLONE_CLONE; // 第二个skb被标记为SKB_FCLONE_CLONE
atomic_inc(fclone_ref);
} else {
// 其它场景,新分配一个sk_buff用于克隆
n = kmem_cache_alloc(skbuff_head_cache, gfp_mask);
if (!n)
return NULL;
n->fclone = SKB_FCLONE_UNAVAILABLE;
}
// 用skb中各个字段初始化克隆的skb
return __skb_clone(n, skb);
}
// 克隆skb的各个字段到n中,要注意的是会将skb和n的cloned字段都标记为1,表示它们被克隆过
static struct sk_buff *__skb_clone(struct sk_buff *n, struct sk_buff *skb)
{
#define C(x) n->x = skb->x
n->next = n->prev = NULL;
n->sk = NULL;
__copy_skb_header(n, skb);
C(len);
C(data_len);
C(mac_len);
n->hdr_len = skb->nohdr ? skb_headroom(skb) : skb->hdr_len;
n->cloned = 1; // 新skb被标记为已被克隆
n->nohdr = 0;
n->destructor = NULL;
C(iif);
C(tail);
C(end);
C(head);
C(data);
C(truesize);
#if defined(CONFIG_MAC80211) || defined(CONFIG_MAC80211_MODULE)
C(do_not_encrypt);
C(requeue);
#endif
// 新克隆的skb引用计数也是1,这样可以独立的删除sk_buff自身
atomic_set(&n->users, 1);
// 增加skb共享信息中的引用计数,表示引用了相同的数据部分
atomic_inc(&(skb_shinfo(skb)->dataref));
skb->cloned = 1; // 源skb被标记为已被克隆
return n;
#undef C
}
如上所示,只要skb被克隆过,或者skb是克隆来的,那么其skb->cloned标记都会被置为1,所以并不能单纯的通过该标记来判断一个skb是否被克隆过,克隆判断函数的实现是skb_cloned(),如下:
static inline int skb_cloned(const struct sk_buff *skb)
{
return skb->cloned &&
(atomic_read(&skb_shinfo(skb)->dataref) & SKB_DATAREF_MASK) != 1;
}
有时候,我们可能只关心skb本身是否被共享,因为共享情况下是不能对其字段进行修改的,此时应该使用函数skb_shared():
static inline int skb_shared(const struct sk_buff *skb)
{
return atomic_read(&skb->users) != 1;
}
skb_share_check()
该函数检查skb本身是否被共享,如果被共享,那么它会克隆一个,并释放旧的skb,返回新的skb。使用示例见ip_rcv(),当IPv4收到一个数据包,之后的处理需要对其进行修改,此时如果发现skb是被共享的,那么就会使用该函数克隆一个。
/**
* skb_share_check - check if buffer is shared and if so clone it
* @skb: buffer to check
* @pri: priority for memory allocation
*
* If the buffer is shared the buffer is cloned and the old copy
* drops a reference. A new clone with a single reference is returned.
* If the buffer is not shared the original buffer is returned. When
* being called from interrupt status or with spinlocks held pri must
* be GFP_ATOMIC.
*
* NULL is returned on a memory allocation failure.
