






梳理总结一下生产中使用到的prometheus相关知识。包括但不限于传统服务(主机、Nginx、Tomcat、Haproxy等)、云原生(Kubernetes)周边生态的监控等等。
部署使用中最直观的感受就是,prometheus只是一个时序数据库,像规则匹配、告警都是在后端机器上配置或借助于其他插件完成。没有Zabbix监控功能齐全,各种成熟的模板、告警媒介插件、规则配置、dashboard定义等。转折来了,随着云原生肉眼可见发展的速度及周边生态不断完善,prometheus监控使用非常广泛,趋势不可违。
目录
一、监控的理论
简单概述,主要以使用方法为主
1、监控的重要性
通过业务监控系统,全⾯掌握业务环境的运⾏状态,通过⽩盒监控能够提前预知业务瓶颈,通过⿊盒监 控能够第⼀时间发现业务故障并通过告警通告运维⼈员进⾏紧急恢复,从⽽将业务影响降到最低。
⿊盒监控,关注的是时时的状态,⼀般都是正在发⽣的事件,⽐如nginx web界⾯打开的是界⾯报错503、 磁盘⽆法报错数据等,即⿊盒监控重点在于能对正在发⽣的故障进⾏通知告警。 ⽩盒监控,关注的是原因,也就是系统内部暴露的⼀些指标数据,⽐如nginx 后端服务器的响应时⻓、磁盘 的I/O负载值等。
监控系统需要能够有效的⽀持⽩盒监控和⿊盒监控,通过⽩盒能够了解其内部的实际运⾏状态,以及对 监控指标的观察能够预判可能出现的潜在问题,从⽽对潜在的不确定因素进⾏提前优化并避免问题的发 ⽣,⽽通过⿊盒监控,⽐如常⻅的如HTTP探针、TCP探针等,可以在系统或者服务在发⽣故障时能够快 速通知相关的⼈员进⾏处理,通过建⽴完善的监控体系,从⽽达到以下⽬的:
1.1、 ⻓期趋势分析
通过对监控样本数据的持续收集和统计,对监控指标进⾏⻓期趋势分析。例如,通过对磁盘 空间增⻓率的判断,我们可以提前预测在未来什么时间节点上需要对资源进⾏扩容。
1.2、 对照分析
两个版本的系统运⾏资源使⽤情况的差异如何?在不同容量情况下系统的并发和负载变化如何? 通过监控能够⽅便的对系统进⾏跟踪和⽐较。
1.3、 告警通知
当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从⽽能够对问题进⾏快速的 处理或者提前预防问题的发⽣,避免出现对业务的影响。
.1.4、 故障分析与定位
当问题发⽣后,需要对问题进⾏调查和处理。通过对不同监控监控以及历史数据的分析, 能够找到并解决根源问题。
.1.5、 故障分析与定位
通过可视化仪表盘能够直接获取系统的运⾏状态、资源使⽤情况、以及服务运⾏状态等直观的 信息。
2、 了解常⻅的监控⽅案
开源监控软件:zabbix、smokeping、open-falcon。等
很少能用到,不用了解cacti、nagios
2.1、Zabbix
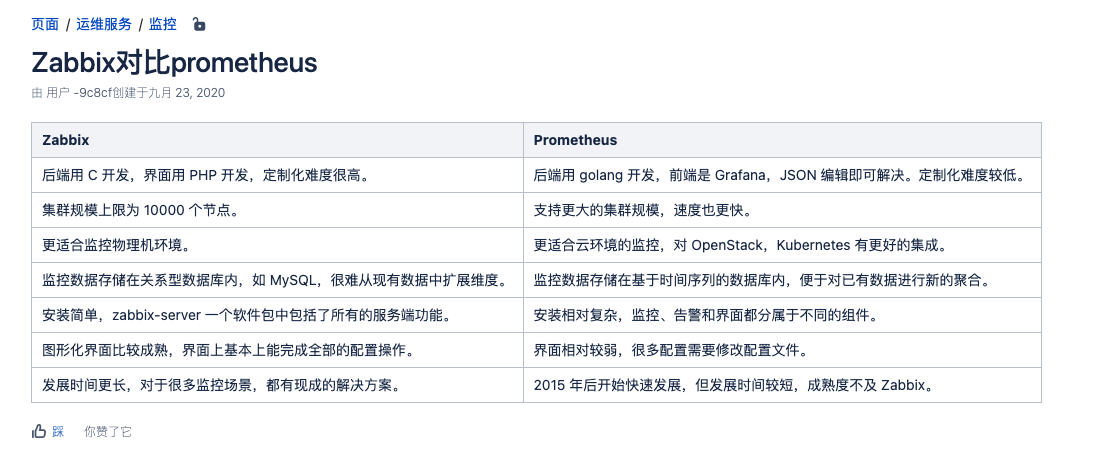
⽬前使⽤较多的开源监控软件,可横向扩展、⾃定义监控项、⽀持多种监控⽅式、可监控⽹络与服务等。
2.2、 SmokePing
Smokeping是⼀款⽤于⽹络性能监测的开源监控软件,主要⽤于对IDC的⽹络状况,⽹络质量,稳定性等做 检测,通过rrdtool制图⽅式,图形化地展示⽹络的时延情况,进⽽能够清楚的判断出⽹络的即时通信情 况。
2.3、 Open-falcon
2.4、 商业监控解决⽅案
不用过多了解,领导让你调研的时候知道有这这样的产品就行
二、Prometheus Server使用
1、本次分享内容环境信息
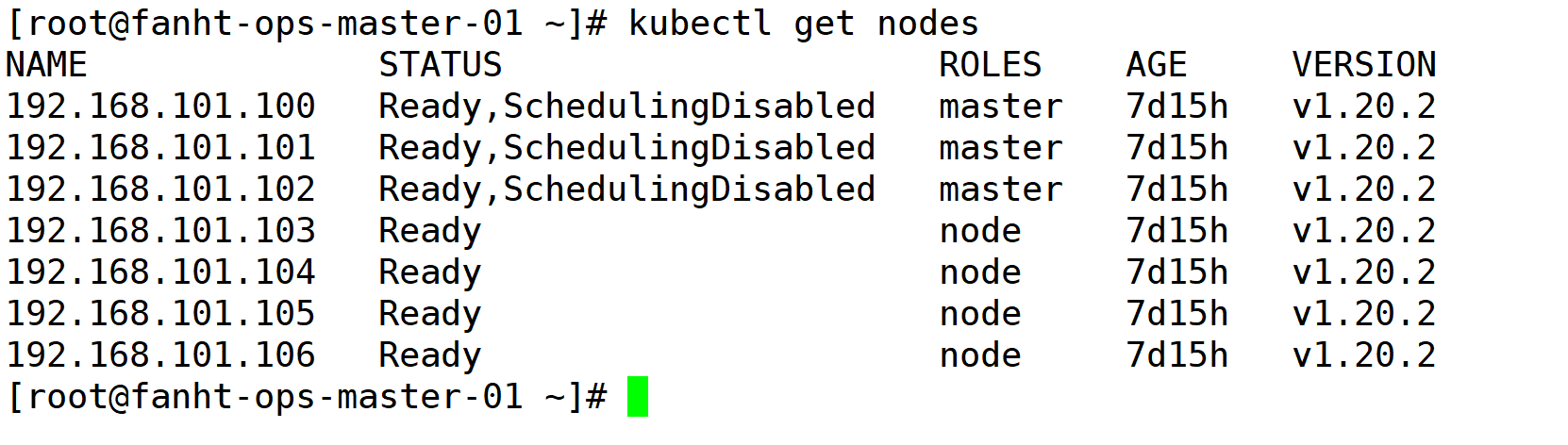
1.1、机器信息
| 主机列表 | 本次分享中角色 | 备注 |
| 192.168.101.200 | 二进制Prometheus Server | 收集exporter的数据和K8s数据 |
| 192.168.101.201 | 二进制部署各种exporter | 完成指标采集 |
| 192.168.101.100-106 | Kubernetes cluster | 部署Prometheus Pod,收集集群信息 |
1.2、端口用途备注
| 使用端口 | 服务名称 | 部署路径 |
| 9090 | prometheus-server | |
| 9100 | node_exporter | 每个Linux机器安装 |
| 30000 | Grafana | prometheus-server机器安装 |
1.3、部署路径
二进制所有服务均存放在目录中
/data
1、prometheus
/data/prometheus
2、alermanger
/data/alertmanger
3、counsul
/data/consul
2、 prometheus 简介
Prometheus是基于go语⾔开发的⼀套开源的监控、报警和时间序列数据库的组合,是由SoundCloud 公司开发的开源监控系统,Prometheus于2016年加⼊CNCF(Cloud Native Computing Foundation, 云原⽣计算基⾦会),2018年8⽉9⽇prometheus成为CNCF继kubernetes 之后毕业的第⼆个项⽬, prometheus在容器和微服务领域中得到了⼴泛的应⽤,其特点主要如下:
使⽤key-value的多维度(多个⻆度,多个层⾯,多个⽅⾯)格式保存数据 数据不使⽤MySQL这样的传统数据库,⽽是使⽤时序数据库,⽬前是使⽤的TSDB ⽀持第三⽅dashboard实现更绚丽的图形界⾯,如grafana(Grafana 2.5.0版本及以上) 组件模块化 不需要依赖存储,数据可以本地保存也可以远程保存 平均每个采样点仅占3.5 bytes,且⼀个Prometheus server可以处理数百万级别的的metrics指标数 据。 ⽀持服务⾃动化发现(基于consul等⽅式动态发现被监控的⽬标服务) 强⼤的数据查询语句功(PromQL,Prometheus Query Language) 数据可以直接进⾏算术运算 易于横向伸缩 众多官⽅和第三⽅的exporter实现不同的指标数据收集
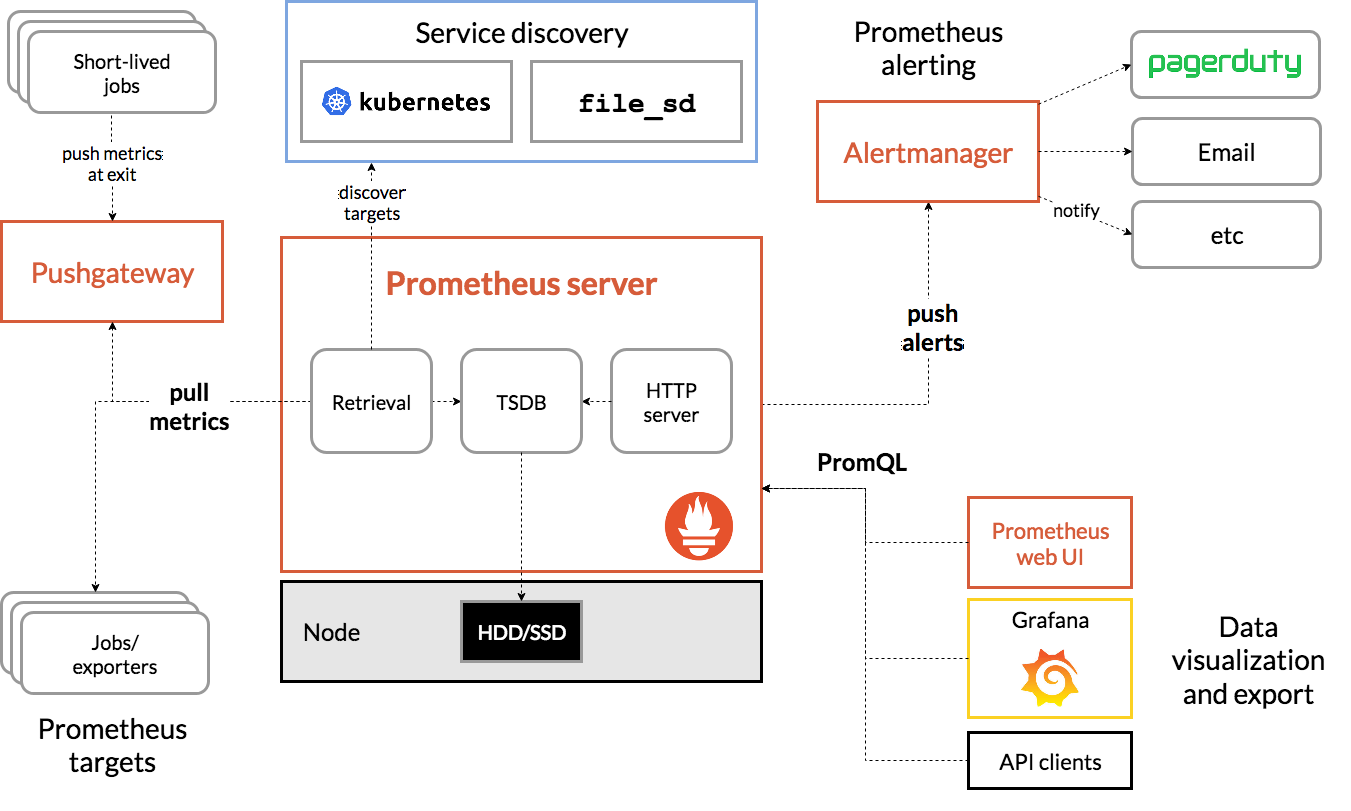
2.1、官网架构图
prometheus server:主服务,接受外部http请求,收集、存储与查询数据等
prometheus targets: 静态收集的⽬标服务数据
service discovery:动态发现服务
prometheus alerting:报警通知
push gateway:数据收集代理服务器(类似于zabbix proxy)
data visualization and export: 数据可视化与数据导出(访问客户端)
2.2、"画蛇添足"图
3、prometheus使用完成效果
3.1、集群联邦
二进制高配机器部署prometheus server 与K8S中的sprometheus监控混着用
3.2、使用二进制prometheus server使用
1、收集非K8s业务服务监控指标
2、配置告警规则
3、结合多种媒介进行告警通知
4、prometheus 部署使用
可以通过不同的⽅式安装部署prometheus监控环境,支持二进制、docker、docker-compose、prometheus等多种方式部署,实际⽣产环境要根据实际需求选择其中⼀种⽅式部署即可,不过⽆论是使⽤哪⼀种⽅式安 装部署的prometheus server,使⽤方法都是⼀样的。本次分享主要以二进制方式为主,因为后面集群联邦的时候二进制prometheus-server会接收所有K8s集群prometheus-server的数据和各种exporter数据。
4.1、二进制部署Prometheus server
官方提供的服务和插件,满足不了需求可以去github上找第三方插件。
4.1.1、下载prometheus server
prometheus-2.36.2.linux-amd64.tar.gz

2022年6月20号版本
不建议使用最新的prometheus,会出现grafana上模板没有数据,不兼容的新规则的问题
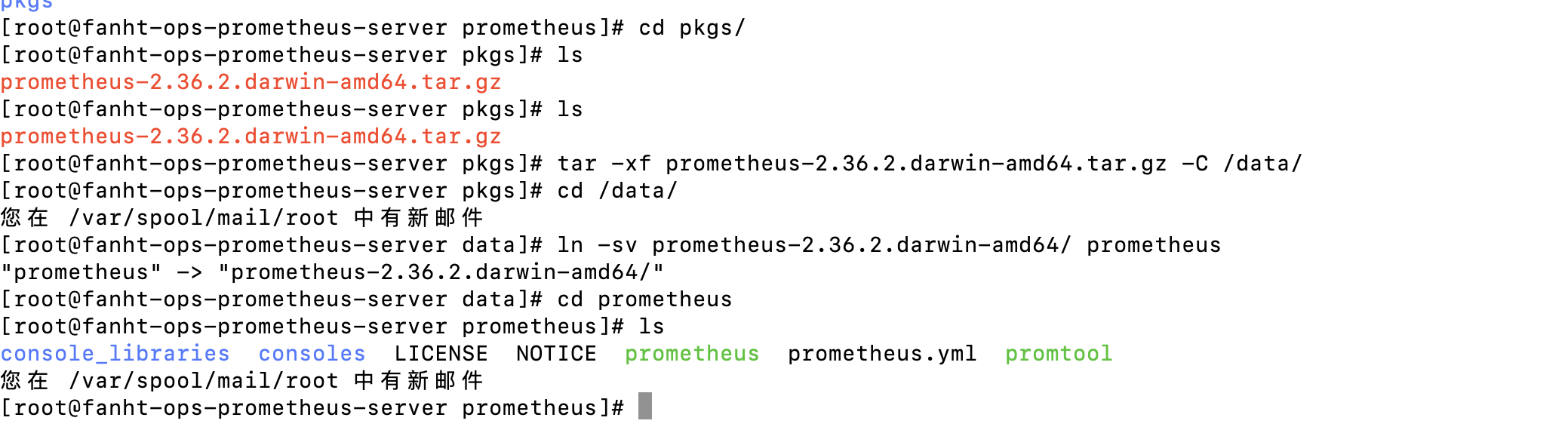
4.1.2、解压安装包
cd pkgs/ ls tar -xf prometheus-2.36.2.darwin-amd64.tar.gz -C /data/ cd /data/ ln -sv prometheus-2.36.2.darwin-amd64/ prometheus
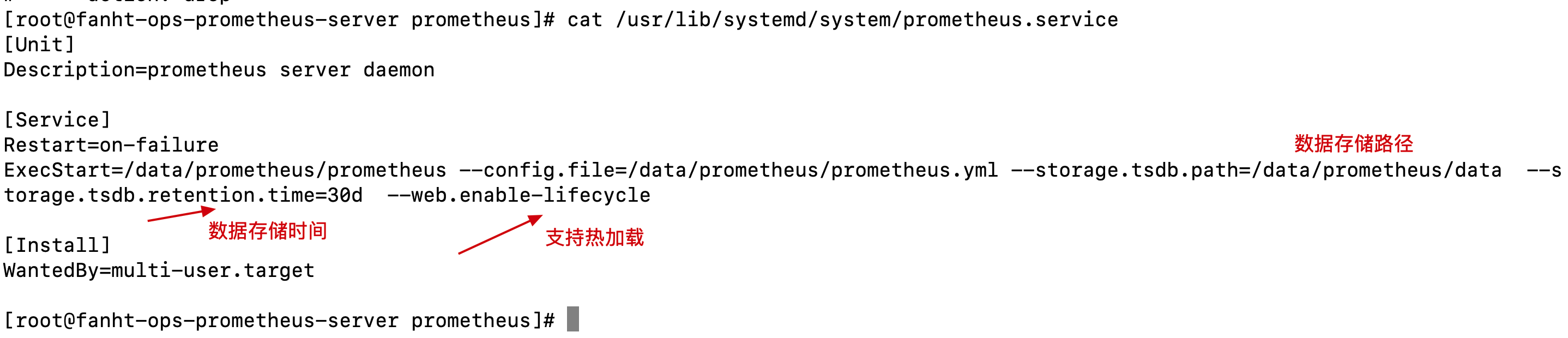
4.1.3、配置启动服务
添加守护进程启动文件
cat /usr/lib/systemd/system/prometheus.service
[Unit] Description=prometheus server daemon [Service] Restart=on-failure ExecStart=/data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --storage.tsdb.retention.time=30d --web.enable-lifecycle [Install] WantedBy=multi-user.target
设置开机自启
systemctl daemon-reload systemctl enable prometheus.service systemctl start prometheus.service

4.1.5、了解prometheus配置文件
# my global config global: # scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. #数据收集间隔时间,如果不配置默认为⼀分钟 evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. #规则扫描间隔时间,如果不配置默认为⼀分钟 # scrape_timeout is set to the global default (10s). # Alertmanager configuration

4.1.6、访问prometheus前端页面
4.2、了解Exporter相关知识
不光键盘敲得飞起,更多知道清楚使用原理。
广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称为target,如下所示,Prometheus通过轮询的方式定期从这些target中获取样本数据:
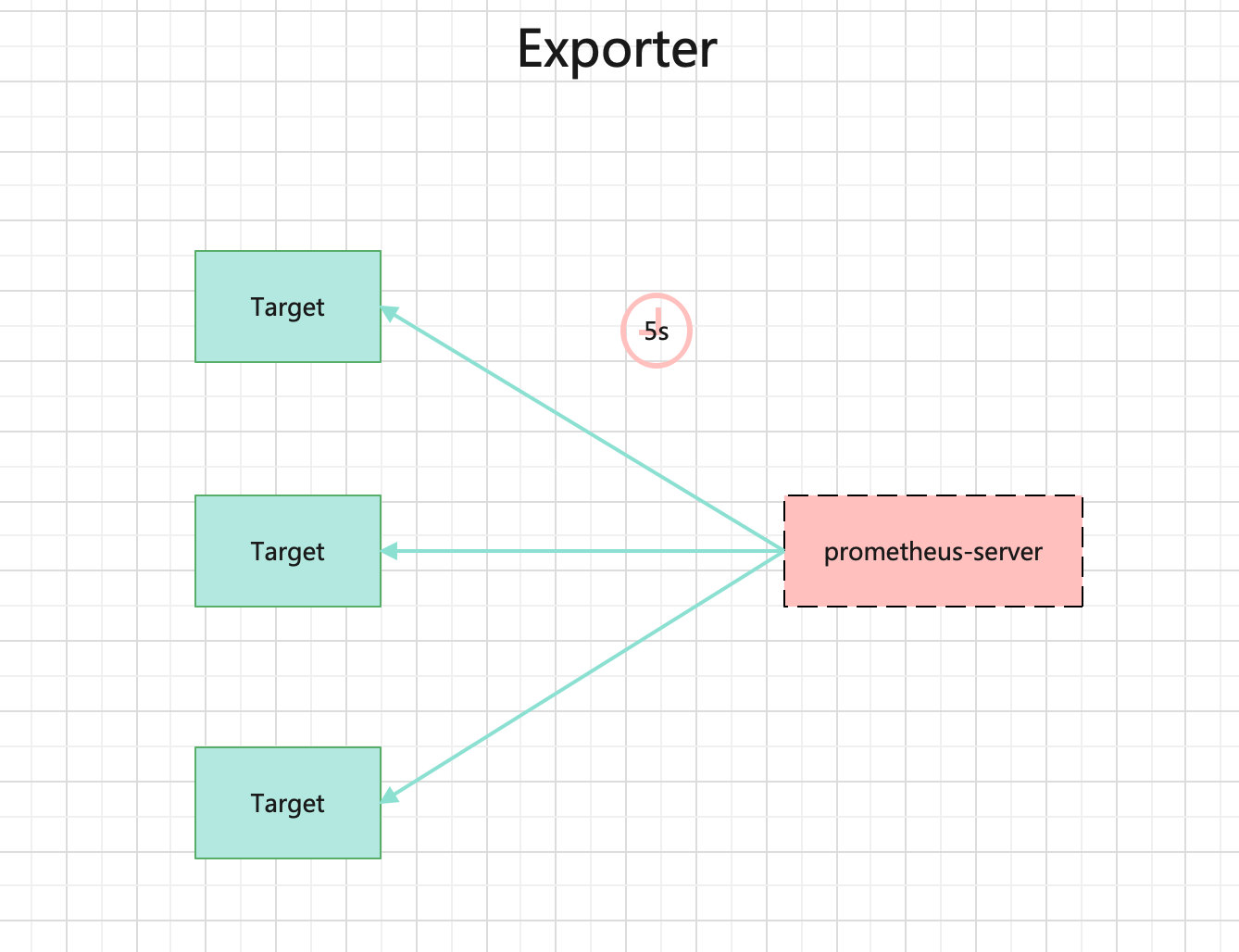
4.2.1、使用Exporter原因
云原生组件支持prometheus接口监控。etcd、Kubernetes、CoreDNS等,可以直接被prometheus监控。
大多数服务在Prometheus诞生前的很多年就已发布,考虑到安全性、稳定性及代码耦合等因素的影响,软件作者并不愿意将监控代码加入现有代码中。
在此背景之下,Exporter 应运而生,Prometheus 在面对众多繁杂的监控对象时并没有采用逐一适配的方式,而是制定了一套独特的监控数据规范,符合这套规范的监控数据都可以被Prometheus统一采集、分析和展现。说白了你想用prometheus收集数据要么改造软件支持prometheus数据格式,要不然开发第三方插件Exporter。
4.2.2、Exporter获取监控数据的方式
HTTPS方式
HTTP方式
TCP方式
本地文件方式
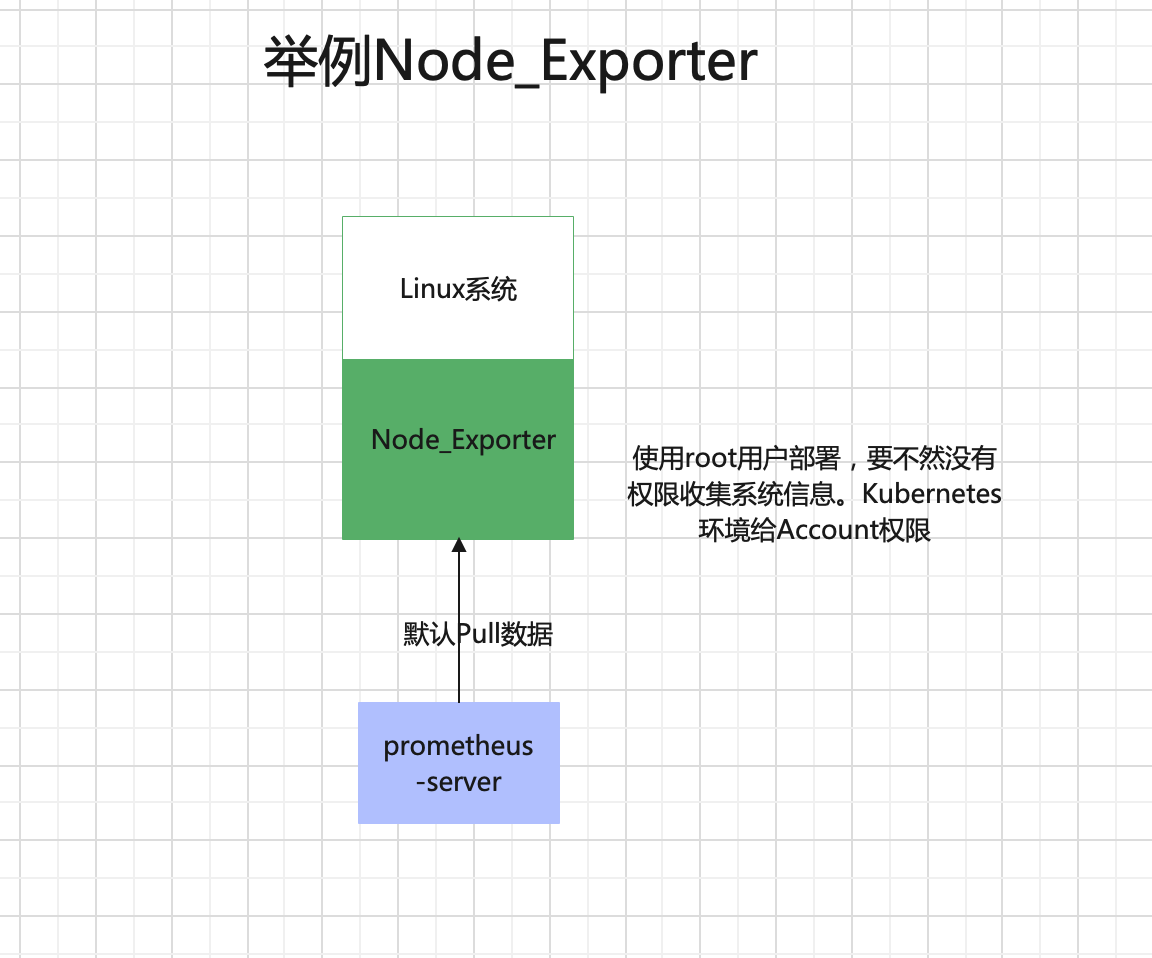
4.2.3、举例Node_Exporter
Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集、存储、对外提供数据查询,的支持。
收集操作系统和硬件信息的组件
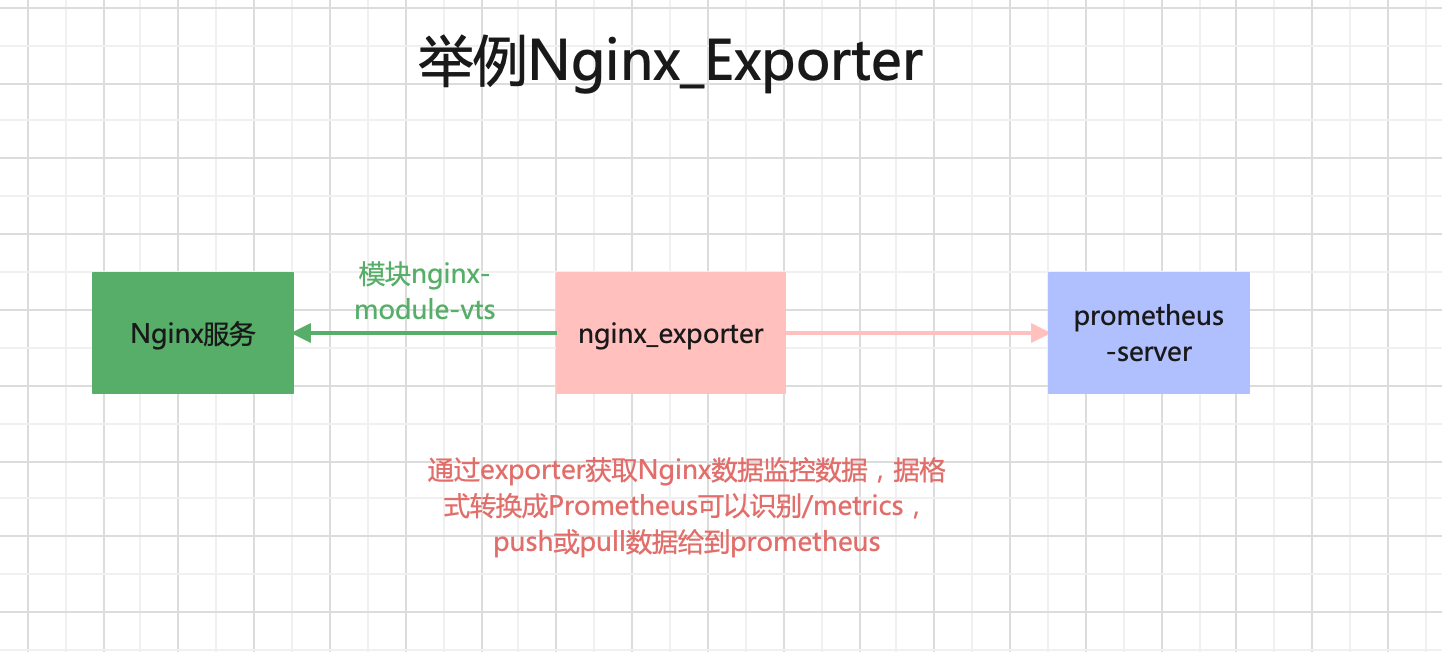
4.2.4、举例Nginx_Exporter
exporter先通过nginx模块(nginx-module-vts)收集指标数据,进行加工转换成prometheus可以识别到的kv/metrics。
所有的Exporter程序都需要按照Prometheus的规范,返回监控的样本数据。
4.3、部署node_exporter
| Ip规划 | 部署角色 | 版本 |
| 192.168.101.200 | node_exporter | |
| 192.168.101.201 | node_exporter |
4.3.1、下载node_exporter
这个稳定版本与prometheus版本发布时间最合适。
1、官网最新版本
4.3.1、192.168.101.200 安装配置node_exporter
1、解压安装包
tar -xf node_exporter-1.4.0.linux-amd64.tar.gz -C /data/ cd /data/ ln -sv node_exporter-1.4.0.linux-amd64/ node_exporter cd node_exporter ls

2、配置Nodde_Exporter系统启动
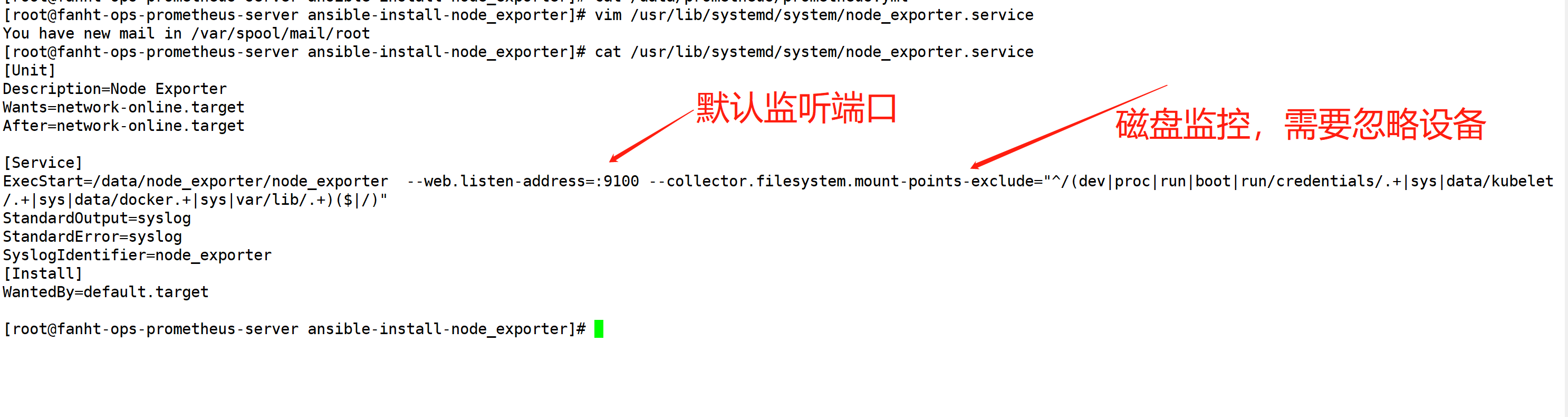
cat /usr/lib/systemd/system/node_exporter.service systemctl daemon-reload systemctl enable node_exporter.service systemctl start node_exporter.service ps -ef |grep node_exporter
[Unit] Description=Node Exporter Wants=network-online.target After=network-online.target [Service] ExecStart=/data/node_exporter/node_exporter --web.listen-address=:9100 --collector.filesystem.mount-points-exclude="^/(dev|proc|run|boot|run/credentials/.+|sys|data/kubelet/.+|sys|data/docker.+|sys|var/lib/.+)($|/)" StandardOutput=syslog StandardError=syslog SyslogIdentifier=node_exporter [Install] WantedBy=default.target
4.3.2、192.168.101.201 安装配置node_exporter
手动安装操作步骤同4.3.1
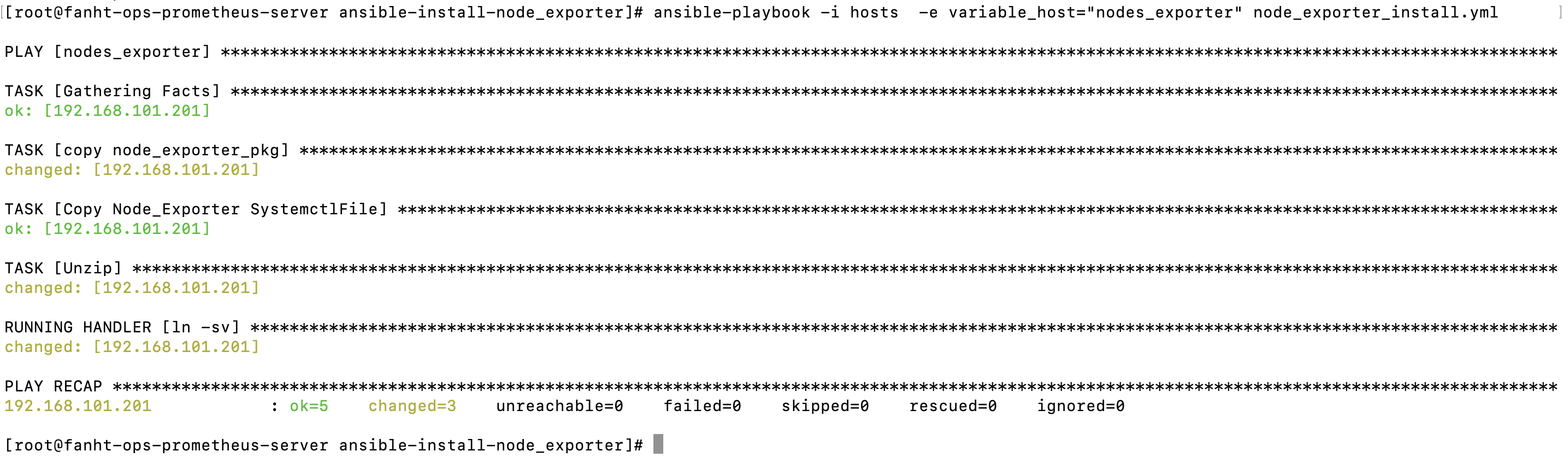
4.3.3、批量安装node_exporter
如果公司内有几十台上百台机器需要安装node_exporter,可以使用ansible批量安装
使用ansible 批量安装node_exporter
- hosts: nodes_exporter
vars:
- node_exporter_package: node_exporter-1.4.0.linux-amd64.tar.gz
- package_version: node_exporter-1.4.0.linux-amd64
tasks:
- name: copy node_exporter_pkg
copy:
src: ./{{node_exporter_package}}
dest: /data/{{node_exporter_package}}
owner: root
group: root
mode: 0644
- name: "Copy Node_Exporter SystemctlFile"
copy:
src: ./node_exporter.service
dest: /usr/lib/systemd/system/node-exporter.service
owner: root
group: root
mode: 0644
- name: "Unzip"
unarchive:
src: /data/{{node_exporter_package}}
dest: /data/
remote_src: yes
mode: 0755
notify:
- "ln -sv"
handlers:
- name: "ln -sv"
file:
src: /data/{{package_version}}
dest: /data/node_exporter
state: link
ansible-playbook -i hosts -e variable_host="nodes_exporter" node_exporter_install.yml
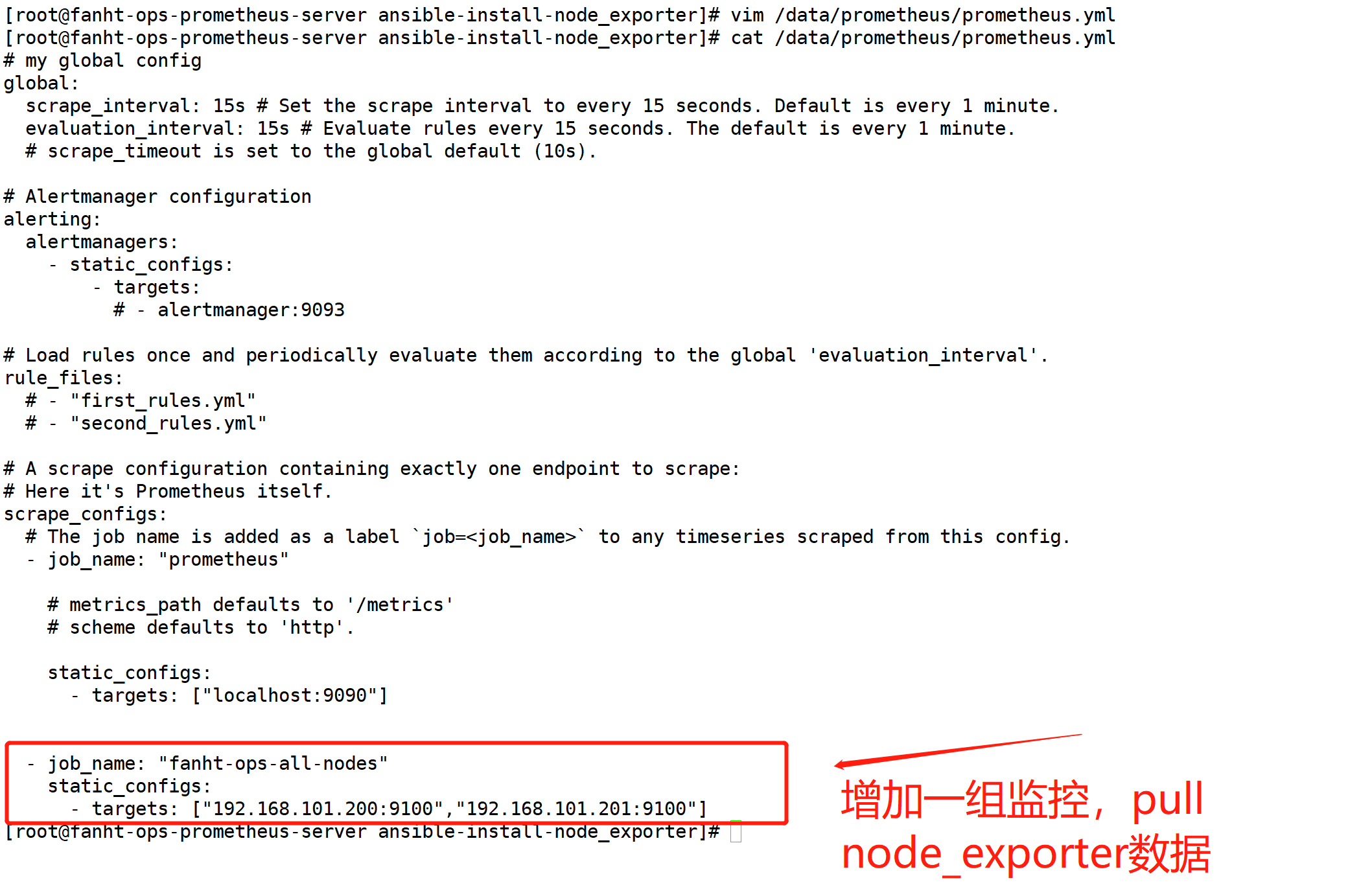
4.3.4、prometheus server收集node节点信息
cat /data/prometheus/prometheus.yml
- job_name: "test_nodes"
static_configs:
- targets: ["192.168.101.200:9100","192.168.101.201"]
4.3.5、调用prometheus接口热加载配置
curl -X POST 192.168.101.200:9090/-/reload
如果报错也会检查到,类似nginx -s reload

