



目录
160.相交链表

读一遍A,一个set存节点,遍历B的时候判断即可。复习下set的STL:set有set和unordered_set,同样有insert,find,count,对于set而言,自动从小到大排序,还有:
| s.lower_bound(k) | O ( l o g N ) | 返回大于等于k的第一个元素的迭代器 |
| s.upper_bound(k) | O ( l o g N ) | 返回大于k的第一个元素的迭代器 |
注意都是大于!(或大于等于)
234.回文链表
无
226.翻转二叉树

翻转二叉树是经典题了,必须掌握。就是递归遍历树,然后从下往上交换左右子树。(实际上很多和树相关的都会涉及递归和遍历)
class Solution {
public:
void switchlr(TreeNode* root){
if(root==nullptr)return;
switchlr(root->left);
switchlr(root->right);
TreeNode*l=root->left;
root->left=root->right;
root->right=l;
return;
}
TreeNode* invertTree(TreeNode* root) {
switchlr(root);
return root;
}
};221.最大正方形
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积。(再次提醒,返回的不是边长,而是边长的平方!)
同样是经典dp了,f(i,j)表示以(i,j)为右下角的正方形的最大边长,有了dp的思路然后画个图就知道dp方程
class Solution {
public:
int maximalSquare(vector<vector<char>>& matrix) {
int dp[310][310];
memset(dp,0,sizeof dp);int ans=0;
int m=matrix.size();int n=matrix[0].size();
for(int i=0;i<m;i++){
if(matrix[i][0]=='0')dp[i][0]=0;
else{
ans=1;dp[i][0]=1;
}
}
for(int j=0;j<n;j++){
if(matrix[0][j]=='0')dp[0][j]=0;
else{
ans=1;dp[0][j]=1;
}
}
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
if(matrix[i][j]=='0'){
dp[i][j]=0;continue;
}
else if(matrix[i][j]=='1'){
dp[i][j]=min(dp[i-1][j-1],min(dp[i-1][j],dp[i][j-1]))+1;
ans=max(ans,dp[i][j]);
}
}
}
return ans*ans;
}
};215.数组中的第k个最大元素
线性查找模板——在快排的基础上改的partion
class Solution {
public:
int partion(vector<int>&nums,int l,int r,int k){
int bench=nums[l];int mid=(l+r)/2;
int i=l,j=r;int z=nums.size();
if(l==r)return nums[k];
while(i<j){
while(nums[j]>=bench&&j>i)j--;
while(nums[i]<=bench&&i<j)i++;
if(i<j)swap(nums[i],nums[j]);
else if(i>=j)break;
}
nums[l]=nums[i];nums[i]=bench;
if(i+1==k)return nums[i];
else if(i+1<k)return partion(nums,i+1,r,k);
else if(i+1>k)return partion(nums,l,i,k);
return -1;
}
int findKthLargest(vector<int>& nums, int k) {
int z=nums.size();
if(z==1)return nums[0];
return partion(nums,0,z-1,z-k+1);
}
};208.实现trie
记住字典树的结构:每个节点由一个字符vector和bool组成(标识是否是末尾)
class Trie {
private:
vector<Trie*>ch;
bool isend;
public:
Trie() {
ch=vector<Trie*>(26);
isend=false;
}
void insert(string word) {
int m=word.size();
Trie* node=this;//注意注释中给出的调用
for(int i=0;i<m;i++){
char c=word[i]-'a';
if(node->ch[c]==nullptr){
node->ch[c]=new Trie();
}
node=node->ch[c];
}
node->isend=true;
}
bool search(string word) {
int m=word.size();
Trie* node=this;//注意注释中给出的调用
for(int i=0;i<m;i++){
char c=word[i]-'a';
if(node->ch[c]==nullptr){
return false;
}
node=node->ch[c];
}
return node->isend;
}
bool startsWith(string prefix) {
int m=prefix.size();
Trie* node=this;
for(int i=0;i<m;i++){
char c=prefix[i]-'a';
if(node->ch[c]==nullptr)return false;
node=node->ch[c];
}
return true;
}
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/207.课程表

拓扑排序显然是和queue相关的,使用队列记录候选头,此外,正确做法应在减少邻接节点入度时立即检查其是否为0。
class Solution {
public:
queue<int>que;unordered_map<int,vector<int>>store;
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
int m=prerequisites.size();int a,b;
vector<int>book(numCourses,0);
vector<int>deg(numCourses,0);
for(int i=0;i<m;i++){
a=prerequisites[i][0];b=prerequisites[i][1];
store[b].push_back(a);deg[a]+=1;
}
for(int i=0;i<deg.size();i++){
if(deg[i]==0)que.push(i);
}
while(!que.empty()){
int head=que.front();que.pop();book[head]=1;
auto vec=store[head];
for(int i=0;i<vec.size();i++){
a=vec[i];deg[a]--;
if(deg[a]==0&&book[a]==0)que.push(a);
}
}
for(int i=0;i<book.size();i++){
if(book[i]==0){
return false;
}
}
return true;
}
};236.二叉树的最近公共祖先
核心:从递归的思路出发,寻求找祖先的逻辑!

class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q)
return root;
TreeNode r = lowestCommonAncestor(root.right , p , q);
TreeNode l = lowestCommonAncestor(root.left , p , q);
return l == null ? r : (r == null ? l : root);
}
}206.反转链表
强调一些语法:for (auto it = store.rbegin(); it != store.rend(); ++it),rend() 表示反向迭代器的结束位置(指向容器第一个元素的前一个位置),it确实是++,只不过从末尾往开头走,it代表迭代器!使用&it代表获取迭代器的地址(x),而*it代表获取迭代器代表的元素(√)
739.每日温度
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
显然是从后往前遍历,维护一个day数组,day[a]=b;比a温度高的是第b天 这样如果前面天的温度更高,j=day[j]; 直接跳到比j温度高的天比较,然后继续跳……
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int k=temperatures.size();
vector<int>day(k,-1);
//day[a]=b;比a温度高的是第b天
for(int i=k-1;i>0;i--){
int j=i;
while(j!=-1){
if(temperatures[i-1]<temperatures[j]){
day[i-1]=j;
break;
}
else{
j=day[j];
}
}
}
vector<int>ans;
for(int i=0;i<k;i++){
if(day[i]==-1)ans.push_back(0);
else{
ans.push_back(day[i]-i);
}
}
return ans;
}
};200.岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
dfs,染色和岛屿数量由color决定。
class Solution {
public:
int board[310][310];int color;
int dire[4][2]={{1,0},{0,-1},{-1,0},{0,1}};
void paint(const vector<vector<char>>&grid,int x,int y){
int m=grid.size();int n=grid[0].size();int tx,ty;
board[x][y]=color;
for(int i=0;i<4;i++){
tx=x+dire[i][0];ty=y+dire[i][1];
if(tx<0||tx>=m||ty<0||ty>=n||grid[tx][ty]=='0'||board[tx][ty]!=0)continue;
paint(grid,tx,ty);
}
}
int numIslands(vector<vector<char>>& grid) {
memset(board,0,sizeof board);color=0;
int m=grid.size();int n=grid[0].size();
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
if(board[i][j]==0&&grid[i][j]=='1'){
color+=1;paint(grid,i,j);
}
}
}
return color;
}
};198.打家劫舍

老dp了,关于i-1和i-2的,拿与不拿(注意下只有一家的特殊情况)。
class Solution {
public:
int rob(vector<int>& nums) {
int k=nums.size();vector<int>dp(k,0);
if(k==1)return nums[0];
dp[0]=nums[0];dp[1]=max(nums[0],nums[1]);
for(int i=2;i<k;i++)dp[i]=max(dp[i-2]+nums[i],dp[i-1]);
return dp[k-1];
}
};169.多数元素
略
238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
看到O(n)就应该想到双指针,两个数组,一个存前缀乘积一个存后缀乘积
注意一个小点:vector已经声明了空间长度,就不要再用push_back!
class Solution {
public:
vector<int> productExceptSelf(vector<int>& nums) {
int m=nums.size();
vector<int>pre(m,1);vector<int>behind(m,1);
for(int i=1;i<m;i++){
pre[i]=(pre[i-1]*nums[i-1]);
}
for(int i=m-2;i>=0;i--){
behind[i]=(behind[i+1]*nums[i+1]);
}
vector<int>ans(m);
for(int i=0;i<m;i++)ans[i]=(pre[i]*behind[i]);
return ans;
}
};155.最小栈

要强调一个点:这里不等同于单调栈!(如果是单调栈,请问获取栈顶的元素和获取最小元素有什么区别)
方法很简单——同时维护一个栈,记录此时此刻在栈中的最小值就行。(与元素栈同步插入与删除,用于存储与每个元素对应的最小值。)
class MinStack {
private:
stack<int>store,work;
public:
MinStack() {
work.push(INT_MAX);
}
void push(int val) {
store.push(val);
work.push(min(work.top(),val));
}
void pop() {
store.pop();
work.pop();
}
int top() {
return store.top();
}
int getMin() {
return work.top();
}
};152.乘积最大子数组
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续 子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
看题目就想到求连续最大值的一遍扫描,只不过这里是乘法,需要考虑负负得正的情况,办法很简单,引入两个变量代表当前乘积最大和最小值,然后同时与nums[i]相乘并比较就好!
框架肯定不变的,就看怎么解决乘积,所以想到引入变量
int maxProduct(vector<int>& nums) {
int neg = nums[0], pos = nums[0], ans = nums[0];
for (int i = 1; i < nums.size(); i++) {
int pre_neg = neg;
int pre_pos = pos;
neg = min({nums[i], nums[i] * pre_neg, nums[i] * pre_pos});
pos = max({nums[i], nums[i] * pre_neg, nums[i] * pre_pos});
ans = max(ans, pos);
}
return ans;
}比较易错的是这样:
for(int i=1;i<k;i++){
neg=trimin(nums[i],nums[i]*neg,nums[i]*pos);
pos=trimax(nums[i],nums[i]*neg,nums[i]*pos);
ans=max(ans,pos);
} 这样肯定不对,neg被更新后立即用于计算新的 pos,而不是上一轮的原始值
148.排序链表
略。
其实严格意义上,这里不应该图省事用快排sort,标准想考查的事链表的归并排序。
sort(store.begin(), store.end(), Comparator());// 使用结构体比较而非 Lambda
成员函数后的 const 保证函数不修改结构体状态
两个括号:
operator() | 实现函数调用语义 | bool operator()(...) |
private:
// 定义比较结构体
struct Comparator {
bool operator()(const ListNode* a, const ListNode* b) const {
return a->val < b->val;
}
};补充:常数空间内找到链表中点——快慢指针法!!!