*/
static inline struct sk_buff *skb_share_check(struct sk_buff *skb, gfp_t pri)
{
might_sleep_if(pri & __GFP_WAIT);
if (skb_shared(skb)) {
// 如果skb被共享,那么会克隆一个,并释放旧的,返回克隆后的skb
struct sk_buff *nskb = skb_clone(skb, pri);
kfree_skb(skb);
skb = nskb;
}
return skb;
}
skb拷贝
如果想要修改skb的数据部分,那么skb克隆就不适用了,需要使用拷贝。skb的拷贝可以分为部分拷贝和全拷贝。如果很明确的知道要拷贝某个部分,那么应该使用pskb_copy(),否则使用skb_copy()。二者过程比较复杂,但是原理很清晰,我们只列出函数原型:
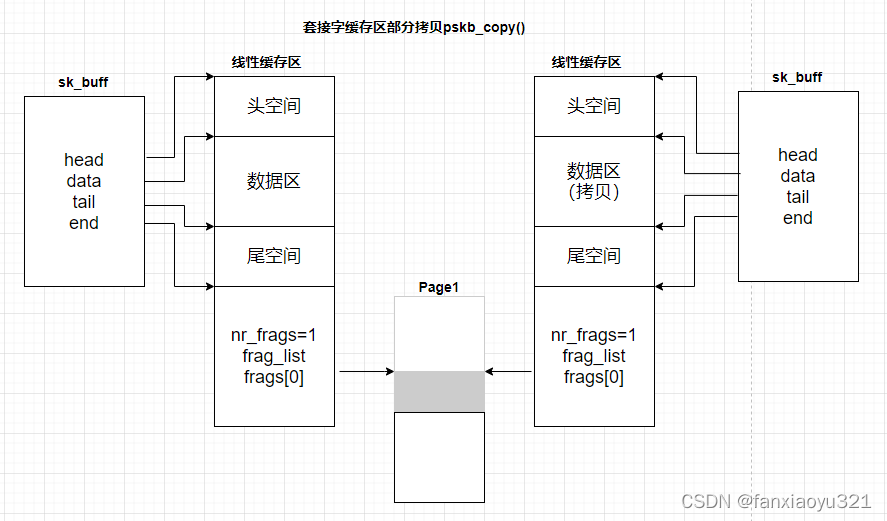
skb部分拷贝: pskb_copy()
注意,pskb_copy()并未提供参数让调用者指定要拷贝哪些数据,它默认只拷贝线性缓存区中的数据区内容,frags片段数组和frag_list片段链表的内容依然是共享的。
/**
* pskb_copy - create copy of an sk_buff with private head.
* @skb: buffer to copy
* @gfp_mask: allocation priority
*
* Make a copy of both an &sk_buff and part of its data, located
* in header. Fragmented data remain shared. This is used when
* the caller wishes to modify only header of &sk_buff and needs
* private copy of the header to alter. Returns %NULL on failure
* or the pointer to the buffer on success.
* The returned buffer has a reference count of 1.
*/
struct sk_buff *pskb_copy(struct sk_buff *skb, gfp_t gfp_mask);
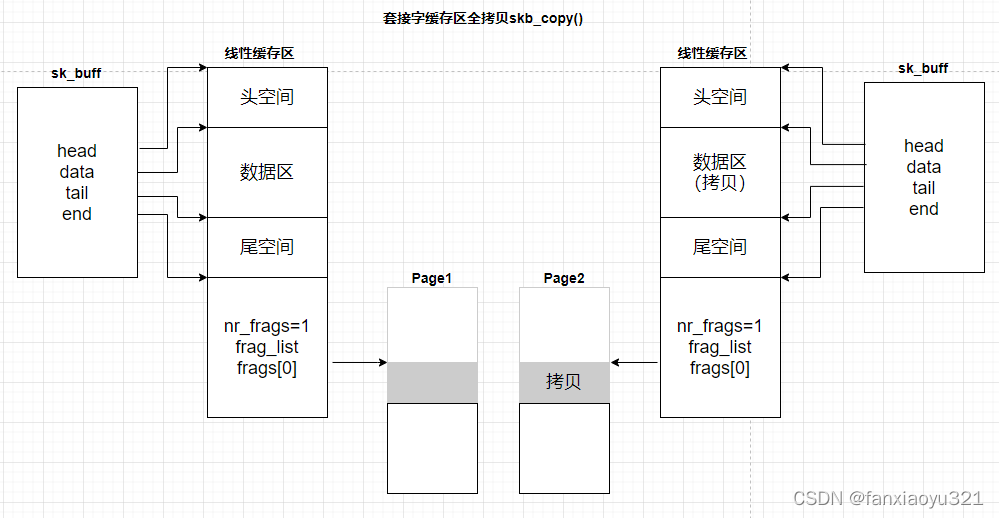
skb全拷贝: skb_copy()
/**
* skb_copy - create private copy of an sk_buff
* @skb: buffer to copy
* @gfp_mask: allocation priority
*
* Make a copy of both an &sk_buff and its data. This is used when the
* caller wishes to modify the data and needs a private copy of the
* data to alter. Returns %NULL on failure or the pointer to the buffer
* on success. The returned buffer has a reference count of 1.
*
* As by-product this function converts non-linear &sk_buff to linear
* one, so that &sk_buff becomes completely private and caller is allowed
* to modify all the data of returned buffer. This means that this
* function is not recommended for use in circumstances when only
* header is going to be modified. Use pskb_copy() instead.
*/
struct sk_buff *skb_copy(const struct sk_buff *skb, gfp_t gfp_mask);

















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