4.4、登录prometheus-server前端
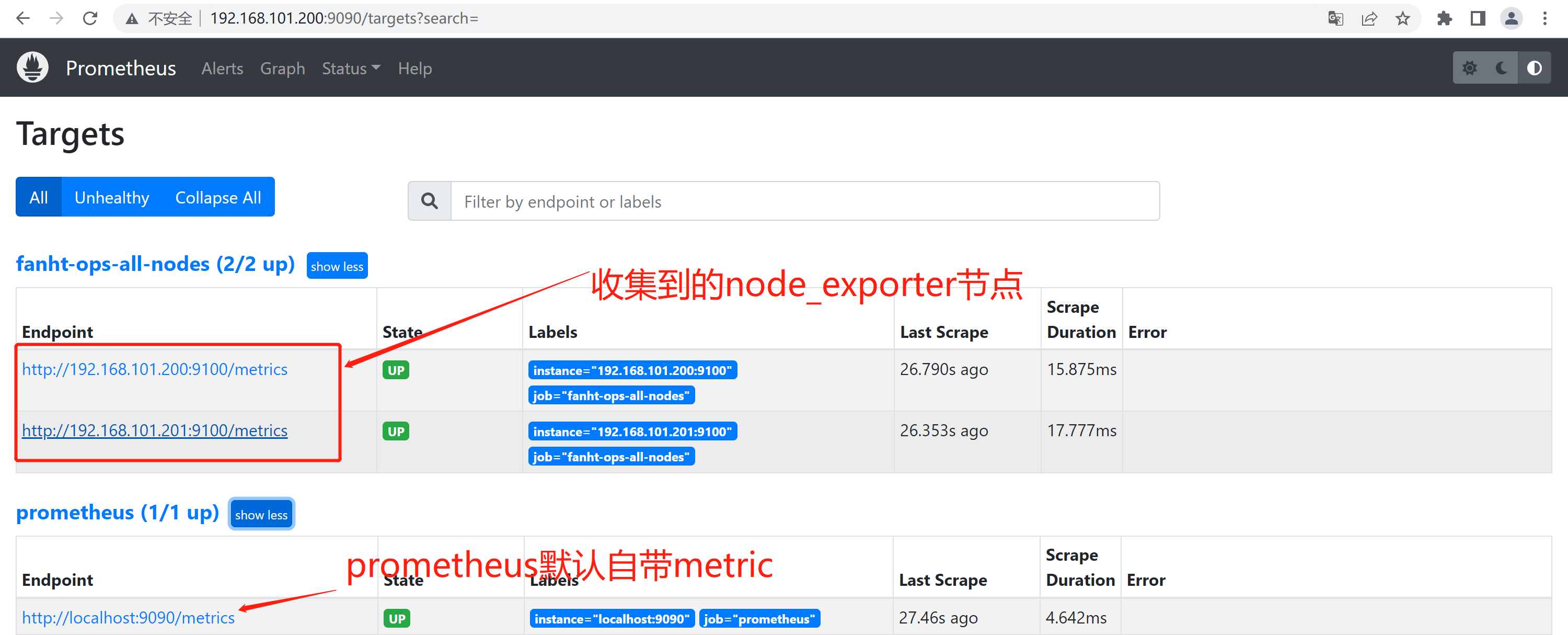
4.4.1、查看Target验证node_exporter
有图更好理解Target
Exporter的一个实例称为Target
可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。
4.4.2、查看node_exporter metrics
http://192.168.101.200:9100/metrics
http://192.168.101.201:9100/metrics
以k:v形式,收集所有指标数据
4.4.1、简单使用PromQL
Prometheus提供⼀个函数式的表达式语⾔PromQL (Prometheus Query Language),可以使⽤户实时 地查找和聚合时间序列数据,表达式计算结果可以在图表中展示,也可以在Prometheus表达式浏览器 中以表格形式展示,或者作为数据源, 以HTTP API的⽅式提供给外部系统使⽤。
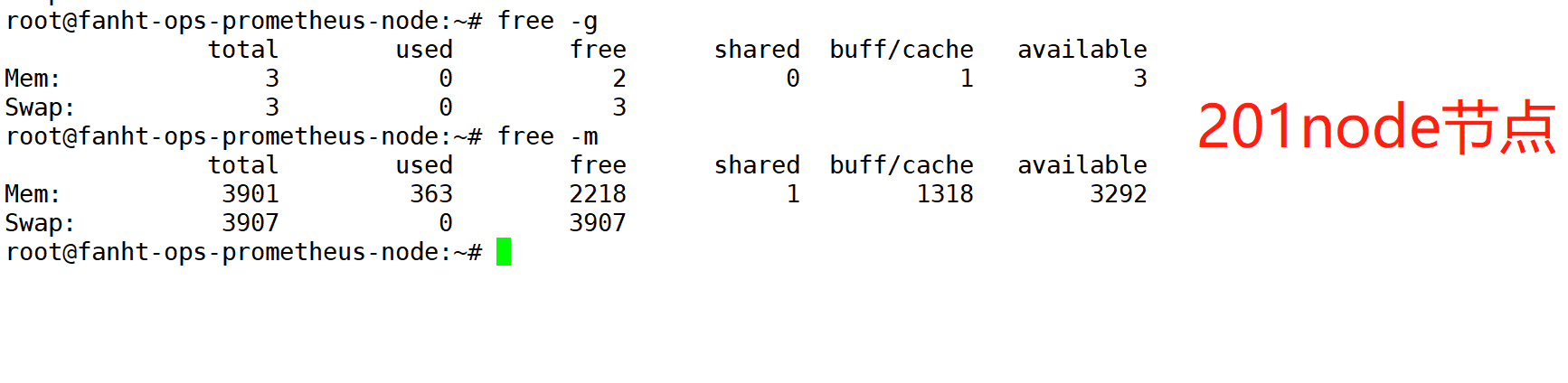
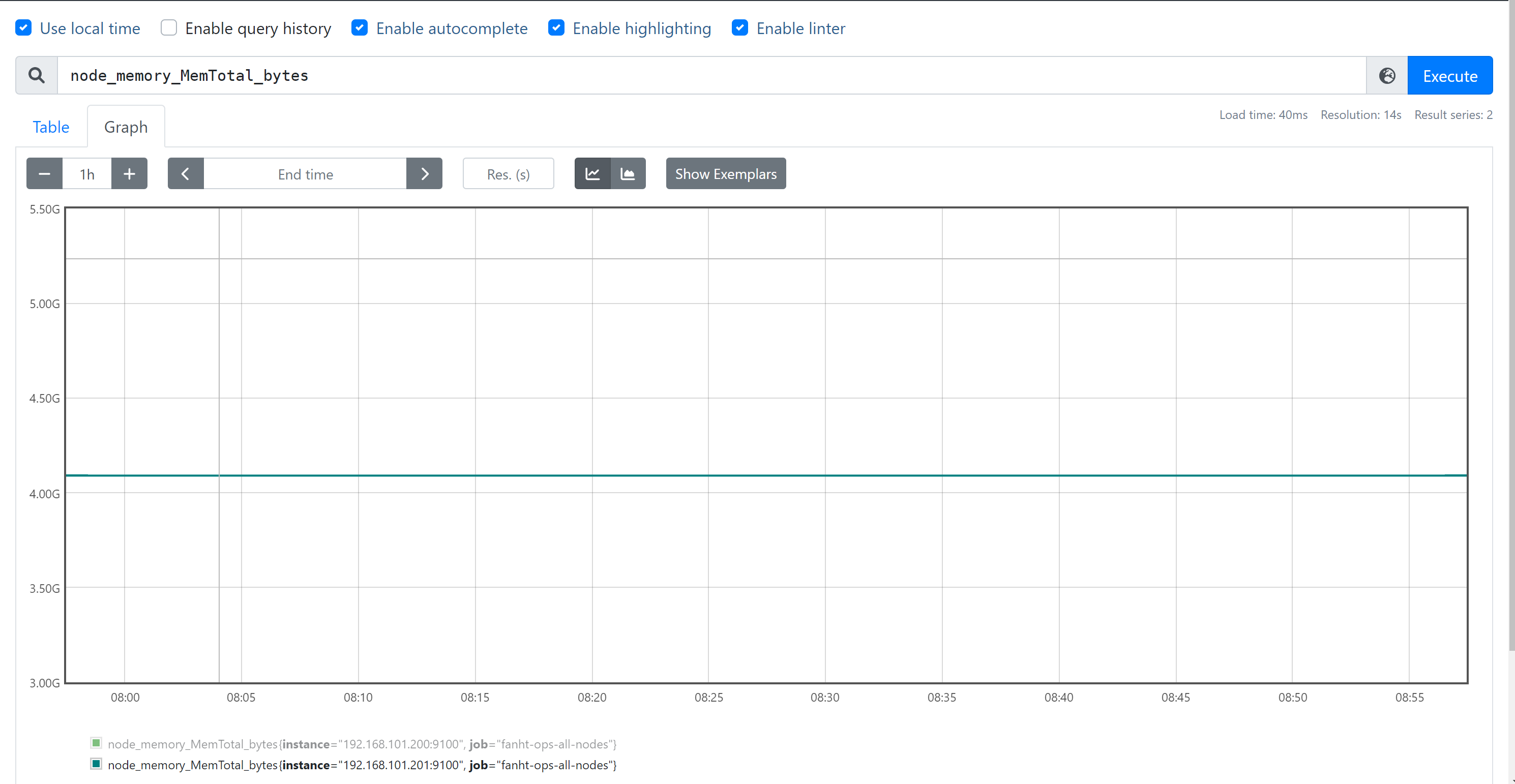
1、查看node节点总内存
node_memory_MemTotal_bytes
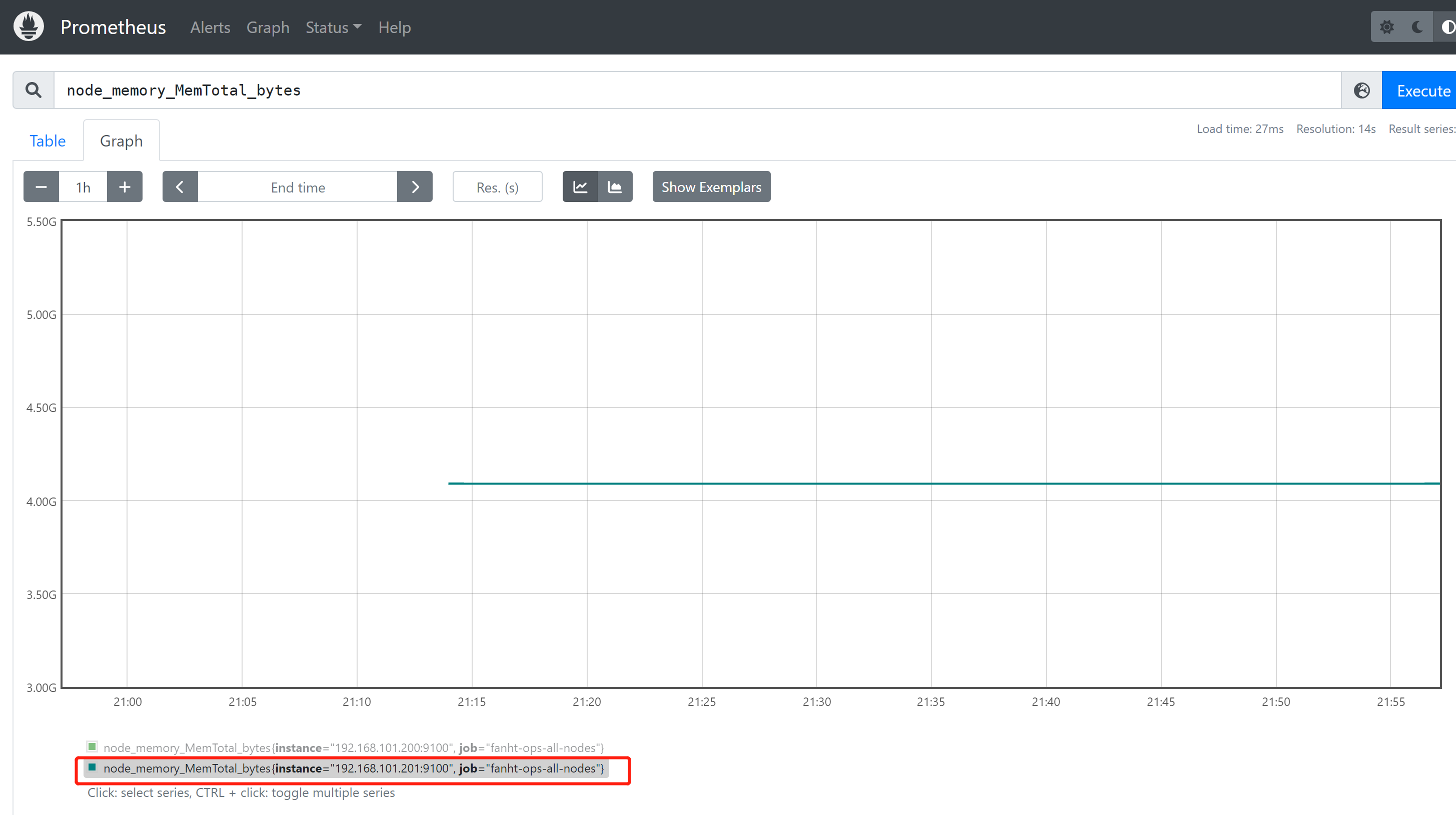
Node节点验证内存
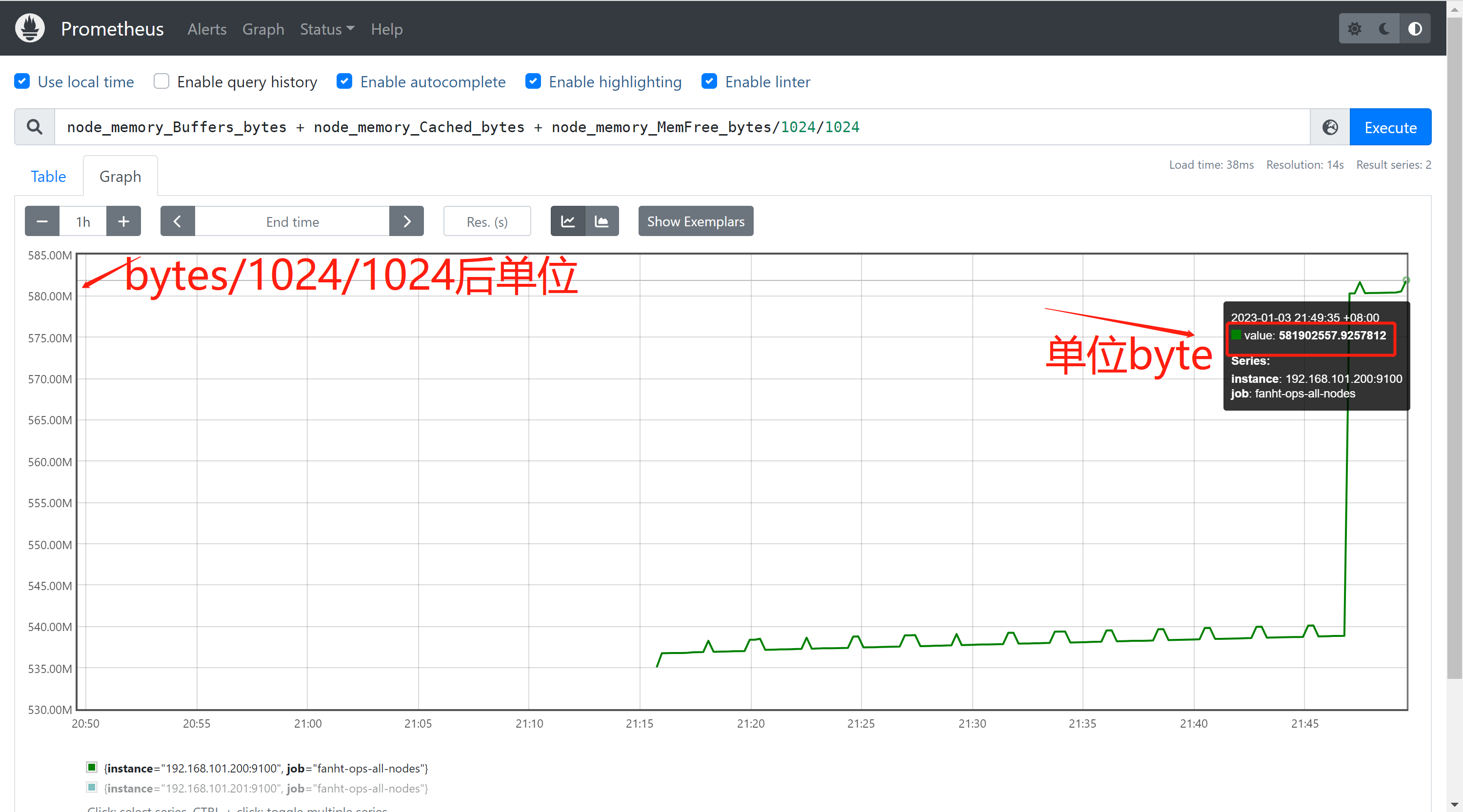
2、统计server可用内存
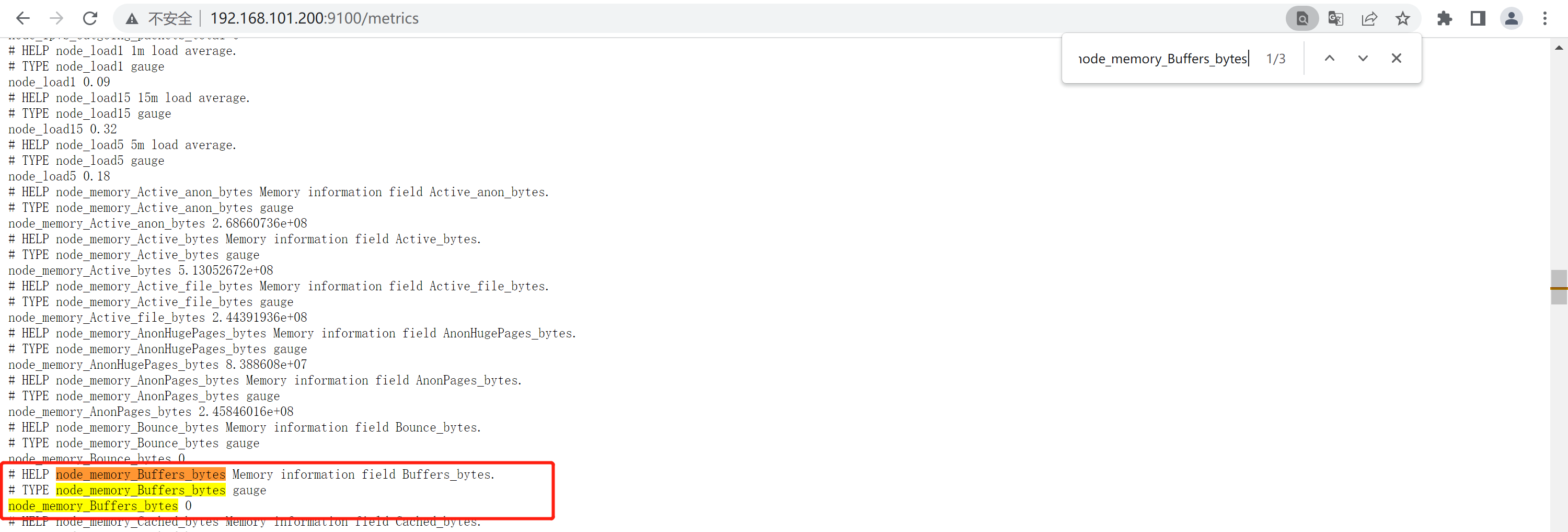
available = free + buffer + cache
node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes/1024/1024
linux查看内存剩余情况

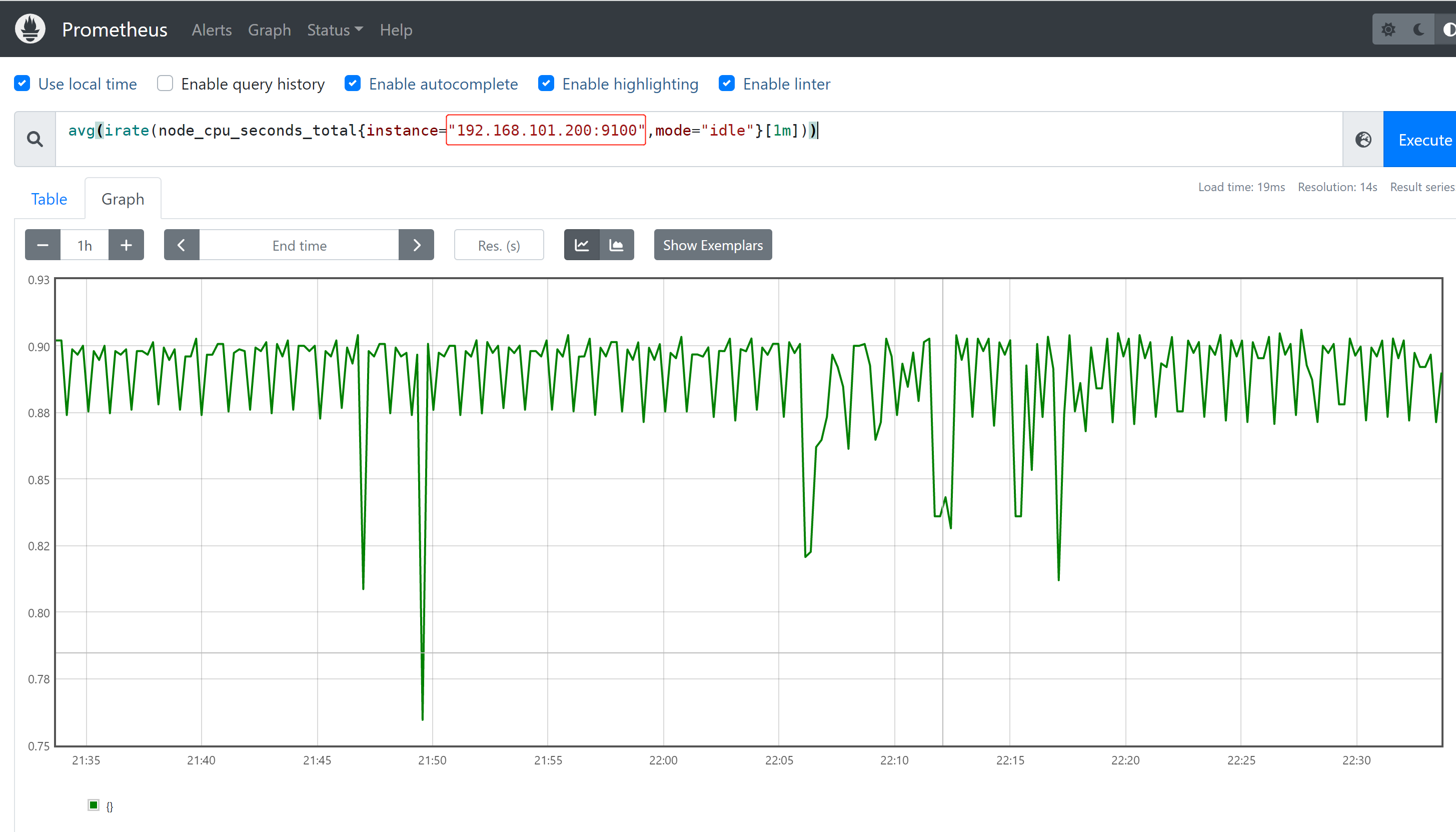
2、查看server节点的cpu使用率
avg(irate(node_cpu_seconds_total{instance="192.168.101.200:9100",mode="idle"}[1m]))
4.4.2、node_exporter 体验总结
prometheus前端使用PromQL语法,跟mysql 语句类似。后面使用Grafana模板呈现出来各种炫酷的图表底层还是通过语句各种查询拼凑,如果碰到定制化需求还是要自己会写查询语句。
三、PromQL深入使用
纯理论多些,枯燥,还得继续难受一下
prometheus核心功能已经体验,会用prometheus各种数据查询语法。
1、 PromQL数据基础
1.1、数据分类
1、瞬时向量
瞬时数据(instant vector):是⼀组时间序列,每个时间序列包含单个数据样本,⽐如 node_memory_MemFree_bytes查询当前剩余内存就是⼀个瞬时向量,该表达式的返回值中只会包含该时 间序列中的最新的⼀个样本值,⽽相应的这样的表达式称之为瞬时向量表达式,例如:例如: prometheus_http_requests_total
2、范围向量
范围数据(range vector):是指在任何⼀个时间范围内,抓取的所有度量指标数据.⽐如最近⼀ 天的⽹卡流量趋势图, 例如:prometheus_http_requests_total[5m]
3、标量
纯量数据(scalar):是⼀个浮点数类型的数据值,使⽤node_load1获取到时⼀个瞬时向量,但是 可⽤使⽤内置函数scalar()将瞬时向量转换为标量,例如:scalar(sum(node_load1)) 字符串(string):简单的字符串类型的数据,⽬前未使⽤,(a simple string value; currently unused)。
1.2、 数据类型
1.2.1、 Counter(计数器)
使用频次非常高
计数器,Counter类型代表⼀个累积的指标数据,在没有被重置的前提下只增不减,⽐如磁盘I/O 总数、nginx的请求总数、⽹卡流经的报⽂总数等
prometheus_http_requests_total
统计/metric 正常访问次数,数据只增不减