141.环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
略。链表中的经典套路——快慢指针
142.环形链表2
加一个返回入环的结点(如果有环的话)。略。遍历的同时维护一个unordered_set
146.LRU缓存

究极面试经典题。关键在于put这个点要是常数复杂度,所以用栈是不行的,堆也是不行的(设计到删除插入),只能考虑双向链表,头部最新,尾部最老(单向的话删除需要遍历找pre,也不行);缓存使用一个map。
还有就是插删的细节问题,以及初始化操作。
class LRUCache {
struct linknode{
int key,value;
linknode*next,*pre;
linknode():key(0),value(0),next(nullptr),pre(nullptr){}
linknode(int key,int val):key(key),value(val),next(nullptr),pre(nullptr){}
};
private:
unordered_map<int,linknode*>umap;
linknode* head;linknode* tail;
int maxcap,cap;
public:
void removenode(linknode* p){
linknode* p1=p->pre;linknode* p2=p->next;
p1->next=p2;p2->pre=p1;
return;
}
void addtohead(linknode* p){
p->pre=head;
p->next=head->next;
head->next->pre=p;
head->next=p;
return;
}
LRUCache(int capacity) {
head=new linknode();
tail=new linknode();
head->next=tail;
tail->pre=head;
this->maxcap=capacity;
cap=0;
return;
}
int get(int key) {
if(umap.find(key)==umap.end())return -1;
linknode* p=umap[key];
removenode(p);
addtohead(p);
return p->value;
}
void put(int key, int value) {
if(umap.find(key)!=umap.end()){
linknode* p=umap[key];
removenode(p);
p->value=value;
addtohead(p);
}
else{
linknode* p=new linknode(key,value);
addtohead(p);
umap[key]=p;
cap++;
if(cap>maxcap){
linknode* p=tail->pre;
removenode(p);
umap.erase(p->key);
delete p;
cap--;
}
}
}
};139.单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
直接开搜,但注意搜索可能会导致超时,所以采取一些策略:首先是引入memo这个map,用于缓存已经计算过的子问题的结果,以避免重复计算;第二个是全部改为引用调用,这样有的递归调用都共享同一个,如果不这样,则每个递归分支都有自己的独立副本(即memo是每个分支独立的),也就失去了memo的意义。
此外,强烈建议再看STL中各种string的函数,很有用!

class Solution {
public:
bool search(string s,const vector<string>&wordDict,unordered_map<string,bool>&memo){
if(s=="")return true;
if(memo.find(s)!=memo.end())return memo[s];
for(auto word:wordDict){
if(s.size()>=word.size()&&s.substr(0,word.size())==word){
if(search(s.substr(word.size()),wordDict,memo)){
memo[s]=true;
return true;
}
}
}
memo[s]=false;
return false;
}
bool wordBreak(string s, vector<string>& wordDict) {
unordered_map<string,bool>memo;
return search(s,wordDict,memo);
}
};136.只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
找元素,且只用常量空间——往位运算上面想! 异或^=
647.回文子串
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
注意一个点:回文的判断用双指针。
class Solution {
public:
int isregu(const string &s,int sta,int len){
int i=sta;int j=sta+len-1;
while(i<=j){
if(s[i]==s[j]){
j--;i++;continue;
}
else return 0;
}
return 1;
}
int countSubstrings(string s) {
int ans=0;int k=s.size();
for(int i=1;i<=k;i++){
for(int j=0;j+i-1<k;j++){
ans+=isregu(s,j,i);
}
}
return ans;
}
};128.最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。要求是O(n)的复杂度
输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
从基础版的代码开始一步步想解决办法:x,x+1,x+2,⋯,x+y 的连续序列,而我们却重新从 x+1,x+2 或者是 x+y 处开始尝试匹配,那么得到的结果肯定不会优于枚举 x 为起点的答案。所以将基础暴力n^2降到n的做法是确定这个数是不是开头,如果是才遍历,如果不是就跳过,即判断set中有没有num-1! ——这种从基础到最终的解决思想是值得学习的
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
//遍历开头的做法
unordered_set<int>store;
for(int num:nums)store.insert(num);
int ans=0;
for(int num:store){
if(!store.count(num-1)){
int cur=num;
int curlen=1;
while(store.count(cur+1)){
cur++;curlen++;
}
ans=max(ans,curlen);
}
}
return ans;
}
};124.二叉树中的最大路径和
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
显然是递归:显然每次返回的应该是单边的最大值(而不是折线,意会一下),但是,这个可能是折线的最大路径和完全可以在递归的过程中更新呀~ 具体看代码,还是很经典的
class Solution {
public:
int ans;
int dfs(TreeNode* root){
if(root==nullptr){
return 0;
}
int maxleft=max(dfs(root->left),0);
int maxright=max(dfs(root->right),0);
//更新最大路径和
ans=max(ans,maxleft+maxright+root->val);
//返回的值又是另一回事:
//他的贡献只能带其中一个孩子(带大孩子走),整个路径才能向上延伸
return root->val+max(maxleft,maxright);
}
int maxPathSum(TreeNode* root) {
ans=INT_MIN;
dfs(root);
return ans;
}
};322.零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。(每种硬币数量无限)
这里使用闫式dp法
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
if(amount==0)return 0;
vector<int>dp(amount+1,amount+1);
dp[0]=0;
for(int i=1;i<=amount;i++){
for(auto coin:coins){
if(coin>i)continue;
dp[i]=min(dp[i],dp[i-coin]+1);
}
}
return dp[amount]>amount?-1:dp[amount];
}
};试了一下dfs+剪枝似乎也能过:不过这种求最值的问题还是优先dp!(必须想到)
复杂度amount*len(nums),这里的剪枝搜索也是模板! 此外,倒排序:用rbegin
class Solution {
private:
vector<int>store;
public:
int dfs(const vector<int>&coins,int amount){
if(amount==0)return 0;
if(store[amount]!=-2)return store[amount];
int min_count=0x3f3f3f;
for(int coin:coins){
if(coin>amount)continue;
int res=dfs(coins,amount-coin);
if(res!=0x3f3f3f){
min_count=min(min_count,res+1);
}
}
store[amount]=min_count;
return store[amount];
}
int coinChange(vector<int>& coins, int amount) {
sort(coins.rbegin(),coins.rend());
store=vector<int>(amount+1,-2);
int result=dfs(coins,amount);
return result==0x3f3f3f?-1:result;
}
};494.目标和
输入:nums = [1,1,1,1,1], target = 3 输出:5 解释:一共有 5 种方法让最终目标和为 3 。 -1 + 1 + 1 + 1 + 1 = 3 +1 - 1 + 1 + 1 + 1 = 3 +1 + 1 - 1 + 1 + 1 = 3 +1 + 1 + 1 - 1 + 1 = 3 +1 + 1 + 1 + 1 - 1 = 3
超级经典的动态规划!

所以转化为背包问题,选哪些组合可以把package_b装满(使用b来判断,b为负有0种情况)
461.汉明距离
注意左移运算符:>>= 此外,左移是高位补0
class Solution {
public:
int hammingDistance(int x, int y) {
int ans=0;
//x和y任意一个不为零都循环
while(x|y){
ans+=(x&1)^(y&1);
x>>=1;y>>=1;
}
return ans;
}
};448.找到所有数组中消失的数字
略
438.找到字符串中的所有异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
令人惊讶的是不考虑任何优化,直接每次考虑两个map是否相等也能过。
class Solution {
public:
unordered_map<char,int>pstore,sstore;
int thesame(){
for(auto it=pstore.begin();it!=pstore.end();it++){
char ch=it->first;
if(sstore.find(ch)==sstore.end()||sstore[ch]!=pstore[ch])
return 0;
}
return 1;
}
vector<int> findAnagrams(string s, string p) {
int k1=s.size();int k2=p.size();
for(int i=0;i<k2;i++){
pstore[p[i]]+=1;
}
vector<int>ans;
if(k1<k2)return ans;
for(int i=0;i<k2;i++){
sstore[s[i]]+=1;
}
for(int i=1;i+k2<=k1;i++){
if(thesame())ans.push_back(i-1);
sstore[s[i-1]]-=1;
sstore[s[i+k2-1]]+=1;
}
if(thesame())ans.push_back(k1-k2);
return ans;
}
};显然是只用比较移入和移出之后的变化的,所以可以有更快的做法:
避免在每次滑动窗口时完整比较两个哈希表,我们可以改用固定大小的数组(大小128,覆盖所有ASCII字符),并利用数组直接比较是否相等。
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
vector<int> ans;
if (p.empty()) {
for (int i = 0; i <= s.size(); i++)
ans.push_back(i);
return ans;
}
if (s.size() < p.size())
return ans;
vector<int> p_count(128, 0);
vector<int> s_count(128, 0);
int pLen = p.size();
for (char c : p)
p_count[c]++;
for (int i = 0; i < pLen; i++)
s_count[s[i]]++;
if (p_count == s_count)
ans.push_back(0);
for (int i = pLen; i < s.size(); i++) {
s_count[s[i - pLen]]--;
s_count[s[i]]++;
if (p_count == s_count)
ans.push_back(i - pLen + 1);
}
return ans;
}
};437.路径综合3
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
深度搜索的同时引入一个前缀和哈希进行判断!
class Solution {
public:
unordered_map<long, int> prefixSumCount; // 存储前缀和出现次数的哈希表
int totalCount; // 记录满足条件的路径总数
void dfs(TreeNode* node, long currentSum, int targetSum) {
if (!node) return;
// 更新当前路径和
currentSum += node->val;
// 检查是否存在前缀和使得 currentSum - prefixSum = targetSum
if (prefixSumCount.find(currentSum - targetSum) != prefixSumCount.end()) {
totalCount += prefixSumCount[currentSum - targetSum];
}
// 更新当前前缀和的出现次数
prefixSumCount[currentSum]++;
// 递归遍历左右子树
dfs(node->left, currentSum, targetSum);
dfs(node->right, currentSum, targetSum);
// 回溯:当前节点访问完成后,从哈希表中去除当前前缀和
prefixSumCount[currentSum]--;
if (prefixSumCount[currentSum] == 0) {
prefixSumCount.erase(currentSum);
}
}
int pathSum(TreeNode* root, int targetSum) {
prefixSumCount.clear();
prefixSumCount[0] = 1; // 重要:初始化空路径的前缀和为0的出现次数为1
totalCount = 0;
dfs(root, 0, targetSum);
return totalCount;
}
};416.分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
略。经典拆成0-1背包。
406.根据身高重建队列
其实是个不错的锻炼思维的题,题目有点绕,核心是输入的数组是乱序的,让你给排序。
解法为将输入按照身高升序排序,然后遍历,这样每次遍历的时候必然是当前最小的身高。
class Solution {
public:
// struct ope{
// bool operator()(const vector<int>&a,const vector<int>&b){
// if(a[0]<b[0])return true;
// else if(a[0]==b[0]&&a[1]<b[1])return true;
// }
// };
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
unordered_map<int,vector<int>>store;int k=people.size();
int height[k+5];memset(height,-1,sizeof height);
sort(people.begin(),people.end());
for(int i=0;i<k;i++){
int h=people[i][0];int pos=people[i][1];int count=0;
for(int j=0;j<k;j++){
if(pos==count){
while(j<k&&height[j]!=-1)j++;
height[j]=h;store[j]=people[i];
break;
}
if(height[j]==-1&&count<pos){
count++;
}
else if(height[j]>=h&&count<pos){
count++;
}
else if(height[j]!=-1&&height[j]<h)continue;
}
}
vector<vector<int>>ans;
for(int i=0;i<k;i++){
ans.push_back(store[i]);
}
return ans;
}
};399.除法求值


除法问题,首先的思路是找基准,比如a/b以b为基准……但显然这个基准不好找,所以想到的是并查集,通过并查集能将相关联的字符归为一个基准!即:根节点(祖先)为基准,且这是个带权的并查集(它的压缩与合并必须掌握)
不同的字符串(这个题好像不约分,即ab/bc就是ab/bc,而并不等于a/c)用哈希表存储,将字符串映射为int,这样就和并查集结合了。
class Solution {
private:
class Union{
//建立并查集
private:
vector<int>parents;
//weights[x] 表示变量 x 相对于其当前直接父节点的权重值
//如果父节点为p,那么x=p×weights[x]
vector<double>weights;
public:
Union(int n):parents(n),weights(n,1.0){
for(int i=0;i<n;i++)parents[i]=i;
//并查集初始化
}
int findfa(int x){
if(parents[x]==x)return parents[x];
else{
//注意这里!带权并查集的压缩的写法!
int ori=parents[x];
parents[x]=findfa(parents[x]);
weights[x]*=weights[ori];
}
return parents[x];
}
//合并,将x所在的子树连到y所在的子树
void unite(int x,int y,double value){
int rootx=findfa(x);
int rooty=findfa(y);
if(rootx==rooty)return;
parents[rootx]=rooty;//x把y当做基
weights[rootx]=weights[y]*value/weights[x];
}
double isconnected(int x,int y){
int rootx=findfa(x);int rooty=findfa(y);
if(rootx==rooty)return weights[x]/weights[y];
else return -1.0;
}
};
public:
vector<double> calcEquation(vector<vector<string>>& equations, vector<double>& values, vector<vector<string>>& queries) {
int k=equations.size();
//注意初始化的表达
Union theunion(2*k);
//变量到id的映射
unordered_map<string,int>hashmap(2*k);
int id=0;
for(int i=0;i<k;i++){
string var1=equations[i][0];
string var2=equations[i][1];
if(!hashmap.count(var1))hashmap[var1]=id++;
if(!hashmap.count(var2))hashmap[var2]=id++;
//建立两个字符串的连接,字符串用id映射表示
theunion.unite(hashmap[var1],hashmap[var2],values[i]);
}
int q=queries.size();
vector<double>res(q);
for(int i=0;i<q;i++){
string var1=queries[i][0];
string var2=queries[i][1];
//新出现的变量
if(!hashmap.count(var1)||!hashmap.count(var2))res[i]=-1.0;
//计算
else res[i]=theunion.isconnected(hashmap[var1],hashmap[var2]);
}
return res;
}
};394.字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
输入:s = "2[abc]3[cd]ef" 输出:"abcabccdcdcdef"
很不错的一道递归题,对于一个字符串,它可能很多地方都会有压缩(即[]),压缩处的标志即数字(这里要注意数字可能有多位),所以当在数字标记处时,求得当前压缩的次数,while结束后进入压缩(跳过[,进入下一轮递归,出来的时候res加上压缩串),其他情况则为没有压缩的字符,正常加即可。
class Solution {
public:
string decodeString(string s) {
int i = 0;
return decodeSub(s, i);
}
private:
string decodeSub(const string& s, int& i) {
string res;
while (i < s.size() && s[i] != ']') {
if (isdigit(s[i])) {
int num = 0;
while (i < s.size() && isdigit(s[i])) {
num = num * 10 + (s[i] - '0');
i++;
}
if (i < s.size() && s[i] == '[') {
i++; // 跳过左括号
string t = decodeSub(s, i);
for (int j = 0; j < num; j++) {
res += t;
}
}
} else {
res += s[i];
i++;
}
}
if (i < s.size() && s[i] == ']') {
i++;
}
return res;
}
};347.前k个高额元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
其实正确做法应该是用堆排序和优先队列(这种看题就应该想到)
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int,int>store;
int u=nums.size();
for(int i=0;i<u;i++){
store[nums[i]]+=1;
}
map<int,vector<int>>temp;
for(auto it=store.begin();it!=store.end();it++){
int a=it->second;int b=it->first;
temp[a].push_back(b);
}
vector<int>ans;
for(auto it=temp.rbegin();it!=temp.rend();it++){
auto vec=it->second;
if(k>0){
for(int j=0;j<vec.size();j++){
ans.push_back(vec[j]);k--;
}
}
else break;
}
return ans;
}
};338.比特位计数
略。(此为第37题)
337.打家劫舍3