1.2.2、 Gauge(仪表盘)
使用频次非常高
Gauge类型代表⼀个可以任意变化的指标数据,值可以随时增⾼或减少,如带宽速录、 CPU负载、内存利⽤率、nginx 活动连接数等。
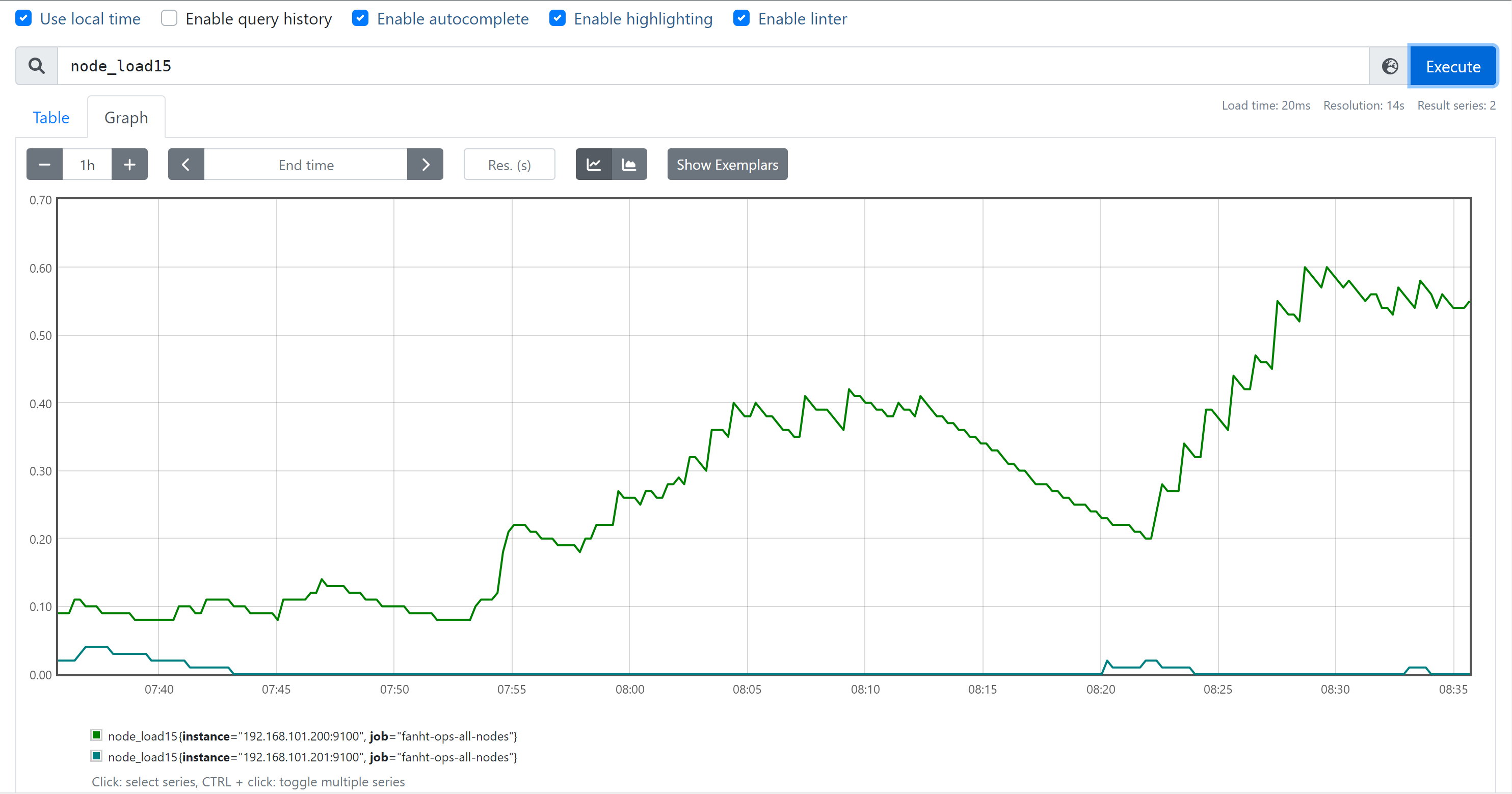
1.2.3、 Histogram 直方数据
绘制热点图搭配Histogram使用
指标生成的是直方数据,Prometheus抓取间隔的百分位数指标
Histogram会在⼀段时间范围内对数据进⾏采样(通常是请求持续时间或响应⼤ ⼩等),假如每分钟产⽣⼀个当前的活跃连接数,那么⼀天就会产⽣1440个数据,查看数据的每间隔的绘图跨 度为2⼩时,那么2点的柱状图(bucket)会包含0点到2点即两个⼩时的数据,⽽4点的柱状图(bucket)则会 包含0点到4点的数据,⽽6点的柱状图(bucket)则会包含0点到6点的数据。
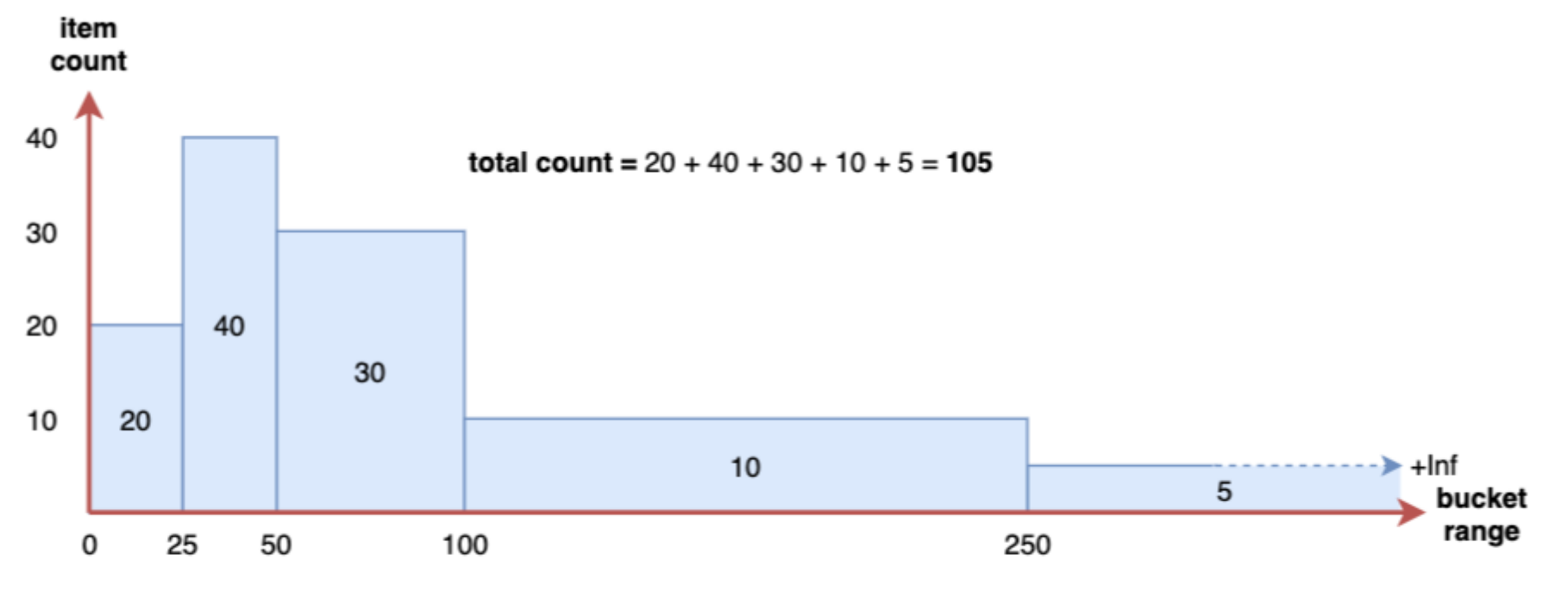
1.2.4、 Summary 摘要
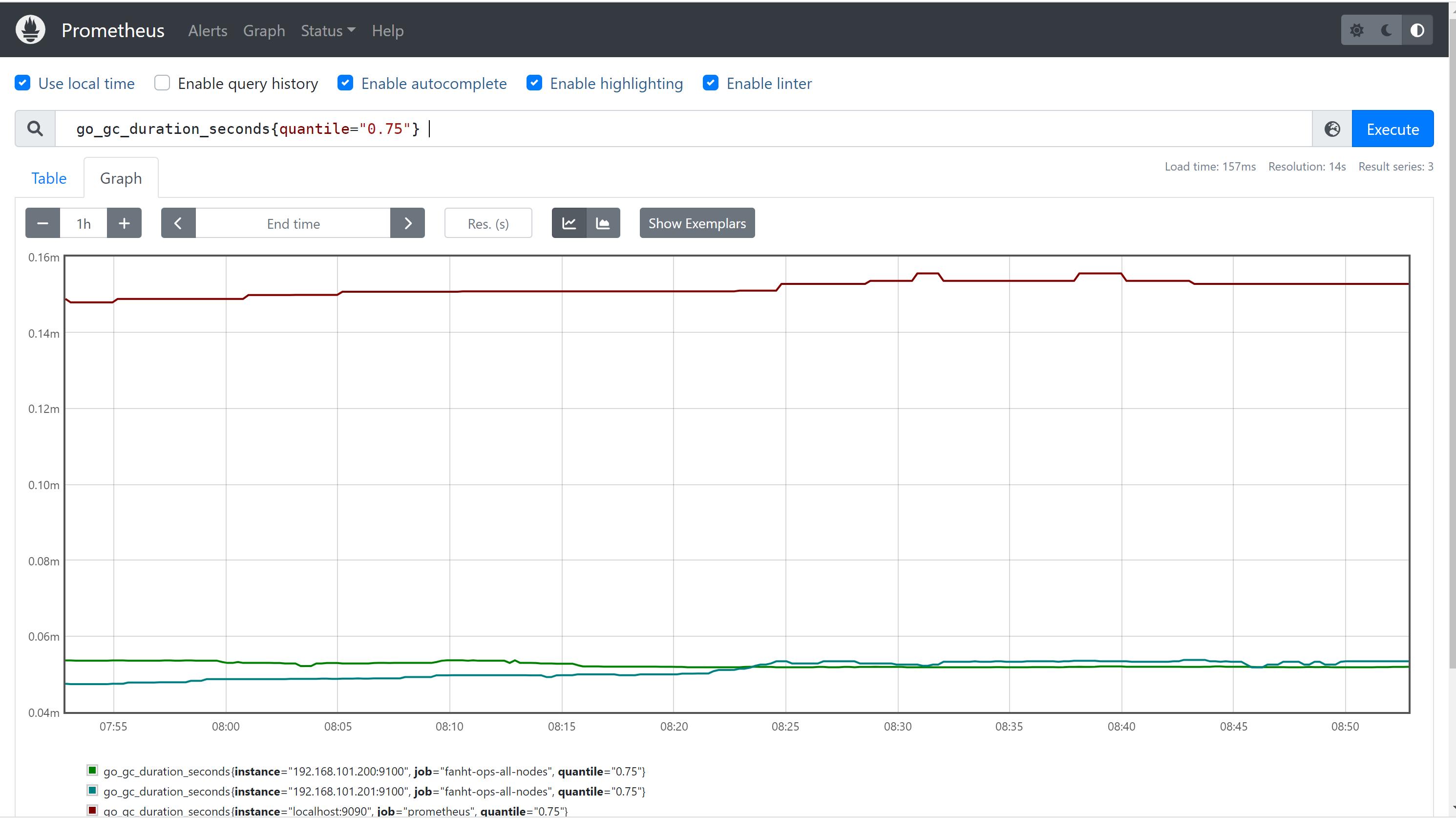
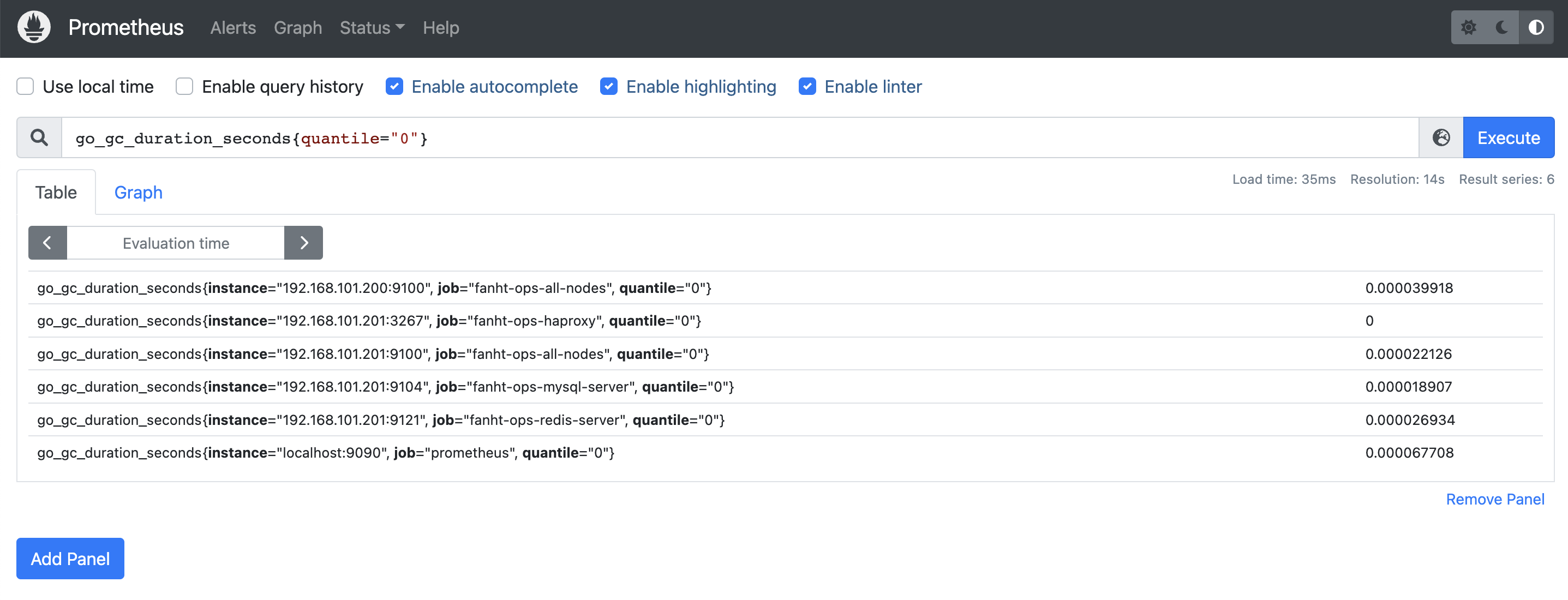
摘要,也是⼀组数据,统计的不是区间的个数⽽是统计分位数,从0到1,表示是0%~100%,如下 统计的是 0、0.25、0.5、0.75、1的数据量分别是多少
go_gc_duration_seconds
go_gc_duration_seconds{quantile="0"}
go_gc_duration_seconds{quantile="0"}
go_gc_duration_seconds{quantile="0.25"}
go_gc_duration_seconds{quantile="0.5"}
go_gc_duration_seconds{quantile="0.75"} #百分之75的
go_gc_duration_seconds的持续时间
go_gc_duration_seconds{quantile="1"}
go_gc_duration_seconds_sum 1.446781088
go_gc_duration_seconds_count 7830
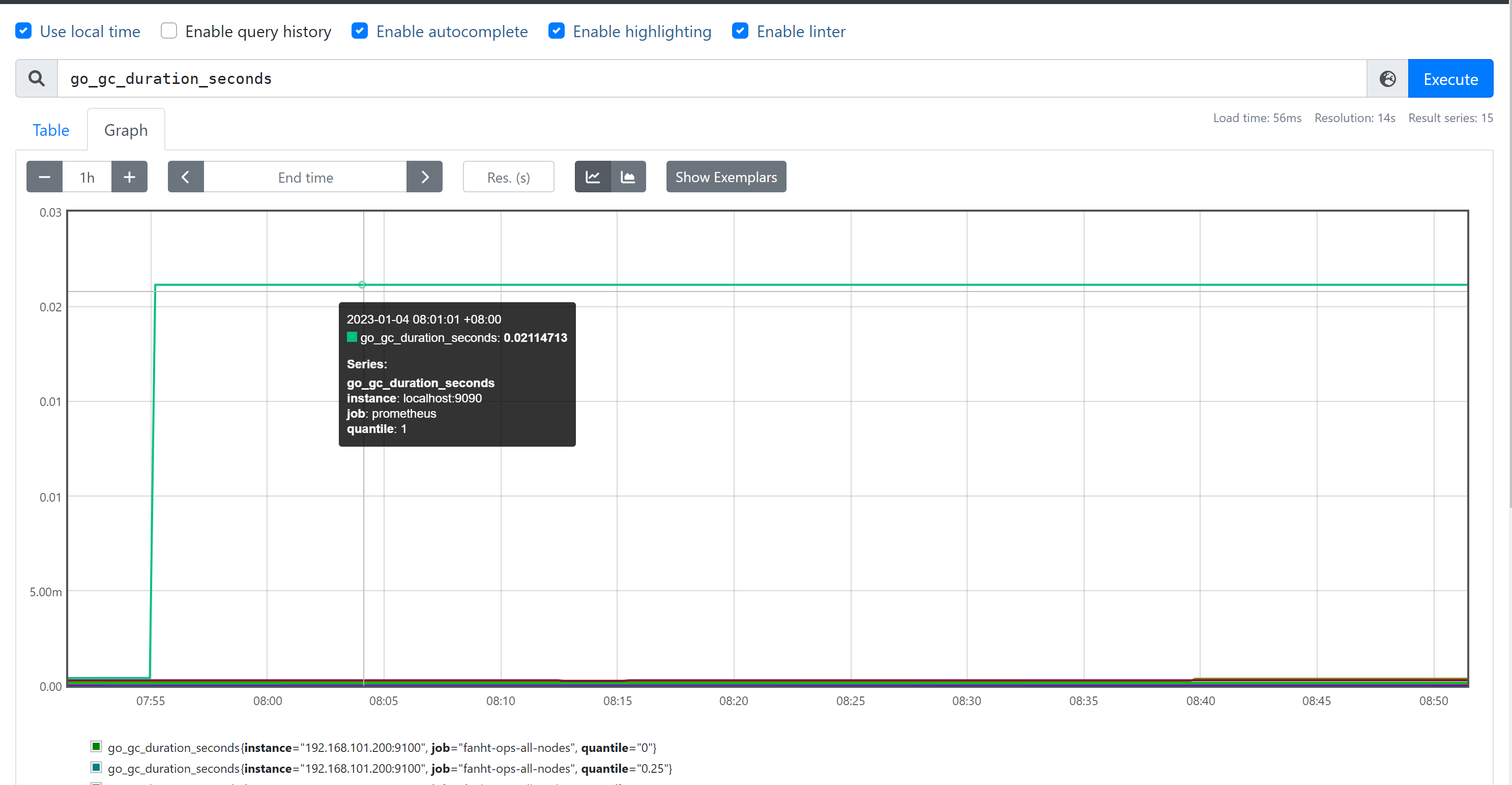
2、PromQL-指标数据
node_memory_MemTotal_bytes #查询node节点总内存⼤⼩
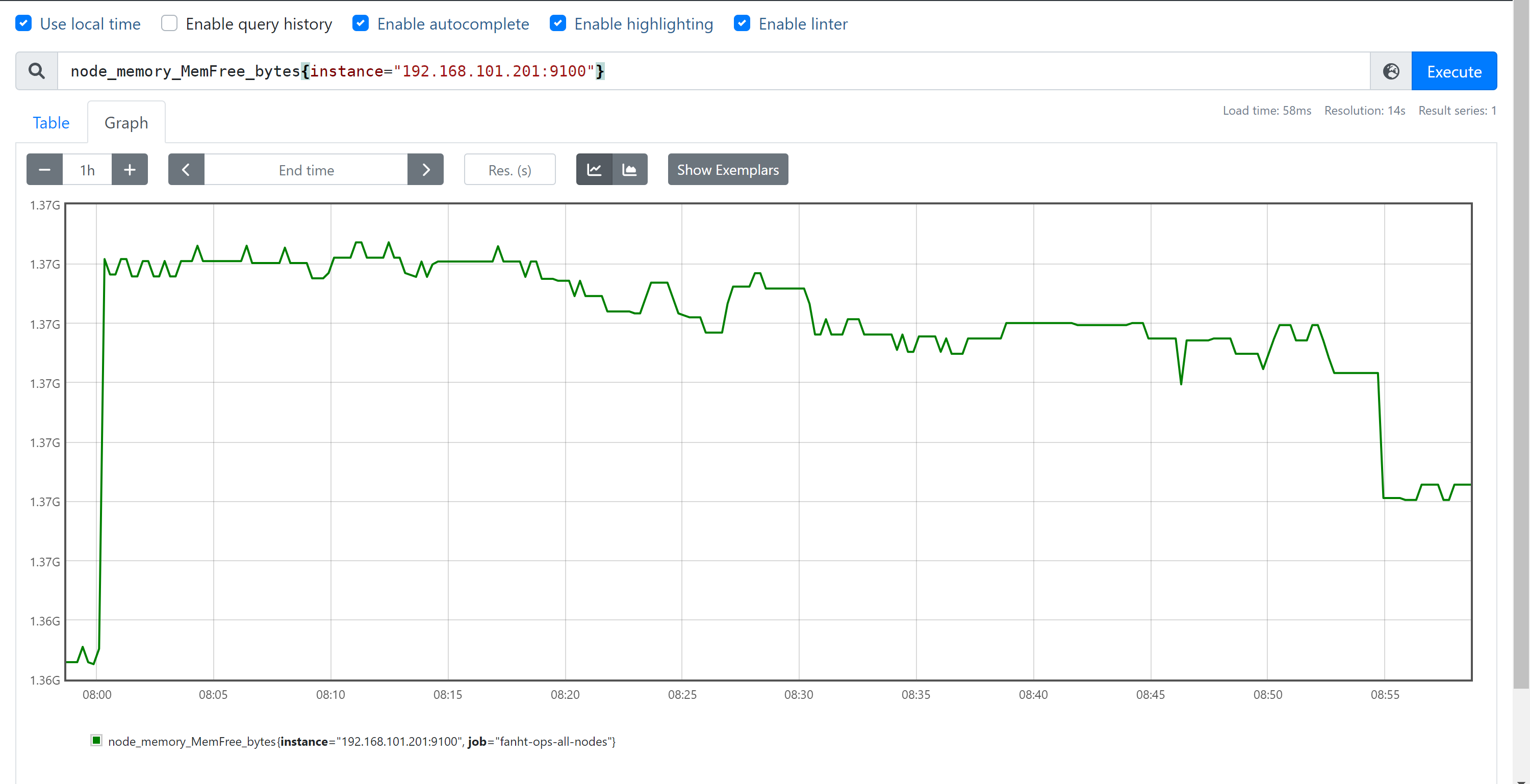
node_memory_MemFree_bytes #查询node节点剩余可⽤内存
node_memory_MemTotal_bytes{instance="192.168.101.200:9100"} #基于标签查询指定节点的总
内存
node_memory_MemFree_bytes{instance="192.168.101.201:9100"} #基于标签查询指定节点的可⽤
内存
node_disk_io_time_seconds_total{device="sda"} #查询指定磁盘的每秒磁盘io
node_filesystem_free_bytes{device="/dev/sda1",fstype="xfs",mountpoint="/"} #查看
指定磁盘的磁盘剩余空间
# HELP node_load1 1m load average. #CPU负载
# TYPE node_load1 gauge
node_load1
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5
截部分图片
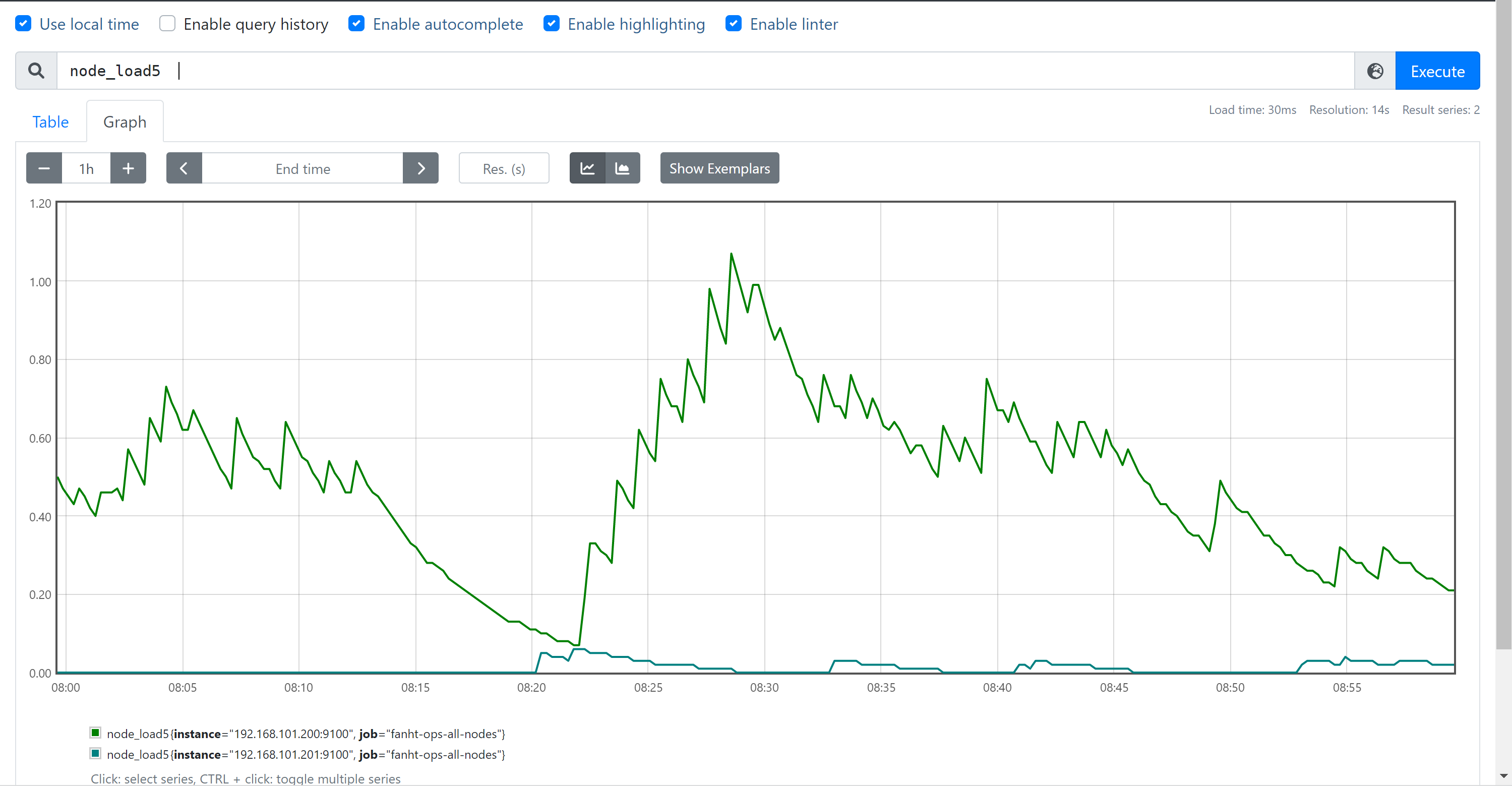
3、 PromQL-匹配器
= :选择与提供的字符串完全相同的标签,精确匹配。
!= :选择与提供的字符串不相同的标签,去反。
=~ :选择正则表达式与提供的字符串(或⼦字符串)相匹配的标签。
!~ :选择正则表达式与提供的字符串(或⼦字符串)不匹配的标签。
3.1.1、 查询格式
查询格式<metric name>{<label name>=<label value>,...}
node_load1{instance="192.168.101.200:9100"} node_load1{job="fanht-ops-all-nodes"}
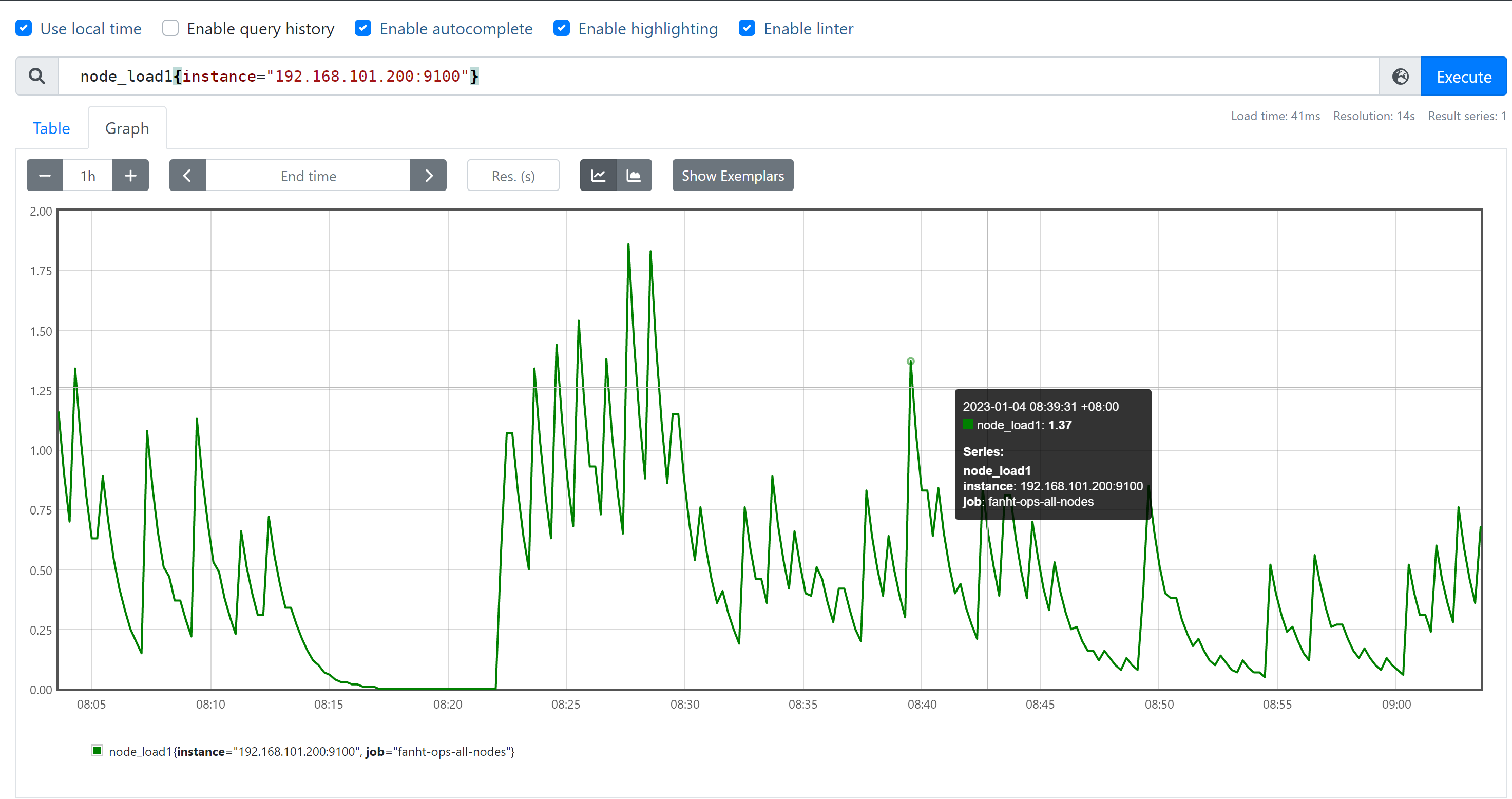
node_load1{job="promethues-node",instance="192.168.101.200:9100"} #精确匹配 node_load1{job="promethues-node",instance!="192.168.101.200:9100"} #取反 node_load1{instance=~"192.168.101.*:9100$"} #包含正则且匹配
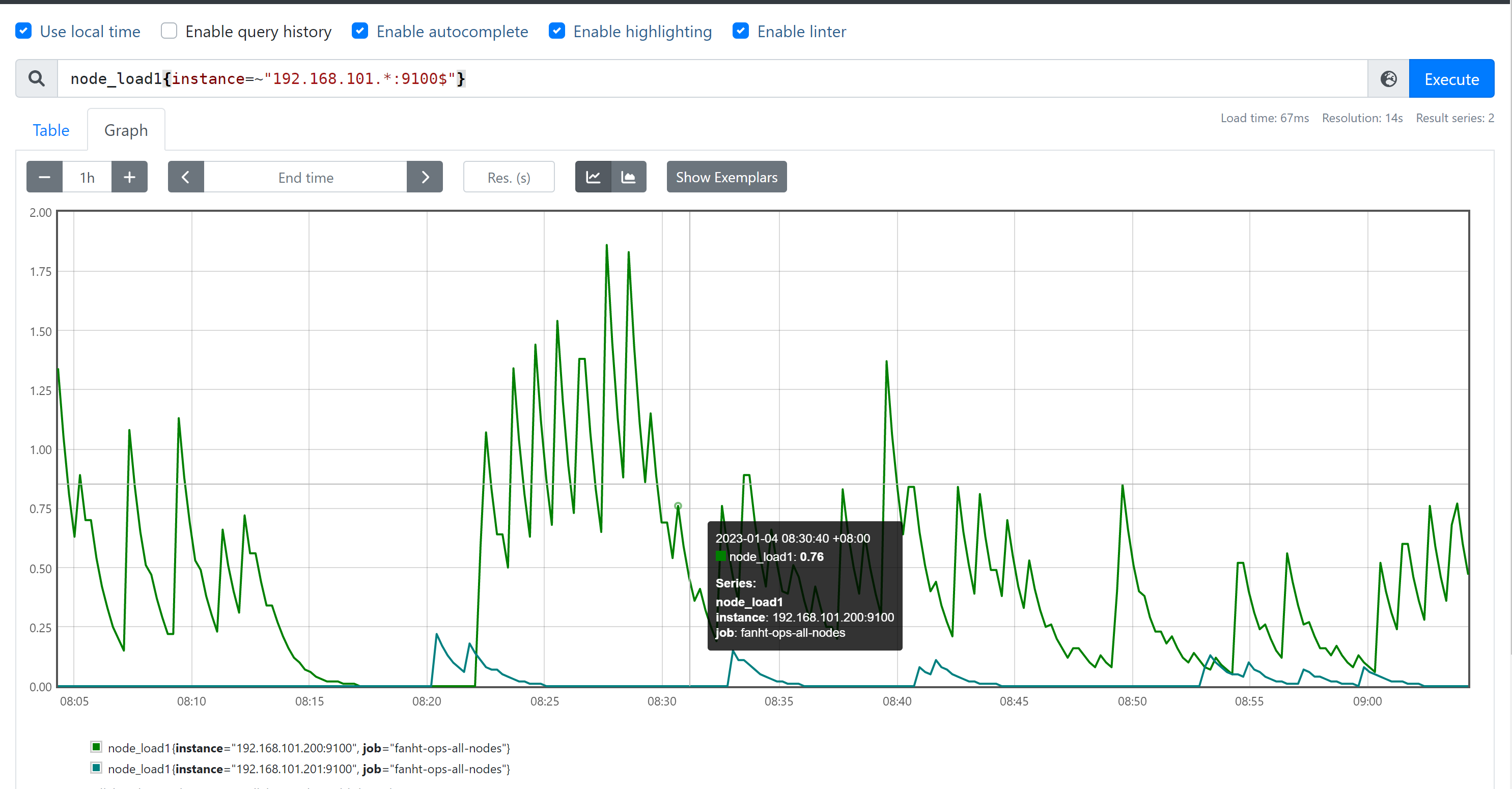
#包含正则且取反
node_load1{instance!~"192.168.101.200:9100"}
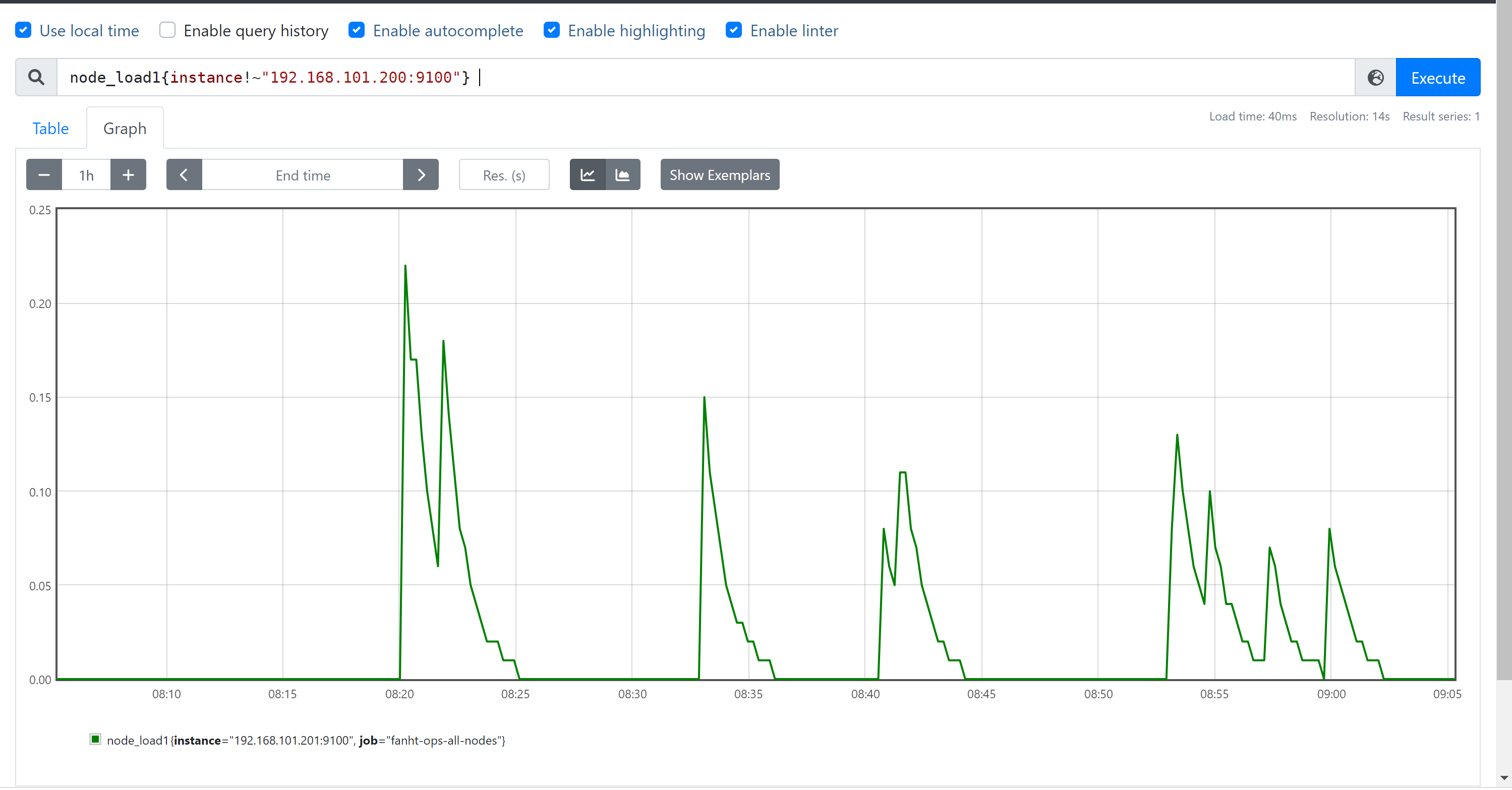
4、PromQL-时间范围
s - 秒 m - 分钟 h - ⼩时 d - 天 w - 周 y - 年
#瞬时向量表达式,选择当前最新的数据
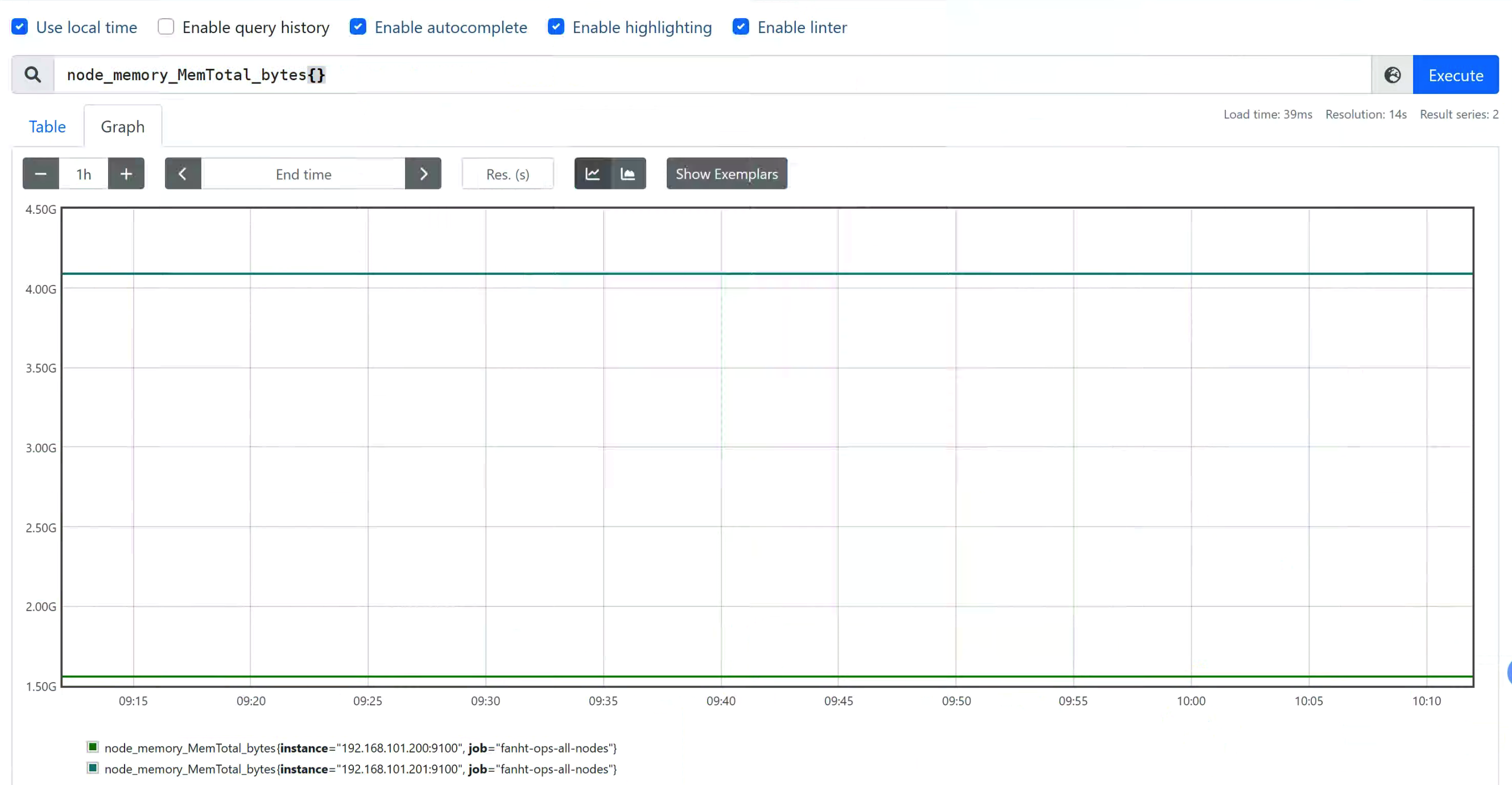
node_memory_MemTotal_bytes{}
#区间向量表达式,选择以当前时间为基准,查询所有节点
node_memory_MemTotal_bytes指标5分钟内 的数据
node_memory_MemTotal_bytes{}[5m]
#区间向量表达式,选择以当前时间为基准,查询指定节点
node_memory_MemTotal_bytes
指标5分钟内 的数据
node_memory_MemTotal_bytes{instance="192.168.101.200:9100"} [5m]
4.1、演示部分截
5、PromQL-运算符
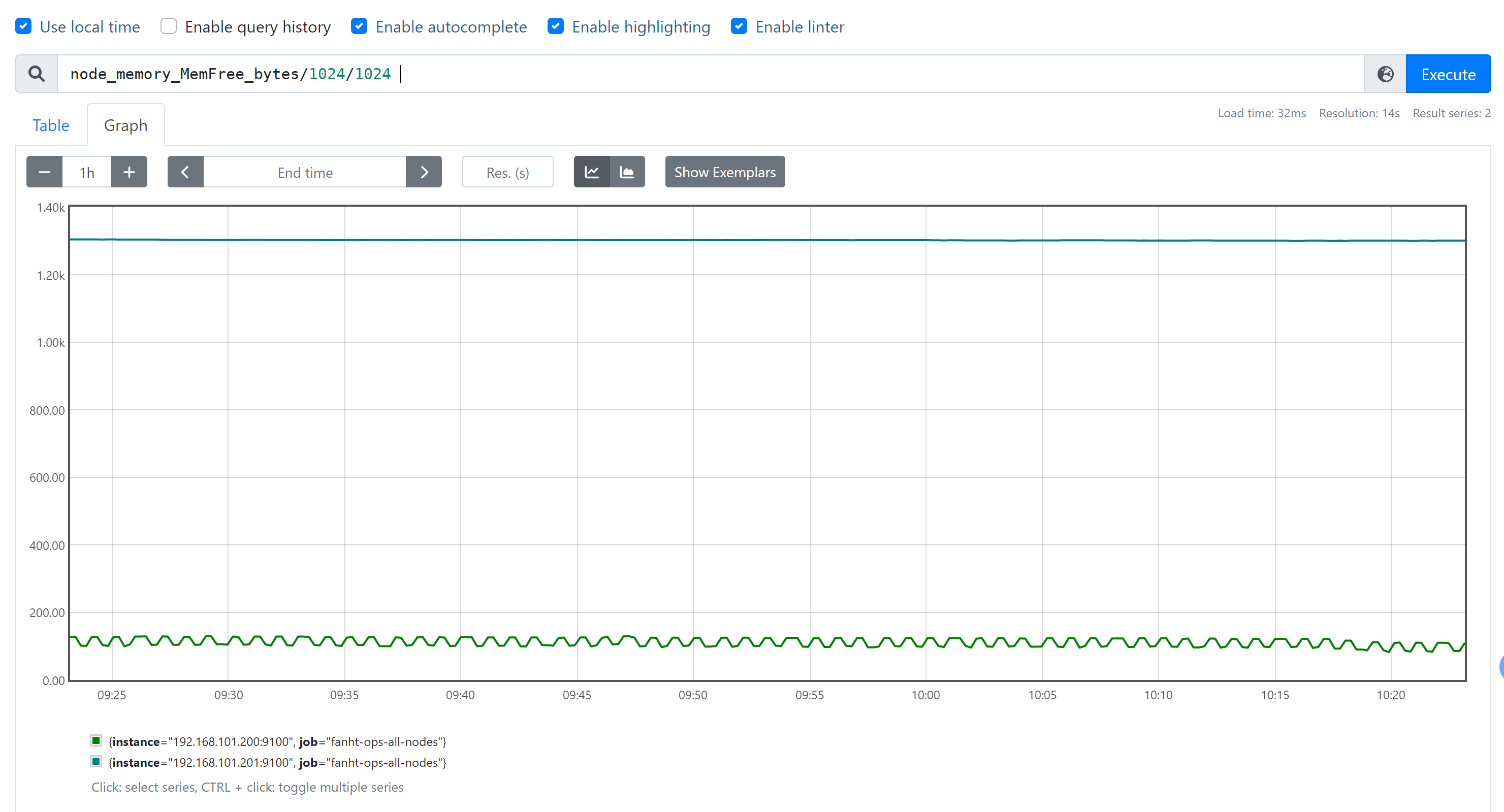
+ 加法 - 减法 * 乘法 / 除法 % 模 ^ 幂等
node_memory_MemFree_bytes/1024/1024 #将内存进⾏单位从字节转⾏为兆 node_disk_read_bytes_total{device="sda"} + node_disk_written_bytes_total{device="sda"} #计算磁盘读写数据量
6、PromQL-聚合运算
6.1、max、min、avg
max() #最⼤值
min() #最⼩值
avg() #平均值
计算每个节点的最⼤的流量值: max(node_network_receive_bytes_total) by (instance) 计算每个节点最近五分钟每个device的最⼤流量 max(rate(node_network_receive_bytes_total[5m])) by (device)
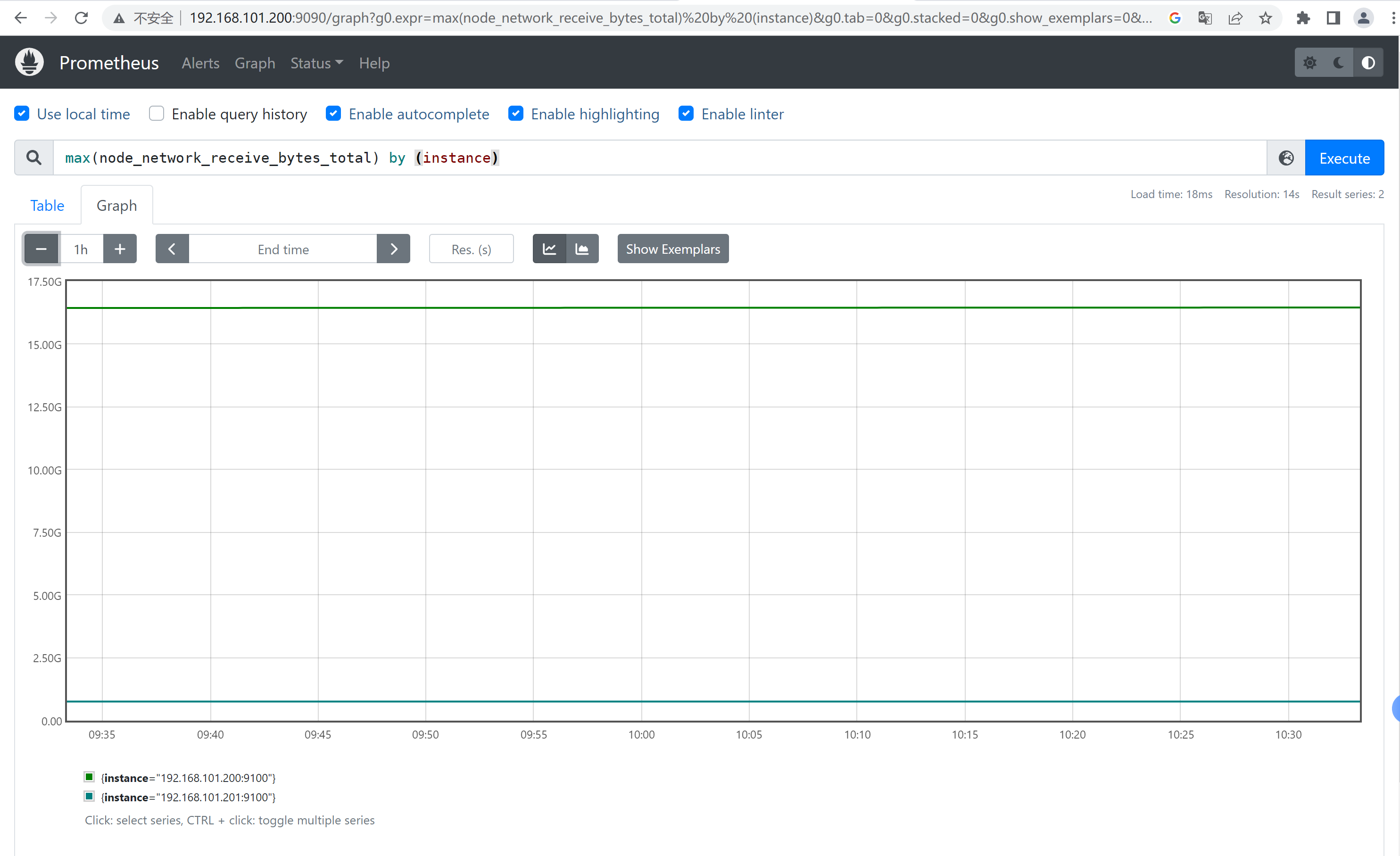
6.2、sum、count
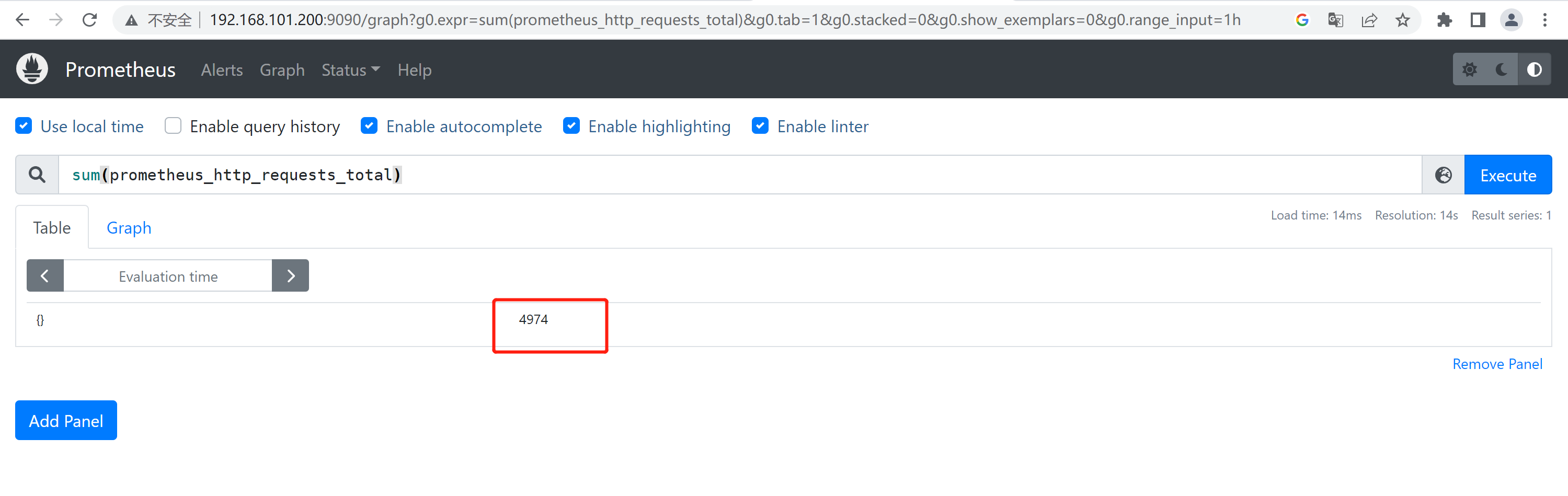
sum() #求数据值相加的和(总数)
sum(prometheus_http_requests_total) #最近总共请求数为4974次,⽤于计算返回值的总数(如http请求次数)
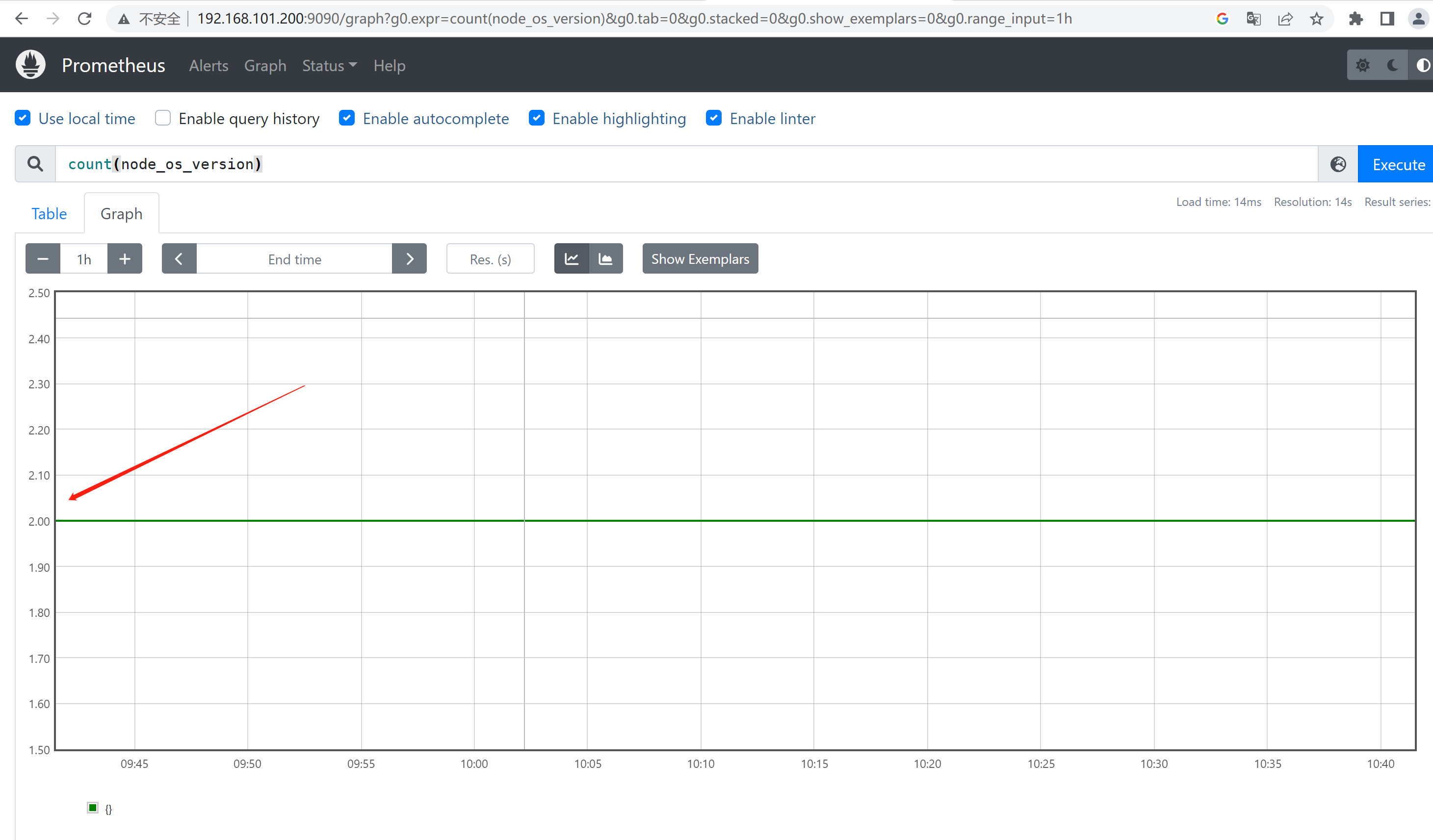
count() #统计返回值的条数
count(node_os_version) #⼀共两条返回的数据,可以⽤于统计节点数、Pod数量等 count_values() #对value的个数(⾏数)进⾏计数 count_values("node_version",node_os_version) #统计不同的系统版本节点有多少
6.3、abs、absent 补充图片
abs() #返回指标数据的值 abs(sum(prometheus_http_requests_total{handler="/metrics"}))
absent() #如果监指标有数据就返回空,如果监控项没有数据就返回1,可⽤于对监控项设置告警通知 absent(sum(prometheus_http_requests_total{handler="/metrics"}))
6.4、stddev、stdvar
stddev() #标准差
stddev(prometheus_http_requests_total) #5+5=10,1+9=10,1+9这⼀组的数据差异就⼤, 在系统是数据波动较⼤,不稳定 。
stdvar() #求⽅差
stdvar(prometheus_http_requests_total)
6.5、topk、bottomk
topk() #样本值排名最⼤的N个数据 #取从⼤到⼩的前6个
topk(6, prometheus_http_requests_total)
bottomk() #样本值排名最⼩的N个数据 #取从⼩到⼤的前6个
bottomk(6, prometheus_http_requests_total)
6.6、rate、irate
irate函数专门搭配counter数据类型使用的函数,irate获取的是指定时间范围内最近的两个数据来计算数据的差异,irate抖动更明显。
rate() #函数是专⻔搭配counter数据类型使⽤函数,功能是取counter数据类型在这个时间段中平均 每秒的增量平均数,适合⽤于计算数据相对平稳的数据。
rate(prometheus_http_requests_total[5m])
rate(node_network_receive_bytes_total[5m])
irate() #函数是专⻔搭配counter数据类型使⽤函数,irate获取的是指定时间范围内最近的两个数据 来计算数据的速率,适合计算数据变化⽐较⼤的数据,显示的数据相对⽐较准确。 irate(prometheus_http_requests_total[5m]) irate(node_network_receive_bytes_total[5m])
6.7、by、without
#by,在计算结果中,只保留by指定的标签的值,并移除其它所有的sum(rate(node_network_receive_packets_total{instance=~".*"}[10m])) by (instance)
sum(rate(node_memory_MemFree_bytes[5m])) by (increase)
#without,从计算结果中移除列举的instance,job标签,保留其它标签 sum(prometheus_http_requests_total) without (instance,job)
四、安装配置Grafana部署
在prometheus-server上部署Grafana
安装节点: 192.168.101.200
监听端口: 30000
计划第三部分写PromQL深入使用,prometheus各种数据查询语法必须要会的。又考虑到文章看了这么长还没见到好看的图表。
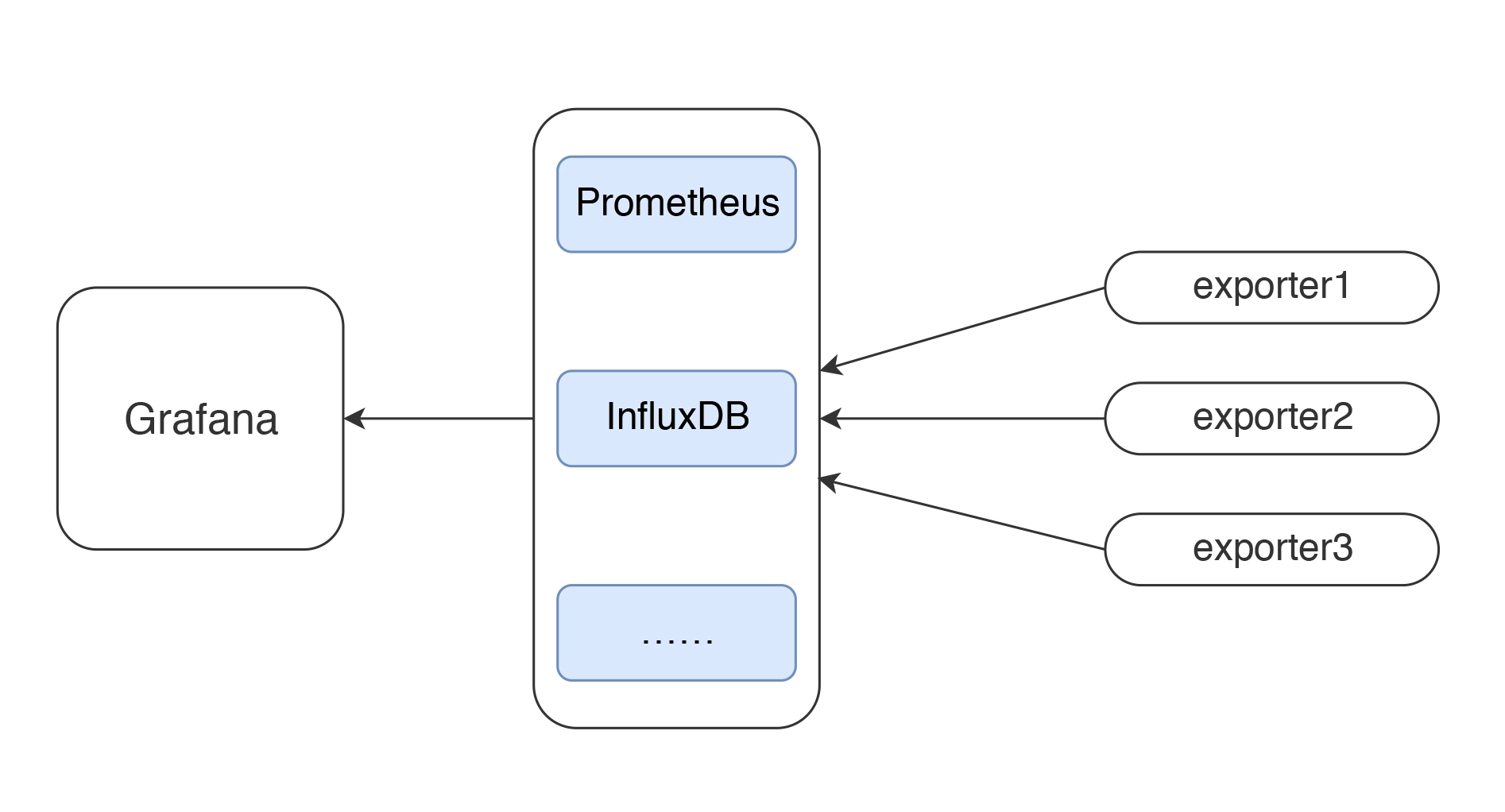
1、Grafana简介
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。(告警功能会通过其他组件对接prometheus完成)
2、二进制安装Grafana
2.1、常用地址
2、更多部署方式
4、更多版本选择
建议不要下载最新版本,否则会出现跟一些模板上的查询数据不兼容问题。
2.2、安装Grafana
2.2.1、yum 安装rpm包
机器有网直接把rpm包下载到本地,
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.0.4-1.x86_64.rpm sudo yum install grafana-enterprise-9.0.4-1.x86_64.rpm
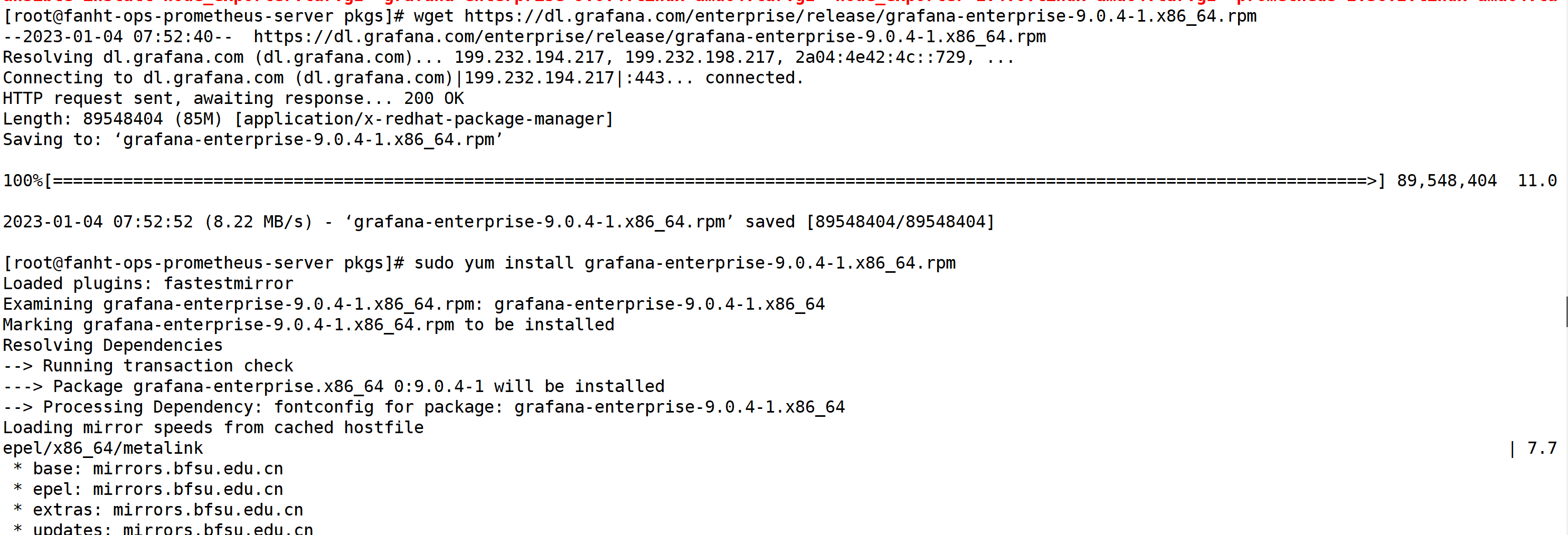
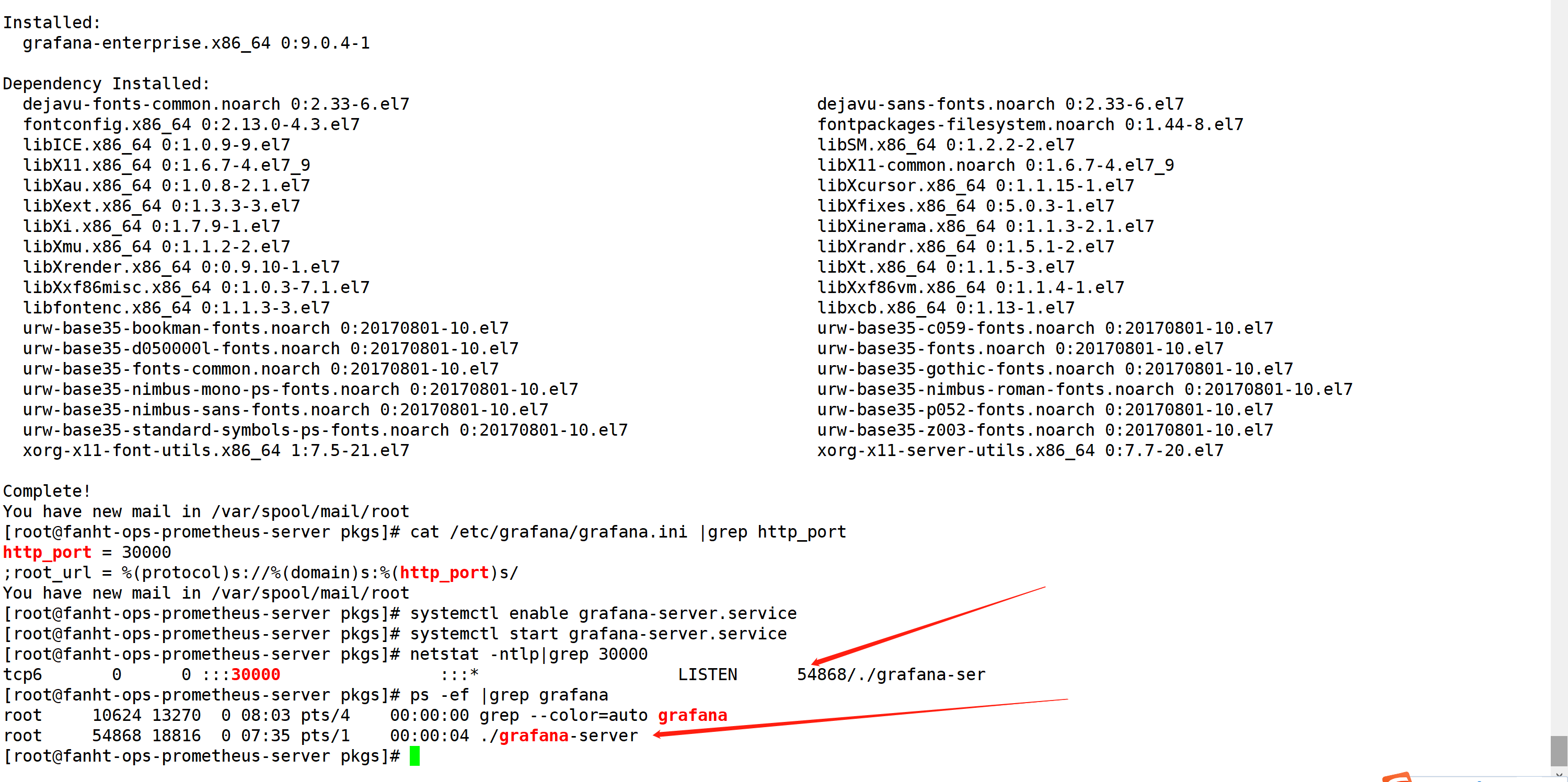
2.2.2、修改启动端口
cat /etc/grafana/grafana.ini |grep http_port systemctl enable grafana-server.service systemctl start grafana-server.service netstat -ntlp|grep 30000 ps -ef |grep grafana
2.4、Grafana访问并配置数据源
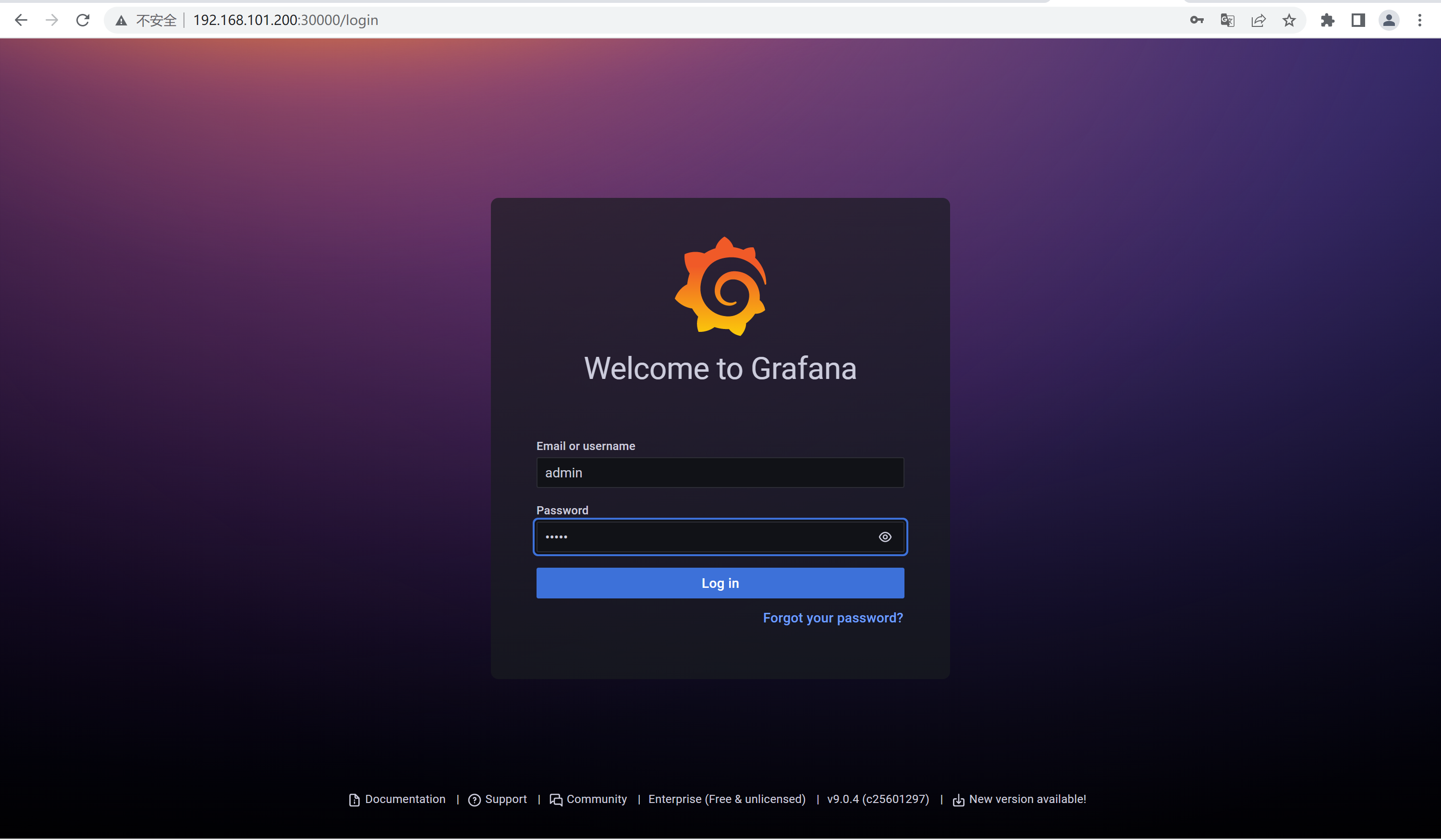
2.4.1、访问grafana前端
用户名admin
初始密码admin
http://192.168.101.200:30000/login
2.4.2、配置prometheus数据源
数据源选择prometheus
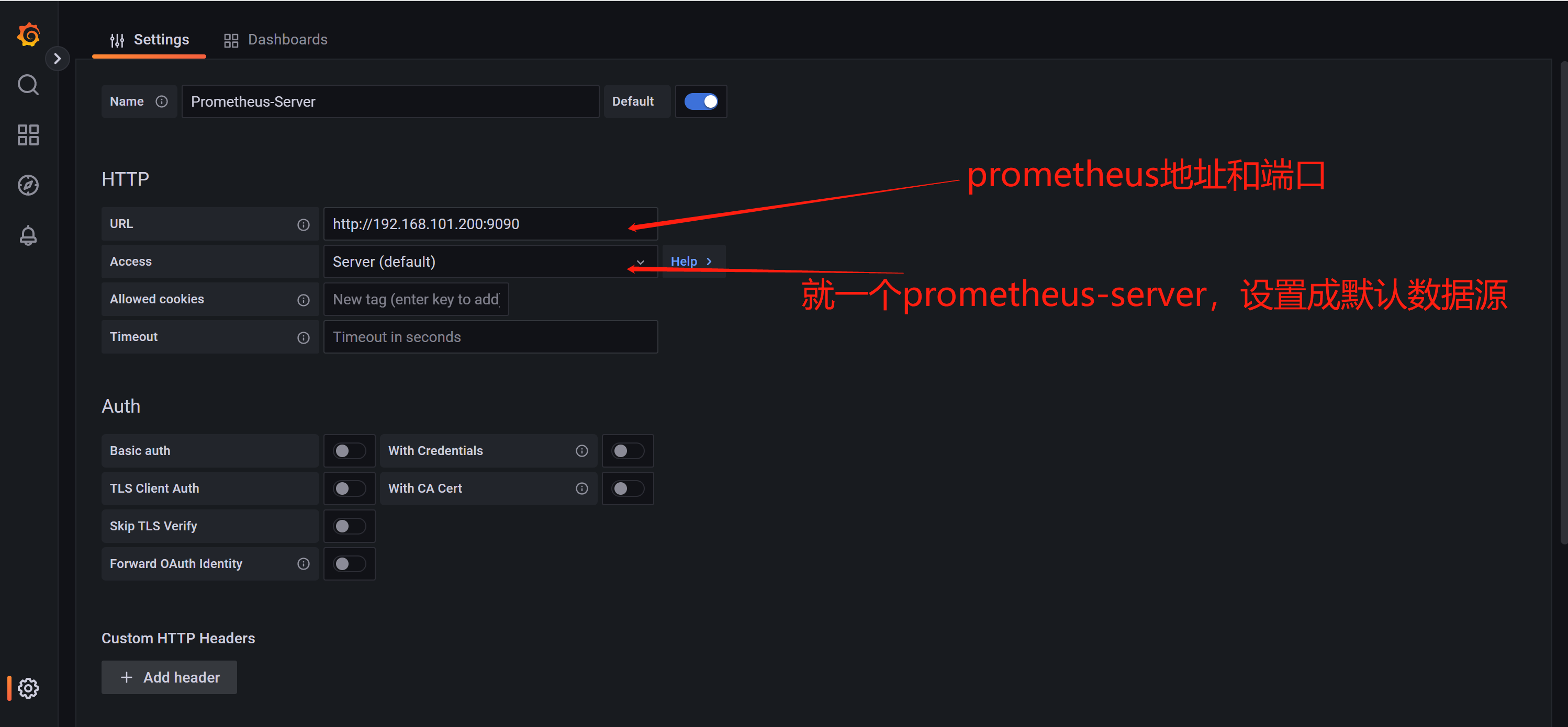
测试成功保存即可
3、使用Grafana模板
1、node_exporter模板
1.1、推荐模板ID
1860、15172(基于11074模板做的优化)
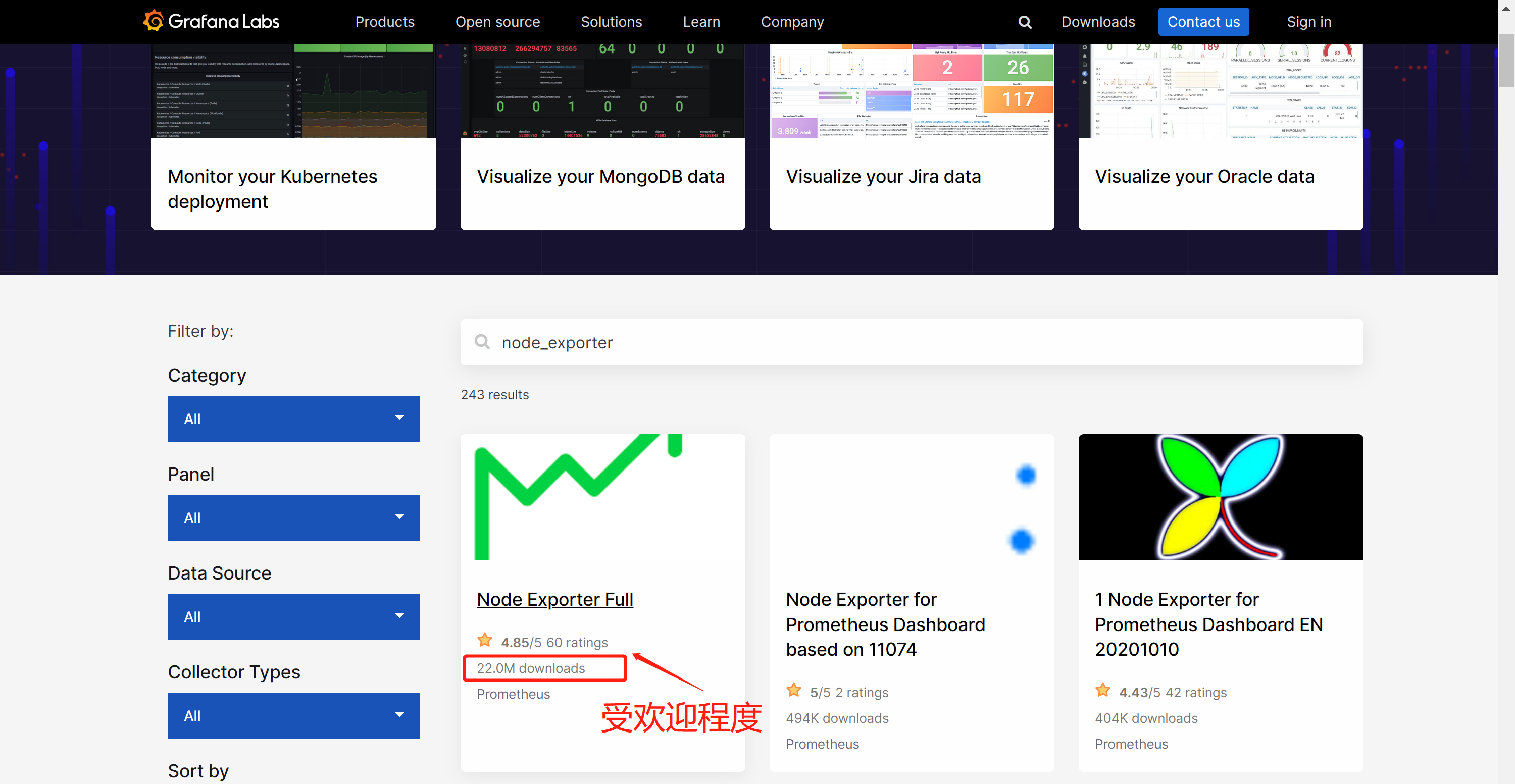
1.2、导入模板两种方法
import 模板ID需要机器能够上网,如果机器不能上网通过导入json文件完成
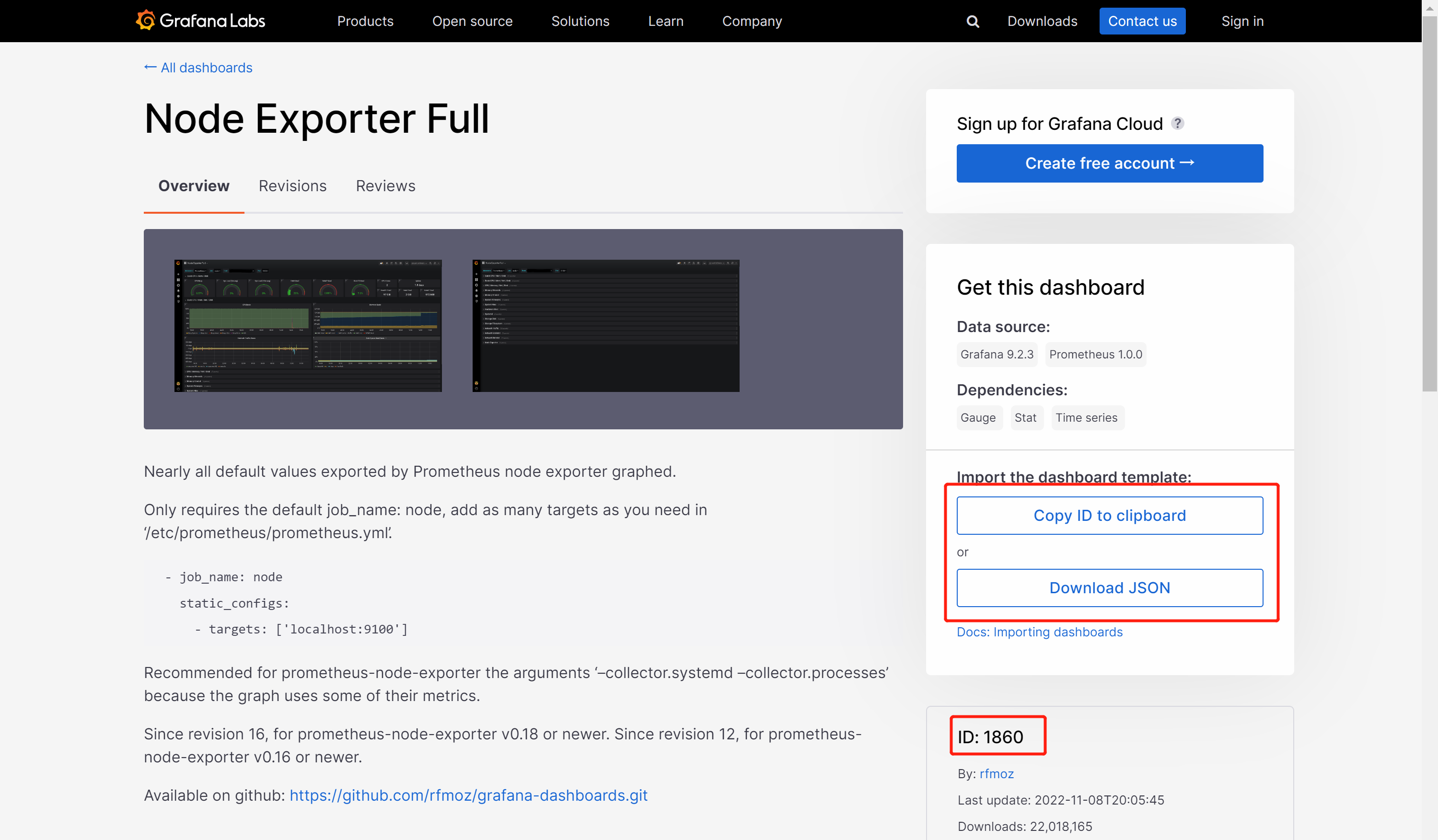
1.2.1、ID导入1860模板
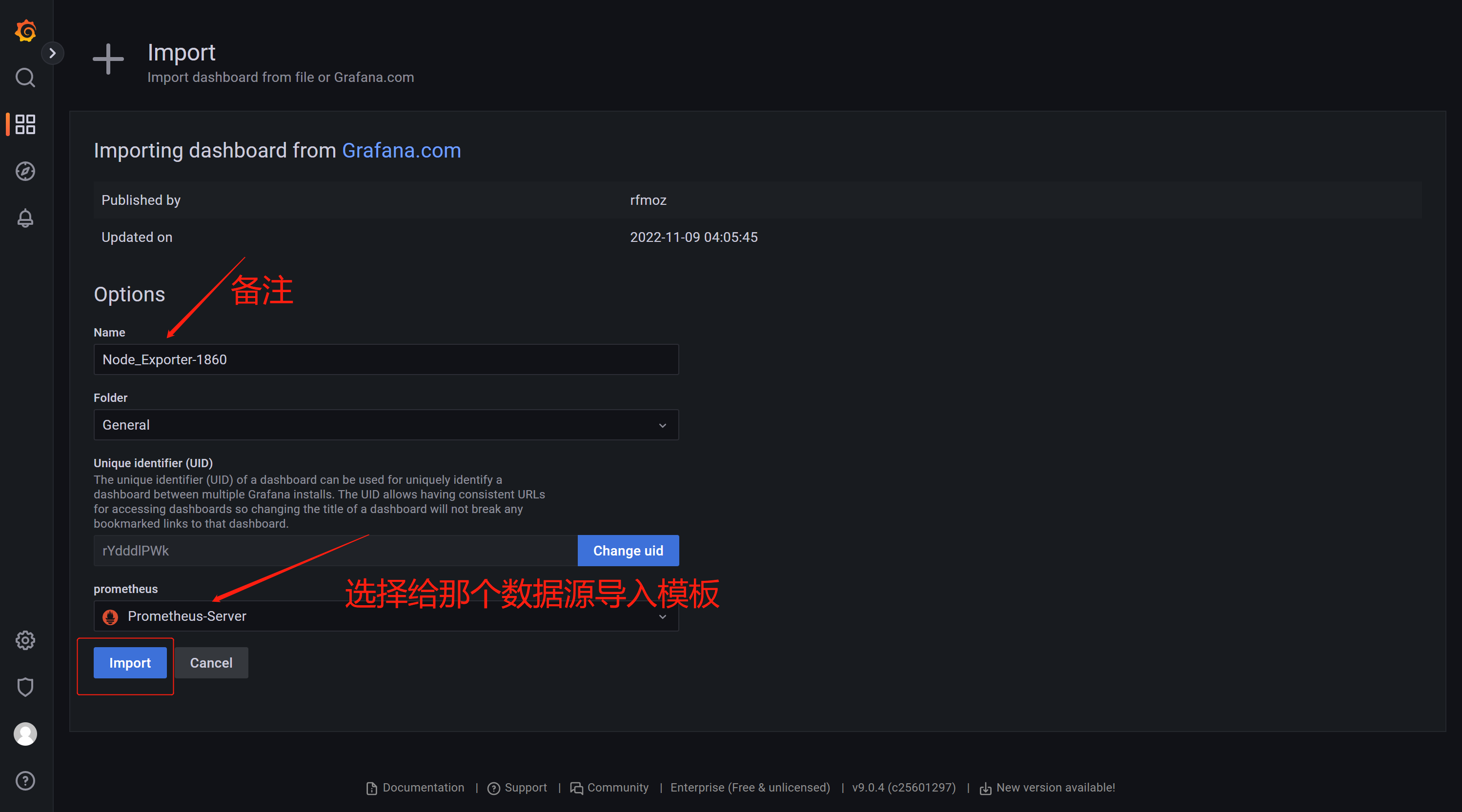
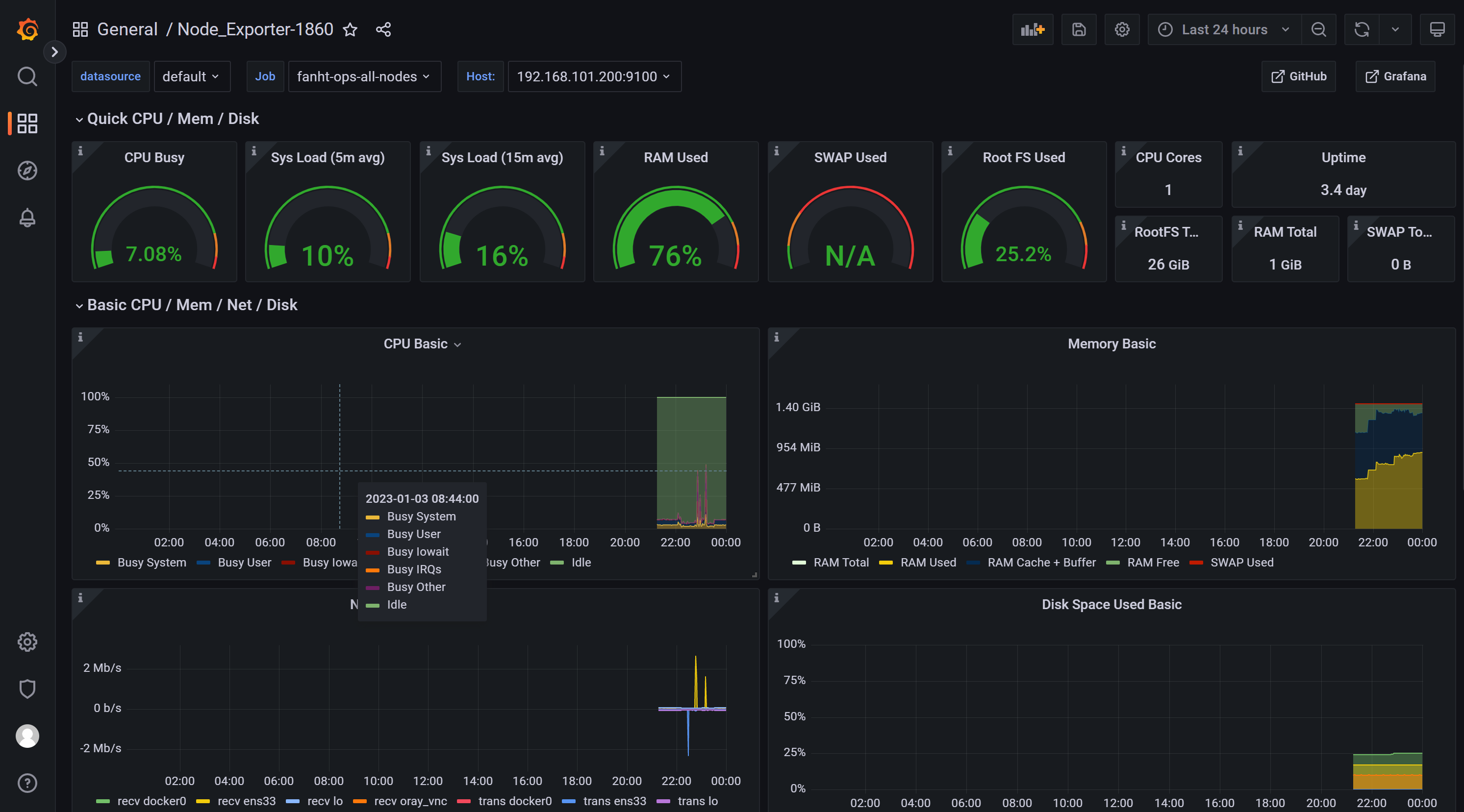
1.2.2、Json文件上传11074模板
导入下载好的json文件
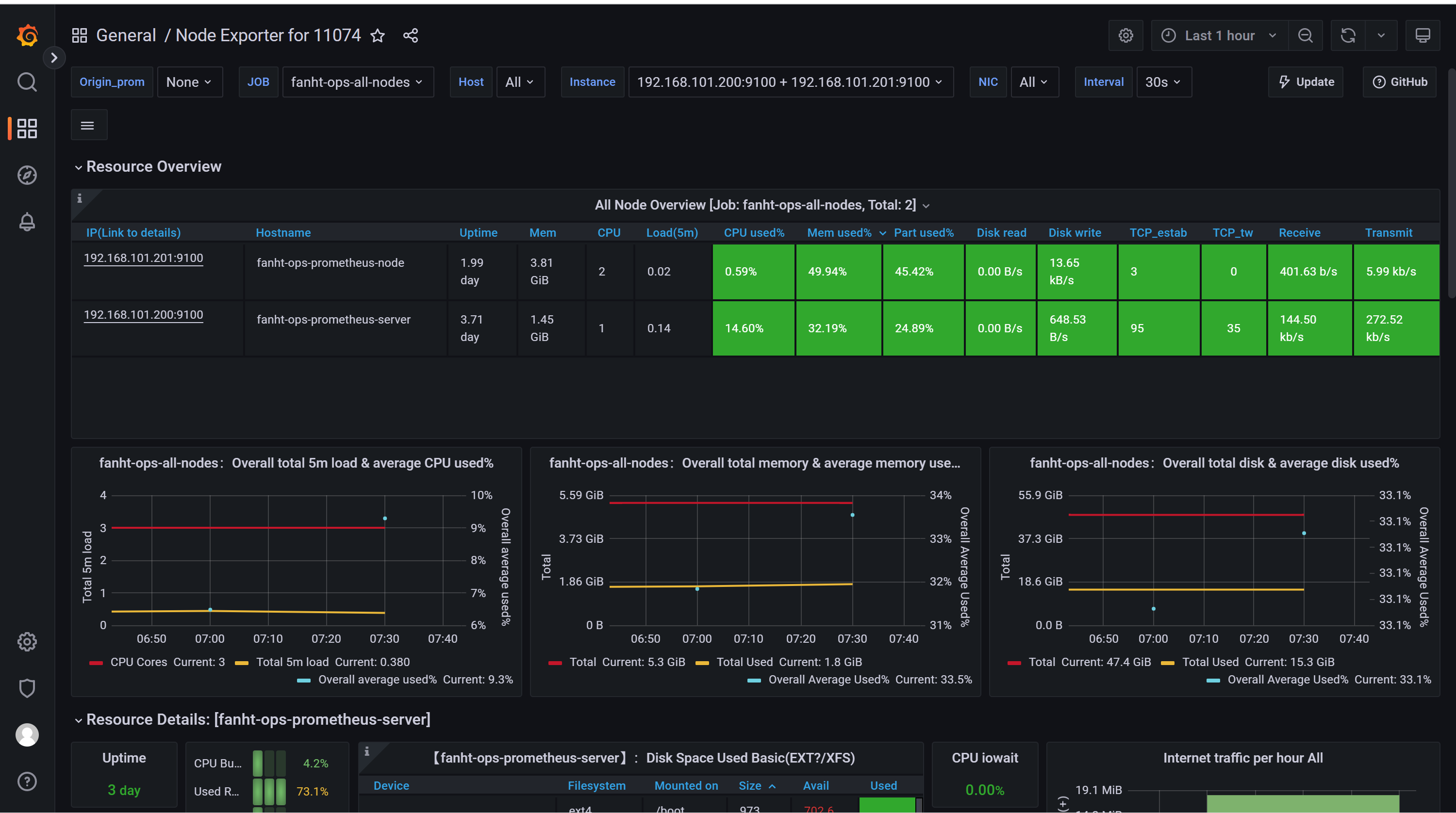
2、生产模版ID汇总-待补充
2.1、xxx监控使用模版ID
2.2、xxx监控使用模版ID
4、插件管理
缺少饼图插件
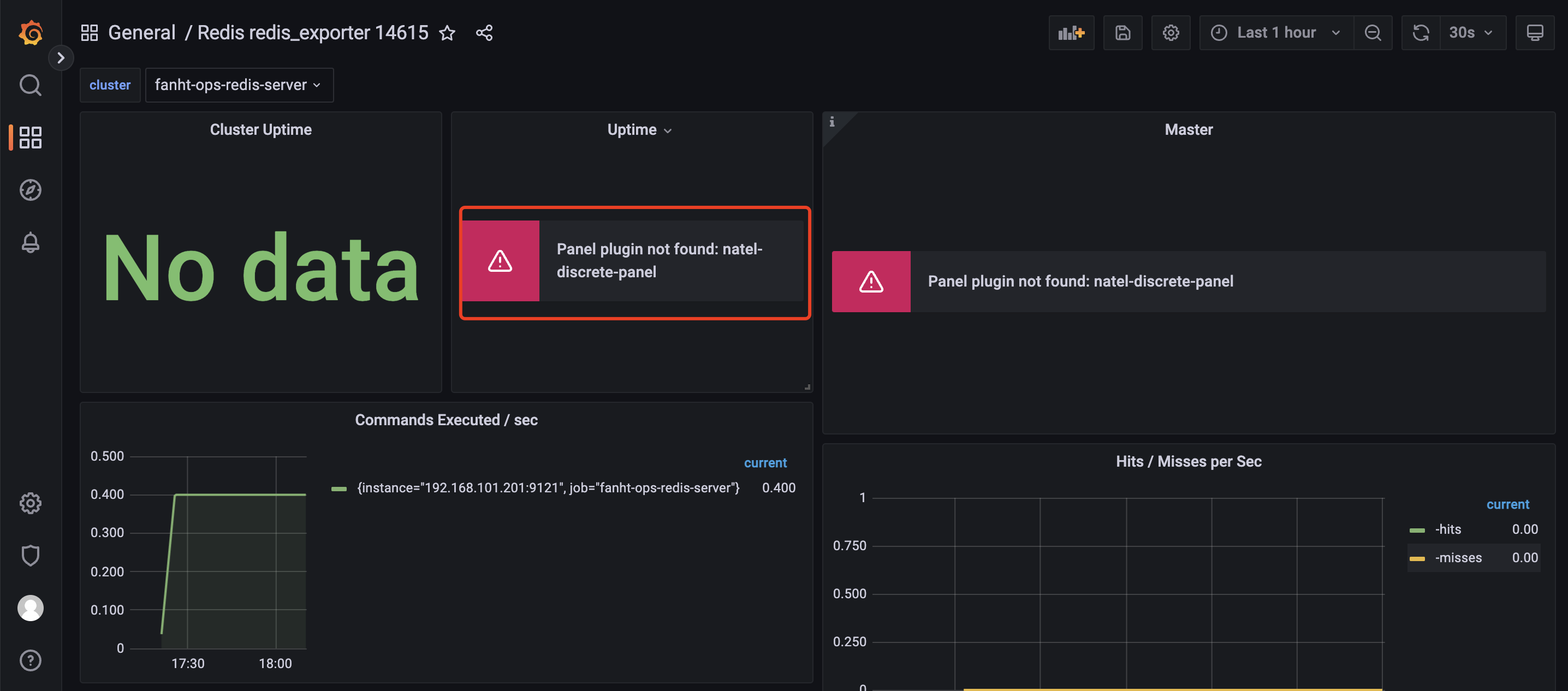
4.1、在线安装插件
饼图插件未安装,需要提前安装
grafana-cli plugins install grafana-piechart-panel #重启生效 systemctl restart grafana-server.service

4.2、离线安装插件
/var/lib/grafana/plugins unzip grafana-piechart-panel-v1.3.8-0-g4f34110.zip mv grafana-piechart-panel-4f34110 grafana-piechart-panel #重启生效 systemctl restart grafana-server.service
4.3、查看安装完插件效果
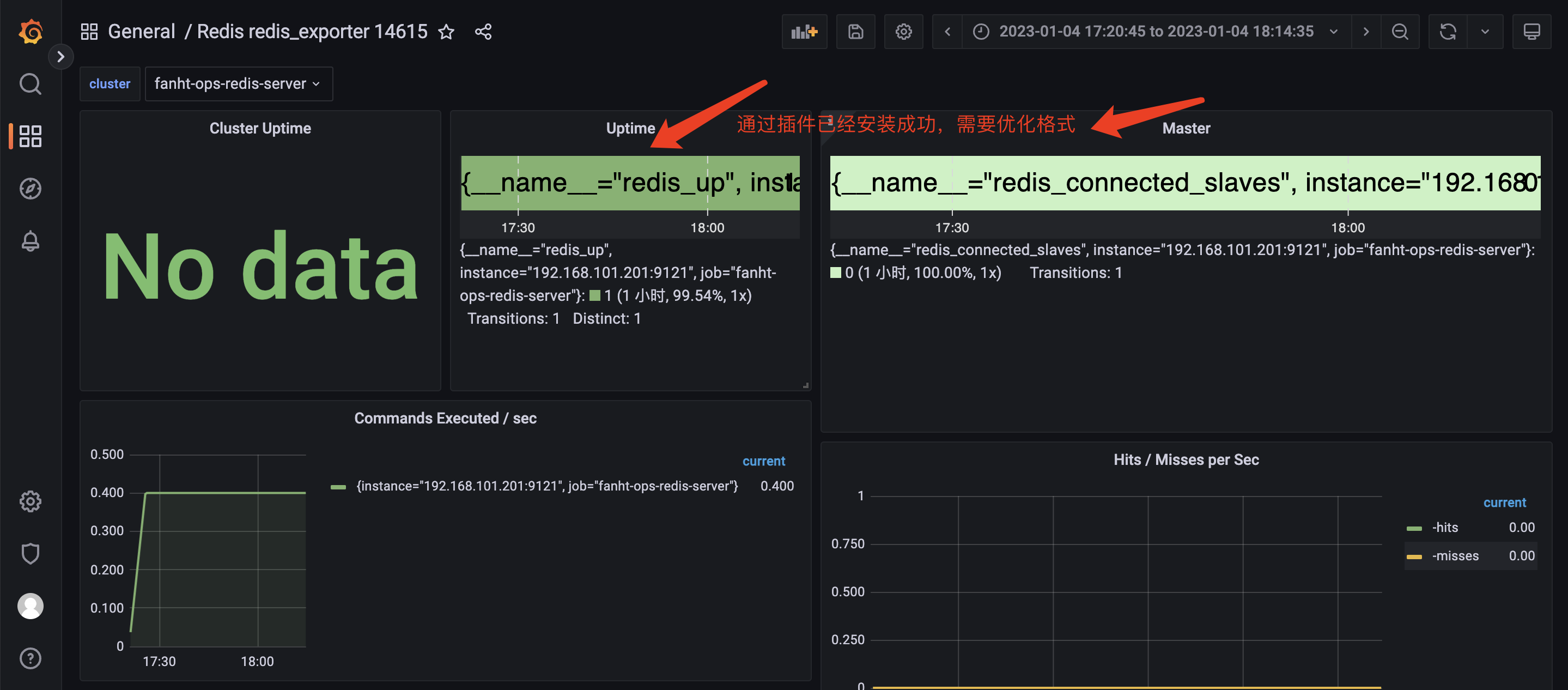
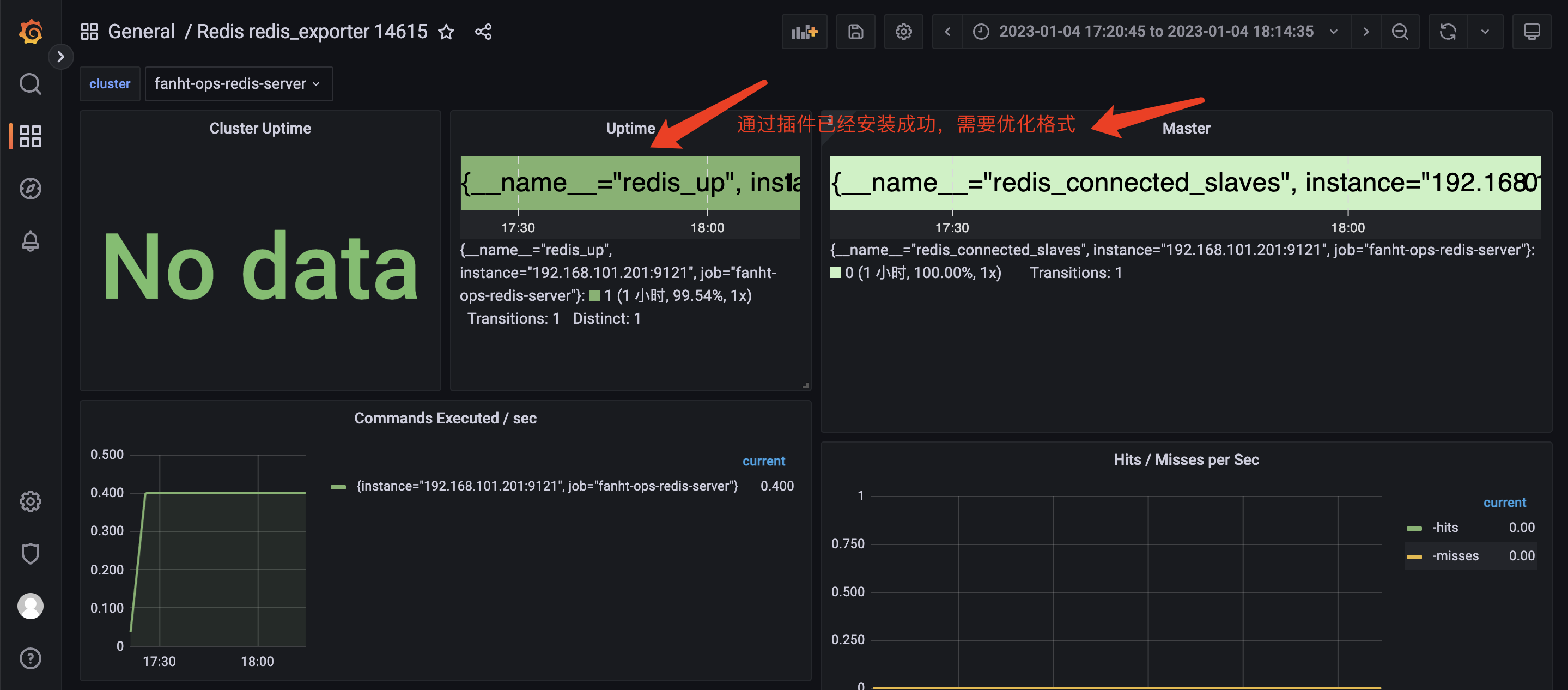
6、Grafana 页面调整演示
1、处理图片显示格式问题
五、Exporter使用案例
所有的exporter都在node 192.168.101.201节点 ubuntu20.04上安装完成。
| 机器信息 | 服务名称 | 端口 | 版本 |
| 192.168.101.201 | redis-server | 6379 | 5.0.7 |
| 192.168.101.201 | redis_exporter | 9121/metrics | v1.42.0 |
| 192.168.101.201 | mysql-server | 3306 | 5.7 |
| 192.168.101.201 | mysql_exporter |
1、Redis
监控 Redis: 通过 redis_exporter 监控 redis 服务状态。
redis_exporter-v1.42.0.linux-amd64.tar.gz
没有安装redis可以参考下面连接安装
1.1、redis_exporter准备环境
tar -xf redis_exporter-v1.42.0.linux-amd64.tar.gz -C /data/ cd /data/ ln -s redis_exporter-v1.42.0.linux-amd64/ redis_exporter

[Unit] Description=Redis Exporter Wants=network-online.target After=network-online.target [Service] User=root Group=root Type=simple ExecStart=/data/redis_exporter/redis_exporter [Install] WantedBy=multi-user.target
vim /usr/lib/systemd/system/redis_exporter.service
cat /usr/lib/systemd/system/redis_exporter.service
systemctl daemon-reload
systemctl start redis_exporter.service
ps -ef |grep redis_exporter
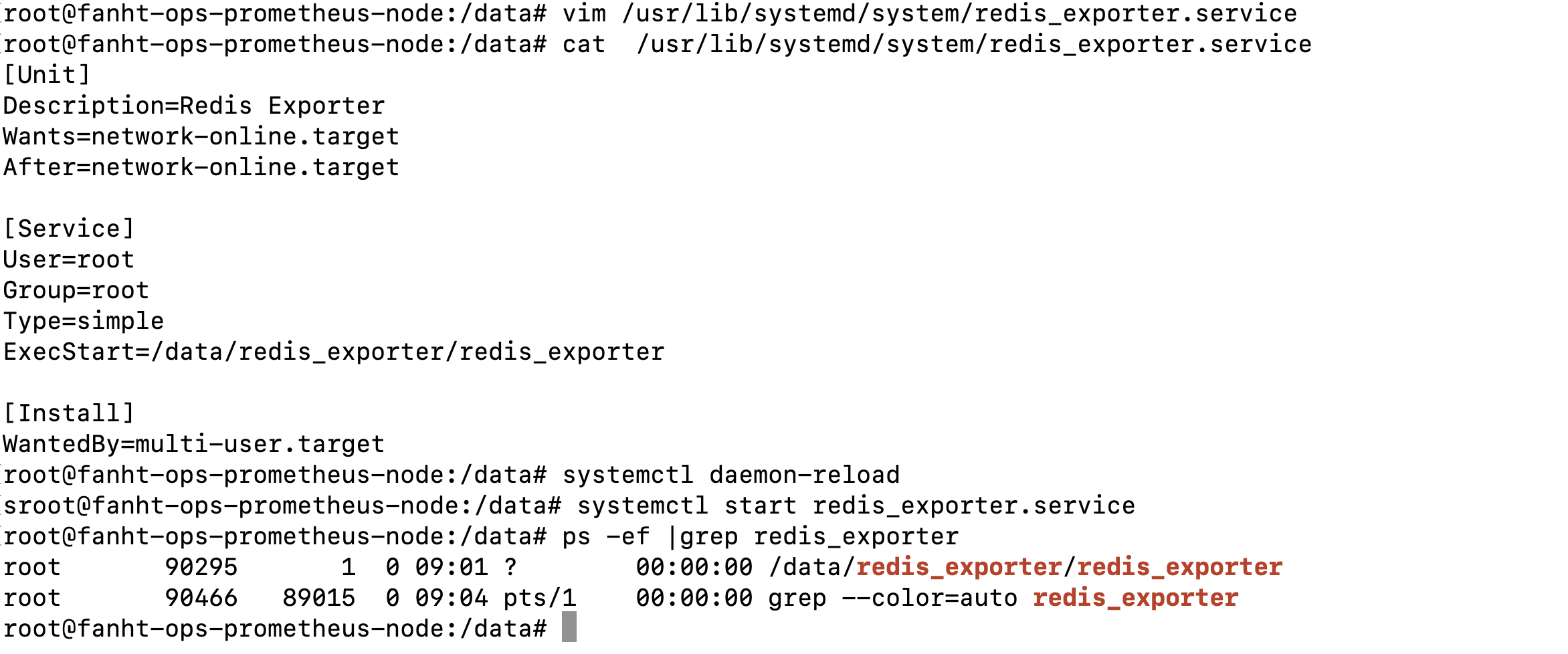
1.2、验证metrics
1.3、Prometheus采集数据
- job_name: "fanht-ops-redis-server"
static_configs:
- targets: ["192.168.101.201:9121"]

curl -X POST 192.168.101.200:9090/-/reload
vim /data/prometheus/prometheus.yml
cat /data/prometheus/prometheus.yml
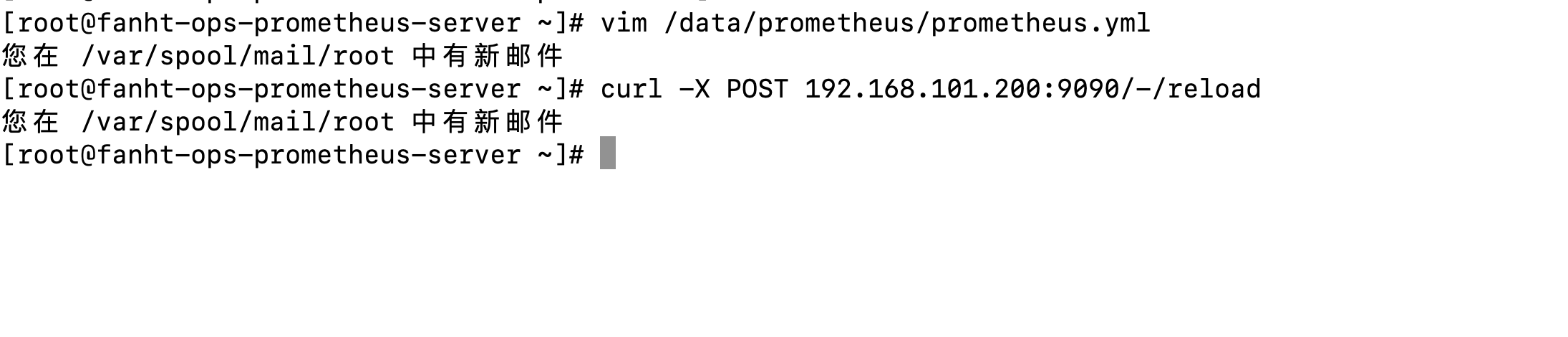
1.4、Prometheus查看Target
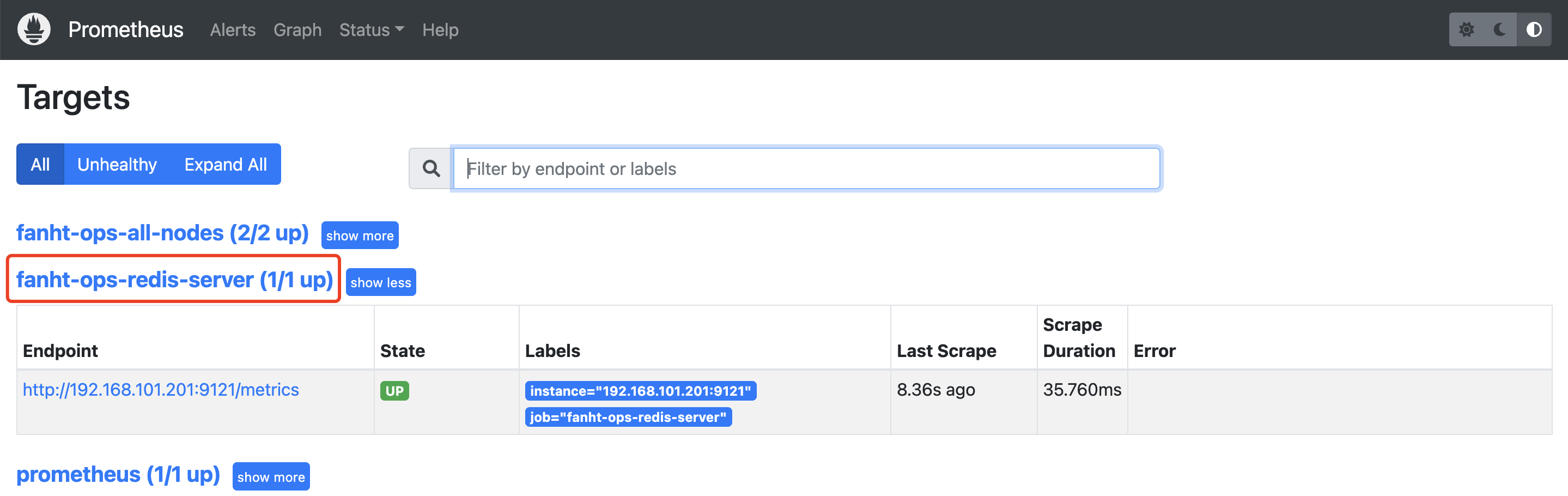
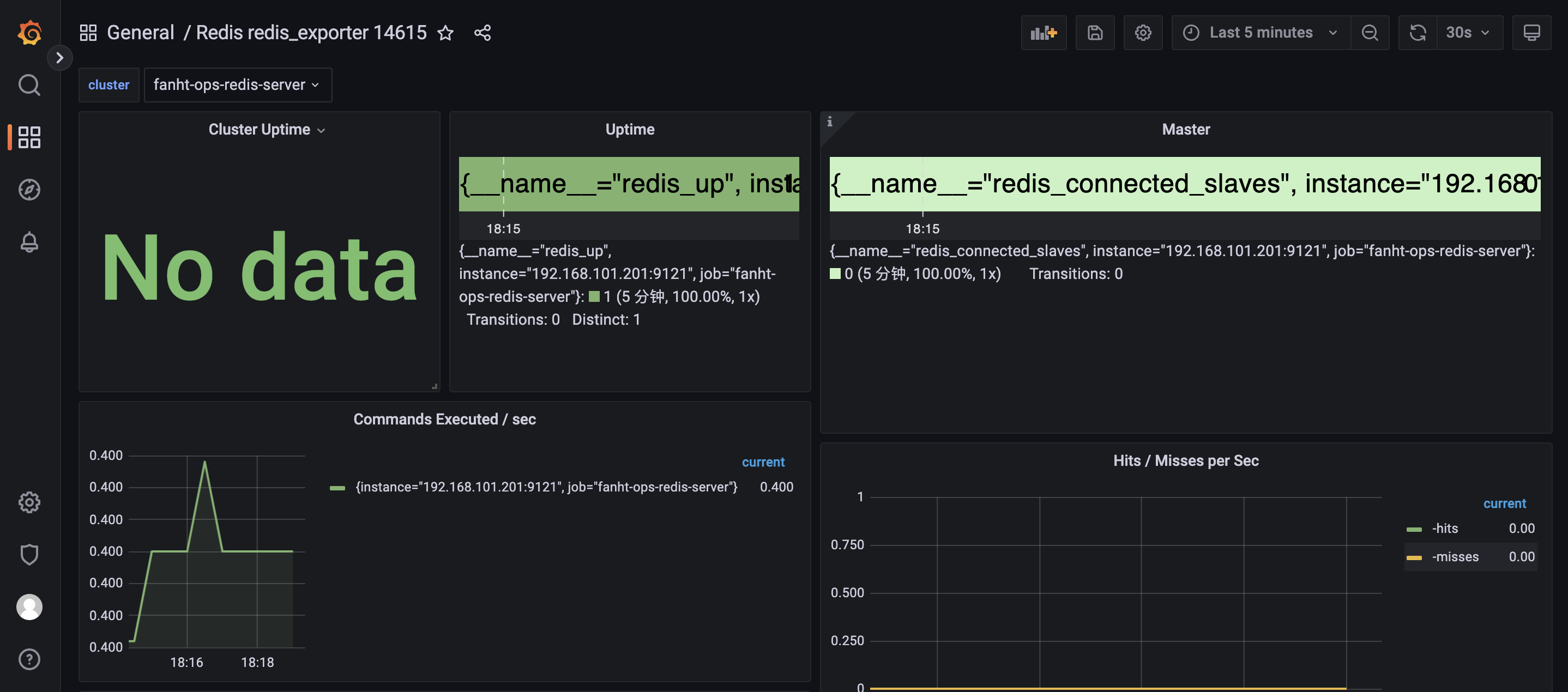
1.5、配置Grafana 模版
推荐模版ID:14615
2、Mysql
通过 mysqld_exporter 监控 MySQL 服务的运行状态
2.1、选择202节点操作
mysql_exporter安装在 192.168.101.201 node节点上,收集数据库问题。
没有安装mysql可以参考
2.2、授权监控账户权限
root密码 普通用户密码mysql_exporter2023+
CREATE USER 'mysql_exporter'@'localhost' IDENTIFIED BY '密码;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO '密码'@'localhost';
2.3、mysqld_exporter准备环境
2.3.1、注意版本信息
Mysql_Exporter支持mysql版本
- MySQL >= 5.6.
- MariaDB >= 10.3
2.3.2、免密码登录配置
# cat /root/.my.cnf
[client]
user=mysql_exporter
password=密码
2.3.3、安装配置mysql_exporter
mysqld_exporter-0.14.0.linux-amd64.tar.gz
2.3.4、配置系统启动
vim /etc/systemd/system/mysqld_exporter.service
[Unit] Description=Prometheus Node Exporter After=network.target [Service] ExecStart=/usr/local/bin/mysqld_exporter --config.my-cnf=/root/.my.cnf [Install] WantedBy=multi-user.target
systemctl daemon-reload
systemctl restart mysqld_exporter
systemctl enable mysqld_exporter
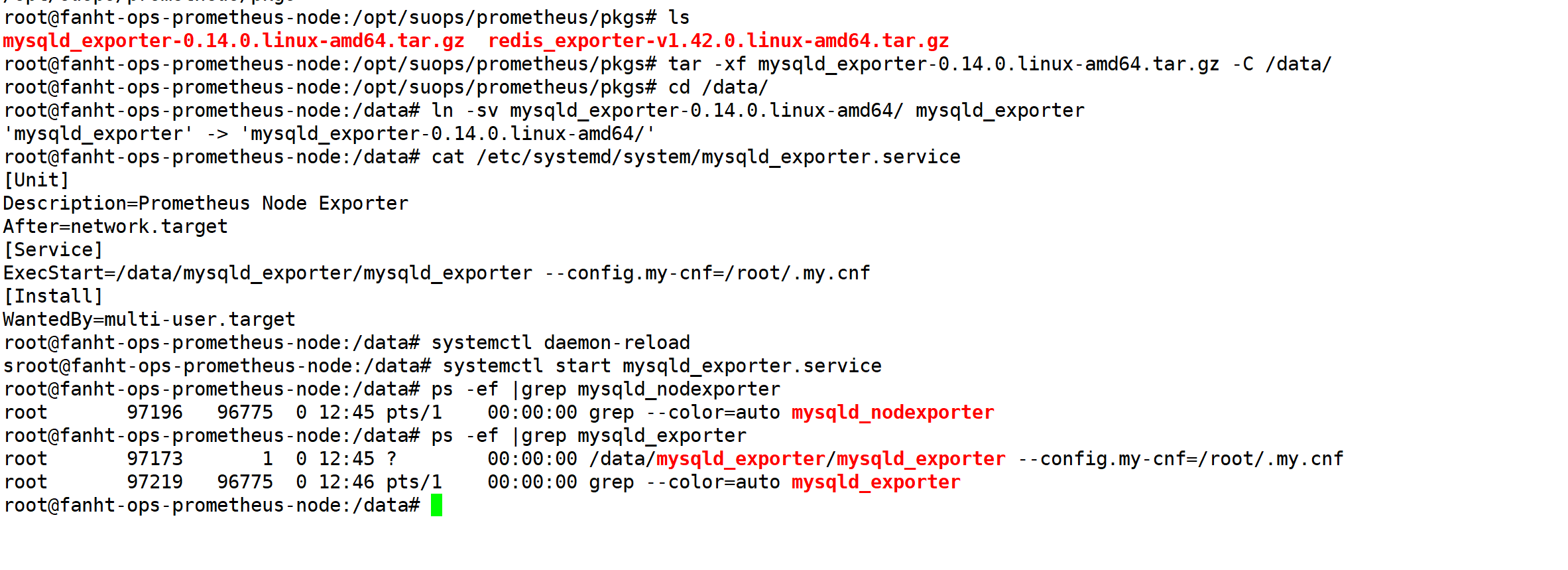
2.4、验证metrics