经典的树形dp了!可以看之前acwing的记录:
这类问题都有一个共同点,或者说同时都属于dp问题的状态机类问题,所谓状态机:
当问题的状态转移涉及多个条件或选择时,直接定义状态转移方程可能变得复杂。状态机通过显式地划分状态和转移条件,使动态规划的逻辑更清晰,避免遗漏可能性。(多个dp空间,这里用map存储+树的遍历)
class Solution {
public:
unordered_map<TreeNode*,vector<int>>store;
void search(TreeNode* root){
if(root==nullptr)return;
else if(root->left==nullptr&&root->right==nullptr){
store[root].push_back(0);
store[root].push_back(root->val);
return;
}
else if(root->left==nullptr&&root->right!=nullptr){
search(root->left);search(root->right);
vector<int>t(2,0);
t[0]=max(store[root->right][0],store[root->right][1]);
t[1]=store[root->right][0]+root->val;
store[root]=t;
}
else if(root->left!=nullptr&&root->right==nullptr){
search(root->left);search(root->right);
vector<int>t(2,0);
t[0]=max(store[root->left][0],store[root->left][1]);
t[1]=store[root->left][0]+root->val;
store[root]=t;
}
else{
search(root->left);search(root->right);
vector<int>t(2,0);
t[0]=max(store[root->left][0],store[root->left][1])+max(store[root->right][0],store[root->right][1]);
t[1]=store[root->left][0]+store[root->right][0]+root->val;
store[root]=t;
}
return;
}
int rob(TreeNode* root) {
search(root);
return max(store[root][0],store[root][1]);
}
};121.买卖股票的最佳时期
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
简单题,不难,关键是想清楚思路:不断更新截止到第i天的股票最低点。
class Solution {
public:
int maxProfit(vector<int>& prices) {
int k=prices.size();
int sta=0;int ans=0;
for(int i=0;i<k;i++){
if(prices[sta]>=prices[i]){
sta=i;continue;
}
else if(prices[sta]<prices[i]){
ans=max(ans,prices[i]-prices[sta]);
}
}
return ans;
}
};312.戳气球
有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i + 1] 枚硬币。 这里的 i - 1 和 i + 1 代表和 i 相邻的两个气球的序号。如果 i - 1或 i + 1 超出了数组的边界,那么就当它是一个数字为 1 的气球。
求所能获得硬币的最大数量。
动态规划解决的问题,需要满足三个条件:最优子结构,无后效性和子问题重叠。
第一次戳哪个气球不满足无后效性
那么就试试最后一次戳哪个气球——这是核心!戳最后一个气球!
因为是最后一个被戳爆的,所以它周边没有球了!没有球了!只有这个开区间首尾的 i 和 j 了!!
这就是为什么DP的状态转移方程是只和 i 和 j 位置的数字有关
class Solution {
public:
int maxCoins(vector<int>& nums) {
int n = nums.size();
vector<vector<int>> rec(n + 2, vector<int>(n + 2));
vector<int> val(n + 2);
val[0] = val[n + 1] = 1;
for (int i = 1; i <= n; i++) {
val[i] = nums[i - 1];
}
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 2; j <= n + 1; j++) {
for (int k = i + 1; k < j; k++) {
int sum = val[i] * val[k] * val[j];
sum += rec[i][k] + rec[k][j];
rec[i][j] = max(rec[i][j], sum);
}
}
}
return rec[0][n + 1];
}
};309.买卖股票的最佳时期含冷冻时期
dp神题了——分析状态——多个状态,那么和前面打家劫舍一样多维的dp就行
// f[i][0]: 手上持有股票的最大收益
// f[i][1]: 手上不持有股票,并且处于冷冻期中的累计最大收益
// f[i][2]: 手上不持有股票,并且不在冷冻期中的累计最大收益
class Solution {
public:
int maxProfit(vector<int>& prices) {
if(prices.size()==0)return 0;
int k=prices.size();
vector<vector<int>>dp(k,vector<int>(3));dp[0][0]=-1*prices[0];
for(int i=1;i<k;i++){
//持有股票,要么是i-1才买的,要么是之前买的
dp[i][0]=max(dp[i-1][0],dp[i-1][2]-prices[i]);
//不持有股票且冷冻,只能是前一天卖了
dp[i][1]=dp[i-1][0]+prices[i];
//不持有股票不冷冻,可能是前面卖了
dp[i][2]=max(dp[i-1][1],dp[i-1][2]);
}
return max(dp[k-1][1],dp[k-1][2]);
}
};301.删除无效的括号
给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。
返回所有可能的结果。答案可以按 任意顺序 返回。
valid函数判断s有不有效(即左右括号是否相同),要求返回删最小数量括号后的有效集合,显然是宽度优先搜索!——对于每个括号,都给他删了看是不是有效的。
不错的题,想想思路。
class Solution {
public:
bool isValid(string s) {
int count = 0;
for (char c : s) {
if (c == '(') {
count++;
} else if (c == ')') {
count--;
if (count < 0) return false;
}
}
return count == 0;
}
vector<string> removeInvalidParentheses(string s) {
vector<string> res;
queue<string> q;
unordered_set<string> visited;
q.push(s);
visited.insert(s);
bool found = false;
while (!q.empty()) {
int size = q.size();
unordered_set<string> nextLevelSet;
for (int i = 0; i < size; i++) {
string cur = q.front();
q.pop();
if (isValid(cur)) {
res.push_back(cur);
found = true;
}
if (found) continue;
for (int j = 0; j < cur.size(); j++) {
if (cur[j] != '(' && cur[j] != ')')
continue;
string nextStr = cur.substr(0, j) + cur.substr(j + 1);
if (visited.find(nextStr) == visited.end()) {
nextLevelSet.insert(nextStr);
visited.insert(nextStr);
}
}
}
if (found) break;
for (auto& str : nextLevelSet) {
q.push(str);
}
}
return res;
}
};300.最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
最经典的一道dp题!dp[i][j]表示以i为始(i必选),到j的递增子序列的最长长度,(至少得确定选一个才有dp的必要),所以有:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = (int)nums.size();
if (n == 0) {
return 0;
}
vector<int> dp(n, 0);
for (int i = 0; i < n; ++i) {
dp[i] = 1;
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}
return *max_element(dp.begin(), dp.end());
}
};但是显然,dp复杂度为n^2(题目n最大2500)
如何优化到nlogn?
需要记住一个点——dp的数组本身,其实是具有单调性的!
此题在acwing中亦有记载
297.二叉树的序列化与反序列化
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
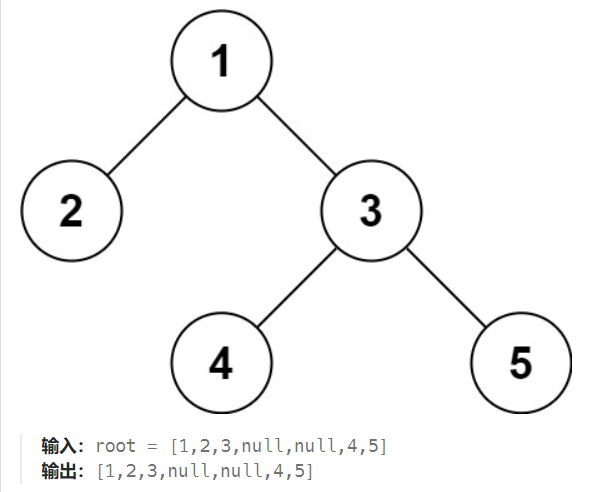
本质上是考查层序遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
if (root == nullptr) return ""; // 处理空树
queue<TreeNode*> store;
string ret = "";
store.push(root);
while (!store.empty()) {
TreeNode* now = store.front(); // 获取队首节点
store.pop(); // 必须先弹出,避免死循环
// 如果当前节点为空,添加 "n"
if (now == nullptr) {
ret += "n";
} else {
ret += to_string(now->val); // 添加数字值(可能多位数)
store.push(now->left); // 将左右子节点推入队列(即使为空)
store.push(now->right);
}
// 添加分隔符(逗号),除非是最后一个元素
if (!store.empty()) {
ret += ",";
}
}
return ret;
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
if (data.empty()) return nullptr; // 空字符串返回空树
// 将字符串按逗号分割为令牌列表
vector<string> tokens;
string token;
istringstream iss(data);
while (getline(iss, token, ',')) {
tokens.push_back(token);
}
if (tokens.empty() || tokens[0] == "n") return nullptr;
// 创建根节点
TreeNode* root = new TreeNode(stoi(tokens[0]));
queue<TreeNode*> q;
q.push(root);
int i = 1; // 令牌索引,从第一个子节点开始
while (!q.empty() && i < tokens.size()) {
TreeNode* node = q.front(); // 获取当前节点以添加子节点
q.pop();
// 处理左子节点
if (i < tokens.size() && tokens[i] != "n") {
node->left = new TreeNode(stoi(tokens[i])); // stoi 处理多位数
q.push(node->left);
}
i++; // 移动到下一个令牌
// 处理右子节点
if (i < tokens.size() && tokens[i] != "n") {
node->right = new TreeNode(stoi(tokens[i]));
q.push(node->right);
}
i++; // 移动到下一个令牌
}
return root;
}
};
// Your Codec object will be instantiated and called as such:
// Codec ser, deser;
// TreeNode* ans = deser.deserialize(ser.serialize(root));287.寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
Floyd判圈算法——快慢指针
class Solution {
public:
int findDuplicate(vector<int>& nums) {
int slow = 0, fast = 0;
// 第一阶段:寻找相遇点
do {
slow = nums[slow]; // 慢指针走一步
fast = nums[nums[fast]]; // 快指针走两步
} while (slow != fast); // 持续直到相遇
// 第二阶段:找到环入口(重复数)
int slow2 = 0;
while (slow != slow2) {
slow = nums[slow];
slow2 = nums[slow2];
}
return slow; // 返回重复数
}
};283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
核心就是那个注意点,需要意识到,令一个变量po统计非零的个数,po的值肯定小于等于遍历时数组下标i(因为它只有数非0才++),这就意味着,我修改数组时,po的位置处已经被遍历了没有用了。
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int po=0;int k=nums.size();
for(int i=0;i<k;i++){
if(nums[i]==0)continue;
else{
nums[po++]=nums[i];
}
}
for(int i=po;i<k;i++)nums[i]=0;
return;
}
};279.完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
从某种意义上讲,能用搜索搞的是不是都可以往dp想?
——dp的思想其实就是把一类子问题当成一个看待(或者说一个集合),这也是闫式dp的思想
——如果一个问题,可以由子问题组成,那么应该就可以用dp?
——所以先判断dp能不能用!即先看这个集合能不能被拆成更小的子集合!
——显然这里是可以的,即dp[i]=min(dp[i],dp[i-j]+dp[j]);
class Solution {
public:
bool judge(int i){
for(int z=0;z<=i;z++){
if(z*z<i)continue;
else if(z*z==i)return true;
else if(z*z>i)break;
}
return false;
}
int numSquares(int n) {
vector<int>dp(n+5,0);
for(int i=0;i<=n;i++)dp[i]=i;
dp[1]=1;dp[4]=1;
for(int i=1;i<=n;i++){
if(judge(i)){
dp[i]=1;continue;
}
for(int j=1;j<i;j++){
dp[i]=min(dp[i],dp[i-j]+dp[j]);
}
}
for(int i=1;i<=n;i++)cout<<dp[i]<<" ";
return dp[n];
}
};240.搜索二维矩阵2
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。