http://192.168.101.201:9104/metrics
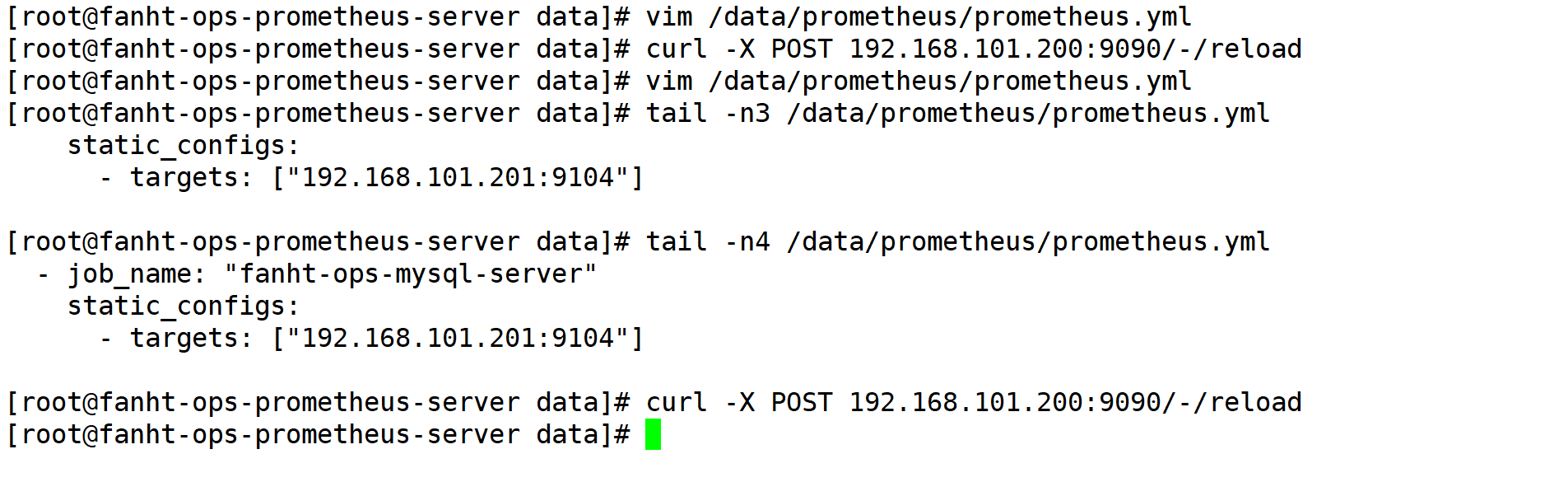
2.5、prometheus收集数据
2.5.1、prometheus server新增配置
vim /data/prometheus/prometheus.yml
- job_name: "fanht-ops-mysql-server"
static_configs:
- targets: ["192.168.101.201:9104"]

2.5.2、prometheus server 热加载生效
tail -n4 /data/prometheus/prometheus.yml
curl -X POST 192.168.101.200:9090/-/reload
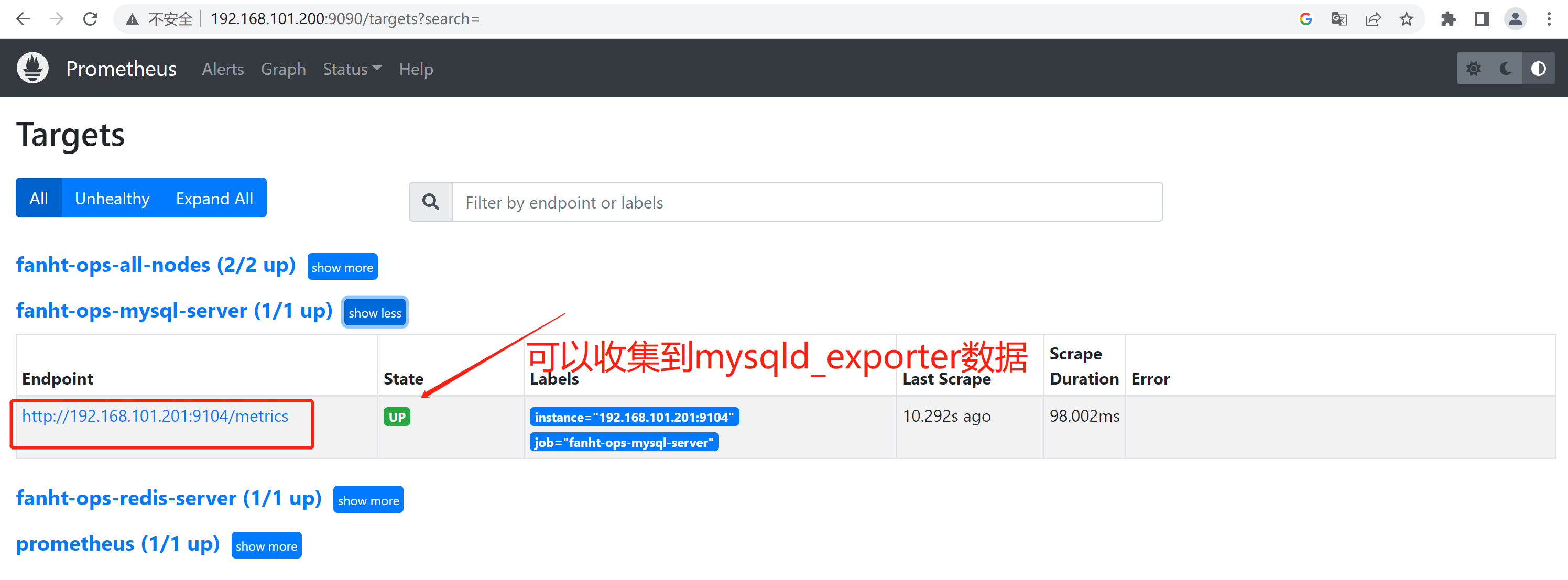
2.5.3、Prometheus查看Target
http://192.168.101.200:9090/targets?search=
2.6、Grafana配置模板
推荐模板ID:7362、 11323
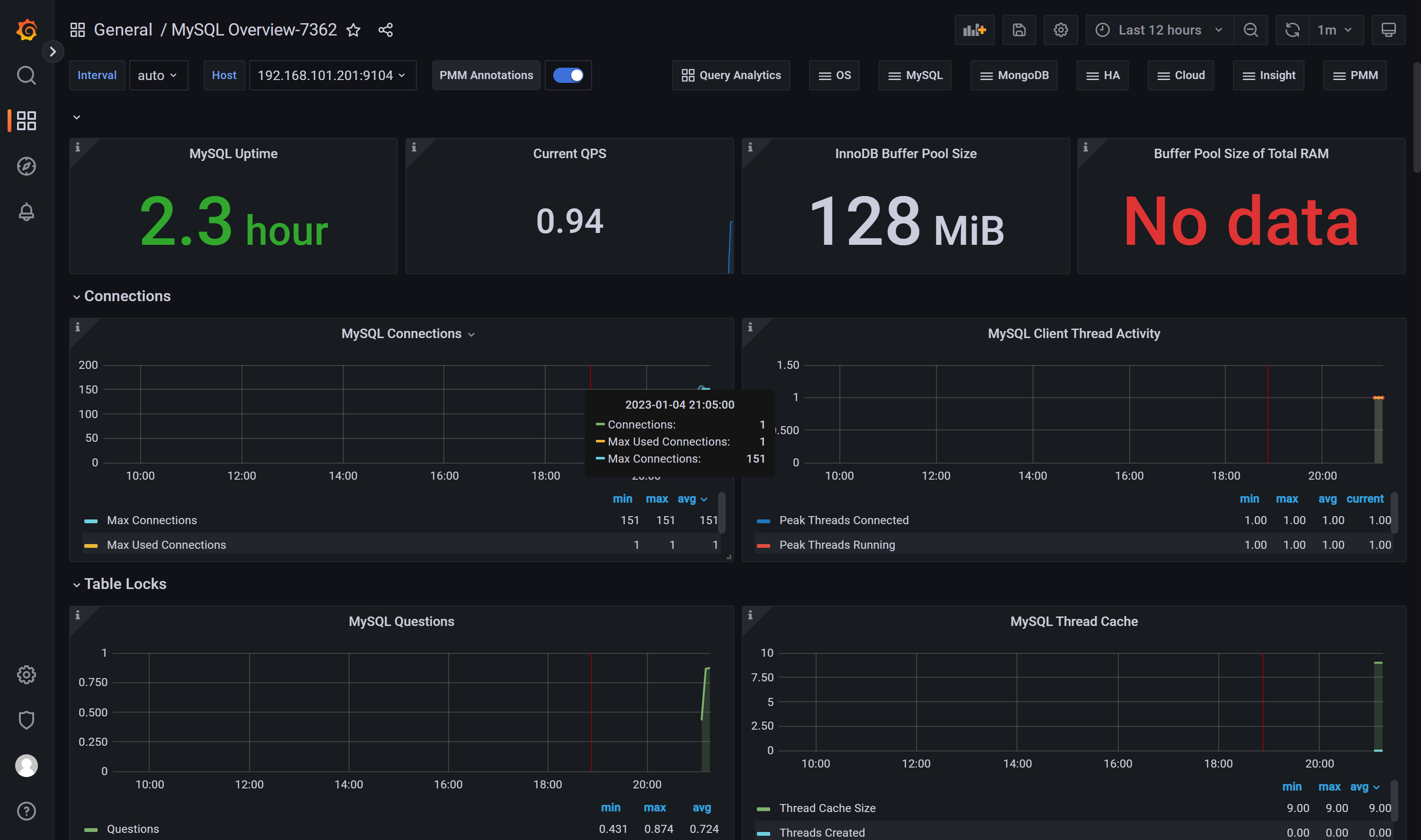
配置主从复制推荐模板ID:11323
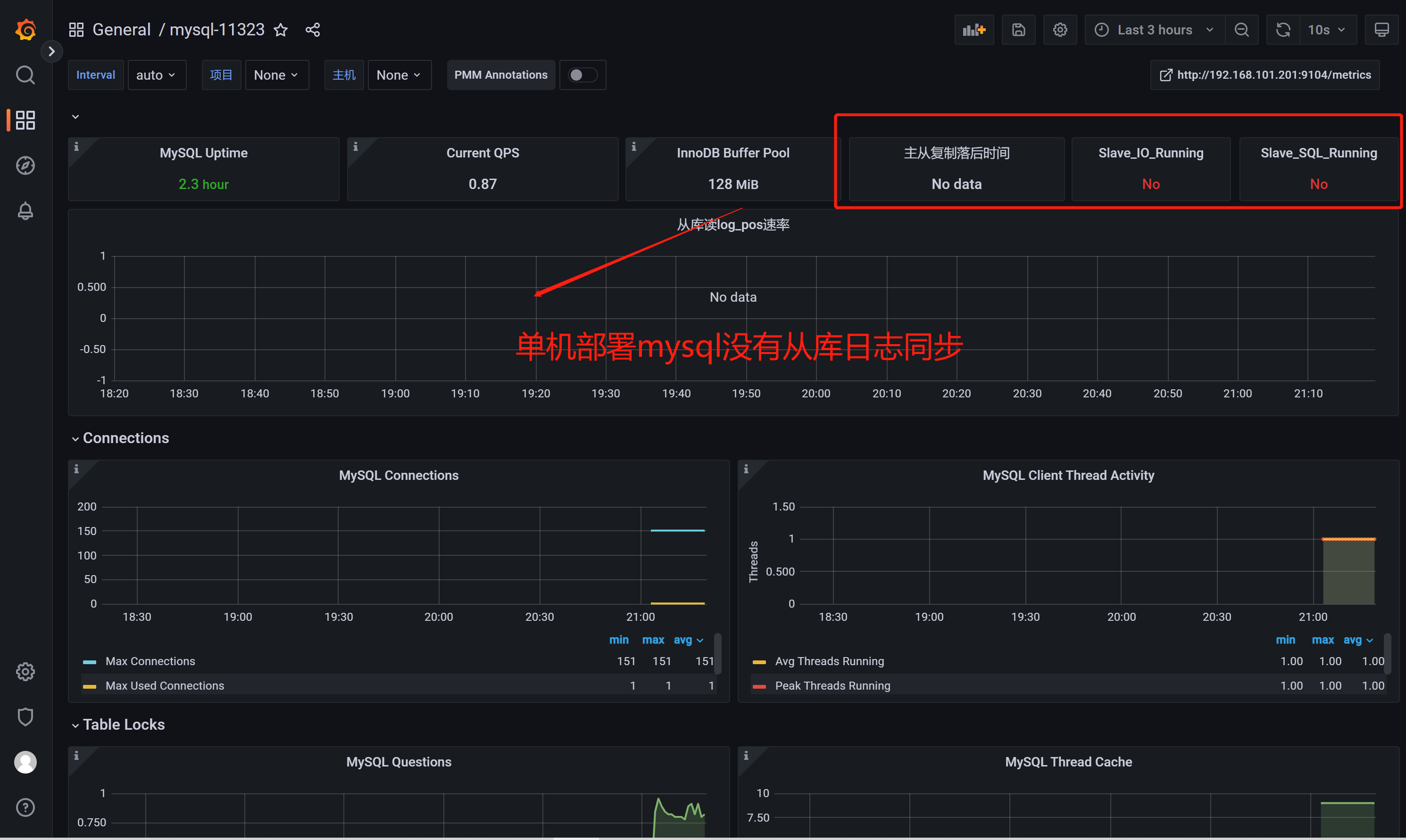
如果安装的是Mariadb推荐模板ID:13106
3、Haproxy
通过 haproxy_exporter 监控 haproxy
haproxy_exporter-0.14.0.linux-amd64.tar.gz
1、在202节点机器上操作
1.1、haproxy代理配置
| Haproxy端口 | 后端端口 | 备注 |
| 3264 | N/A | haproxy管理页面 |
| 3265 | 9090 | prometheus server |
| 3266 | 30000 | grafana dashboard |
1.2、ubuntu20.04安装Haproxy
2、haproxy_exporter准备环境
2.1、安装haproxy_exporter
wget https://github.com/prometheus/haproxy_exporter/releases/download/v0.14.0/haproxy_exporter-0.14.0.linux-amd64.tar.gz ls tar -xf haproxy_exporter-0.14.0.linux-amd64.tar.gz -C /data/ cd /data/ ln -sv haproxy_exporter-0.14.0.linux-amd64/ haproxy_exporter

2.2、配置系统启动
官方提供多种启动方法
./haproxy_exporter --haproxy.scrape-uri=unix:/run/haproxy/admin.sock # 了解即可
配置 haproxy_exporter.service
vim /usr/lib/systemd/system/haproxy_exporter.service
cat /usr/lib/systemd/system/haproxy_exporter.service
[Unit] Description=haproxy-exporter Documentation=https://prometheus.io/ After=network.target [Service] Type=simple User=root Group=root WorkingDirectory=/data/haproxy_exporter ExecStart=/data/haproxy_exporter/haproxy_exporter \ --web.listen-address=0.0.0.0:9101 \ #--haproxy.scrape-uri="http://admin:1234567@127.0.0.1:3264/haproxy?stats;csv" --haproxy.scrape-uri=unix:/run/haproxy/admin.sock ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID Restart=on-failure [Install] WantedBy=multi-user.target
启动服务
cat /usr/lib/systemd/system/haproxy_exporter.service
systemctl daemon-reload
systemctl start haproxy_exporter.service
ps -ef |grep haproxy_exporter
netstat -ntlp|grep haproxy
systemctl enable haproxy_exporter.service

2.3、验证metrics
2.4、prometheus收集数据
2.4.1、配置jobname
vim /data/prometheus/prometheus.yml

2.4.2、热加载配置生效
curl -X POST 192.168.101.200:9090/-/reload
2.4.2、prometheus 查看Target
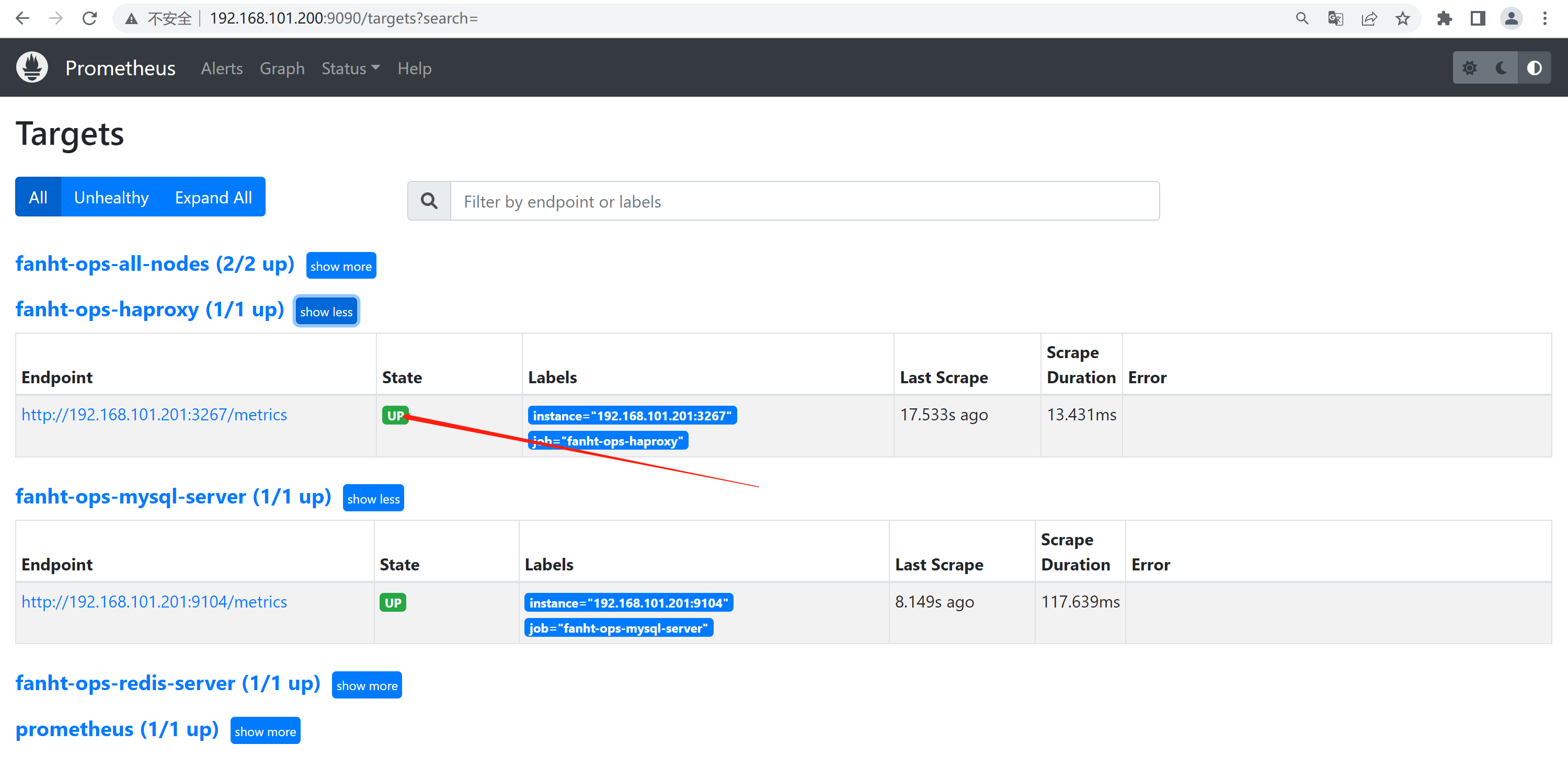
2.5、Grafana配置模板
推荐模板ID: 367和2428
25.1、访问代理产生数据
多访问几次产生数据,方便haproxy_exporter收集
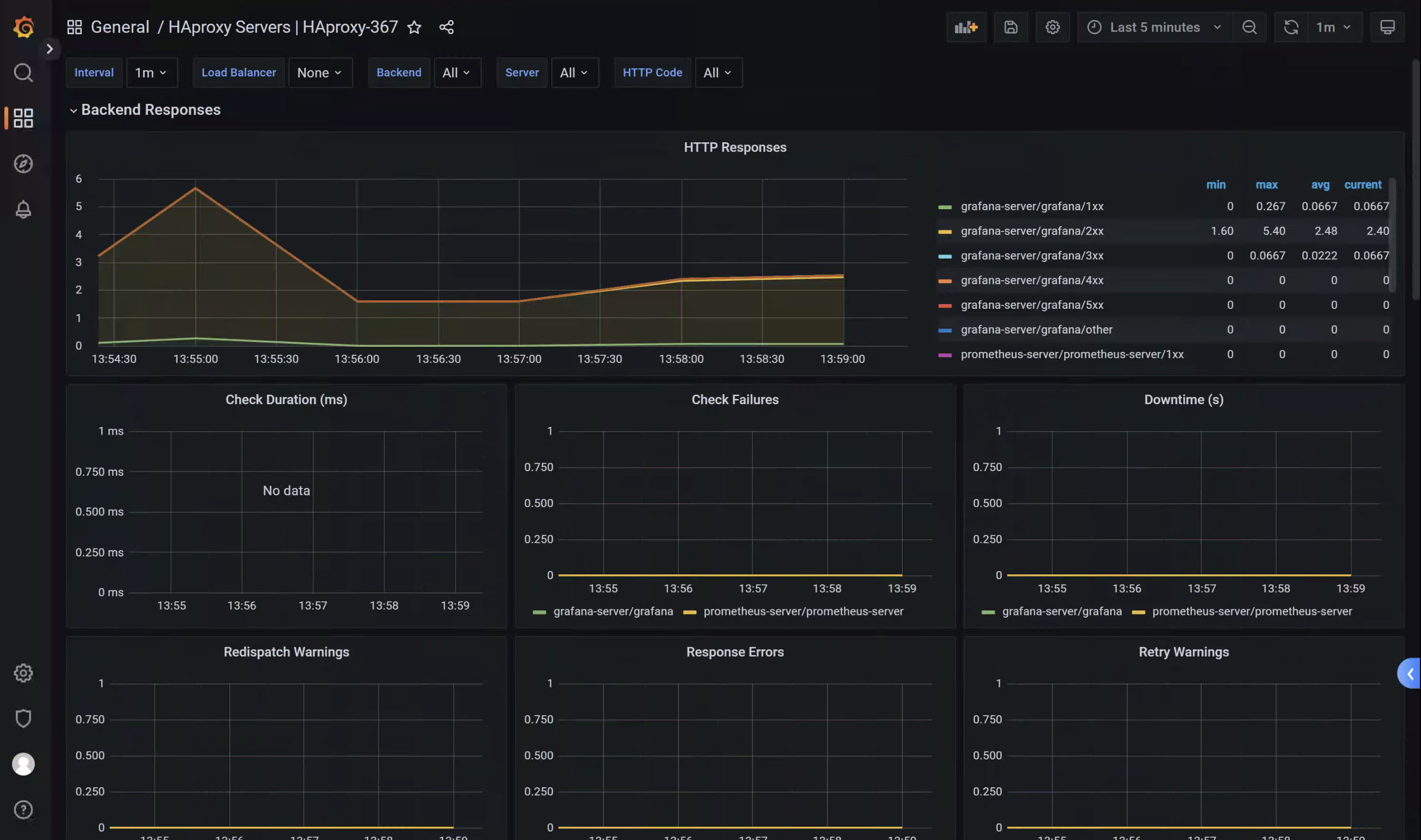
2.5.2、验证数据
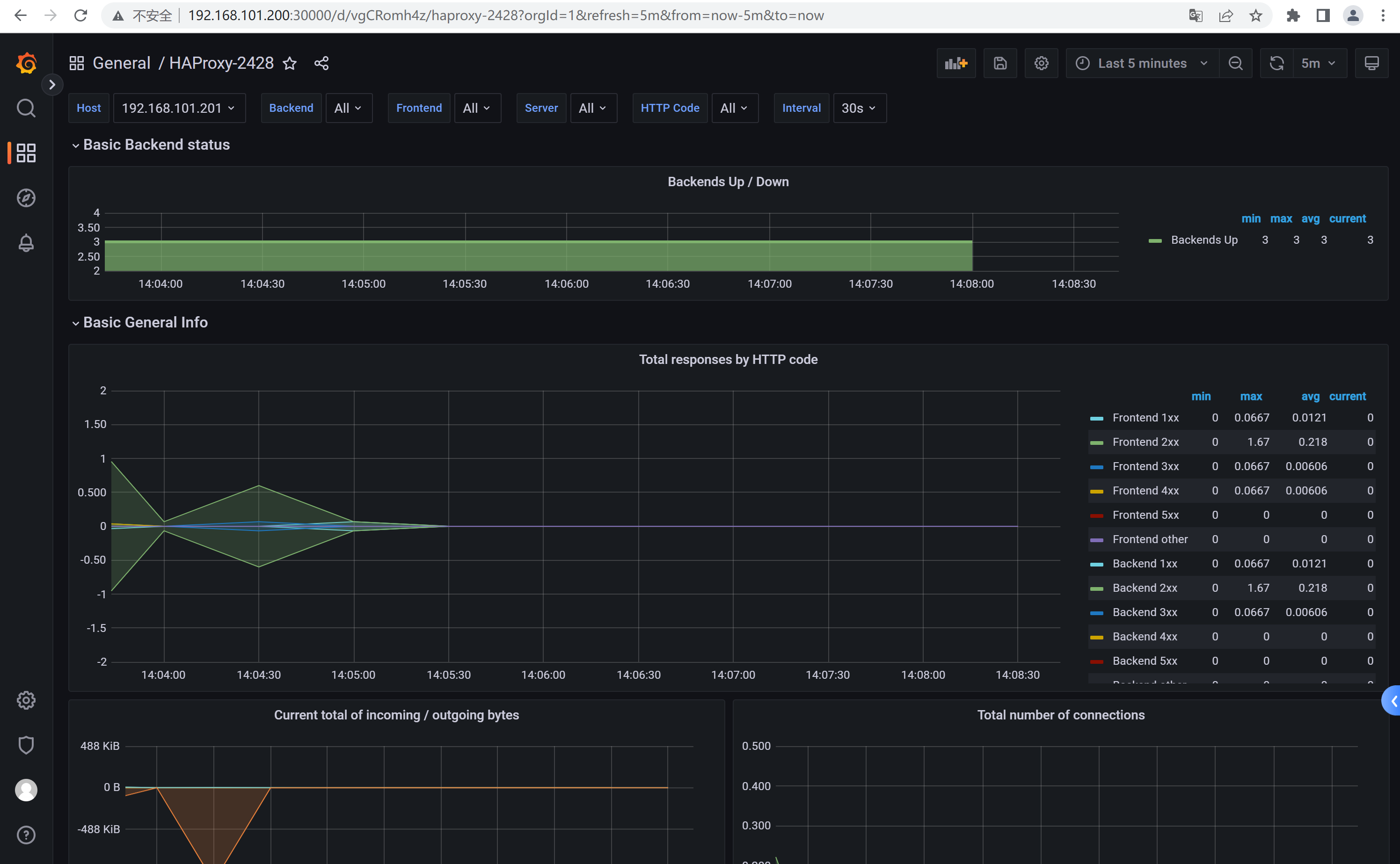
4、Nginx Exporter
exporter 默认端口9913
通过 prometheus 监控 nginx
需要在编译安装 nginx 的时候添加 nginx-module-vts 模块
github 地址:
nginx-vts-exporter-0.10.0.linux-amd64.tar.gz
4.、编译安装Nginx和vts模块
4.2、nginx-vts-exporter环境准备
4.2.1、安装nginx-vts-exporter
wget https://github.com/hnlq715/nginx-vts-exporter/releases/download/v0.10.0/nginx-vts-exporter-0.10.0.linux-amd64.tar.gz tar -xf nginx-vts-exporter-0.10.0.linux-amd64.tar.gz -C /data/ cd /data/ ln -sv nginx-vts-exporter-0.10.0.linux-amd64/ nginx-vts-exporter

4.2.2、配置系统启动
[Unit] Description=Prometheus exporter thar exports Nginx VTS stats. Documentation=https://github.com/hnlq715/nginx-vts-exporter After=network.target [Service] EnvironmentFile=-/data/nginx-vts-exporter User=prometheus ExecStart=/data/nginx-vts-exporter/nginx-vts-exporter $NGINX_VTS_EXPORTER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target
4.3、验证metrics
http://192.168.101.201:9913/metrics
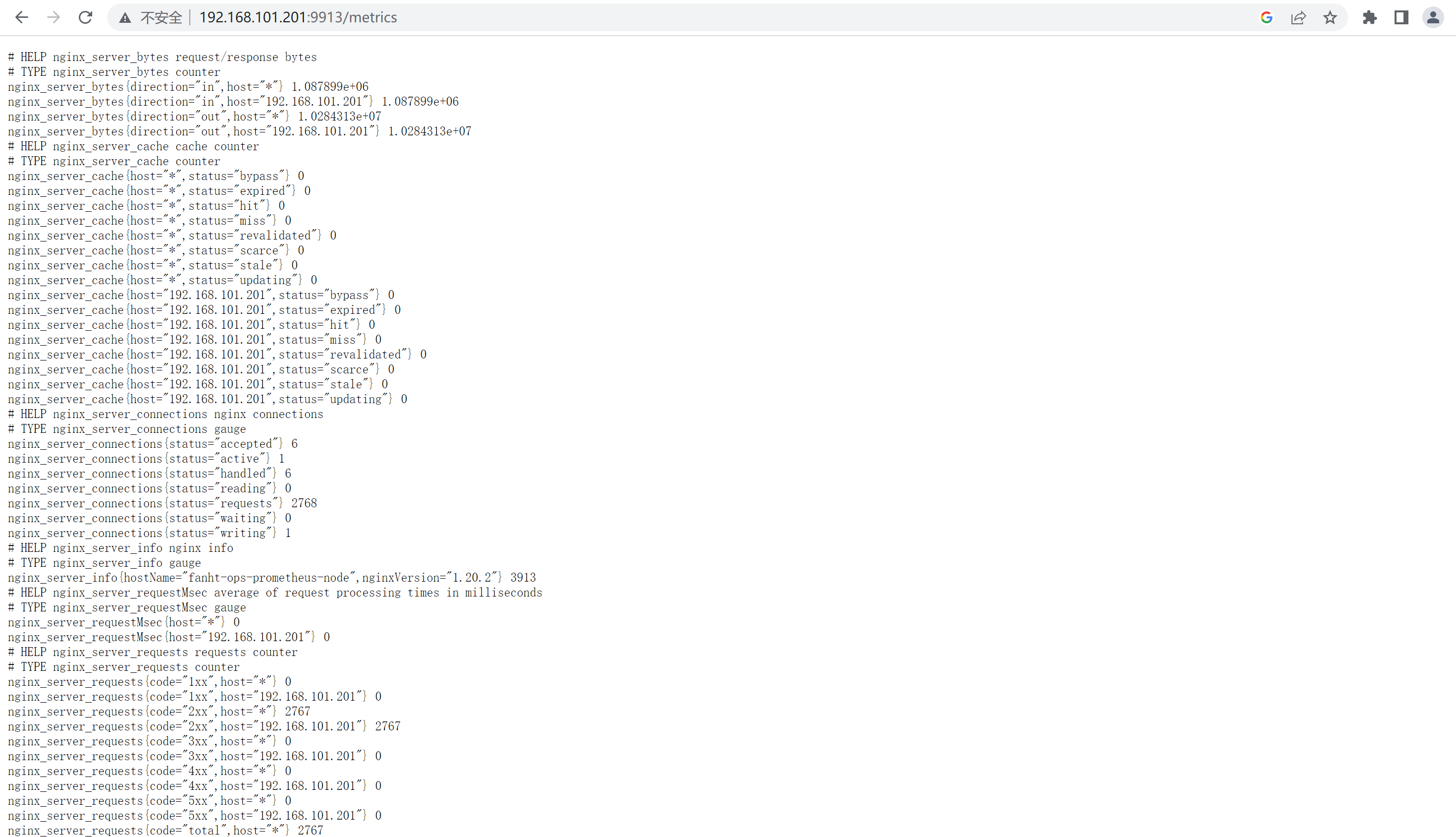
5、Prometheus验证Target

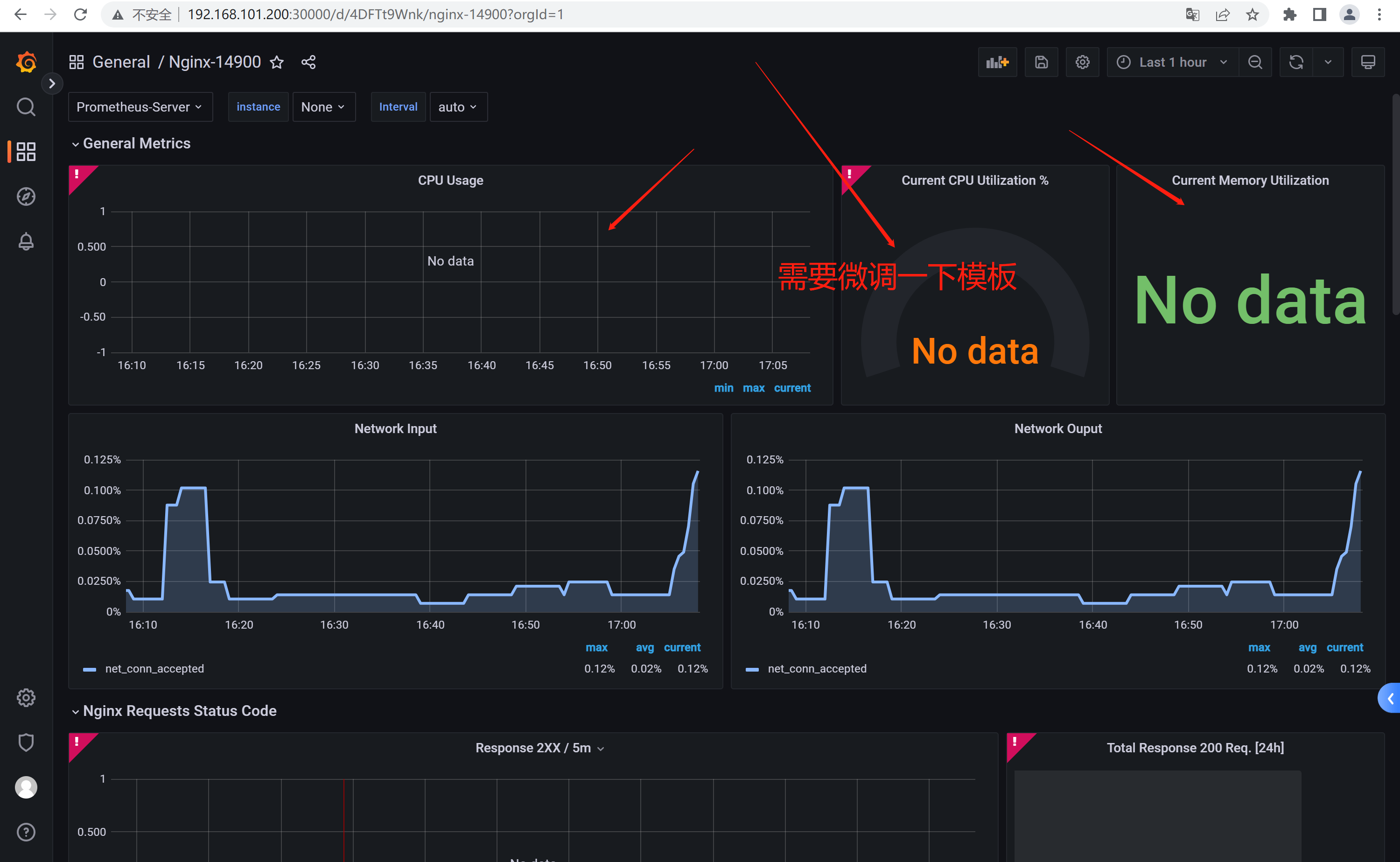
6、Grafana配置模版
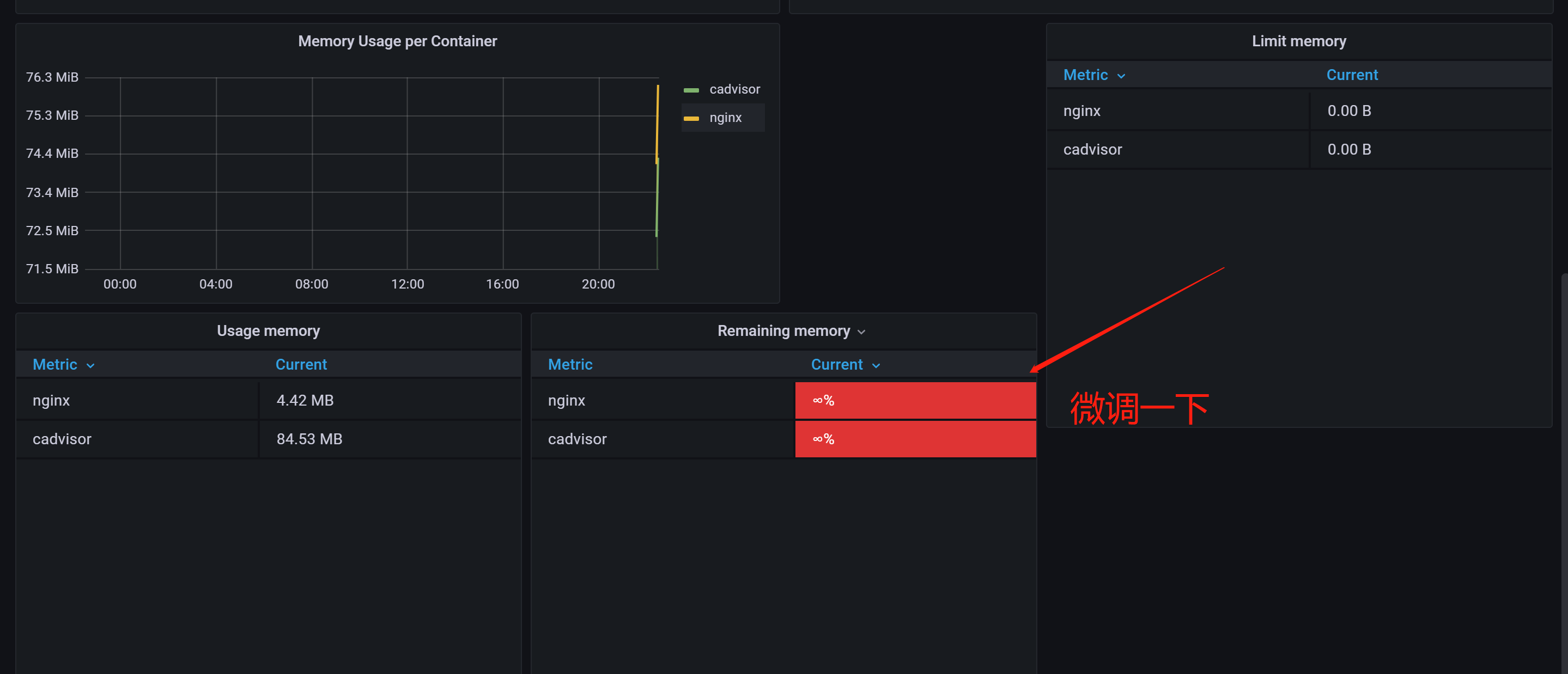
推荐模版ID:14900

模版需要微调一下
100 - (cpu_usage_idle{instance=~ "$instance*",cpu="cpu-total"})
5、 Blackbox exporter
blackbox_exporter 是 Prometheus 官方提供的一个 exporter,可以通过HTTP, HTTPS, DNS, TCP 和 ICMP 对被监控节点进行监控和数据采集。
HTTP/HTPPS:URL/API 可用性检测 TCP:端口监听检测 ICMP:主机存活检测 DNS:域名解析
blackbox_exporter可以安装在任意节点,前提可以跟prometheus server通信。可以访探测到其他内部服务端口
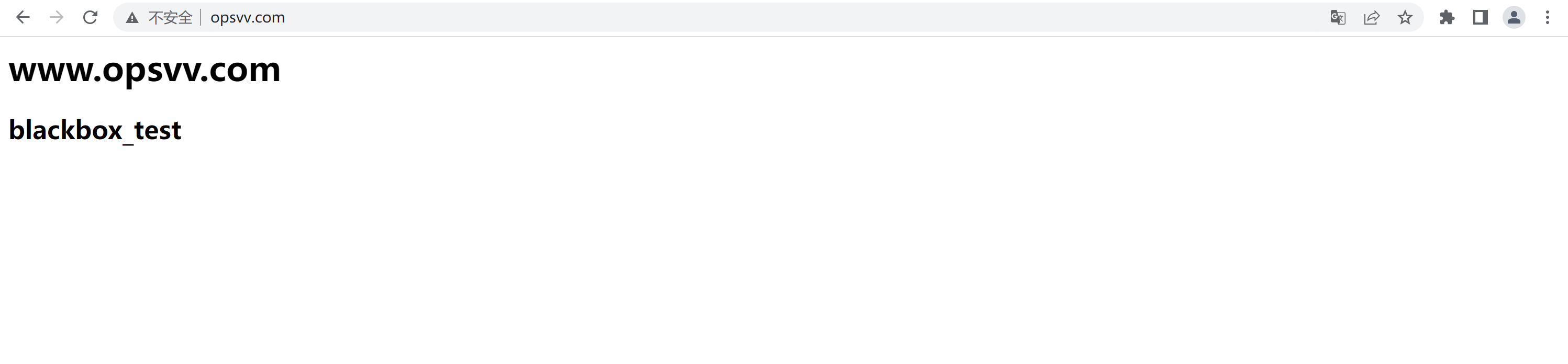
5.1、配置公网域名,解析到内部服务器
可以使用bind powerdns 等配置内部解析
直接使用公网域名解析到内网服务器
http访问测试域名

5.2、Exporter环境准备
| 角色 | 机器IP | 端口 |
| prometheus server | 192.168.101.200 | 9090 |
| blackbox exporter | 192.168.101.201 | 91115 |
| www.opsvv.com #测试域名解析 | 192.168.101.201 | 80 |

blackbox_exporter-0.22.0.linux-amd64.tar.gz
5.2.1、下载安装blackbox exporter
wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.22.0/blackbox_exporter-0.22.0.linux-amd64.tar.gz tar -xf blackbox_exporter-0.22.0.linux-amd64.tar.gz -C /data/ cd /data/ ln -sv blackbox_exporter-0.22.0.linux-amd64/ blackbox_exporter

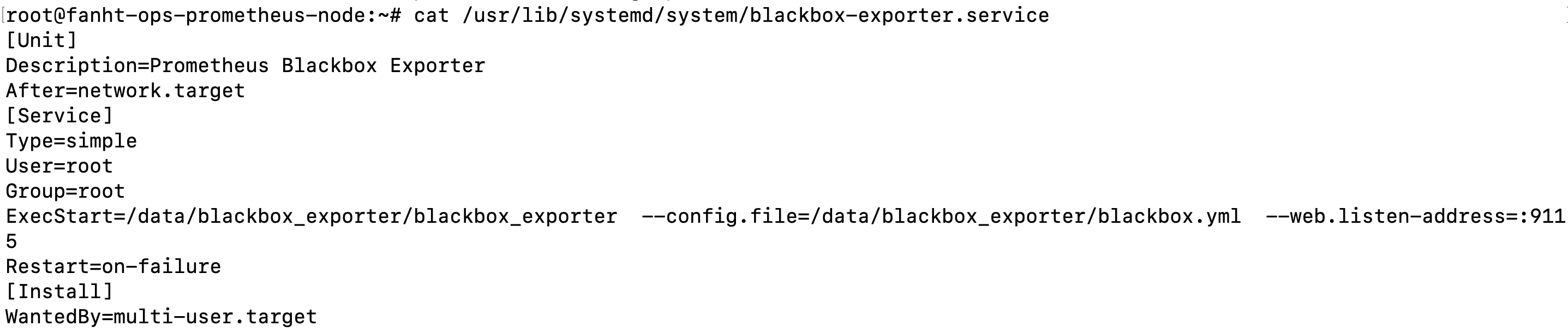
5.2.2、配置系统启动
cat /usr/lib/systemd/system/blackbox-exporter.service
[Unit] Description=Prometheus Blackbox Exporter After=network.target [Service] Type=simple User=root Group=root ExecStart=/data/blackbox_exporter/blackbox_exporter --config.file=/data/blackbox_exporter/blackbox.yml --web.listen-address=:9115 Restart=on-failure [Install] WantedBy=multi-user.target
cd /data/
systemctl daemon-reload
systemctl start blackbox-exporter.service
ps -ef |grep blackbox
netstat -ntlp|grep blackbox

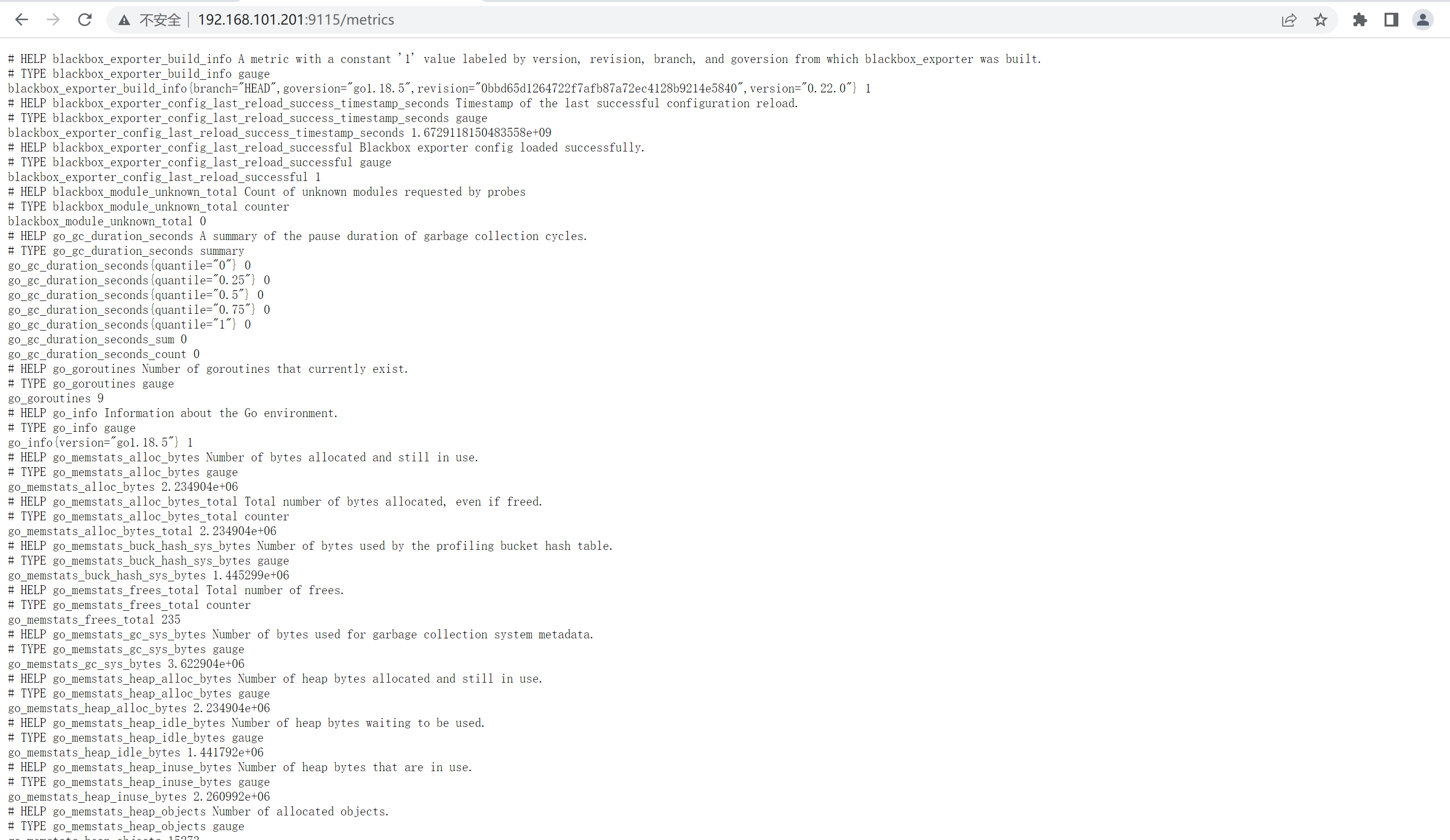
5.3、验证metrics
http://192.168.101.201:9115/metrics
5.4、prometheus server收集数据
prometheus 调用 blackbox exporter 实现对 URL/ICMP 的监控。
5.4.1、配置常用监控项
##blackbox监控
- job_name: 'http_status'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets: ['http://www.opsvv.com', 'http://www.opsvv.com']
#- targets: ['https://ssl.ingress.opsvv.com', 'https://test01.ingress.opsvv.com']
labels:
instance: http_status
group: web
relabel_configs:
- source_labels: [__address__] #relabel通过将__address__(当前目标地址)写入__param_target标签来创建一个label。
target_label: __param_target #监控目标www.opsvv.com,作为__address__的value
- source_labels: [__param_target] #监控目标
target_label: url #将监控目标与url创建一个label
- target_label: __address__
replacement: 192.168.101.201:9115 #blackbox安装的那台机器
# icmp 检测
- job_name: 'ping_status'
metrics_path: /probe
params:
module: [icmp]
static_configs:
- targets: ['192.168.101.100',"192.168.101.200"]
labels:
instance: 'ping_status'
group: 'icmp'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: ip #将ip与__param_target创建一个label
- target_label: __address__
replacement: 192.168.101.201:9115 #blackbox安装的那台机器
# 端口监控
- job_name: 'port_status'
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets: ['192.168.101.200:9090', '192.168.101.100:80','192.168.101.100:22']
labels:
instance: 'port_status'
group: 'port'
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: ip
- target_label: __address__
replacement: 192.168.101.201:9115 #blackbox安装的那台机器

5.4.2、热加载配置
curl -X POST 192.168.101.200:9090/-/reload

5.4.3、prometheus验证 Trarget

展开查看详细target信息
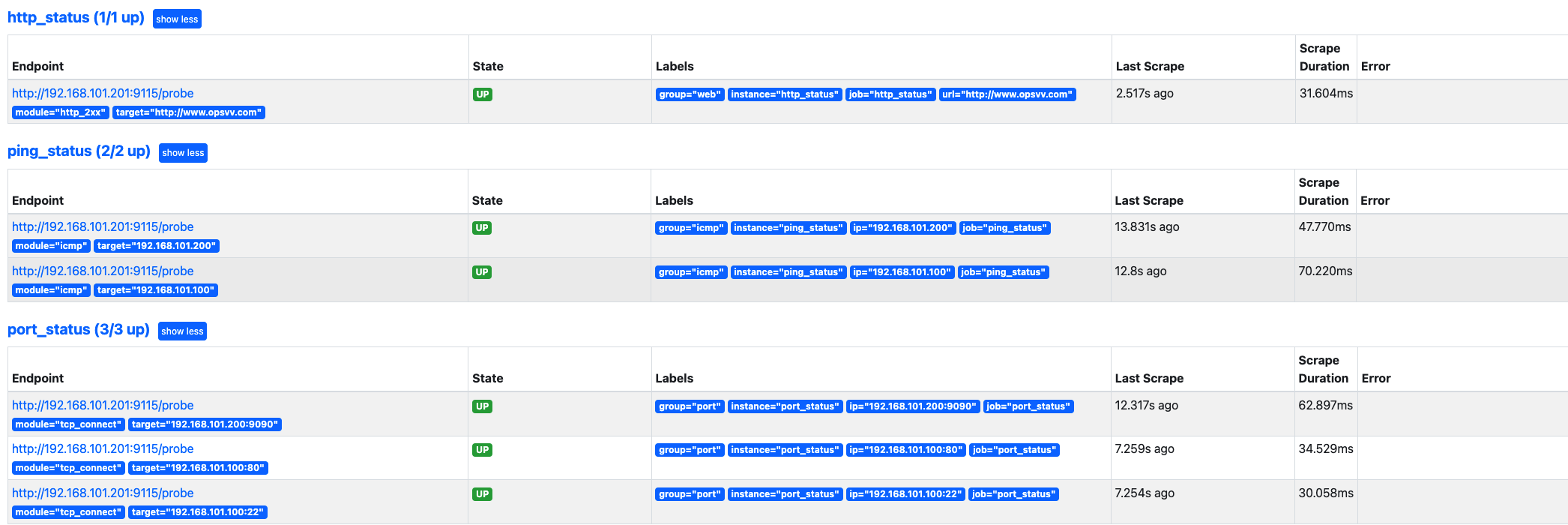
5.4.4、访问blackbox
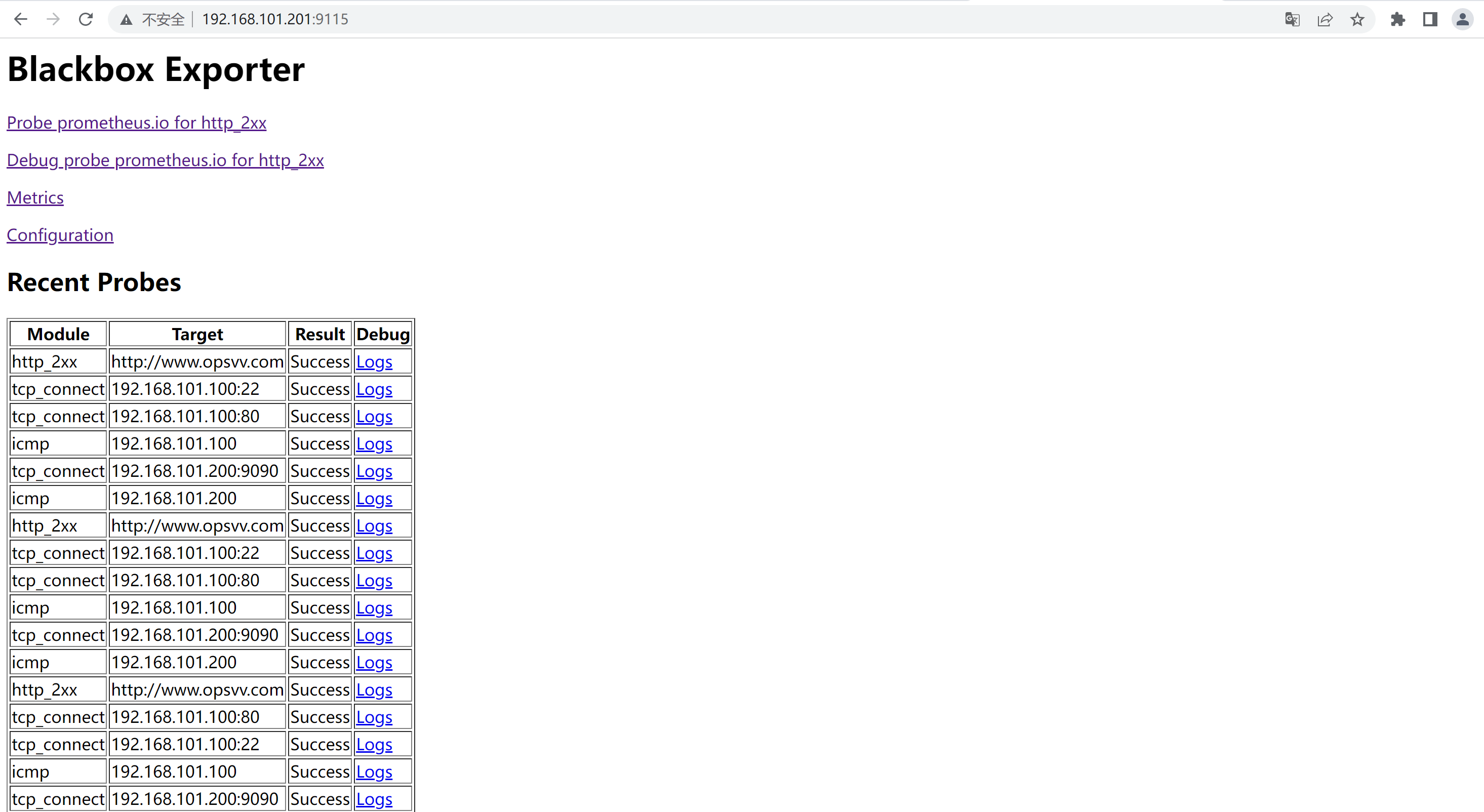
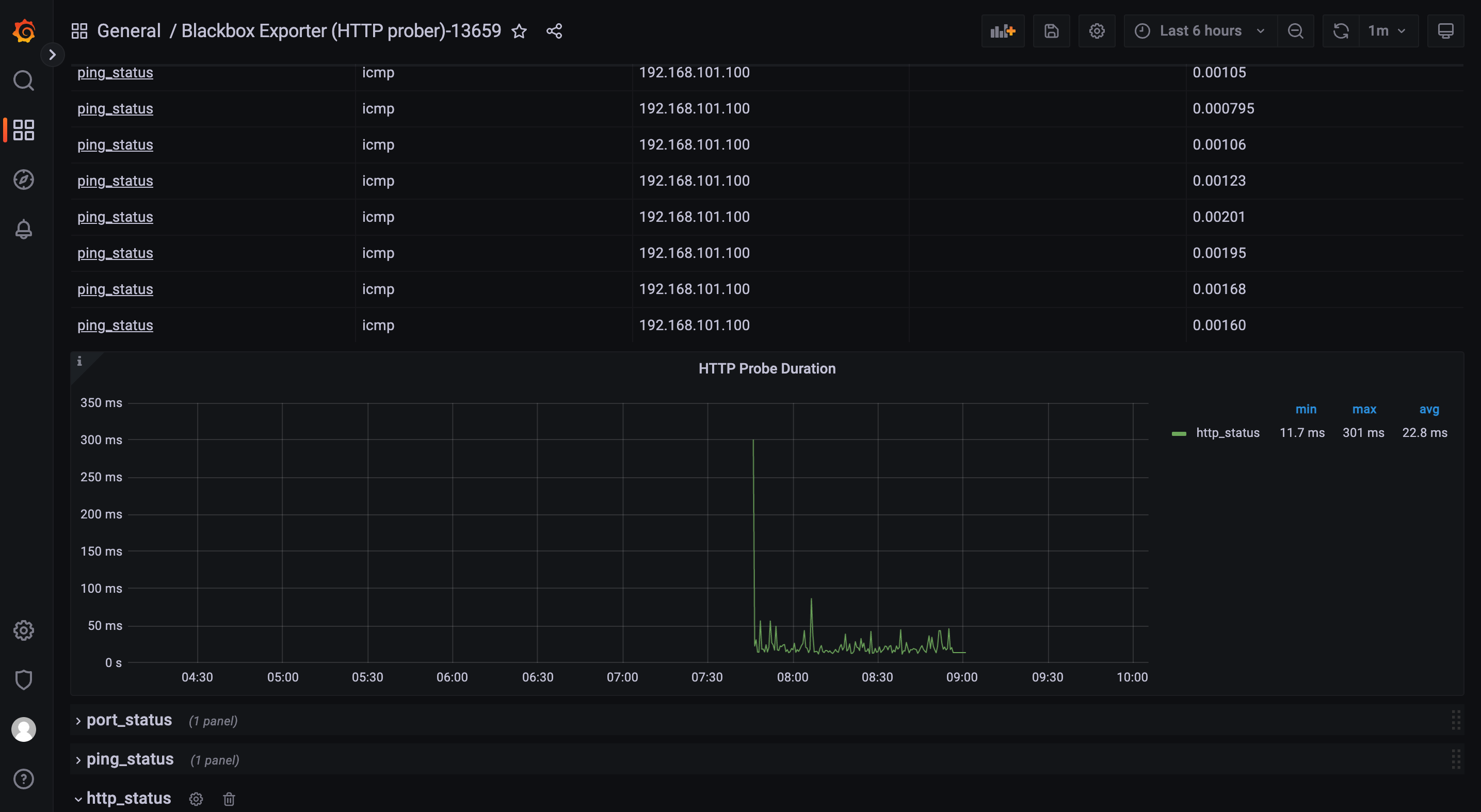
6、Grafana配置模版
推荐模版ID:13587、7587、13659
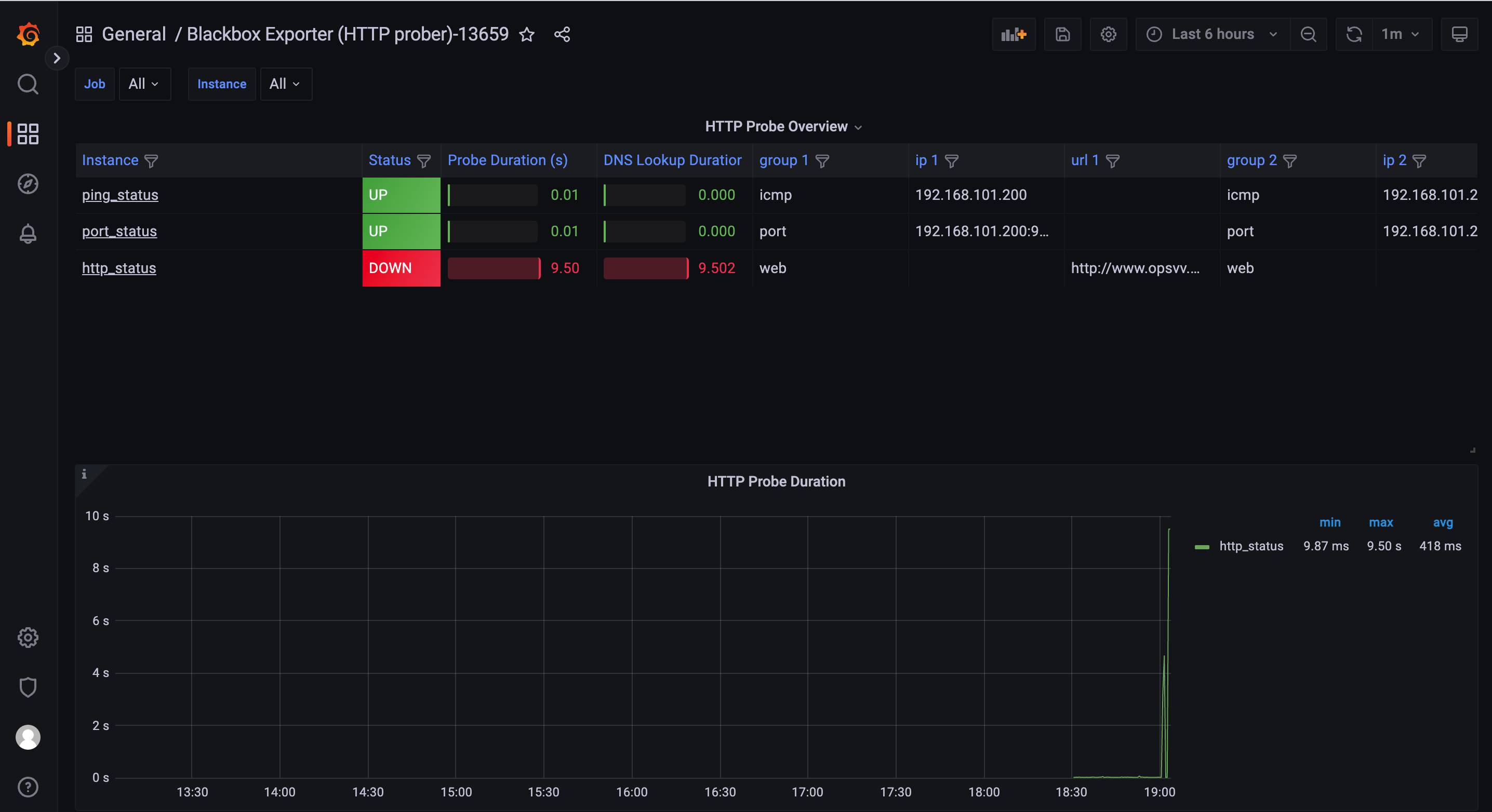
7、总结
生产中常用的exporter就介绍完了。如果有其他需求操作套路都是一样的。
1、Github找exporter 2、安装配置 3、验证数据 4、配置Grafana 模版进行微调等。
所有的操作都是经过一步一步验证,可能会有Linux操作时间和图片分秒对不上,碰到的突发问题需要排查处理,整理排版这些都花费时间。
六、 Cadvisor监控容器
cAdvisor收集Host上运行的容器信息
cAdvisor(容器顾问)让容器⽤户了解其运⾏容器的资源使⽤情况和性能状态,cAdvisor⽤于收集、聚 合、处理和导出有关正在运⾏的容器的信息,具体来说,对于每个容器都会保存资源隔离参数、历史资源使 ⽤情况、完整历史资源使⽤情况的直⽅图和⽹络统计信息,此数据按容器和机器范围导出。
1、环境准备
| 角色 | 机器IP | 映射端口 |
| cadvisor | 192.168.101.201 | 8080 |

2、安装cadvisor
注意地方
安装cadvisor一定要有root权限,可以用普通用户权限需要放行即可
2.1、导入镜像
docker load -i cadvisor.tar
2.2、启动cadvisor服务
docker 数据存储路径为/data/docker
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:ro --volume=/sys:/sys:ro --volume=/data/docker/:/data/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor --privileged --device=/dev/kmsg google/cadvisor:latest
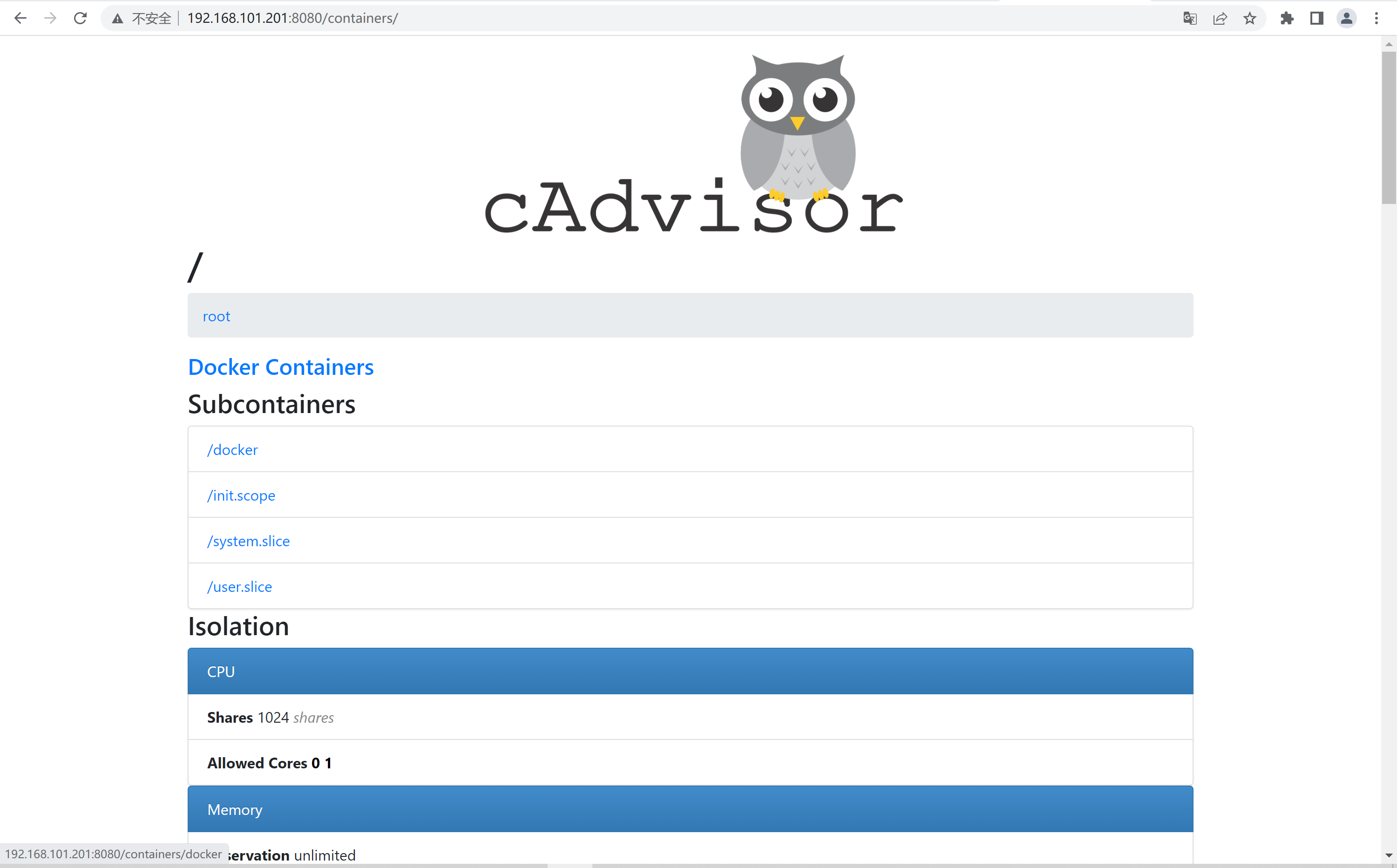
2.3、 验证cadvisor web界⾯
http://192.168.101.201:8080/containers/
验证metrics
1、增加配置文件
vim /data/prometheus/prometheus.yml
#Cadvisor
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.101.201:8080']
labels:
lable: "docker"
2、热加载prometheus
curl -X POST 192.168.101.200:9090/-/reload
3、prometheus验证Target
http://192.168.101.200:9090/targets?search=

4、Grafana配置模板
推荐模板ID:893
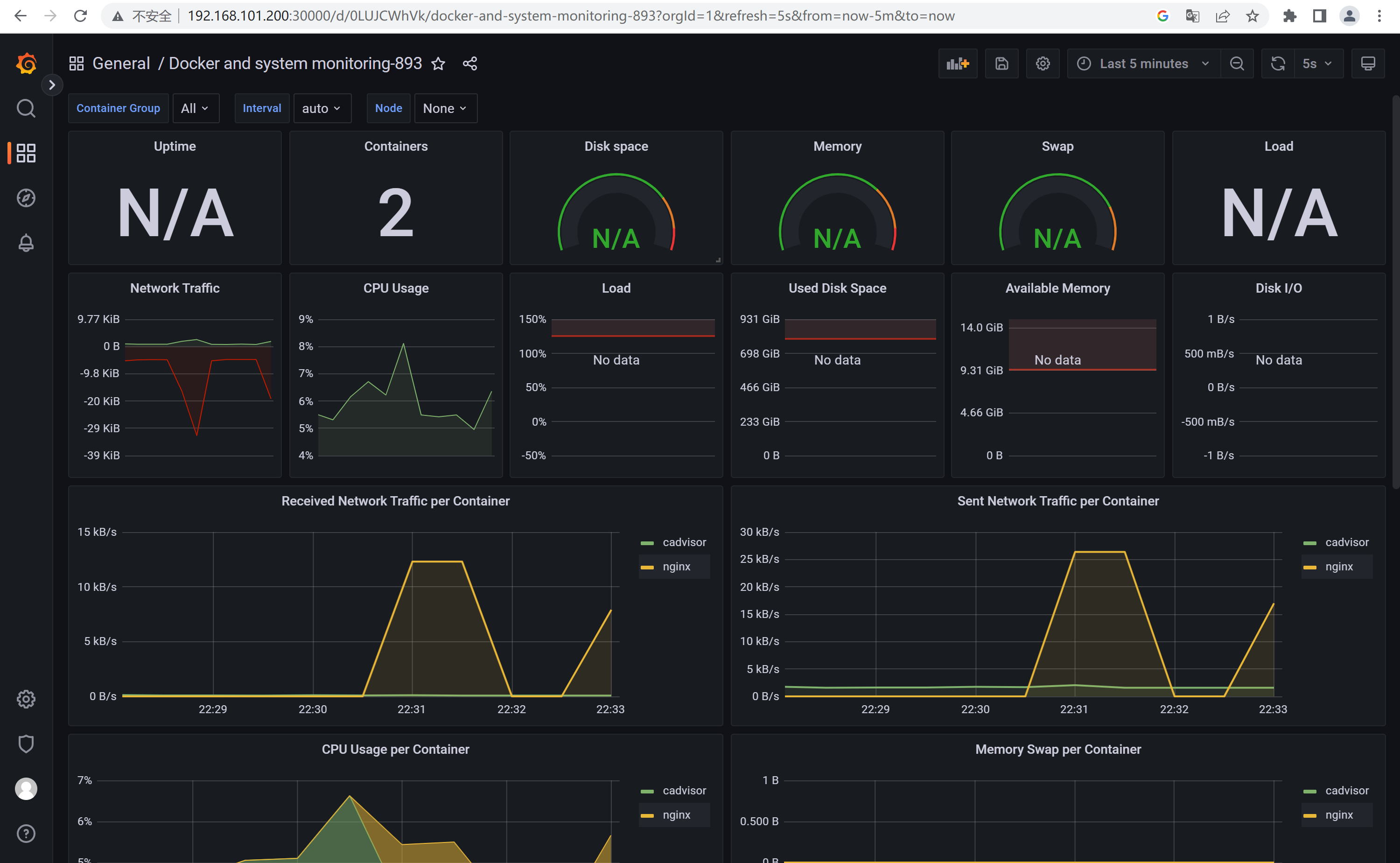
查看主机上的docker容器

七、服务发现
1、自动发现注册原因
每次增加exporter修改prometheus.yml各位估计早不耐烦了。
prometheus配置文件 prometheus.yml 里配置需要监听的服务时,是按服务名写死的,如果后面增加了节点或者组件信息,就得手动修改此配置,并重启 promethues或热加载太麻烦;那么能否动态的监听微服务呢?Prometheus 提供了多种动态服务发现的功能。
2、Consul服务发现使用
1.1、consul简介
只需要在consul中维护监控组件配置,prometheus就能够动态发现配置了。
Consul 是分布式 k/v 数据存储集群,目前常用于服务的服务注册和发现。
1.2、consul环境备注
也可以单机使用,只要保证consul不挂就行。如果consul挂了prometheus通过注册发现获取配置就都没了。
| 角色 | 机器IP | 备注 |
| consul | 192.168.101.100 | 资源有限借K8s Master |
| consul | 192.168.101.200 | prometheus server |
| consul | 192.168.101.201 | node演示各种exporter |
1.3、端口介绍
| 名称 | 端口 | 标识 | 描述 |
| Server RPC | 8300 | 用于接受来自其他 agent 的入站请求。仅 TCP。 | |
| Serf LAN | 8301 | 用于在局域网上交流。所有 agent 都依赖此。TCP 和 UDP。 | |
| Serf WAN | 8302 | -1 以禁用 (Consul 1.0.7 可用) | 用于在广域网上交流。TCP 和 UDP。 |
| HTTP API | 8500 | -1 以禁用 | 用于客户端与 HTTP API 通信。仅 TCP。 |
| DNS Interface | 8600 | -1 以禁用 |
1.4、Consul数据中心设计
一个典型的 Consul 集群包含三到五个 server 和若干 client,可以部署在一个物理的数据中心里,也可以分成多个数据中心。对于强读写的大型集群建议部署在同一个物理局域网下获取更好的性能。在云环境下,单数据中心可以跨越多个可用空间比如把每个服务分在单个主机上。Consul 还支持通过外网的多服务中心部署,其中的单个服务中心内部可能在相同的内网环境下。
1.5、部署consul集群
consul_1.13.0_solaris_amd64.zip
1.5.1、192.168.101.200 操作
1.5.2、下载安装包解压
consul安装包解压后就是一个二进制文件,建议放在 /usr/local/bin/
wget https://releases.hashicorp.com/consul/1.13.0/consul_1.13.0_linux_amd64.zip
unzip consul_1.13.0_linux_amd64.zip -d /usr/local/bin/
consul -v
1.5.3、创建数据路径
mkdir /data/consul/ -p
1.5.4、启动consul
指定master为192.168.101.200
方式一:快速验证功能
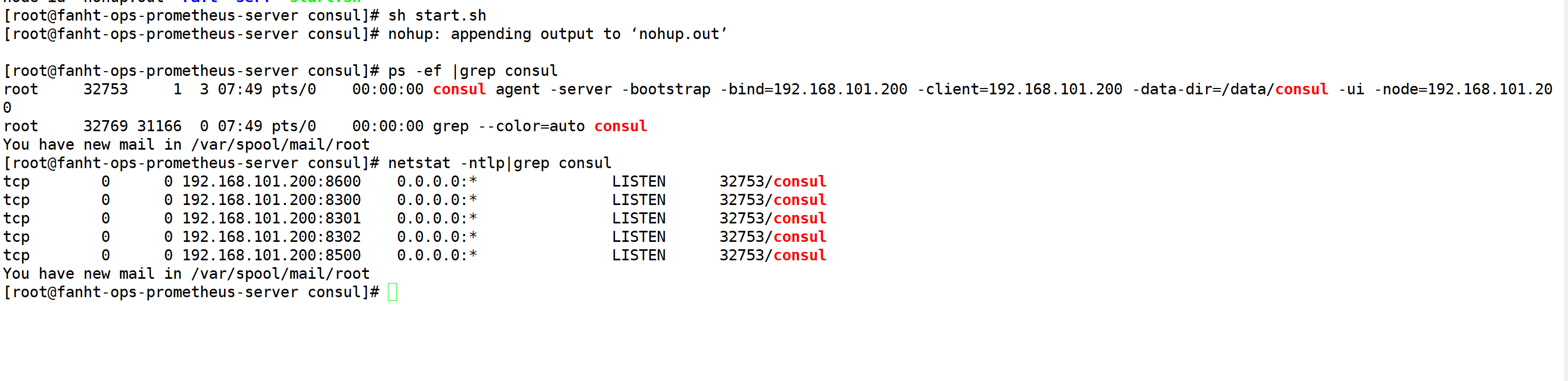
nohup consul agent -server -bootstrap -bind=192.168.101.200 -client=192.168.101.200-data-dir=/data/consul -ui -node=192.168.101.200 &
方式二:推荐
1.6、同步文件到node节点
分别创建数据目录 mkdir -p /data/consul/
拷贝consul二进制文件

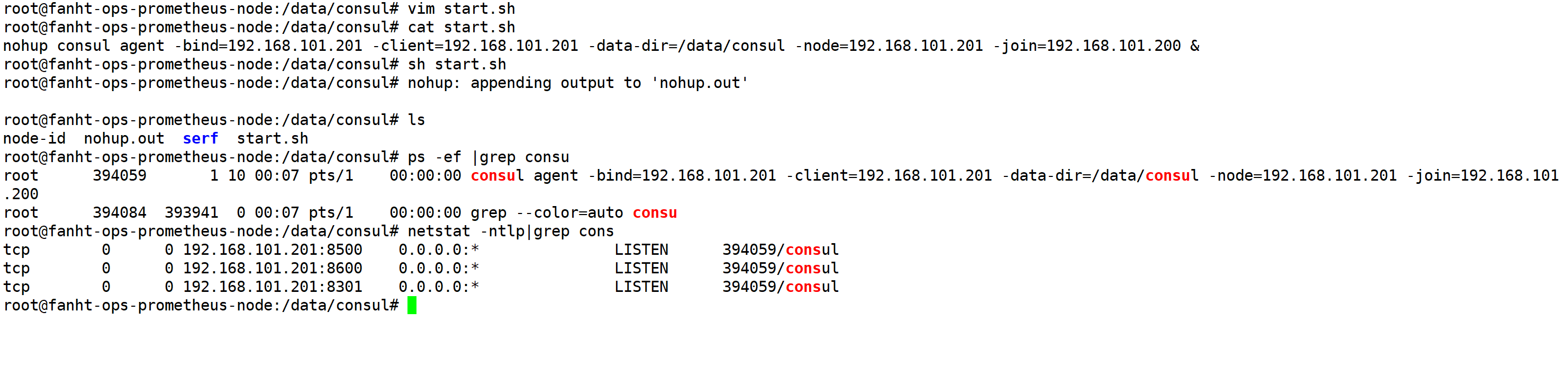
1.7、192.168.101.201 consu配置
192.168.101.201 作为node节点添加到192.168.101.200master中
mkdir -p /data/consul
cd /data/consul/
vim start.sh
nohup consul agent -bind=192.168.101.201 -client=192.168.101.201 -data-dir=/data/consul -node=192.168.101.201 -join=192.168.101.200 &
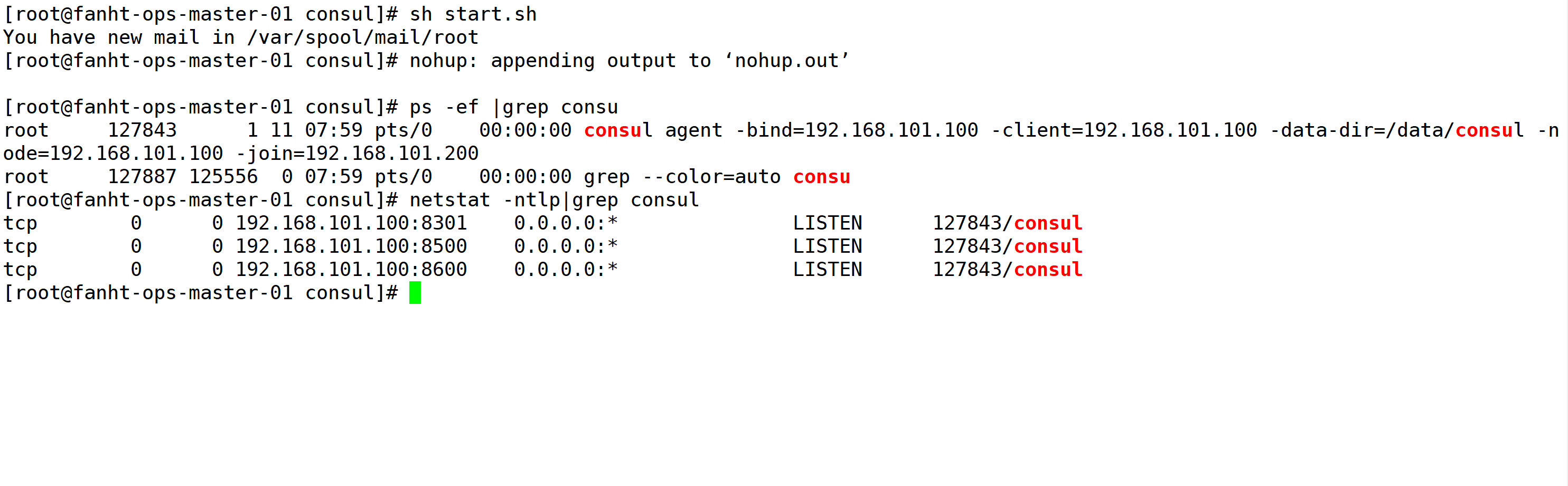
1.8、192.168.101.100配置
192.168.101.100 作为node节点添加到192.168.101.200master中
1.8.1、配置启动文件
mkdir -p /data/consul
cd /data/consul/
vim start.sh
nohup consul agent -bind=192.168.101.100 -client=192.168.101.100 -data-dir=/data/consul -node=192.168.101.100 -join=192.168.101.200 &

1.9、验证集群
集群配置完成
http://192.168.101.200:8500/ui/dc1/nodes
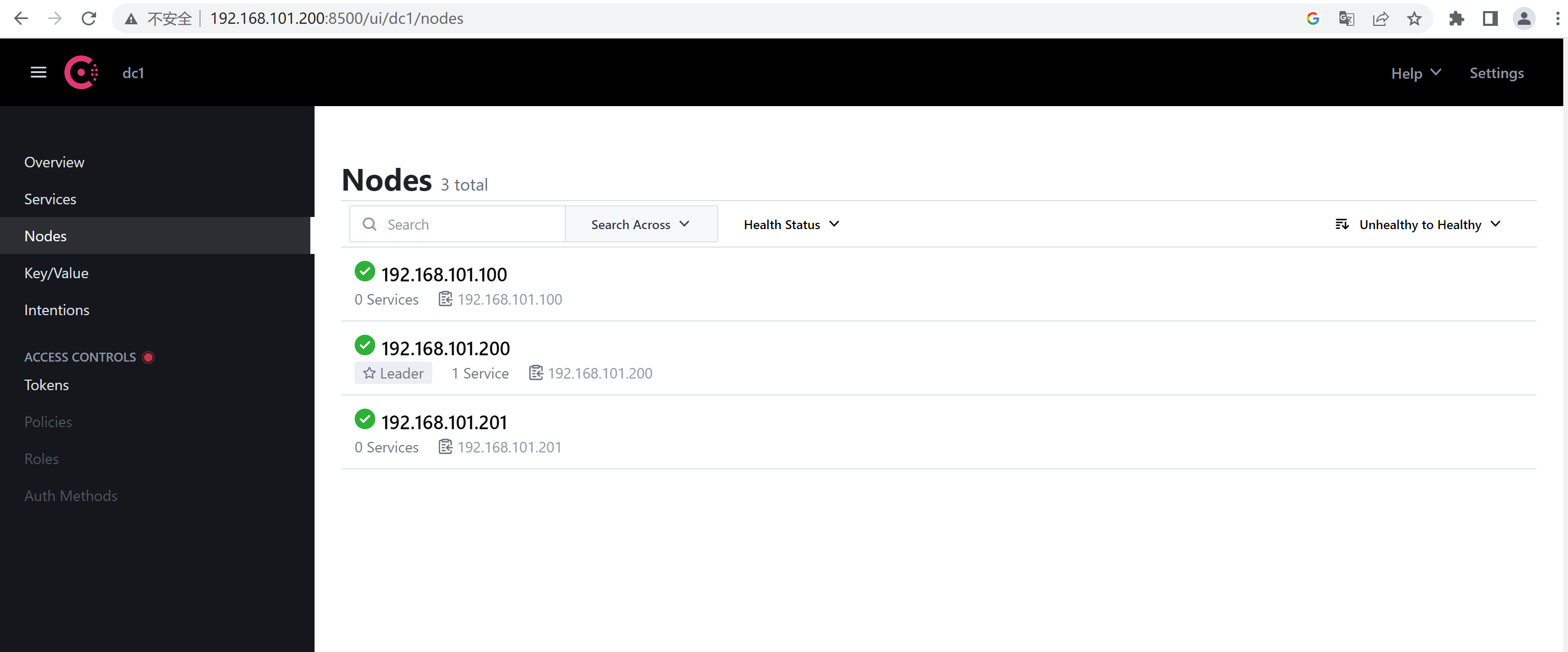
1.6、Consul使用
1.6.1、测试数据
选在了consulmaster上操作。任意机器执行,可以访问consul即可。
通过 consul 的 API 写入数据
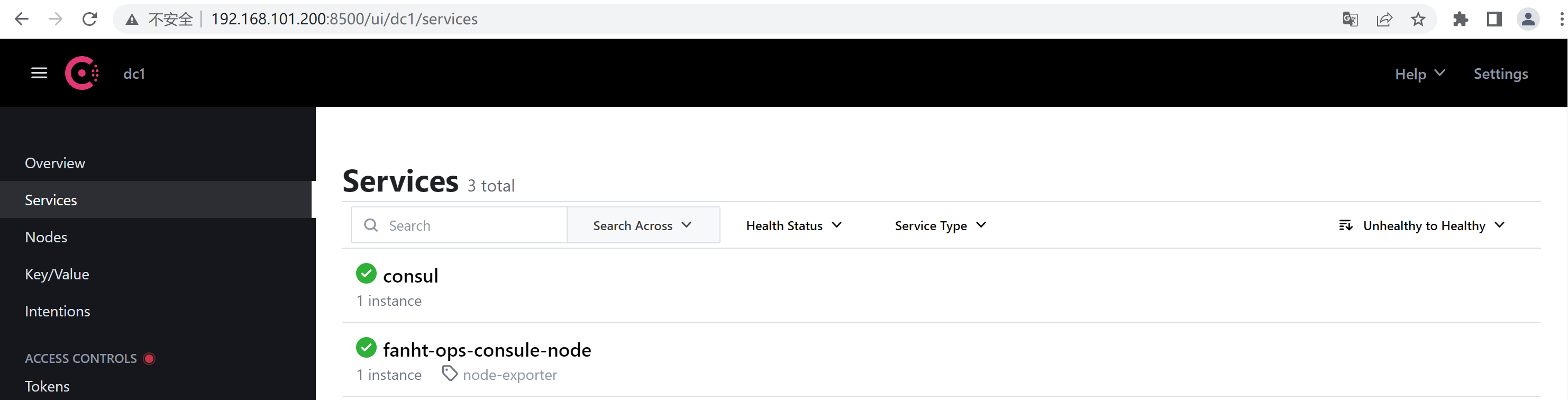
curl -X PUT -d '{"id": "fanht-ops-consule-node","name": "fanht-ops-consule-node","address": "192.168.101.200","port":9100,"tags": ["node-exporter"],"checks": [{"http": "http://192.168.101.200:9100/","interval": "5s"}]}' http://192.168.101.200:8500/v1/agent/service/register