核心就一个点——从右上角看,构成是一个排序的二叉树!(看到题想到这个就行)
class Solution {
public:
bool ans;
bool trace(int x,int y,vector<vector<int>>& matrix,int target){
int m=matrix.size();int n=matrix[0].size();
if(y==-1||x==m){
return false;
}
if(matrix[x][y]==target){
ans=true;
return true;
}
else if(matrix[x][y]<target){
return trace(x+1,y,matrix,target);
}
else if(matrix[x][y]>target){
return trace(x,y-1,matrix,target);
}
return false;
}
bool searchMatrix(vector<vector<int>>& matrix, int target) {
ans=false;
trace(0,matrix[0].size()-1,matrix,target);
return ans;
}
};22.括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
经典搜索框架了,搜索类题注意的就是边界条件!(一定小心)
class Solution {
public:
vector<string>ans;
void trace(int left,int right,int n,string&t){
if(left>n||right>n)return;
if(left==right&&left==n){
ans.push_back(t);
return;
}
if(left>right){
t.push_back('(');
trace(left+1,right,n,t);
t.pop_back();
t.push_back(')');;
trace(left,right+1,n,t);
t.pop_back();
}
else if(left==right){
t.push_back('(');
trace(left+1,right,n,t);
t.pop_back();
}
else if(left<right)return;
}
vector<string> generateParenthesis(int n) {
string temp="";
trace(0,0,n,temp);
return ans;
}
};49.字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
异位词的核心是找一个基准!——比如找升序排列(string可以sort cba变为abc)
相同的异位词sort后相等,就可以用map存储。
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>>mmap;
for(auto str:strs){
string t=str;
sort(t.begin(),t.end());
mmap[t].push_back(str);
}
vector<vector<string>>ans;
for(auto it=mmap.begin();it!=mmap.end();it++){
ans.push_back(it->second);
}
return ans;
}
};48.旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
核心:分层四元素交换!
遍历每边元素(除最后一个,避免重复):
- 同时交换四个位置的元素(上→右→下→左→上)。
class Solution {
public:
int n;
void subrot(vector<vector<int>>& matrix, int z) {
int len = n - 2 * z; // 当前层边长
for (int i = 0; i < len - 1; i++) {
int temp = matrix[z][z + i]; // 保存上边
// 左 → 上(左边从下往上取元素)
matrix[z][z + i] = matrix[n - 1 - z - i][z];
// 下 → 左(下边从右往左取元素)
matrix[n - 1 - z - i][z] = matrix[n - 1 - z][n - 1 - z - i];
// 右 → 下(右边从上往下取元素)
matrix[n - 1 - z][n - 1 - z - i] = matrix[z + i][n - 1 - z];
// 上 → 右(用保存的上边元素)
matrix[z + i][n - 1 - z] = temp;
}
}
void rotate(vector<vector<int>>& matrix) {
n = matrix.size();
// 逐层处理从外层(0)到内层(n/2 - 1)
for (int i = 0; i < n / 2; i++) {
subrot(matrix, i);
}
}
};46.全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
同样是非常基础的搜索题,搜索题模板。明晰标记与回退
class Solution {
public:
int book[15];
vector<vector<int>>ans;
vector<int>t;
void trace(int step,vector<int>&nums){
if(step==nums.size()){
ans.push_back(t);
return ;
}
for(int i=0;i<nums.size();i++){
if(book[i])continue;
else{
book[i]=1;
t.push_back(nums[i]);
trace(step+1,nums);
book[i]=0;
t.pop_back();
}
}
return;
}
vector<vector<int>> permute(vector<int>& nums) {
trace(0,nums);
return ans;
}
};42.接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
一种做法是一行一行来——显然是会超时的(时间复杂度m*n)
class Solution {
public:
int trap(vector<int>& height) {
int ans=0;int k=height.size()-1;int count=0;
while(true){
int l=-1;int r=k+1;
for(int i=0;i<=k;i++){
if(height[i]!=0){
l=i;break;
}
}
for(int i=k;i>=0;i--){
if(height[i]!=0){
r=i;break;
}
}
if(l>=r||l==-1||r==k+1){
return ans;
}
for(int i=l;i<=r;i++){
if(height[i]==0)ans++;
else if(height[i]>0)height[i]-=1;
}
}
return ans;
}
};基本上,看到接雨水这类题,就得想到双指针!
- 维护两个指针
left和right,以及两个变量left_max和right_max分别记录左右遍历时的最大高度。 - 在每个位置,能接的雨水量取决于当前侧的最大高度与当前柱子高度之差。
- 从左边的视角看整个数组,看过去;再从右边的视角看!
class Solution {
public:
int trap(vector<int>& height) {
int n=height.size();
if(n<=2)return 0;
int l=0;int r=n-1;
int ans=0;int l_max=0;int r_max=0;
while(l<r){
//先把满足左边部分的求了
if(height[l]<height[r]){
if(height[l]>=l_max)l_max=height[l];
else{
//height[l]<l_max,height[l]<height[r]
//即在前面部分有左边挡板l_max,后面有右边挡板,此时可以接
ans+=l_max-height[l];
}
l++;
}
//右边指针的高度更小或相等
//一样的,求右边部分的影响
else{
if(height[r]>=r_max)r_max=height[r];
else ans+=r_max-height[r];
r--;
}
}
return ans;
}
};39.组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
这里不再是简单的搜索就行,还涉及到对结果的去重,套用前面的做法似乎不太现实:unordered_set 需要自定义哈希函数才能存储 vector<int>,没有的话会编译报错。
所以只能从根源入手——遍历时限制其实的位置,让它不要找以前的
(每次遍历时的i=start也保证了该元素的可重复性)
class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> ans;
vector<int> path;
backtrack(0, target, candidates, path, ans);
return ans;
}
void backtrack(int start, int target, vector<int>& candidates,
vector<int>& path, vector<vector<int>>& ans) {
if (target < 0) return;
if (target == 0) {
ans.push_back(path);
return;
}
for (int i = start; i < candidates.size(); i++) {
path.push_back(candidates[i]);
backtrack(i, target - candidates[i], candidates, path, ans);
path.pop_back();
}
}
};543.二叉树的直径
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
涉及数的递归时刻记住递归的意义!——trace表示子树的深度
class Solution {
public:
int ans;
int trace(TreeNode* root){
if(root==nullptr)return 0;
int le=trace(root->left);
int ri=trace(root->right);
ans=max(ans,le+ri);
cout<<ans<<" ";
return max(le,ri)+1;
}
int diameterOfBinaryTree(TreeNode* root) {
ans=0;
trace(root);
return ans;
}
};34.在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
也是经典题了!——核心是考查对二分搜索的理解
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
if(nums.empty())return {-1,-1};
int le=0;int ri=nums.size()-1;
while(le<ri){
int mid=le+(ri-le)/2;
if(target>nums[mid]){
le=mid+1;
}
else if(target<=nums[mid]){
ri=mid;
}
}
if(target!=nums[le])le=-1;
int a=le;le=0;ri=nums.size()-1;
while(le<ri){
int mid=le+(ri-le+1)/2;
if(target>=nums[mid]){
le=mid;
}
else if(target<nums[mid]){
ri=mid-1;
}
}
if(target!=nums[le])le=-1;
int b=le;
return {a,b};
}
};无非就是两次搜索,一次确定左边,一次确定右边。如何使二分搜索按照左边界和按照右边界搜?
左边界——对左边动,即le+1 右边界,对右边动,即ri-1;
运用迭代来实现二分 然后注意确定边界通过while来,le>=ri时退出。
33.搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题
本题的核心在于对顺序数组进行二分,所以要记住——与nums[0]进行判断,然后两次if判断都是针对每个部分的顺序数组做二分!
class Solution {
public:
int search(vector<int>& nums, int target) {
int k=nums.size();
if(k==1){
return nums[0]==target?0:-1;
}
int le=0;int ri=k-1;
while(le<=ri){
int mid=(le+ri)/2;
if(nums[mid]==target)return mid;
if(nums[mid]>=nums[0]){
//高部分的顺序
if(target<nums[mid]&&target>=nums[0]){
ri=mid-1;
}
else le=mid+1;
}
else{
//低部分的顺序
if(target>nums[mid]&&target<=nums[k-1]){
le=mid+1;
}
else ri=mid-1;
}
}
return -1;
}
};32.最长有效扩号
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
输入:s = "(()" 输出:2 解释:最长有效括号子串是 "()"
无敌思路:
- 用栈模拟一遍,将所有无法匹配的括号的位置全部置1
- 例如: "()(()"的mark为[0, 0, 1, 0, 0]
- 再例如: ")()((())"的mark为[1, 0, 0, 1, 0, 0, 0, 0]
- 经过这样的处理后, 此题就变成了寻找最长的连续的0的长度
真无敌这思路,开背 ——将括号以数字代替,转化为连续数字的问题!
class Solution {
public:
int longestValidParentheses(string s) {
stack<int> st;
vector<bool> mark(s.length());
for(int i = 0; i < mark.size(); i++) mark[i] = 0;
int left = 0, len = 0, ans = 0;
for(int i = 0; i < s.length(); i++) {
if(s[i] == '(') st.push(i);
else {
// 多余的右括号是不需要的,标记
if(st.empty()) mark[i] = 1;
else st.pop();
}
}
// 未匹配的左括号是不需要的,标记
while(!st.empty()) {
mark[st.top()] = 1;
st.pop();
}
// 寻找标记与标记之间的最大长度
for(int i = 0; i < s.length(); i++) {
if(mark[i]) {
len = 0;
continue;
}
len++;
ans = max(ans, len);
}
return ans;
}
};31.下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
- 例如,
arr = [1,2,3],以下这些都可以视作arr的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1]。
整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 下一个排列 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
- 例如,
arr = [1,2,3]的下一个排列是[1,3,2]。 - 类似地,
arr = [2,3,1]的下一个排列是[3,1,2]。 - 而
arr = [3,2,1]的下一个排列是[1,2,3],因为[3,2,1]不存在一个字典序更大的排列。
给你一个整数数组 nums ,找出 nums 的下一个排列。
必须 原地 修改,只允许使用额外常数空间。
思路!
例如 2, 6, 3, 5, 4, 1 这个排列, 我们想要找到下一个刚好比他大的排列,于是可以从后往前看
我们先看后两位 4, 1 能否组成更大的排列,答案是不可以,同理 5, 4, 1也不可以
直到3, 5, 4, 1这个排列,因为 3 < 5, 我们可以通过重新排列这一段数字,来得到下一个排列
因为我们需要使得新的排列尽量小,所以我们从后往前找第一个比3更大的数字,发现是4
然后,我们调换3和4的位置,得到4, 5, 3, 1这个数列
因为我们需要使得新生成的数列尽量小,于是我们可以对5, 3, 1进行排序,可以发现在这个算法中,我们得到的末尾数字一定是倒序排列的,于是我们只需要把它反转即可
最终,我们得到了4, 1, 3, 5这个数列
完整的数列则是2, 6, 4, 1, 3, 5
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int n = nums.size();
int i = n - 2;
// 从后向前找第一个升序的位置(即 nums[i] < nums[i+1])
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
if (i >= 0) {
int j = n - 1;
// 从后向前找第一个大于 nums[i] 的数
while (j > i && nums[j] <= nums[i]) {
j--;
}
swap(nums[i], nums[j]);
}
// 反转 i 之后的部分(无论 i 是否找到)
reverse(nums.begin() + i + 1, nums.end());
}
};再次凝练核心思路三部分:
- 从右往左查找第一个升序位置:我们需要找到最右边的一个位置
i,使得nums[i] < nums[i + 1]。这个位置i是可以增大的位置,因为其右侧的子数组已经是降序排列,无法再增大。 - 从右往左查找第一个更大元素:如果找到了这样的位置
i,我们需要从右往左找到第一个比nums[i]大的元素nums[j]。 - 交换这两个元素:交换
nums[i]和nums[j],这样可以确保当前排列尽可能小地增大。 - 反转右侧子数组:由于
i右侧的子数组原本是降序排列的,交换后仍然保持降序,因此反转该子数组可以使其变为升序,从而得到最小的下一个排列。
538.把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
使用反中序遍历(右-根-左)并维护一个全局累加和!
class Solution {
public:
void traverse(TreeNode* root, int& sum) {
if (!root) return;
traverse(root->right, sum);
sum += root->val; // 累加当前节点的原始值
root->val = sum; // 更新当前节点为累加和
traverse(root->left, sum);
}
TreeNode* convertBST(TreeNode* root) {
int sum = 0;
traverse(root, sum);
return root;
}
};23.合并k个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6
也不知道这样算不算偷鸡,用一个map存储(利用map的自动排序特性),反正能过,效率还高
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
map<int,vector<ListNode*>>store;
int k=lists.size();
for(int i=0;i<k;i++){
ListNode* sta=lists[i];
while(sta!=nullptr){
store[sta->val].push_back(sta);
sta=sta->next;
}
}
ListNode* root=new ListNode(-1);ListNode*pre=root;
for(auto it=store.begin();it!=store.end();it++){
auto vec=it->second;
for(ListNode* li:vec){
pre->next=li;
pre=pre->next;
}
}
return root->next;
}
};一种更加通用的做法是优先队列
需要维护当前每个链表没有被合并的元素的最前面一个,k 个链表就最多有 k 个满足这样条件的元素,每次在这些元素里面选取 val 属性最小的元素合并到答案中。在选取最小元素的时候,我们可以用优先队列来优化这个过程。
class Solution {
public:
struct Status {
int val;
ListNode *ptr;
bool operator < (const Status &rhs) const {
return val > rhs.val;
}
};
priority_queue <Status> q;
ListNode* mergeKLists(vector<ListNode*>& lists) {
for (auto node: lists) {
if (node) q.push({node->val, node});
}
ListNode head, *tail = &head;
while (!q.empty()) {
auto f = q.top(); q.pop();
tail->next = f.ptr;
tail = tail->next;
if (f.ptr->next) q.push({f.ptr->next->val, f.ptr->next});
}
return head.next;
}
};560.和为k的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
这题不是滑动窗口,滑动窗口需要满足窗口的性质单一,如果出现负数,那么不好判断是right++还是left--。
应用前缀和。
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
vector<int>partsum;int z=nums.size();int store=0;
for(int i=0;i<z;i++){
store+=nums[i];partsum.push_back(store);
}
int ans=0;
for(int i=0;i<z;i++){
if(partsum[i]==k)ans++;
for(int j=0;j<i;j++){
if(partsum[i]-partsum[j]==k)ans++;
}
}
return ans;
}
};前缀和能过,不过n^2的复杂度是可以被优化的——经常和前缀和捆一起的是哈希!
所以需要学习进阶的思想:

class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
unordered_map<int, int> mp;
mp[0] = 1;
int count = 0, pre = 0;
for (auto& x:nums) {
pre += x;
if (mp.find(pre - k) != mp.end()) {
count += mp[pre - k];
}
mp[pre]++;
}
return count;
}
};21.合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
链表的基础题。
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode*head=new ListNode(-101);ListNode* mark=head;
ListNode*p=list1;ListNode*q=list2;
while(p!=nullptr&&q!=nullptr){
if(p->val<=q->val){
mark->next=p;
mark=mark->next;
p=p->next;
}
else if(p->val>q->val){
mark->next=q;
mark=mark->next;
q=q->next;
}
}
if(q!=nullptr)mark->next=q;
else if(p!=nullptr)mark->next=p;
return head->next;
}
};20.有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
要注意的一个点是这里需要考虑括号的顺序!因此无法通过简单的统计括号数量来做(这和之前单类型括号不一样),无法检测([)]这种错误。
所以还是需要使用栈
class Solution {
public:
bool isValid(string s) {
stack<char> st;
for (char c : s) {
if (c == '(' || c == '{' || c == '[') {
st.push(c);
} else {
if (st.empty()) return false; // 栈空说明右括号多余
char top = st.top();
st.pop();
// 检查最近左括号是否匹配当前右括号
if ((c == ')' && top != '(') ||
(c == '}' && top != '{') ||
(c == ']' && top != '[')) {
return false;
}
}
}
return st.empty(); // 栈空说明所有括号匹配
}
};19.删除链表的倒数第N个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
古朴的存每个结点,删了之后再组合,显然是无法匹配本题中等的难度的。
这种一趟扫描就可以解决的问题——使用快慢指针!(经典套路了)
快慢指针,快指针先走n步,然后快慢一起走,直到快指针走到最后,要注意的是可能是要删除第一个节点,这个时候可以直接返回head -> next
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* fast=head;ListNode* slow=head;ListNode* slowfront=head;
for(int i=0;i<n;i++)fast=fast->next;
while(fast!=nullptr){
fast=fast->next;
slowfront=slow;
slow=slow->next;
}
slowfront->next=slow->next;
if(slow==head)return head->next;
return head;
}
};17.电话号码的字母组合