1.6.2、consul注册验证
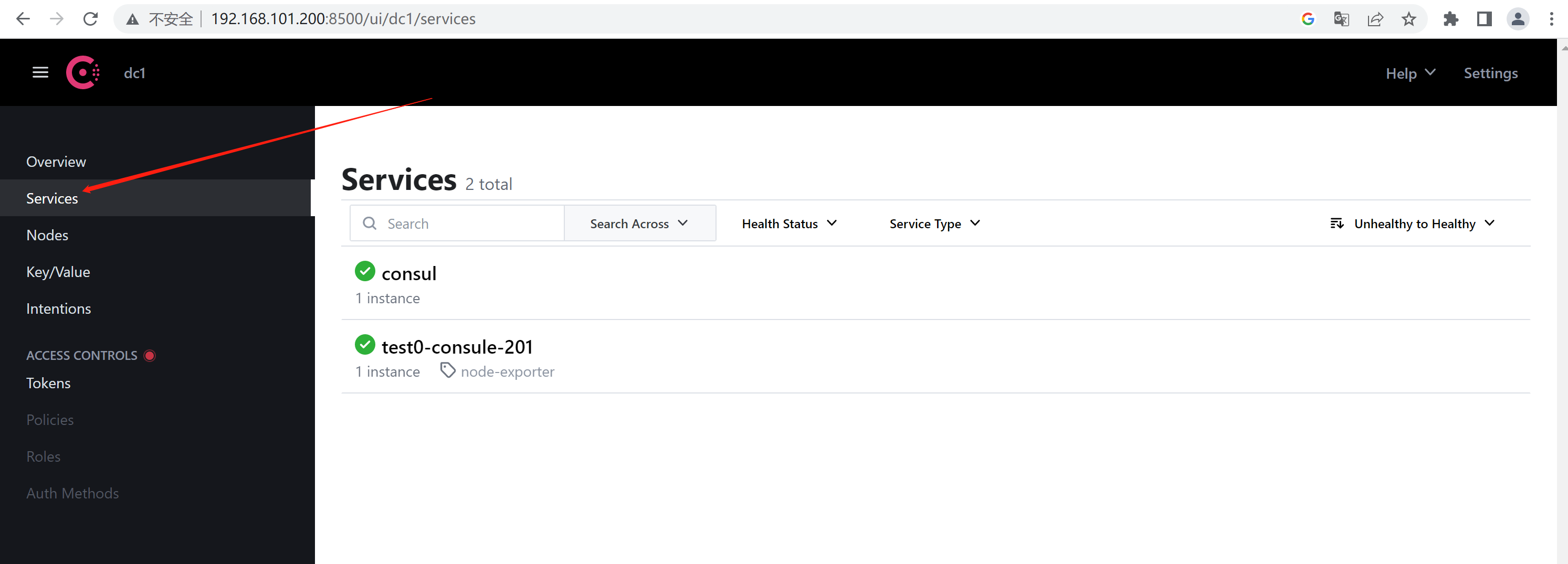
http://192.168.101.200:8500/ui/dc1/services
http://192.168.101.200:8500/ui/dc1/services
http://192.168.101.200:8500/ui/dc1/services
1.6.3、prometheus 自动发现node_exporter 示例
千万别迷路,一直在做IP备注。登录这台机器操作 192.168.101.200
1.6.3.1、prometheus增加配置文件
关键字段解释
static_configs: #配置数据源
consul_sd_configs: #指定基于 consul 服务发现的配置
rebel_configs:#重新标记
services: [] #表示匹配 consul 中所有的 service
匹配删除__meta_consul_service 为 consul 的发现结果:- source_labels: ['__meta_consul_service'] regex: "consul" action: drop
jobname跟consule中对应上
添加node_exporter jobname
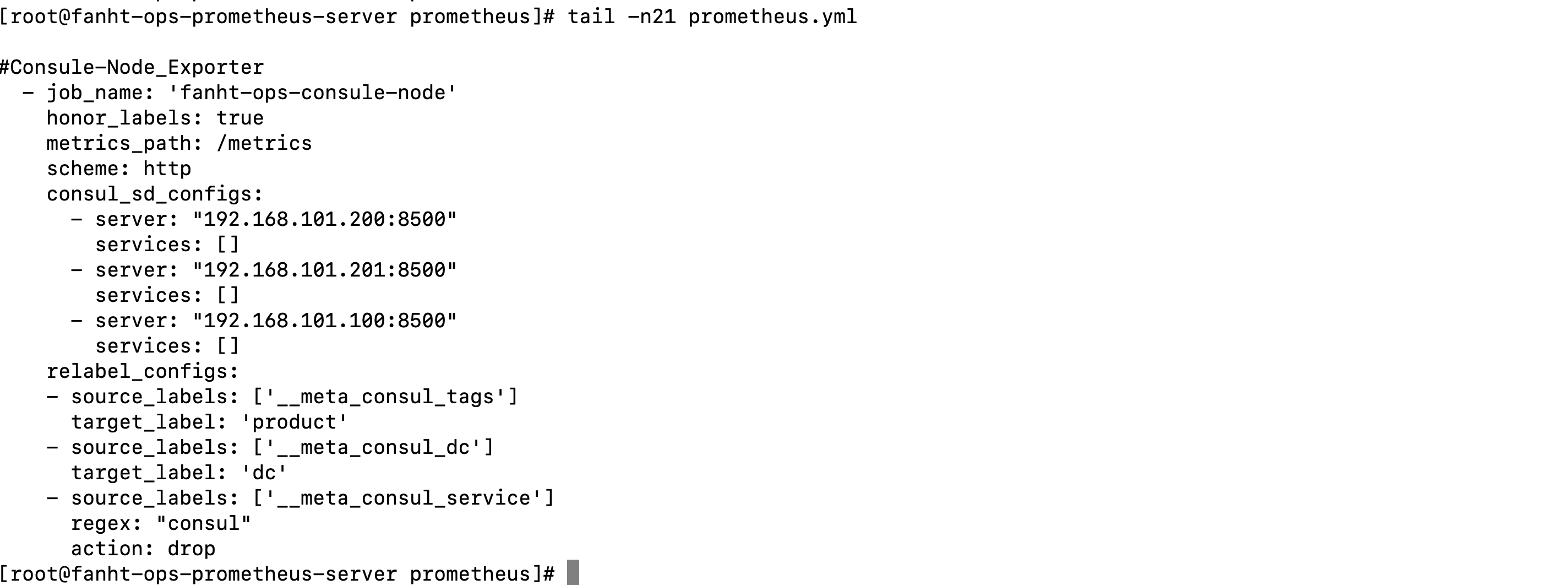
#Consule-Node_Exporter
- job_name: 'fanht-ops-consule-node'
honor_labels: true
metrics_path: /metrics
scheme: http
consul_sd_configs:
- server: "192.168.101.200:8500"
services: [fanht-ops-consule-node]
- server: "192.168.101.201:8500"
services: [fanht-ops-consule-node]
- server: "192.168.101.100:8500"
services: [fanht-ops-consule-node]
relabel_configs:
- source_labels: ['__meta_consul_tags']
target_label: 'product'
- source_labels: ['__meta_consul_dc']
target_label: 'dc'
- source_labels: ['__meta_consul_service']
regex: "consul"
action: drop
1.6.3.1、prometheus热加载
curl -X POST 192.168.101.200:9090/-/reload
1.6.3.2、prometheus 验证Target

1.6.3.3、grafana验证
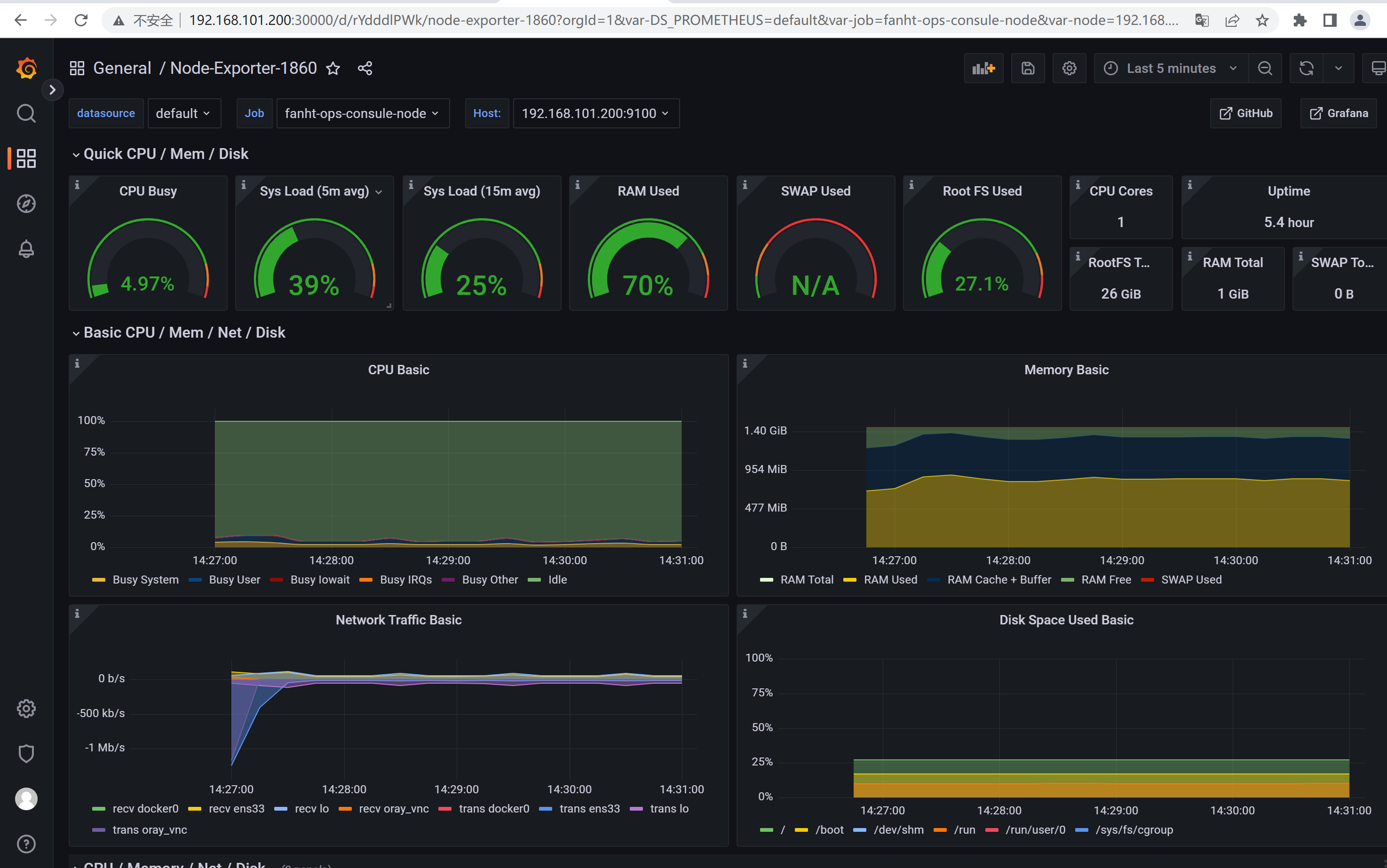
1.6.4、Prometheus自动发现Blackbox
1.6.4.1、Consul写入数据
curl -X PUT -d '{"id": "fanht-ops-consule-blackbox","name": "fanht-ops-consule-blackbox","address": "192.168.101.201","port":9115,"tags": ["blackbox"],"checks": [{"http": "http://192.168.101.201:9115/","interval": "5s"}]}' http://192.168.101.200:8500/v1/agent/service/register

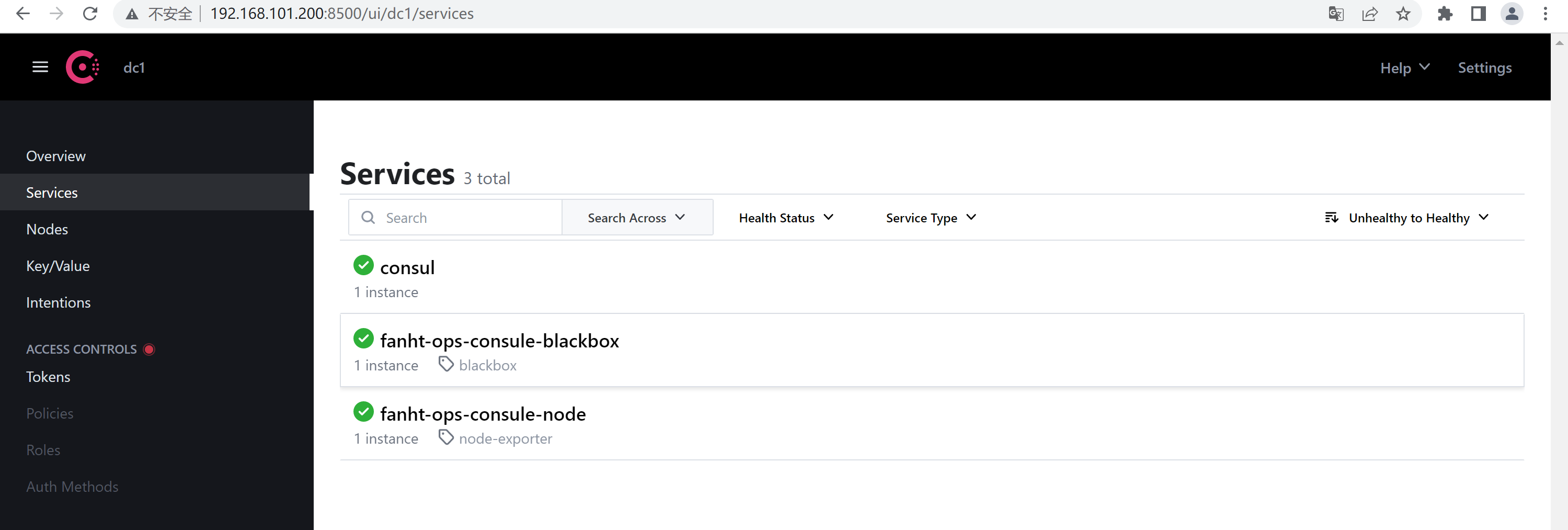
1.6.4.2、prometheus收集数据
#Consule-Blackbox
- job_name: 'fanht-ops-consule-blackbox'
metrics_path: /probe
params:
module: [tcp_connect]
scrape_interval: 15s
consul_sd_configs:
- server: "192.168.101.200:8500"
services: [fanht-ops-consule-blackbox] ##发现的目标服务名称,空为所有服务,可以写 servicea,servcieb,servicec
- server: "192.168.101.201:8500"
services: [fanht-ops-consule-blackbox]
- server: "192.168.101.100:8500"
services: [fanht-ops-consule-blackbox]
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
#- target_label: __address__
#replacement: 192.168.101.201:9115 #blackbox 安装的机器
- source_labels: [__meta_consul_service_metadata_cluster]
target_label: cluster
- source_labels: [__meta_consul_service_metadata_app]
target_label: app
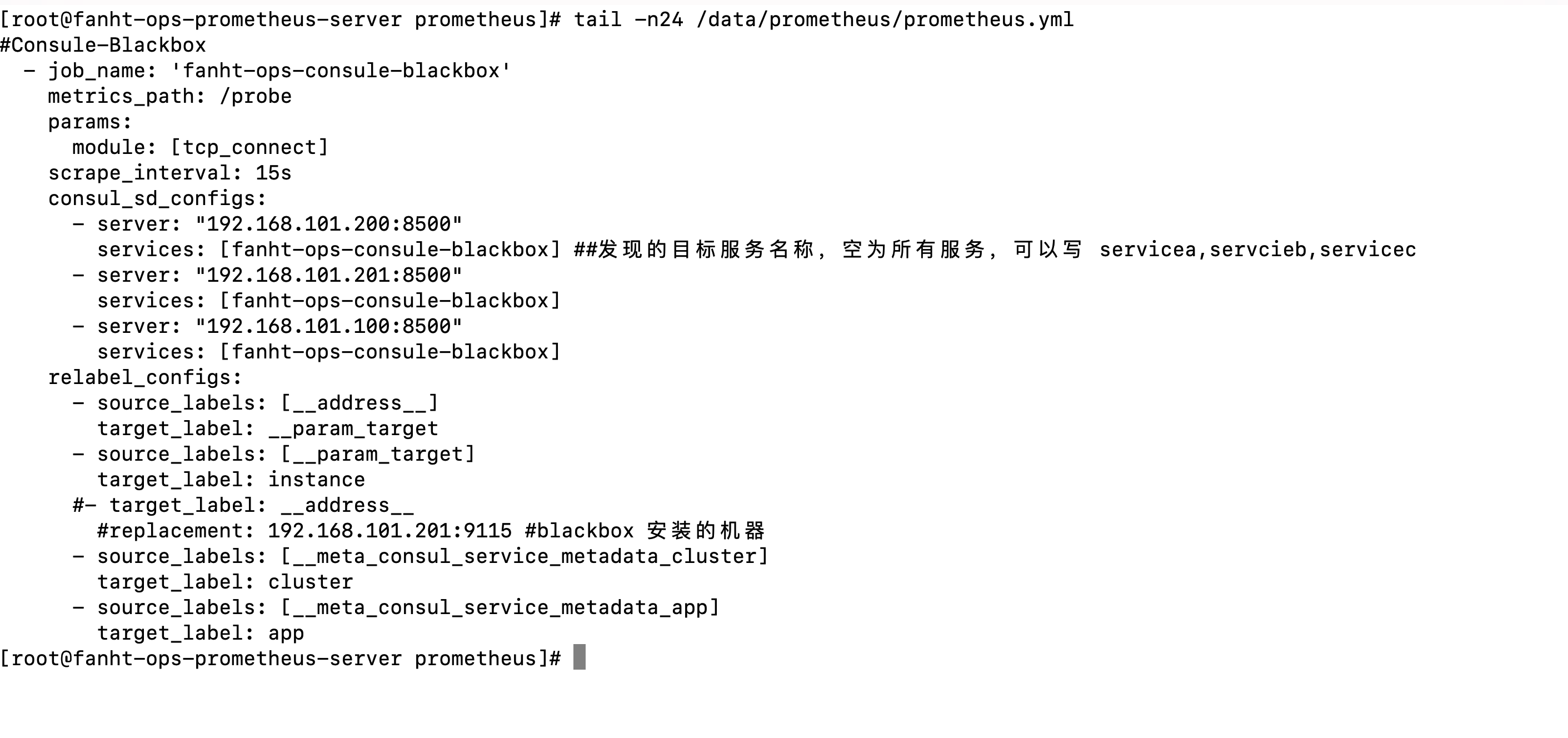
1.6.4.3、热加载配置
curl -X POST 192.168.101.200:9090/-/reload
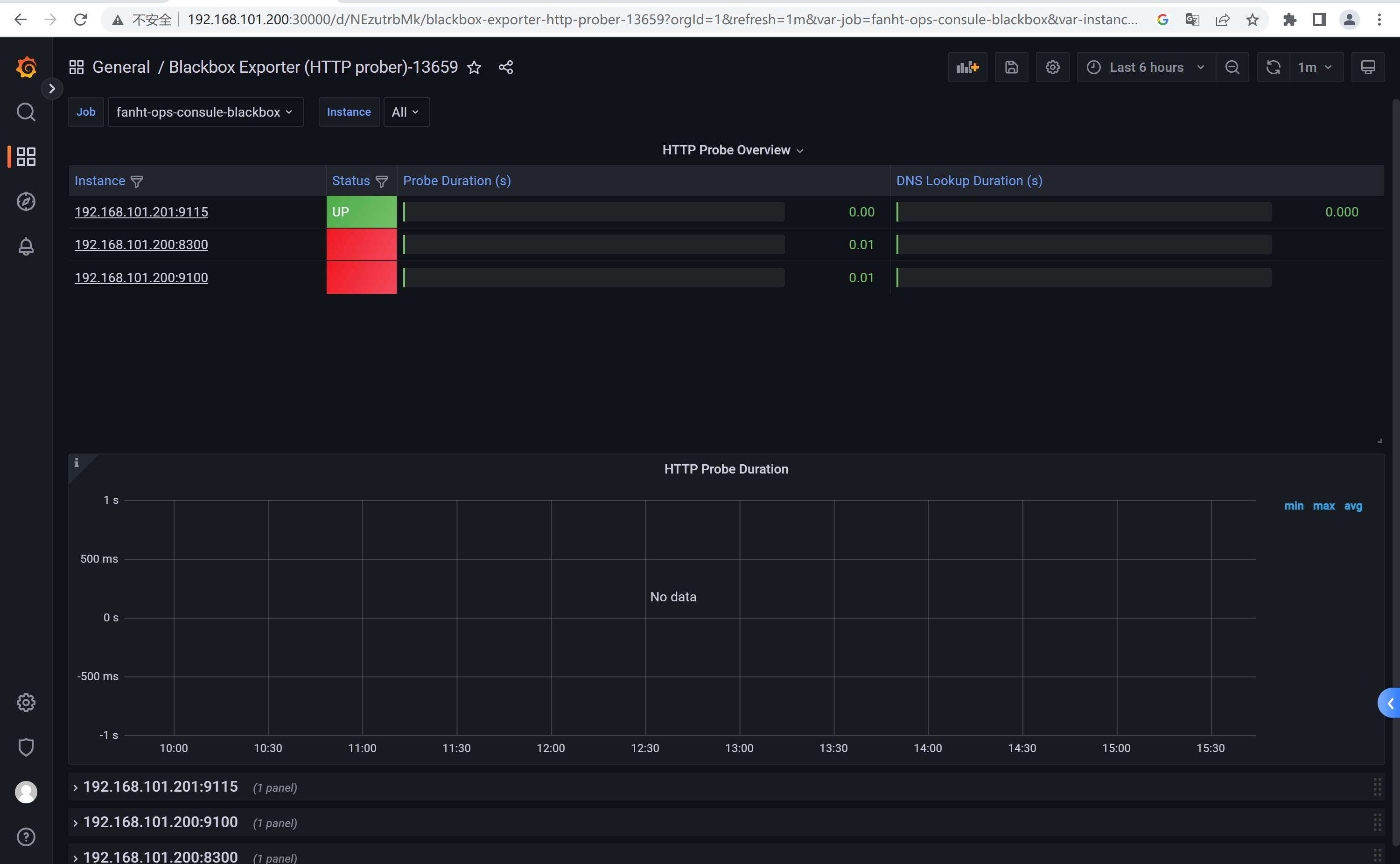
1.6.4.4、prometheus 验证Target

1.6.4.5、grafana配置
1.6.5、consul 删除注册过Target
curl --request PUT http://192.168.101.200:8500/v1/agent/service/deregister/ops-fanht-consul-node

验证
1.6.5、consul 删除集群节点(仅限了解)
curl -X PUT http://192.168.101.200:8500/v1/agent/service/deregister/192.168.101.100
3、prometheus文件发现
作为扩展了解,有了consul文件发现使用不多了。
1、编辑 sd_configs 文件
mkdir -p /data/prometheus/file_sd/
vim /data/prometheus/file_sd/sd_node_exporter.json
[
{ "targets": ["192.168.101.200:9100","192.168.101.201:9100"]
}
]
2、prometheus 调用 sd_configs
#file_sd_config
- job_name: 'file_sd_node_exporter'
file_sd_configs:
- files:
- /data/prometheus/file_sd/sd_node_exporter.json
refresh_interval: 10s

3、prometheus 验证Target

4、配置文件发现总结
1、配置文件自动发现配置完成
2、同一类业务exporter使用一个json文件来存储,不同业务使用json区分。
4、DNS A记录服务发现
IP地址发生变化后使用dns发现,不用修改配置文件。
基于 DNS 的服务发现允许配置指定一组 DNS 域名,这些域名会定期查询以发现目标列表,域名需要可以被配置的 DNS 服务器解析为 IP。 此服务发现方法仅支持基本的 DNS A、AAAA 和 SRV 记录查询。 A 记录: 域名解析为 IP
prometheus 会对收集的指标数据进行重新打标,重新标记期间,可以使用以下元标签:__meta_dns_name:产生发现目标的记录名称。 __meta_dns_srv_record_target: SRV 记录的目标字段 __meta_dns_srv_record_port: SRV 记录的端口字段。
| 域名 | IP |
| www.opsvv.com | 192.168.101.201 |
4.1、配置DNS服务发现
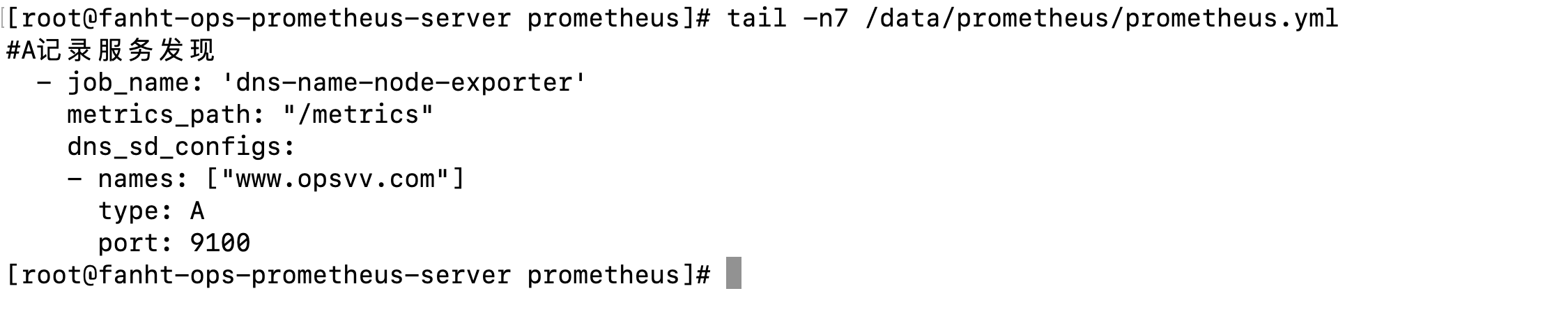
#A记录服务发现
- job_name: 'dns-name-node-exporter'
metrics_path: "/metrics"
dns_sd_configs:
- names: ["www.opsvv.com"]
type: A
port: 9100
4.2、prometheus 热加载
curl -X POST 192.168.101.200:9090/-/reload
4.3、prometheus 验证Target

八、告警通知Alertmanager
Alertmanager是Prometheus监控系统的一个组件,它负责接收Prometheus发出的报警信息,并将报警信息转发给适当的接收人或系统
prometheus 触发告警过程
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--->邮件|钉钉|飞书等。
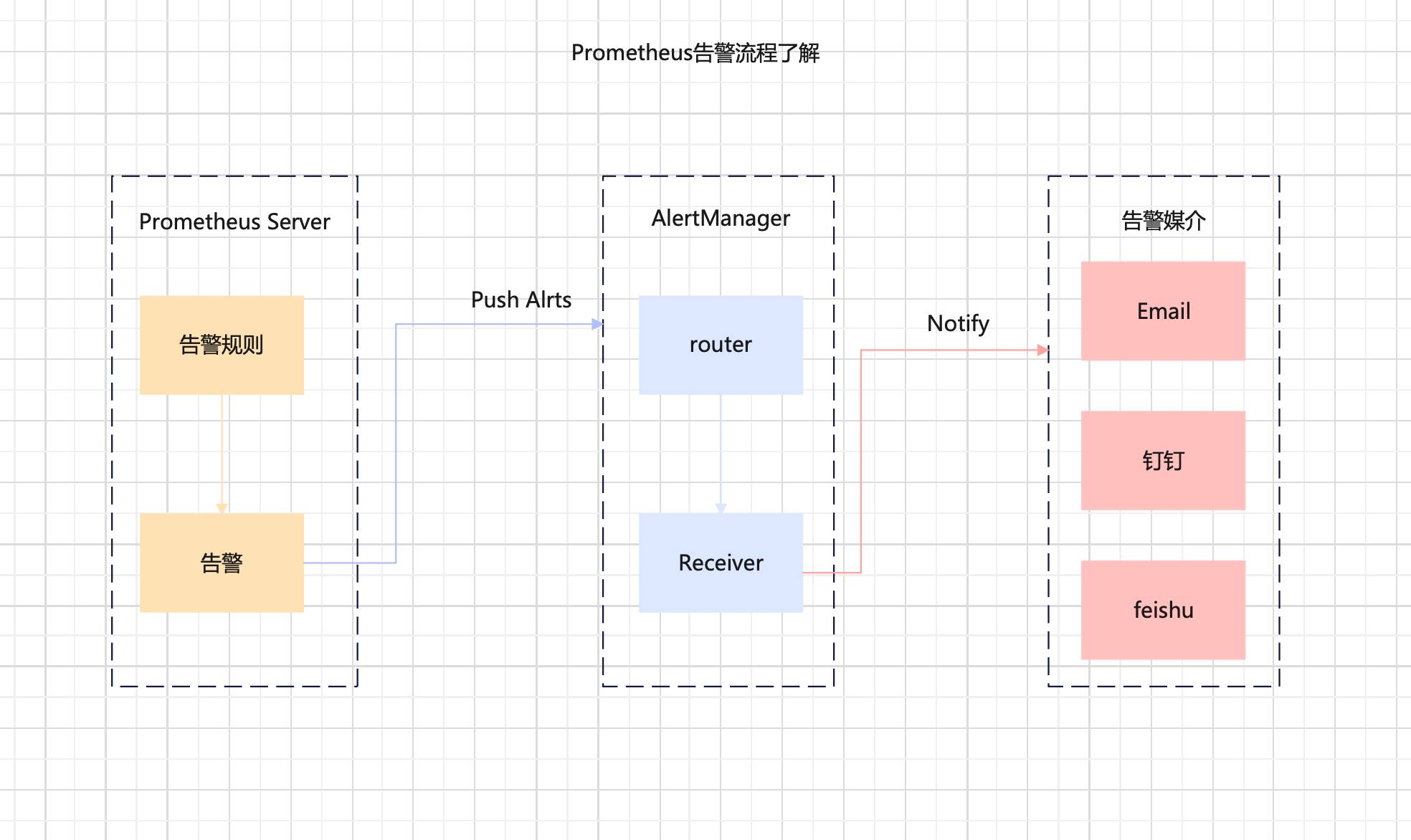
分组(group):
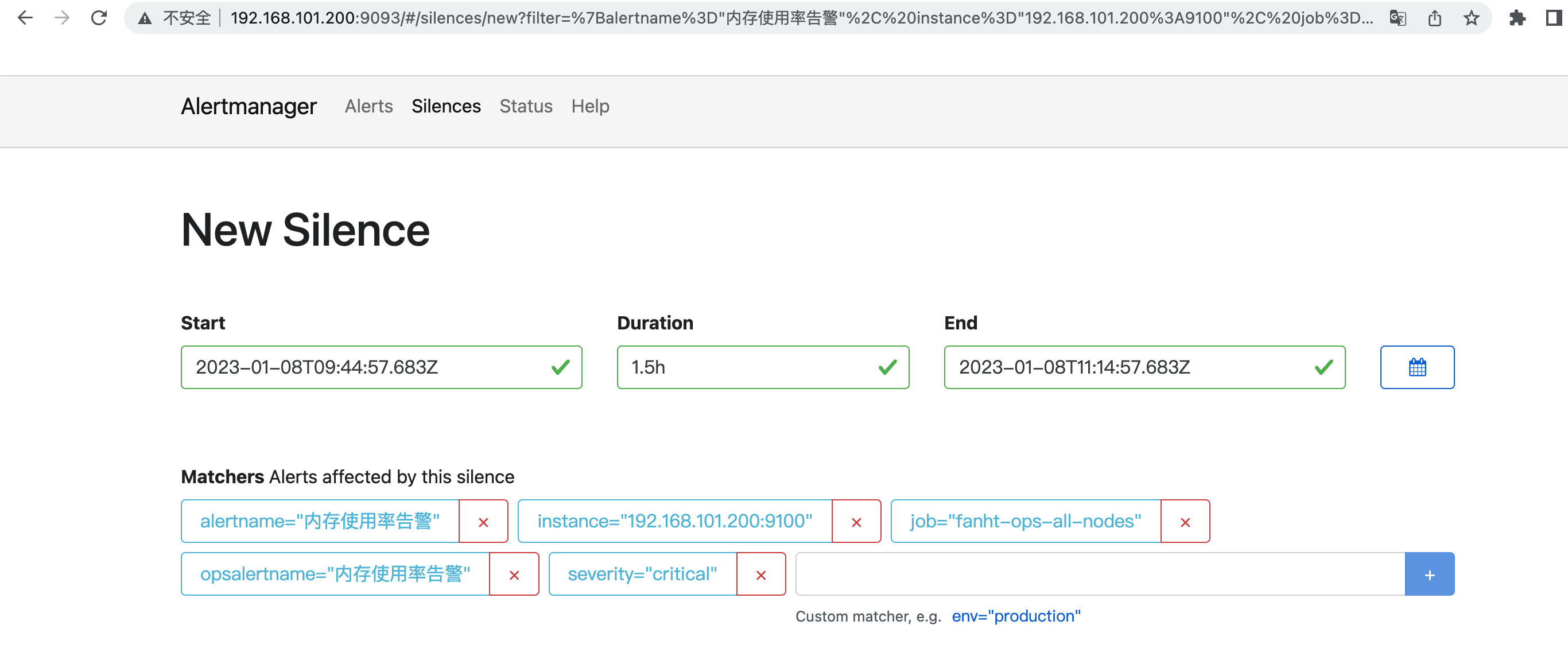
将类似性质的警报合并为单个通知,比如网络通知、主机通知、服务通知。静默(silences): 是一种简单的特定时间静音的机制,例如:服务器要升级维护可以先设置这个时间段告警
静默:
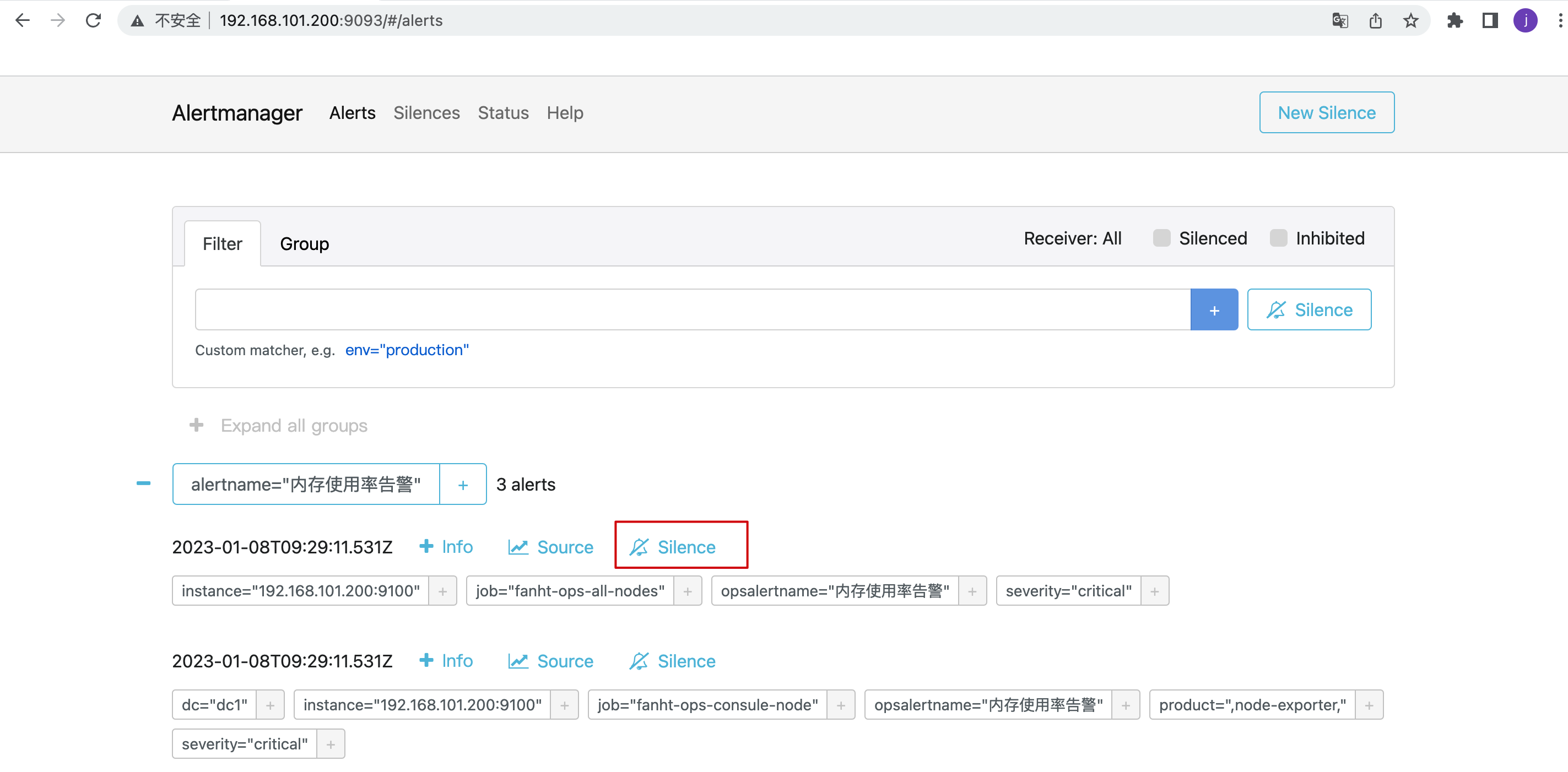
抑制(inhibition): 当警报发出后,停止重复发送由此警报引发的其他警报即合并一个故障引起的多个报警事件,可以消除冗余告警
| 角色 | 机器 | 服务端口 |
| Alermanager | 192.168.101.200(prometheus server) | |
1、安装配置alertmanger
1.1、准备环境
使用次新稳定版本
alertmanager-0.24.0.linux-amd64.tar.gz

1.2、安装Alertmanager
解压创建软连接
tar -xf alertmanager-0.24.0.linux-amd64.tar.gz -C /data/
cd /data/
ln -sv alertmanager-0.24.0.linux-amd64/ alertmanager

1.3、服务系统启动
vim /usr/lib/systemd/system/alertmanager.service
[Unit] Description=alertmanager.service [Service] ExecStart=/data/alertmanager/alertmanager --config.file=/data/alertmanager/alertmanager.yml Restart=on-failure [Install] WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable alertmanager
systemctl start alertmanager
ps -ef |grep alertmanager
netstat -ntlp|grep alert

2、prometheus告警配置
2.1、添加告警规则
groups:
- name: node_exporter
rules:
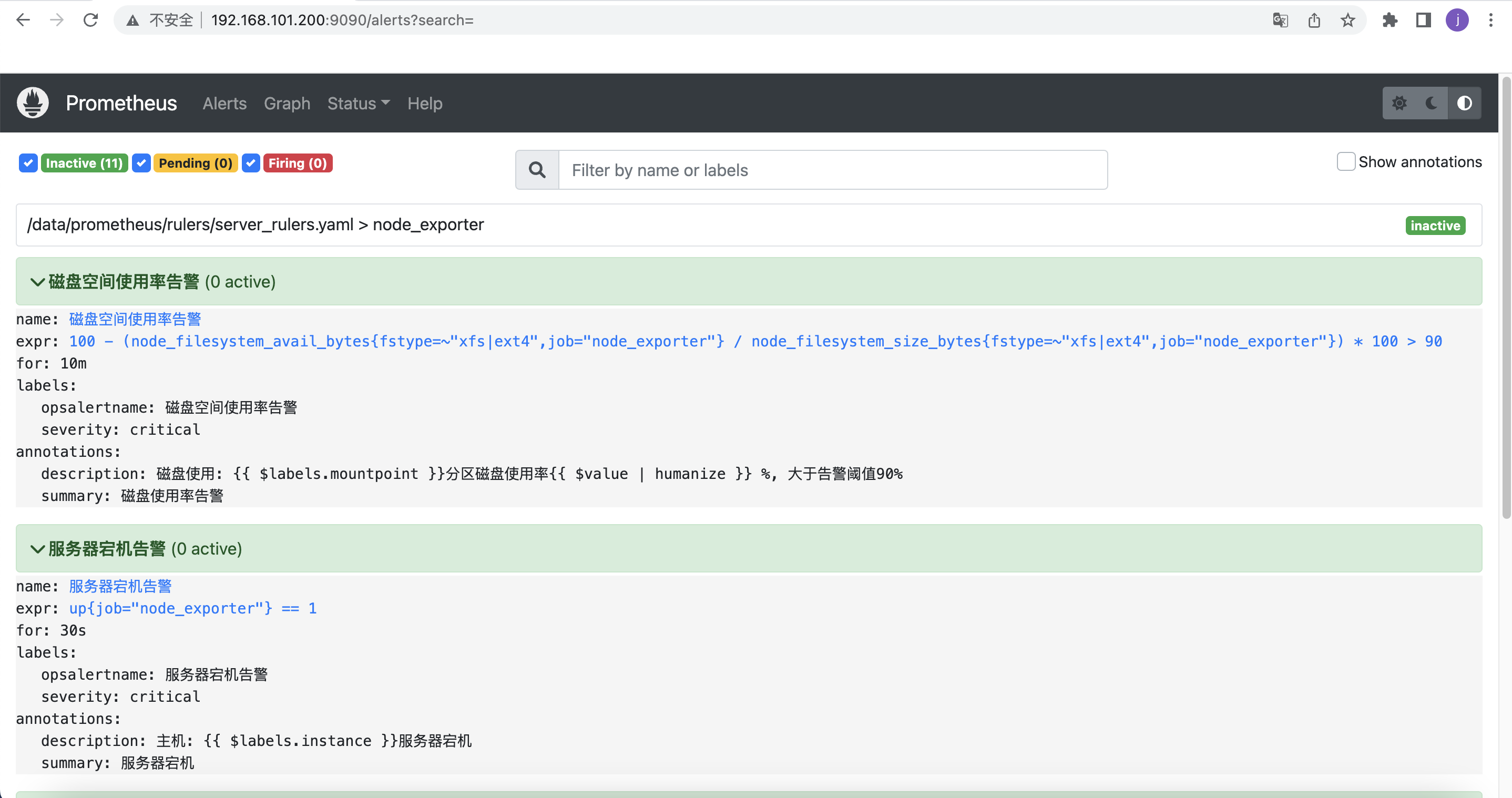
- alert: 磁盘空间使用率告警
expr: 100
- (node_filesystem_avail_bytes{fstype=~"xfs|ext4",job="node_exporter"}
/ node_filesystem_size_bytes{fstype=~"xfs|ext4",job="node_exporter"}) * 100
> 90
for: 10m
labels:
severity: critical
opsalertname: 磁盘空间使用率告警
annotations:
summary: '磁盘使用率告警'
description: |
磁盘使用: {{ $labels.mountpoint }}分区磁盘使用率{{ $value | humanize }} %, 大于告警阈值90%
- alert: 服务器宕机告警
expr: up{job="node_exporter"} == 1 #正确应该为0,为了测试告警通知是否生效
for: 30s
labels:
severity: critical
opsalertname: 服务器宕机告警
annotations:
summary: '服务器宕机'
description: |
主机: {{ $labels.instance }}服务器宕机
- alert: 磁盘inode使用率告警
expr: 100 - (node_filesystem_files_free{job="node_exporter",fstype=~"ext4|xfs"} / node_filesystem_files{job="node_exporter",fstype=~"ext4|xfs"}) * 100 > 80
for: 15m
labels:
severity: critical
opsalertname: 磁盘inode使用率告警
annotations:
summary: "磁盘Inode告警"
description: |
Inode使用: {{ $value | humanize }} %, 大于告警阈值80%
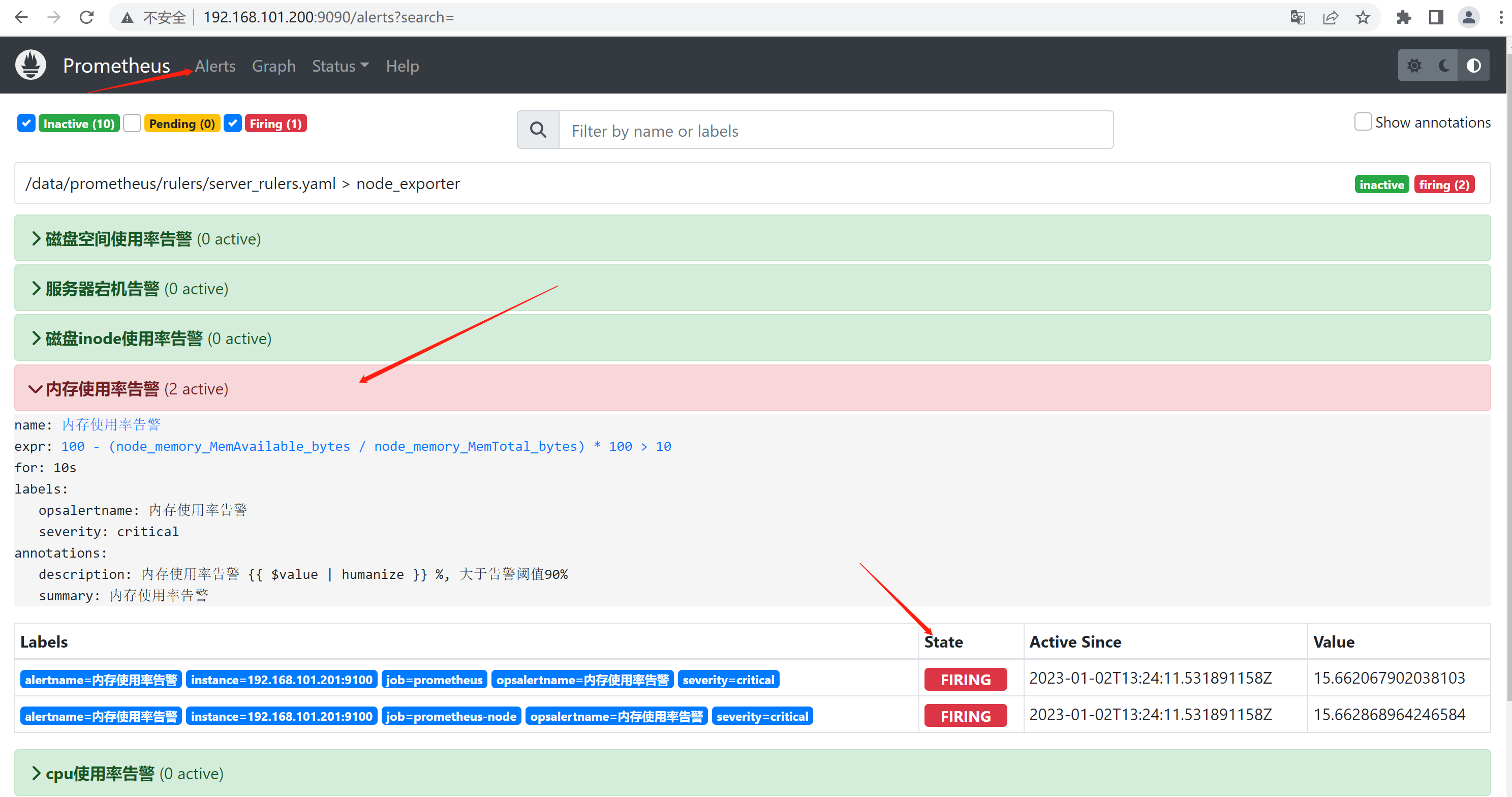
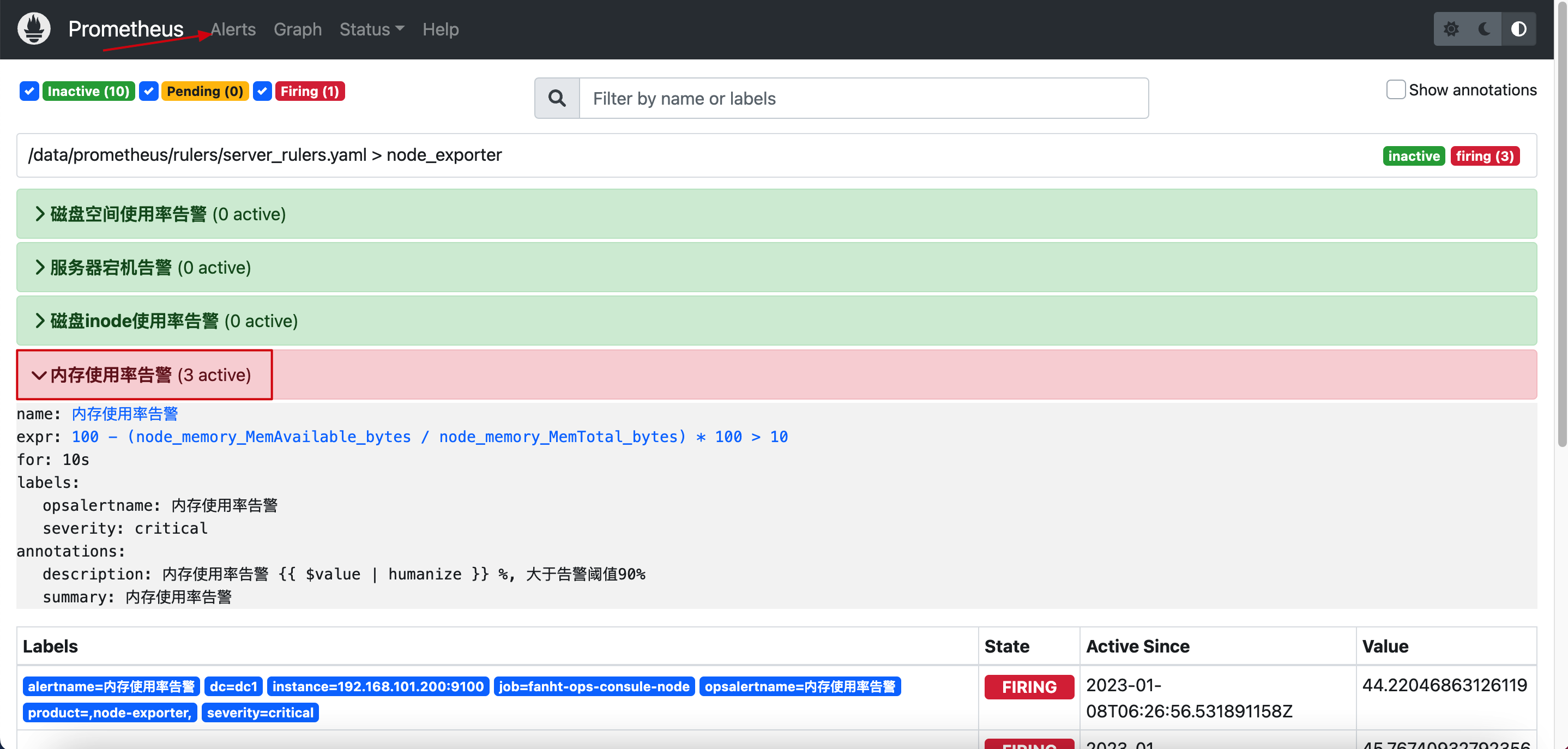
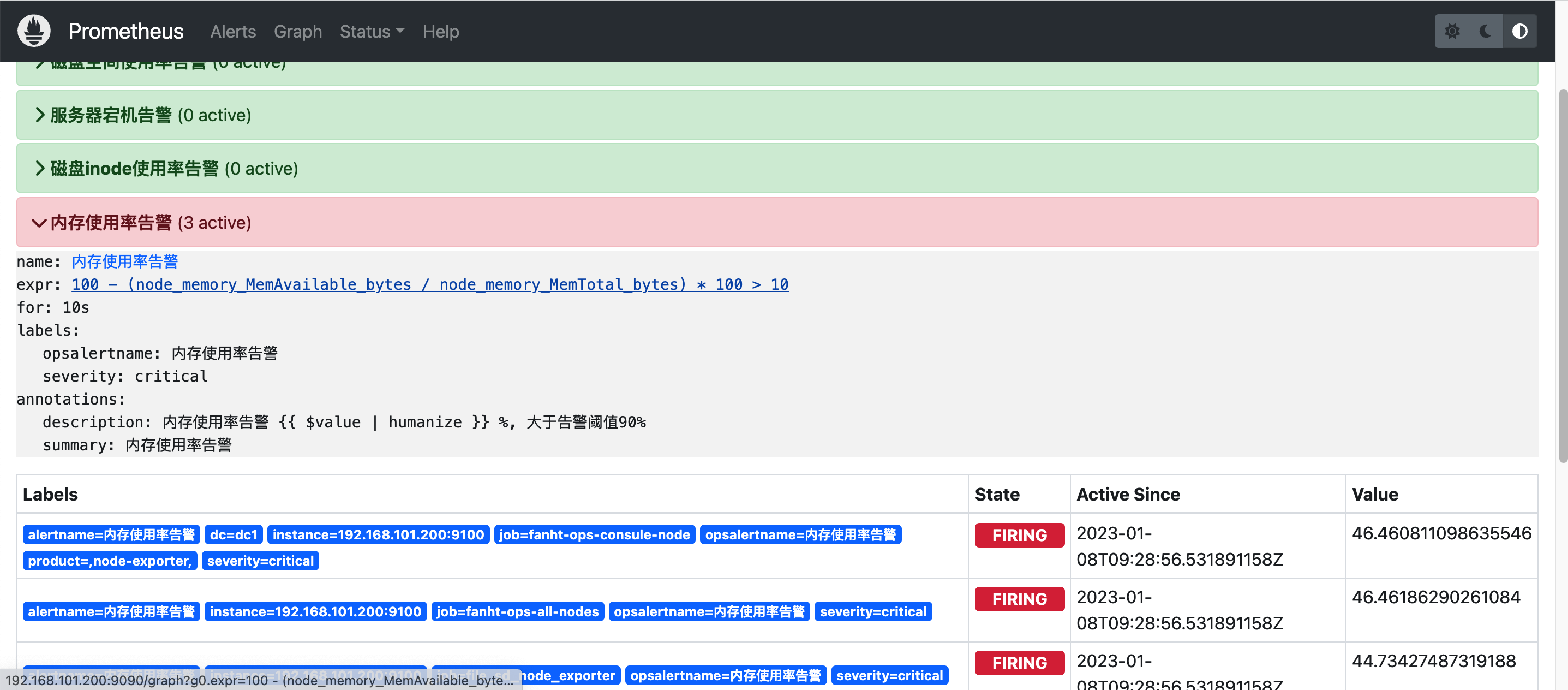
- alert: 内存使用率告警
expr: 100 - ( node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes ) * 100 > 10 # 正常值为90,为了测试告警信息
for: 10s #正常值为5m
labels:
severity: critical
opsalertname: 内存使用率告警
annotations:
summary: '内存使用率告警'
description: |
内存使用率告警 {{ $value | humanize }} %, 大于告警阈值90%
#更多规则参考上面配置

2.2、prometheus加载报警规则
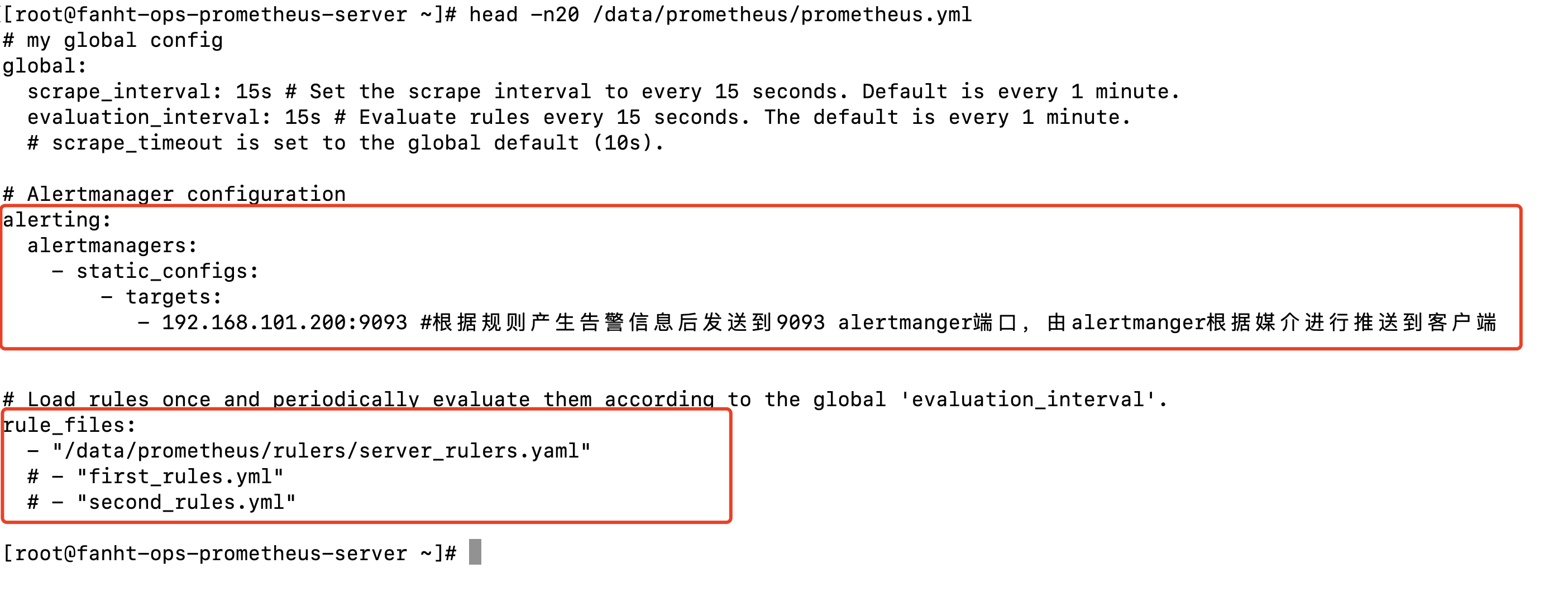
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.101.200:9093 #根据规则产生告警信息后发送到9093 alertmanger端口,由alertmanger根据媒介进行推送到客户端
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/data/prometheus/rulers/server_rulers.yaml"
2.3、规则验证
/data/prometheus/promtool check rules /data/prometheus/rulers/server_rulers.yaml c

2.4、prometheus热加载
curl -X POST 192.168.101.200:9090/-/reload

2.5、prometheus前端验证
http://192.168.101.200:9090/alerts?search=
3、AlerManager配置告警媒介
3.1、邮件告警
3.1.1、邮箱使用授权码
3.1.2、alertmanager配置
cat /data/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'notice9527@163.com' #发件人邮箱地址 smtp_smarthost: #邮箱 smtp 地址。 smtp_auth_username: #发件人的登陆用户名,默认和发件人地址一致。 smtp_auth_password: #发件人的登陆密码,有时候是授权码。 smtp_require_tls: #是否需要 tls 协议。默认是 true。
smtp_auth_username: 'notice9527@163.com'
smtp_auth_password: '你的密码'
smtp_hello: '@163.com'
smtp_require_tls: false
route:
group_by: [alertname] #通过 alertname 的值对告警进行分类,- alert: 物理节点 cpu 使用率group_wait: 10s #一组告警第一次发送之前等待的延迟时间,即产生告警后延迟 10 秒钟将组内新产生的消息一起合并发送(一般设置为 0 秒 ~ 几分钟)。
group_wait: 10s #一组告警第一次发送之前等待的延迟时间,即产生告警后延迟 10 秒钟将组内新产生的消息一起合并发送(一般设置为 0 秒 ~ 几分钟)。
group_interval: 2m #一组已发送过初始通知的告警接收到新告警后,下次发送通知前等待的延迟时间(一般设置为 5 分钟或更多)。
repeat_interval: 5m #一条成功发送的告警,在最终发送通知之前等待的时间(通常设置为3 小时或更长时间)。
receiver: 'email-receiver'
#间隔示例:
#group_wait: 10s #第一次产生告警,等待 10s,组内有告警就一起发出,没有其它告警就单独发出。
#group_interval: 2m #第二次产生告警,先等待 2 分钟,2 分钟后还没有恢复就进入repeat_interval。
#repeat_interval: 5m #在最终发送消息前再等待 5 分钟,5 分钟后还没有恢复就发送第二次告警。
#定义告警接收媒介信息
receivers: #定义多接收者
- name: 'email-receiver' #其它的告警发送给 default-receiver
email_configs:
- to: 'ms95270@163.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
3.1.3、验证告警,手动触发
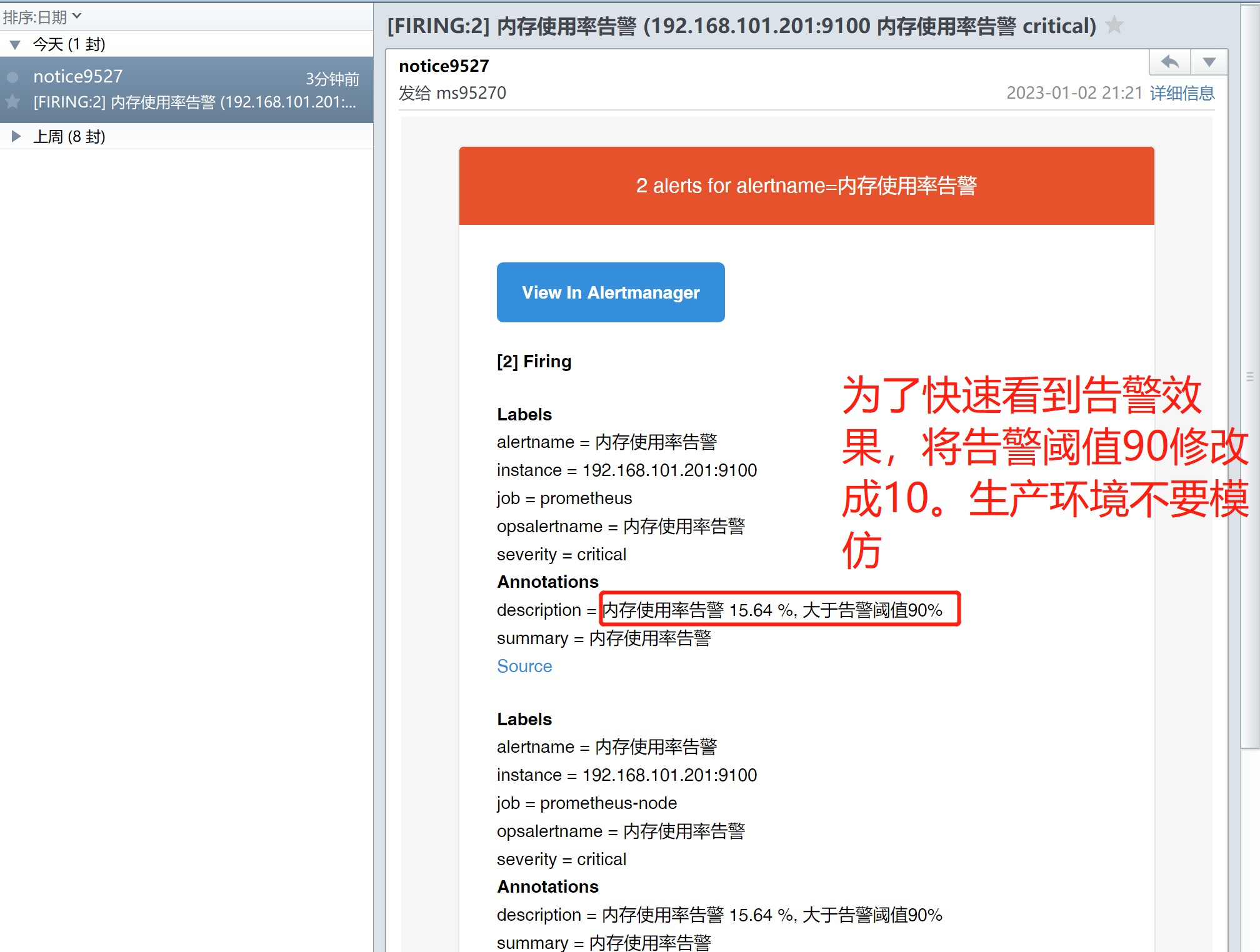
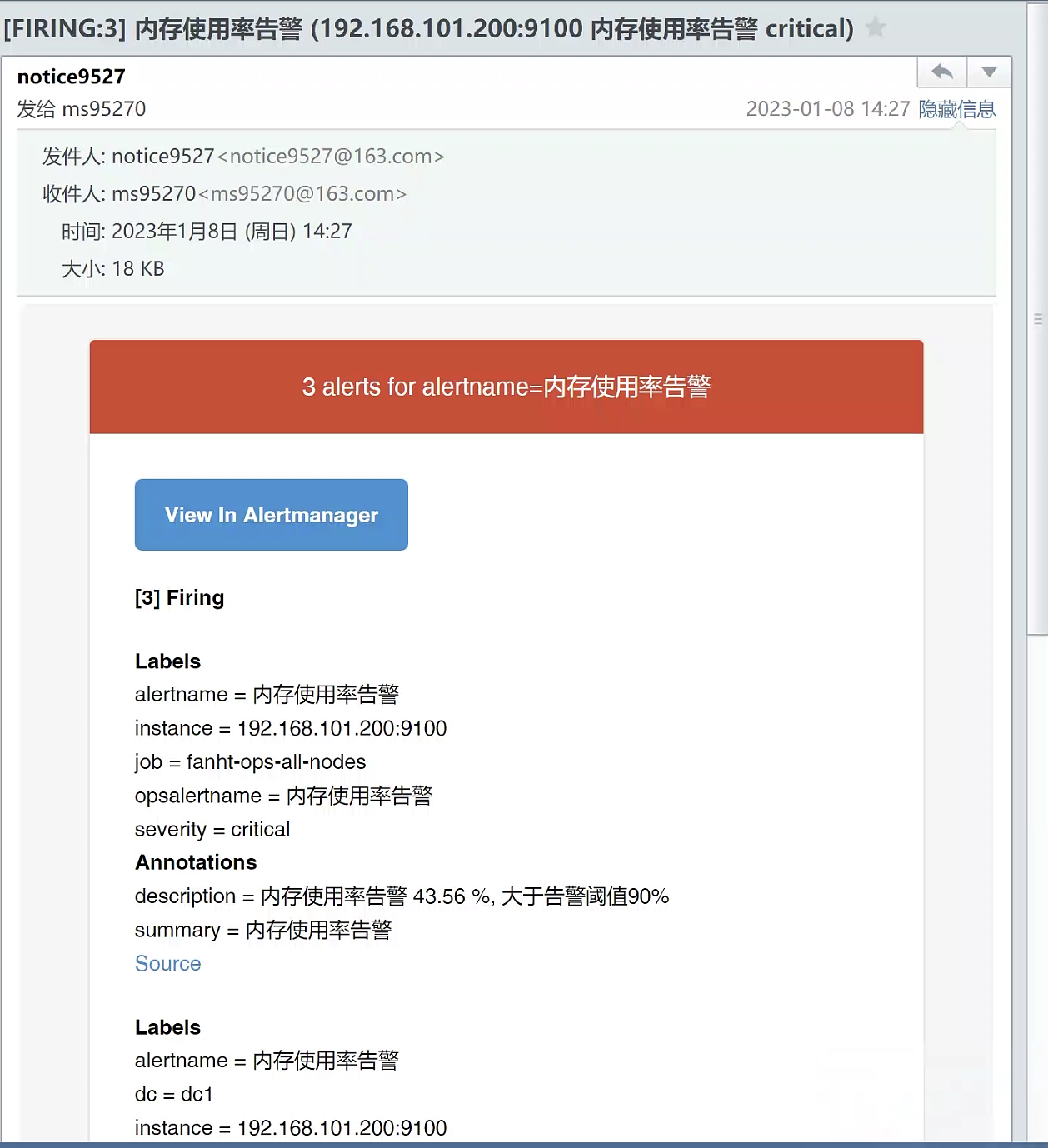
把内存告警阈值由90%改成10%还是很容易看到告警效果的,触发完成后改回去,千万别影响正常告警。
#假期触发告警,文章没写完今天做补充了,多水一张图
4.1.3、Alertmanager页面验证
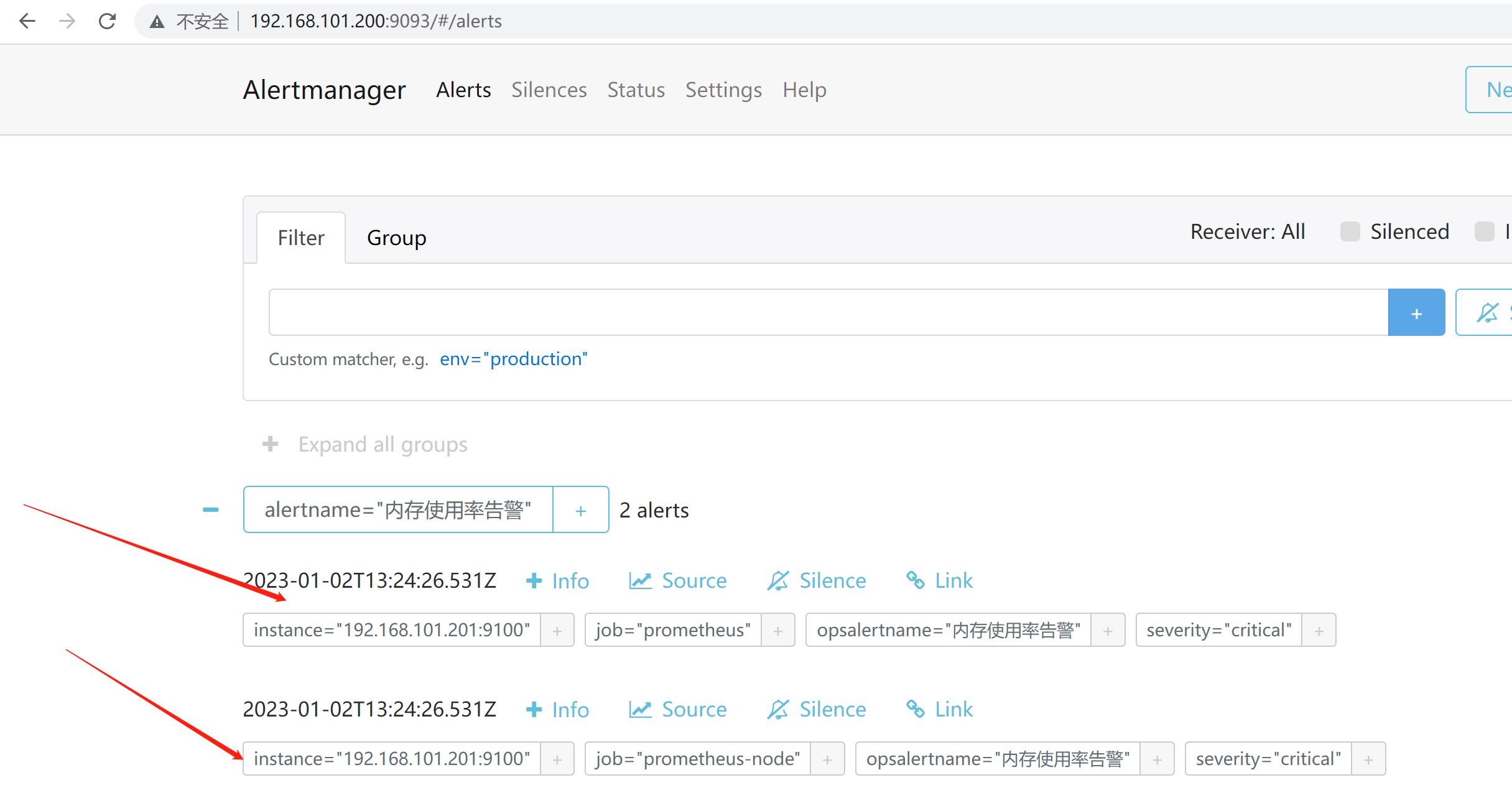
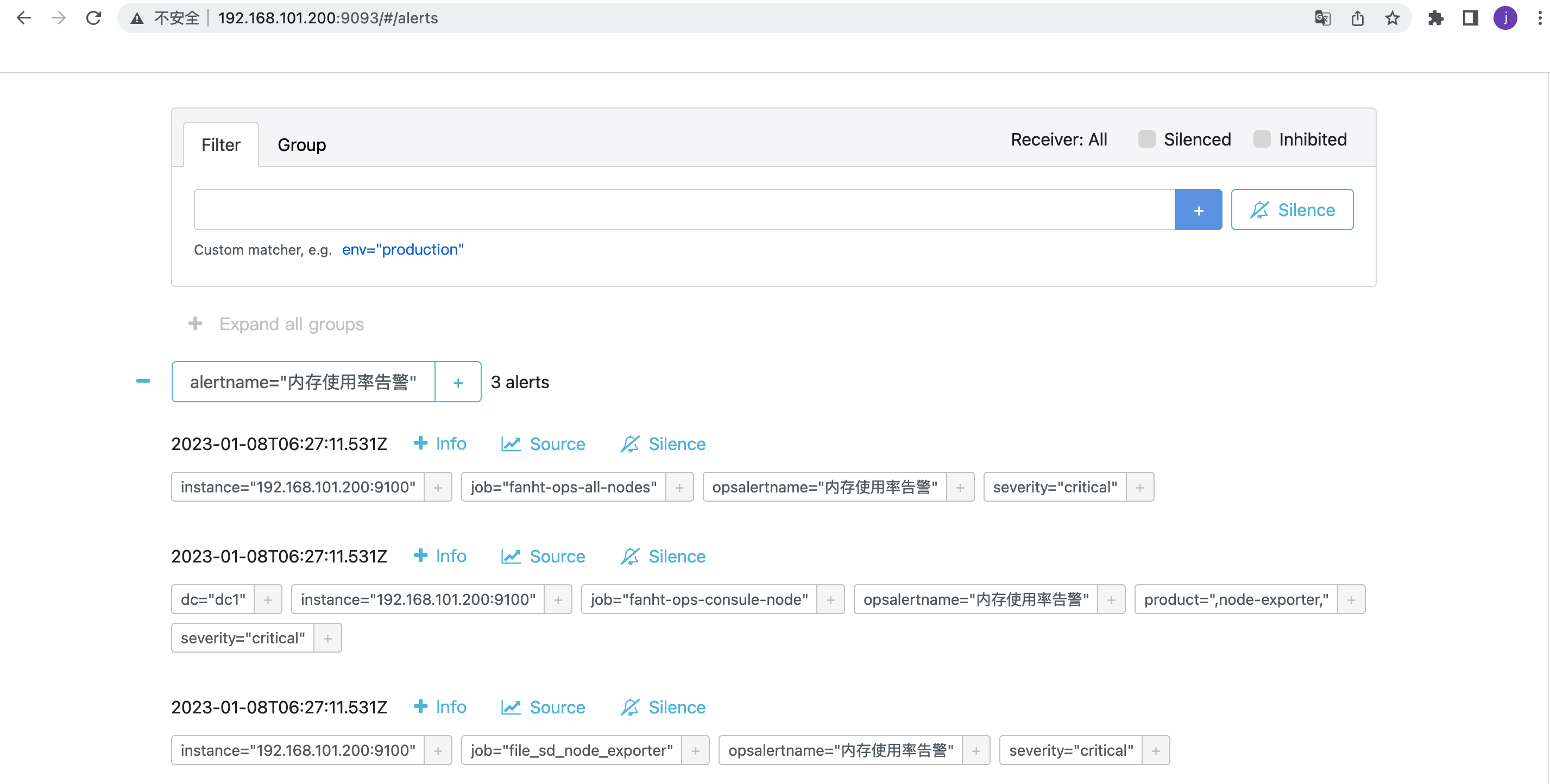
alertmanger告警页面
http://192.168.101.200:9093/#/alerts
4.1.4、邮件验证
3.2、钉钉告警
默认 端8060
prometheus发送钉钉告警需要借助插件webhook-dingtalk

3.2.1、创建钉钉机器人
自己搞定,使用脚本测试钉钉机器人
#!/bin/bash
source /etc/profile
MESSAGE=$1
/usr/bin/curl -X "POST" 'https://oapi.dingtalk.com/robot/send?access_token=自己的token' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text","text": {"content":"'${MESSAGE}'"}}'
3.2.2、github
3.2.3、下载插件安装包
prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
3.2.4、参考钉钉官网使用
3.2.5、安装Dingtalk组件
mkdir -p /data/prometheus/dingtalk tar -xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz -C /data/prometheus/dingtalk/ ln -sv prometheus-webhook-dingtalk-2.1.0.linux-amd64/ prometheus-webhook-dingtalk

3.2.5、修改dingtalk 配置
cd /data/prometheus/dingtalk/
cd prometheus-webhook-dingtalk
cp config.example.yml config.yml

vim config.yml
url: https://oapi.dingtalk.com/robot/send?access_token=97c9a4c1fc86dfac161c4eda0fbdf018c0b8a0e2a1bfe96ef5e6cbbf38ae6aab

3.2.6、dingtalk配置系统启动
cat /usr/lib/systemd/system/prometheus-webhook-dingtalk.service
# 添加如下内容 [Unit] Description=https://github.com/timonwong/prometheus-webhook-dingtalk/releases/ After=network-online.target [Service] Restart=on-failure ExecStart=/data/prometheus/dingtalk/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/data/prometheus/dingtalk/prometheus-webhook-dingtalk/config.yml [Install] WantedBy=multi-user.target

启动和停止服务命令
# 查看状态
systemctl status prometheus-webhook-dingtalk
# 启动
systemctl enable prometheus-webhook-dingtalk.service
systemctl start prometheus-webhook-dingtalk.service
# 停止
systemctl stop prometheus-webhook-dingtalk.service

3.2.7、验证
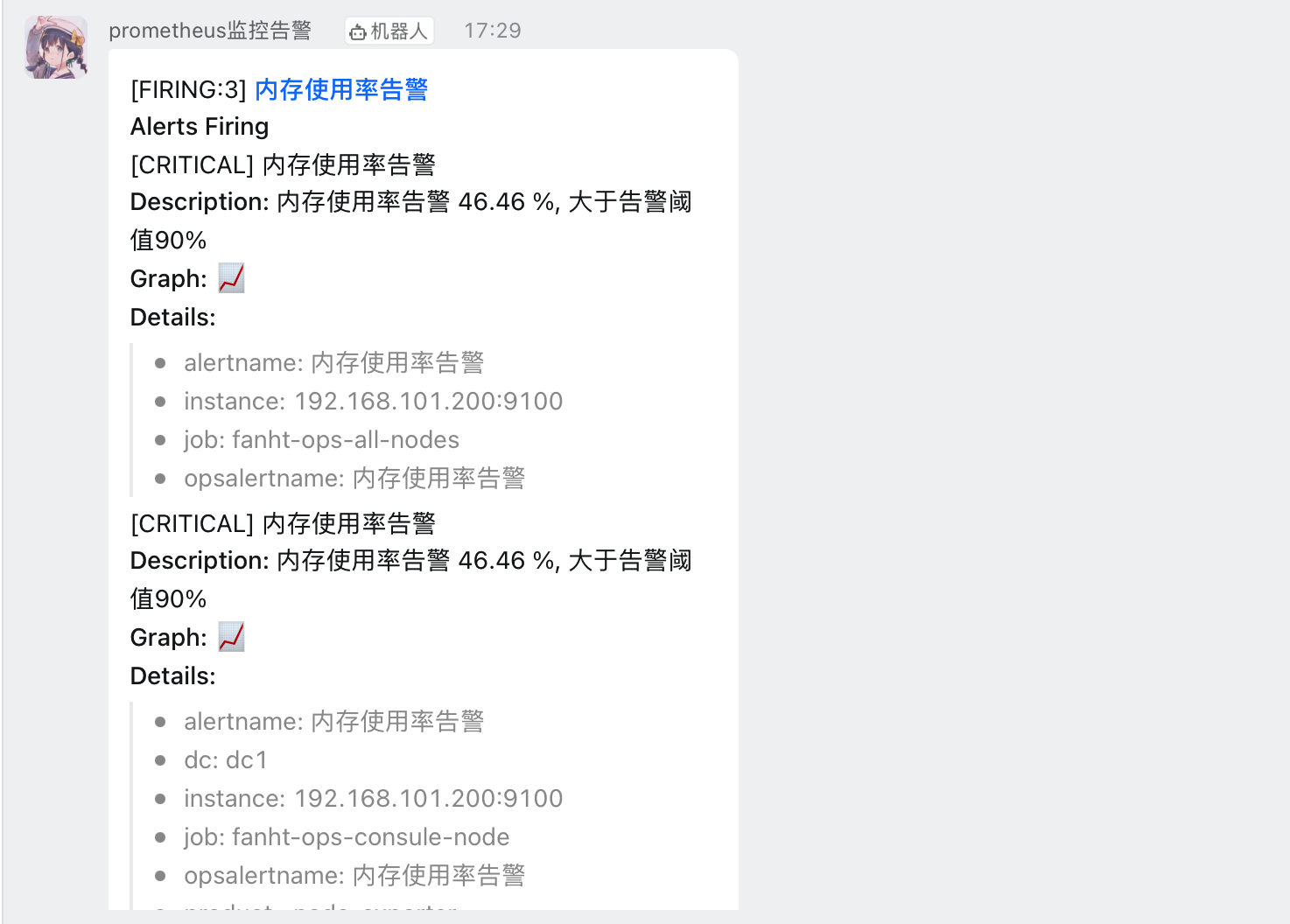
4、告警抑制
4.1、访问Alertmanager
http://192.168.101.200:9093/#/alerts
2、静默1.5小时
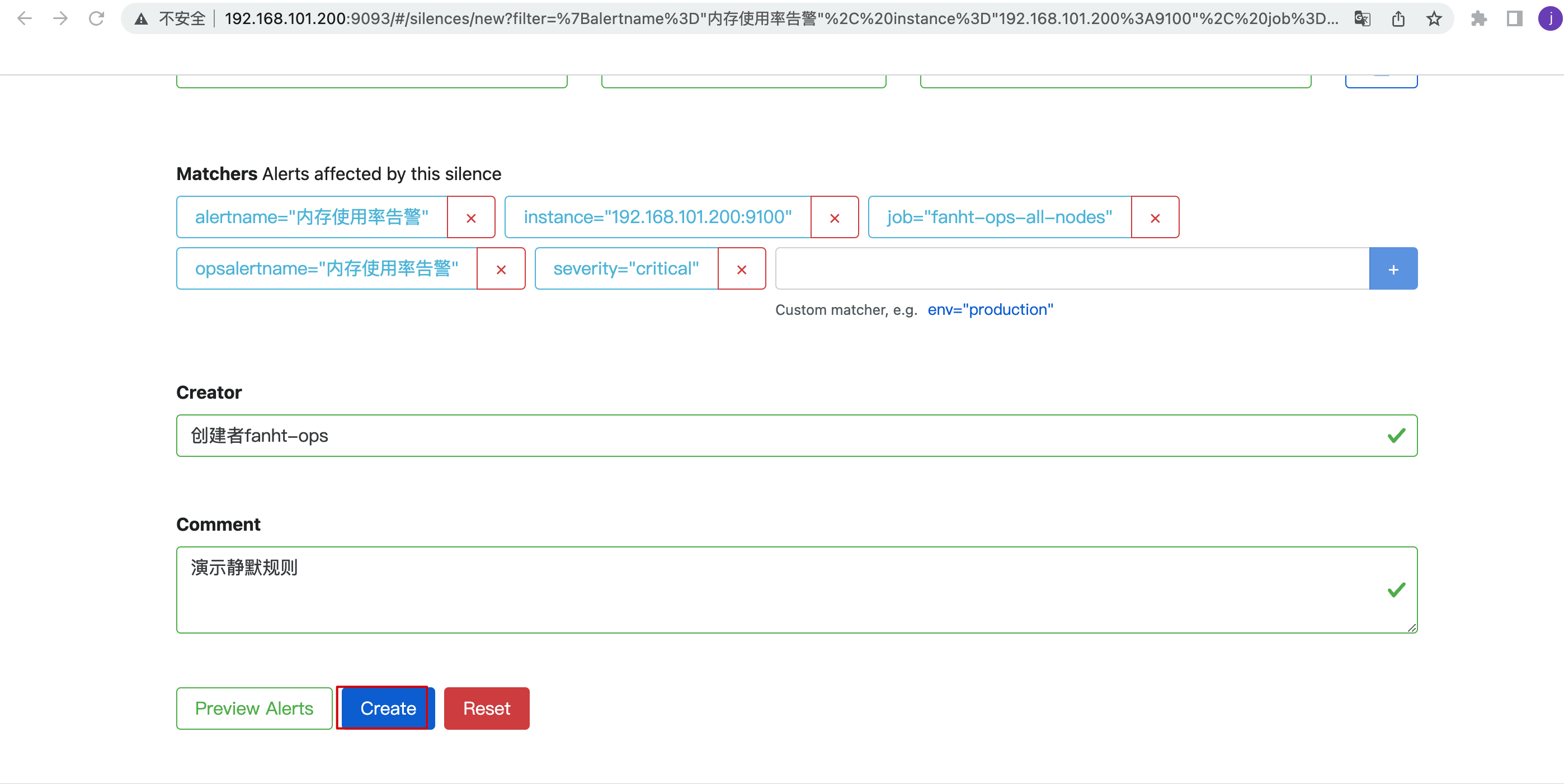
4、告警分类
九、PrometheusAlert
PrometheusAlert是开源的运维告警中心消息转发系统,支持主流的监控系统Prometheus、Zabbix,日志系统Graylog2,Graylog3、数据可视化系统Grafana、SonarQube。阿里云-云监控,以及所有支持WebHook接口的系统发出的预警消息,支持将收到的这些消息发送到钉钉,微信,email,飞书,腾讯短信,腾讯电话,阿里云短信,阿里云电话,华为短信,百度云短信,容联云电话,七陌短信,七陌语音,TeleGram,百度Hi(如流)等。
1、安装PrometheusAlert
#打开PrometheusAlert releases页面,根据需要选择需要的版本下载到本地解压并进入解压后的目录 如linux版本(https://github.com/feiyu563/PrometheusAlert/releases/download/v4.8.1/linux.zip) # wget https://github.com/feiyu563/PrometheusAlert/releases/download/v4.8.1/linux.zip && unzip linux.zip && cd linux/ #,下载好后解压并进入解压后的文件夹 #运行PrometheusAlert # ./PrometheusAlert (#后台运行请执行 nohup ./PrometheusAlert &) #启动后可使用浏览器打开以下地址查看:http://127.0.0.1:8080 #默认登录帐号和密码在app.conf中有配置
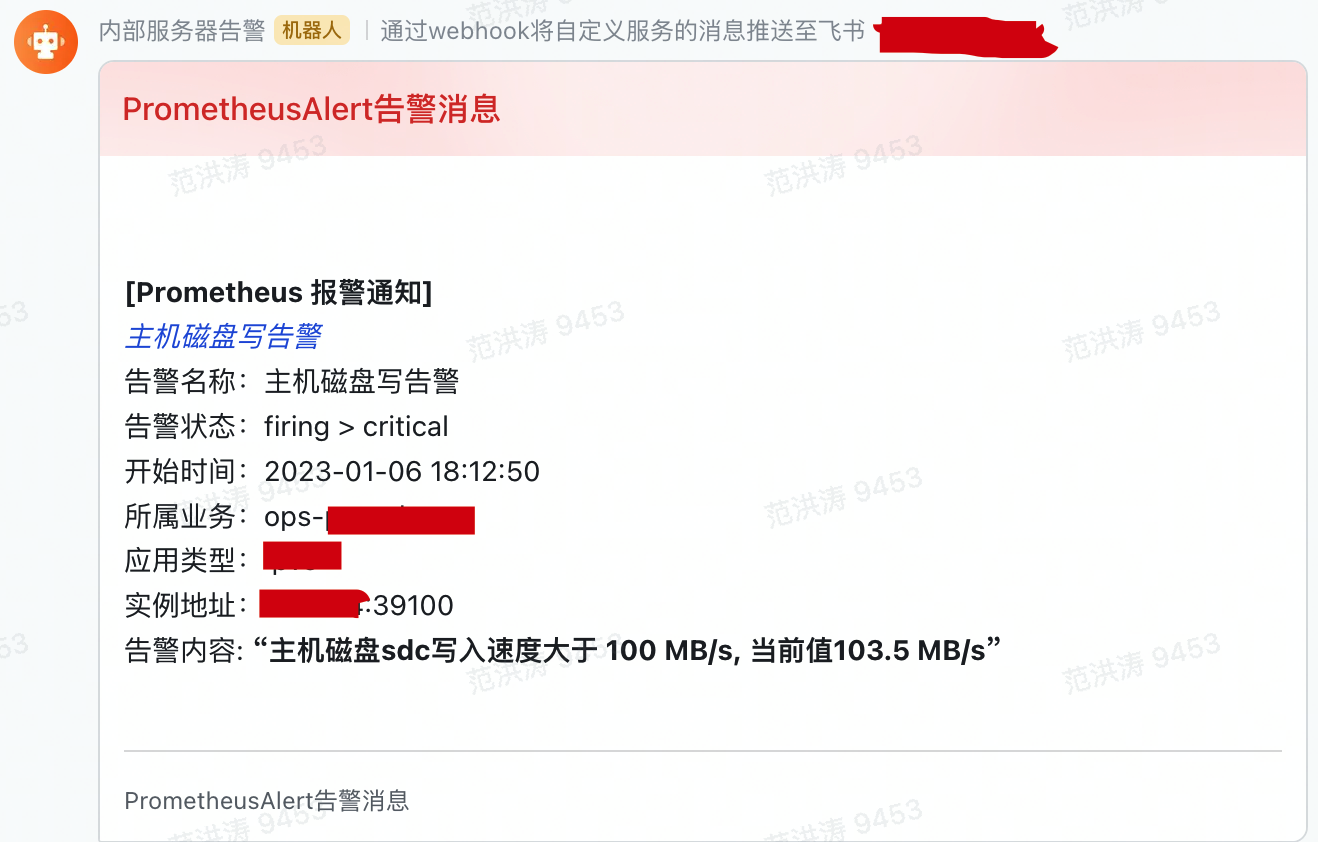
2、演示飞书告警配置
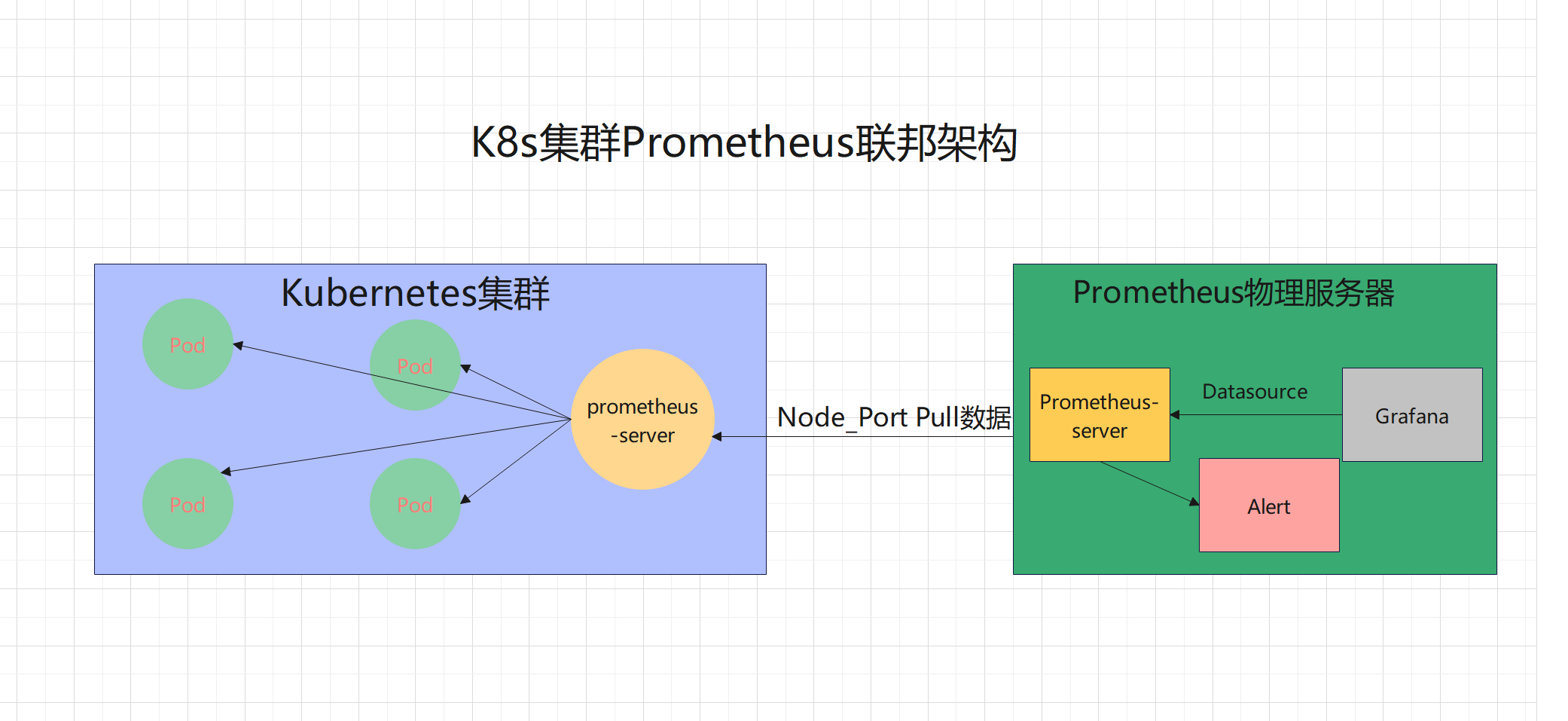
十、K8s集群使用Prometheus
十一、总结
一期总算是整理完了,没想用这么长时间,本来以为元旦假期可以梳理完,有的部分是节后下班补充。每一个字符都是经过验证的,要对输出的内容负责。
1、使用程度
通过上面操作完成了prometheus基础入门使用,可以在基础上做扩展。
2、Prometheus二期输出计划
1、继续输出Prometheus 云原生方面使用
2、Go二次开发Prometheus前端页面操作为主
3、远端存储Victoria(维多利亚)集群配置

















 4688
4688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