哈希表存电话按键,然后套经典的回溯框架。
class Solution {
public:
unordered_map<char,string>mmap{
{'2', "abc"},
{'3', "def"},
{'4', "ghi"},
{'5', "jkl"},
{'6', "mno"},
{'7', "pqrs"},
{'8', "tuv"},
{'9', "wxyz"}
};
vector<string>ans;
void trace(const string&digits,int step,string&t){
if(step==digits.size()){
ans.push_back(t);return;
}
string s=mmap[digits[step]];
for(int i=0;i<s.size();i++){
t.push_back(s[i]);
trace(digits,step+1,t);
t.pop_back();
}
return ;
}
vector<string> letterCombinations(string digits) {
string t="";t.clear();
if(digits.empty())return ans;
trace(digits,0,t);
return ans;
}
};15.三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
如果固定一个数的话,那么就变为双数之和问题。本题的核心在于如何去重。
去重肯定首先是排序!考虑到排序之后相同的元素变为相邻的,所以可以使用左右指针,当满足三数为0时,跳过相邻重复的
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<vector<int>> ans;
int n = nums.size();
for (int i = 0; i < n - 2; i++) {
if (nums[i] > 0) break; // 提前终止
if (i > 0 && nums[i] == nums[i - 1]) continue; // 跳过重复的固定数
int left = i + 1, right = n - 1;
while (left < right) {
int s = nums[i] + nums[left] + nums[right];
if (s < 0) {
left++;
} else if (s > 0) {
right--;
} else {
ans.push_back({nums[i], nums[left], nums[right]});
// 跳过左右指针的重复值
while (left < right && nums[left] == nums[left + 1]) left++;
while (left < right && nums[right] == nums[right - 1]) right--;
left++;
right--;
}
}
}
return ans;
}
};11.盛水最多的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
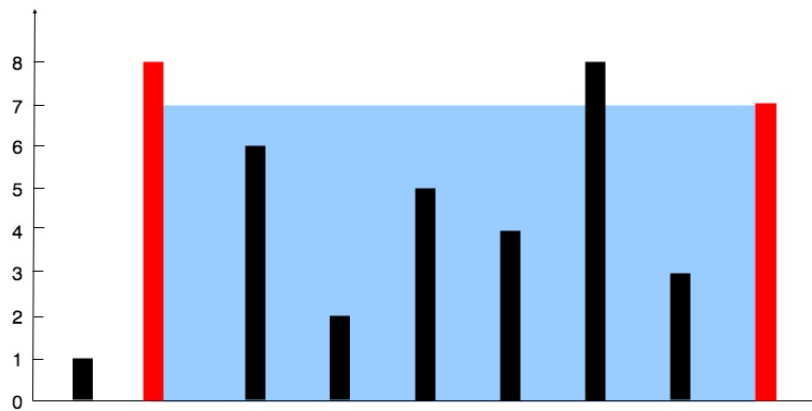
n可取到10^5,所以两次循环是不行的,只有nlogn和n复杂度会考虑,优先考虑n。
想到双指针,并结合贪心——必须清楚一个点: 双指针的话容器的长是确定的:right-left,而容器的最大容量就受限于两边柱子的最小值
换而言之,无论这个柱子有多高,只要另一个柱子低,总体容量就是低
也就明晰了贪心的策略:如果左边柱子低,那么left++;如果右边柱子低,那么right--
class Solution {
public:
int maxArea(vector<int>& height) {
int ans=0;int left=0;int right=height.size()-1;
while(left<right){
if(height[left]<=height[right]){
ans=max(ans,height[left]*(right-left));
left++;
}
else if(height[left]>height[right]){
ans=max(ans,height[right]*(right-left));
right--;
}
}
return ans;
}
};10.正则表达式匹配
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.'匹配任意单个字符'*'匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s 的,而不是部分字符串。
输入:s = "ab", p = ".*" 输出:true 解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
这里大模拟肯定是不行的,匹配任意字符情况很多。想到dp——匹配其实和前一个状态密切相关
思路有人总结的很好:
子串匹配的题目,不由自主的先想DP。。。
DP分两步
- 定义状态
- 定义状态转移方程
1. 状态
dp[i][j]表示s[..i]与p[..j]是否能够匹配。dp[s.size()-1][p.size()-1]即为本题答案。
2. 状态转移
明显能看出状态dp[i][j]和前面的状态有关系,我们逐个条件分析。
2.1 s[i]==p[j] 或者 p[j]=='.'
此时dp[i][j] = dp[i-1][j-1]
2.2 s[i]与p[j]不匹配,并且p[j] != '*'
如果2.1不成立,并且p[j]也不是通配符'*',那没辙了,直接返回匹配失败。
2.3 s[i]与p[j]虽然不匹配,但是p[j] == '*'
这就要分两种情况了,要看p[j-1]和s[i]是否匹配。
- 如果
p[j-1]和s[i]不匹配,那'*'只能把前元素p[j-1]匹配成0个 - 如果
p[j-1]和s[i]可以匹配,那'*'就可以把前元素p[j-1]匹配成0个,1个,多个。
class Solution {
public:
bool isMatch(string s, string p) {
int m = s.length(), n = p.length();
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
//空模式匹配空字符串
dp[0][0] = true;
// 初始化第一行
for (int j = 2; j <= n; j++) {
if (p[j - 1] == '*') {
dp[0][j] = dp[0][j - 2];
}
}
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 直接匹配的情况:相同字符或通配符'.'
if (p[j - 1] == '.' || p[j - 1] == s[i - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
// 处理'*'匹配的情况
else if (j >= 2 && p[j - 1] == '*') {
// 情况1:匹配0个前一字符
dp[i][j] = dp[i][j - 2];
// 情况2:匹配1个或多个前一字符(需检查前一字符匹配)
if (!dp[i][j] && (p[j - 2] == '.' || p[j - 2] == s[i - 1])) {
dp[i][j] = dp[i - 1][j];
}
}
}
}
return dp[m][n];
}
};5.最长回文子串
给你一个字符串 s,找到 s 中最长的 回文 子串。
神奇的是暴力的优化也能过,效率还可以。(从最长长度开始枚举,如果有满足立刻返回)
class Solution {
public:
bool check(const string&s,int le,int ri){
while(le<=ri){
if(s[le]==s[ri]){
le++;ri--;continue;
}
else return false;
}
return true;
}
string longestPalindrome(string s) {
int k=s.size();
for(int i=k;i>=1;i--){
for(int j=0;j+i<=k;j++){
if(check(s,j,j+i-1)){
return s.substr(j,i);
}
}
}
string ss="";
return ss;
}
};其实本题的主要思路有两个,首先是动态规划:P(i,j)=P(i+1,j−1)∧(Si==Sj) 它的边界条件:
P(i,i)=true P(i,i+1)=(Si==Si+1)
另一种比较常见的思路:枚举每一个回文中心并拓展!直到无法拓展为止
4.寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
当 m+n 是奇数时,中位数是两个有序数组中的第 (m+n)/2 个元素,当 m+n 是偶数时,中位数是两个有序数组中的第 (m+n)/2 个元素和第 (m+n)/2+1 个元素的平均值。因此,这道题可以转化成寻找两个有序数组中的第 k 小的数,其中 k 为 (m+n)/2 或 (m+n)/2+1。
要找到第 k 个元素,我们可以比较 A[k/2−1] 和 B[k/2−1]——一次能排除0-k/2-1个
class Solution {
public:
int getkth(const vector<int>&nums1,const vector<int>&nums2,int k){
int m=nums1.size();int n=nums2.size();int index1=0;int index2=0;
while(1){
//边界情况,一个vector为空
if(index1==m)return nums2[index2+k-1];
if(index2==n)return nums1[index1+k-1];
if(k==1)return min(nums1[index1],nums2[index2]);
int newindex1=min(index1+k/2-1,m-1);
int newindex2=min(index2+k/2-1,n-1);
if(nums1[newindex1]<=nums2[newindex2]){
//nums1的前k/2-1个被排除
k-=newindex1-index1+1;
index1=newindex1+1;
}
else{
k-=newindex2-index2+1;
index2=newindex2+1;
}
}
}
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
int totlen=nums1.size()+nums2.size();
if(totlen%2==1)return getkth(nums1,nums2,totlen/2+1);
else return (getkth(nums1,nums2,totlen/2)+getkth(nums1,nums2,totlen/2+1))/2.0;
}
};3.无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
使用哈希表,然后一次遍历
class Solution {
public:
int lengthOfLongestSubstring(string s) {
unordered_map<char,int>mmap;
if(s.size()==0)return 0;
int k=s.size();int ans=0;int sta=0;
for(int i=0;i<k;i++){
if(mmap.find(s[i])==mmap.end()){
mmap[s[i]]=i;ans=max(ans,i-sta+1);
}
else{
for(int j=sta;j<mmap[s[i]];j++)mmap.erase(s[j]);
sta=mmap[s[i]]+1;
mmap[s[i]]=i;
}
}
return ans;
}
};其实也就是官解给出的滑动窗口思想。注意一些stl:
| erase(key_value) | O ( l o g N ) | 删除键值key_value的值 |
| erase(iterator) | O ( l o g N ) | 删除定位器iterator指向的值 |
| erase(first, second) | 删除定位器first和second之间的值 |
2.两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
第一点是这个链表长度可达100位,所以转化成整形再相加是不可能的。这题没有思路,考查的就是高精加。
class Solution {
public:
void trace(ListNode* &l1,string &s){
ListNode* p=l1;char ch;
while(p!=nullptr){
ch=p->val+'0';
s.push_back(ch);
p=p->next;
}
// reverse(s.begin(),s.end());
return ;
}
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
string s1="";string s2="";string s3="";
trace(l1,s1);trace(l2,s2);int p=0;int t=0;
for(int i=0;i<min(s1.size(),s2.size());i++){
p=(s1[i]-'0')+(s2[i]-'0')+t;
s3.push_back(p%10+'0');
t=p/10;
}
if(s1.size()>s2.size()){
for(int i=s2.size();i<s1.size();i++){
p=(s1[i]-'0')+t;
s3.push_back(p%10+'0');
t=p/10;
}
}
else if(s1.size()<=s2.size()){
for(int i=s1.size();i<s2.size();i++){
p=(s2[i]-'0')+t;
s3.push_back(p%10+'0');
t=p/10;
}
}
while(t!=0){
s3.push_back(t%10+'0');
t/=10;
}
ListNode* prehead=new ListNode(-1);
ListNode* pre=prehead;
for(int i=0;i<s3.size();i++){
ListNode* q=new ListNode(s3[i]-'0');
pre->next=q;
pre=pre->next;
}
return prehead->next;
}
};79.单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用
深搜的模板,注意剪枝思想的利用。
class Solution {
public:
bool ans;
int book[10][10];
int m, n;
void dfs(const vector<vector<char>>& board, const string& word, int step, int x, int y) {
if (ans) return;
if (board[x][y] != word[step]) return;
if (step == word.size() - 1) {
ans = true;
return;
}
book[x][y] = 1;
int dire[4][2] = {{0,1}, {1,0}, {0,-1}, {-1,0}};
for (int i = 0; i < 4; i++) {
int tx = x + dire[i][0];
int ty = y + dire[i][1];
if (tx < 0 || tx >= m || ty < 0 || ty >= n) continue;
if (book[tx][ty] || board[tx][ty] != word[step+1]) continue;
dfs(board, word, step+1, tx, ty);
if (ans) break;
}
book[x][y] = 0;
}
bool exist(vector<vector<char>>& board, string word) {
m = board.size();
n = board[0].size();
ans = false;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == word[0]) {
memset(book, 0, sizeof(book));
dfs(board, word, 0, i, j);
if (ans) return true;
}
}
}
return false;
}
};114.二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
注意一个小点:TreeNode* p,q; // 错误:q 被声明为 TreeNode 对象而非指针
TreeNode *p, *q; // 正确:p 和 q 都是指针 声明的细节!
class Solution {
public:
vector<TreeNode*>store;
void dfs(TreeNode* root){
if(root==nullptr)return;
store.push_back(root);
dfs(root->left);
dfs(root->right);
return;
}
void flatten(TreeNode* root) {
if(root==nullptr)return;
dfs(root);
for(int i=0;i<store.size()-1;i++){
store[i]->left = nullptr;
store[i]->right = store[i + 1];
}
store.back()->left = nullptr;
store.back()->right = nullptr;
return;
}
};621.任务调度器
给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表,用字母 A 到 Z 表示,以及一个冷却时间 n。每个周期或时间间隔允许完成一项任务。任务可以按任何顺序完成,但有一个限制:两个 相同种类 的任务之间必须有长度为 n 的冷却时间。
返回完成所有任务所需要的 最短时间间隔 。
输入:tasks = ["A","A","A","B","B","B"], n = 2
输出:8
题解清晰易懂,注意分析就好。
code block /**
* 解题思路:
* 1、将任务按类型分组,正好A-Z用一个int[26]保存任务类型个数
* 2、对数组进行排序,优先排列个数(count)最大的任务,
* 如题得到的时间至少为 retCount =(count-1)* (n+1) + 1 ==> A->X->X->A->X->X->A(X为其他任务或者待命)
* 3、再排序下一个任务,如果下一个任务B个数和最大任务数一致,
* 则retCount++ ==> A->B->X->A->B->X->A->B
* 4、如果空位都插满之后还有任务,那就随便在这些间隔里面插入就可以,因为间隔长度肯定会大于n,在这种情况下就是任务的总数是最小所需时间
*/
public int leastInterval(char[] tasks, int n) {
if (tasks.length <= 1 || n < 1) return tasks.length;
//步骤1
int[] counts = new int[26];
for (int i = 0; i < tasks.length; i++) {
counts[tasks[i] - 'A']++;
}
//步骤2
Arrays.sort(counts);
int maxCount = counts[25];
int retCount = (maxCount - 1) * (n + 1) + 1;
int i = 24;
//步骤3
while (i >= 0 && counts[i] == maxCount) {
retCount++;
i--;
}
//步骤4
return Math.max(retCount, tasks.length);
}
617.合并二叉树
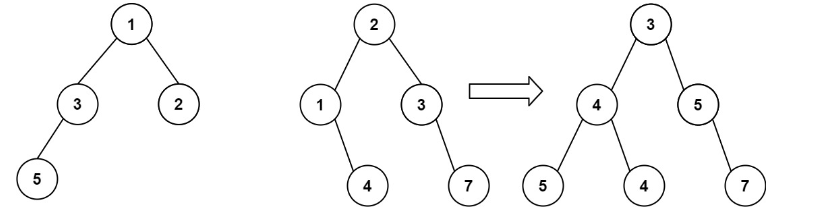
提醒我们一个事,写树的递归时返回值不仅仅局限于void,如果发现void不好写,尝试换为treenode。
官解写的很漂亮(最漂亮的一集)
class Solution {
public:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
if (t1 == nullptr) {
return t2;
}
if (t2 == nullptr) {
return t1;
}
auto merged = new TreeNode(t1->val + t2->val);
merged->left = mergeTrees(t1->left, t2->left);
merged->right = mergeTrees(t1->right, t2->right);
return merged;
}
};105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
也是板子题了,递归,和之前一样,返回的是node节点,这里我用queue,这样每次弹出来的都是根节点,就可以不用管序号了。 此外,注意下递归刚开始的边界条件
class Solution {
public:
TreeNode* construct(queue<int>&que,vector<int>&inorder,int l,int r){
if(que.empty()||l>r)return nullptr;
int v=que.front();que.pop();
TreeNode* root=new TreeNode(v);
if(l==r)return root;
int k=0;
for(int i=l;i<=r;i++){
if(inorder[i]==v){
k=i;break;
}
}
root->left=construct(que,inorder,l,k-1);
root->right=construct(que,inorder,k+1,r);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
queue<int>que;
for(int num:preorder)que.push(num);
return construct(que,inorder,0,inorder.size()-1);
}
};104.二叉树的最大深度
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
简单题,递归就行。
class Solution {
public:
int ans;
void dfs(TreeNode* root,int step){
if(root==nullptr){
ans=max(ans,step);return;
}
dfs(root->left,step+1);
dfs(root->right,step+1);
return;
}
int maxDepth(TreeNode* root) {
ans=0;
dfs(root,0);
return ans;
}
};102.二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
层序遍历模板题。这里用vector而不是用queue的原因是后续输出的时候还要遍历一遍。
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>>ans;
if(root==nullptr)return ans;
vector<TreeNode*>store;unordered_map<TreeNode*,int>layer;
store.push_back(root);int sta=0;int end=1;layer[root]=0;
TreeNode* p= new TreeNode(-1);
while(sta!=end){
p=store[sta];
if(p->left!=nullptr){
store.push_back(p->left);end++;
layer[p->left]=layer[p]+1;
}
if(p->right!=nullptr){
store.push_back(p->right);end++;
layer[p->right]=layer[p]+1;
}
sta++;
}
vector<int>t;
for(int i=0;i<store.size();i++){
t.push_back(store[i]->val);
if(i==store.size()-1||layer[store[i]]!=layer[store[i+1]]){
ans.push_back(t);
t.clear();
}
}
return ans;
}
};101.对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
通过中序遍历,然后判断vector是不是回文的做法是行不通的,因为节点的值可能会相同,光从值上判断是不对的,比如对下面的例子就会报错:
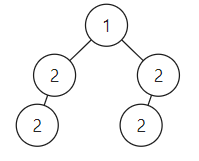
正确做法还是递归!
class Solution {
public:
bool check(TreeNode*p,TreeNode*q){
if(p==nullptr&&q==nullptr)return true;
else if(p==nullptr&&q!=nullptr)return false;
else if(q==nullptr&&p!=nullptr)return false;
if(check(p->left,q->right)&&check(p->right,q->left)&&p->val==q->val)return true;
else return false;
}
bool isSymmetric(TreeNode* root) {
return check(root->left,root->right);
}
};98.验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
注意:BST要求整个左子树的所有节点都小于当前节点,整个右子树的所有节点都大于当前节点(而不是简单的检查当前节点的直接左子节点和右子节点),所以需要一个min和max来存储
class Solution {
public:
bool isValidBST(TreeNode* root) {
return isValid(root, nullptr, nullptr);
}
bool isValid(TreeNode* root, TreeNode* minNode, TreeNode* maxNode) {
if (!root) return true;
// 检查当前节点是否在允许范围内
if (minNode && root->val <= minNode->val) return false;
if (maxNode && root->val >= maxNode->val) return false;
// 递归检查子树:左子树的最大值不能超过当前值,右子树的最小值不能小于当前值
return isValid(root->left, minNode, root) &&
isValid(root->right, root, maxNode);
}
};96.不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
 强调一下,必须得满足二叉搜索树~ 这种一看就是dp,种类树其实和左右子树是密切相关的,对于根节点是i的情况,它左子树必然为i-1个节点,右子树为n-i个节点,而这又可以dp……
强调一下,必须得满足二叉搜索树~ 这种一看就是dp,种类树其实和左右子树是密切相关的,对于根节点是i的情况,它左子树必然为i-1个节点,右子树为n-i个节点,而这又可以dp……
其实dp的核心就是涉及到前后状态就要想,如何转化。
class Solution {
public:
int numTrees(int n) {
int dp[25];
memset(dp,sizeof dp,0);
dp[0]=1;dp[1]=1;dp[2]=2;dp[3]=5;
if(n<=3)return dp[n];
for(int i=4;i<=n;i++){
for(int j=1;j<=i;j++){
dp[i]+=dp[j-1]*dp[i-j];
}
}
return dp[n];
}
};94.二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
简单题,模板。
class Solution {
public:
vector<int>ans;
void dfs(TreeNode* root){
if(root==nullptr)return ;
dfs(root->left);
ans.push_back(root->val);
dfs(root->right);
return;
}
vector<int> inorderTraversal(TreeNode* root) {
dfs(root);
return ans;
}
};84.柱状图中的最大矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
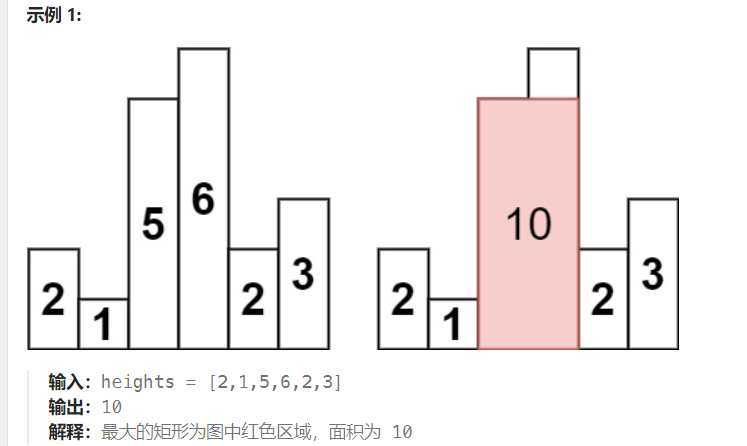
其实和前面盛水最多的容器有异曲同工之处,核心应该聚焦在高度!对于某个高度的柱子,旁边高度比他高的柱子没用(它做不了高度的贡献,只能做宽度),所以对于某个高度的柱子A,我只需要统计它左右两边比他高的柱子的数量(下标差即为宽度),对于高度比他低的柱子B,换个说法:对于某个高度的柱子B,柱子A高度比他高,这也包含在了上一个情况里。
所以对于某个柱子,我们只需要关心她左右高度比他高的,高度比他低的在后续情况被考虑了。
现在核心就在如何统计左右两边高度比他高的柱子数量——方法是维护一个单调栈

- 首先,什么是单调栈?就是栈中保存递增的元素。
- 我们遍历数组,枚举每个元素
nums[i],就称为新元素吧。若新元素大于栈顶,就加入新元素;若新元素小于栈顶元素,栈顶元素出栈,进行相关处理,然后一直出栈,直到栈中栈顶元素小于新元素,将新元素入栈。这样我们就维持了单调栈的定义,即栈中保存的是单调递增的序列。 - 那这个
相关处理是什么?就要看我们的目标。我们的目标是求最大矩形面积,其实就是对数组中的每个元素高度,找最大的长度。最大的长度是多少?举个例子,heights = [2,1,5,6,2,3]中,5高度对应的最大长度是多少?从5开始分别向左向右找,向左找到元素5第一个小于5的元素1,向右找到5第一个小于5的元素2,则元素5对应的长度是4-1-1=2,这是暴力的思路,我们用单调栈来处理这个过程。 - 于是我们得到这样的解法:首先遍历数组,对每个元素,如果大于栈顶元素,则元素入栈;如果小于等于栈顶元素,栈顶元素出栈,并计算以栈顶元素
nums[i]为高,长为i - stack.peek() - 1的矩形面积。记录最大的面积即可。遍历完整个数组后,栈中还保存着一些递增的元素,这些元素是没有遇到更小的元素,所以没有右边界,可以认为nums.length就是它对应的右边界,它左边界依旧是栈顶元素出栈后,栈的stack.peek()。
为什么想到单调栈?——这类“在一维数组中找第一个满足某种条件的数”的场景就是典型的单调栈应用场景! 非常好且非常经典的一道题!
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
stack<int> mysta;
int ans = 0;
int k = heights.size();
for (int i = 0; i < k; i++) {
while (!mysta.empty() && heights[mysta.top()] >= heights[i]) {
int idx = mysta.top();
mysta.pop();
// 计算左边界:新栈顶或-1
int left_bound = mysta.empty() ? -1 : mysta.top();
int width = i - left_bound - 1;
ans = max(ans, heights[idx] * width);
}
mysta.push(i);
}
// 处理栈中剩余元素
while (!mysta.empty()) {
int idx = mysta.top();
mysta.pop();
int left_bound = mysta.empty() ? -1 : mysta.top();
int width = k - left_bound - 1;
ans = max(ans, heights[idx] * width);
}
return ans;
}
};85.最大矩形
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
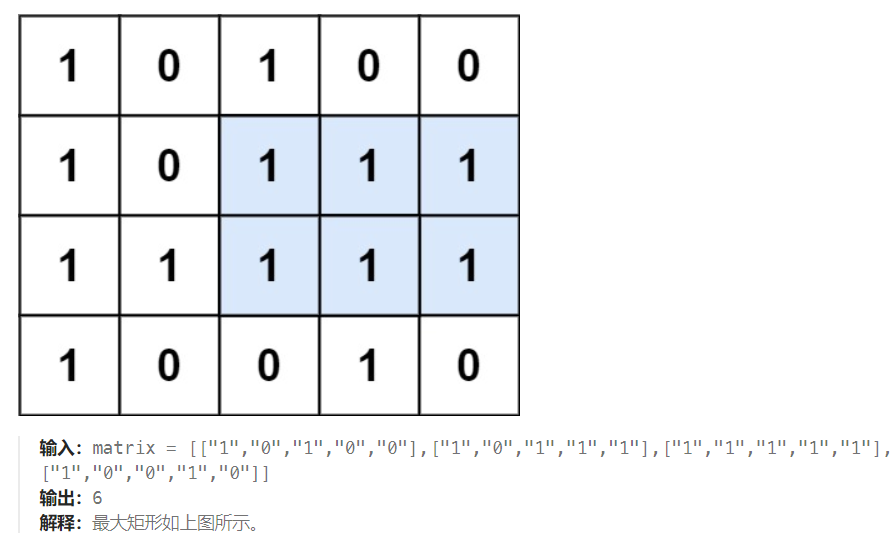
这也就是上面那道题重要的原因! 上面那道题其实可以作为很多题的模板题!对于此题:
1、对每一行,计算每个位置向上连续的1的个数,作为柱状图的高度。
2、按照lc84题思路来做,对每一行的高度数组,使用单调栈算法计算当前行的最大矩形面积。
3、比较每一行的最大面积,保留全局最大值。
class Solution {
public:
int book[210][210];int ans;int a;int b;
int findmax(int row){
stack<int>mysta;int tem=0;
for(int i=0;i<b;i++){
while(!mysta.empty()&&book[row][mysta.top()]>=book[row][i]){
int idx=mysta.top();mysta.pop();
int left_bound=mysta.empty()?-1:mysta.top();//计算时包括了idx,边界是统计不包括的
int width=i-left_bound-1;
tem=max(tem,width*book[row][idx]);
}
mysta.push(i);
}
while(!mysta.empty()){
int idx=mysta.top();mysta.pop();
int left_bound=mysta.empty()?-1:mysta.top();
int width=b-left_bound-1;
tem=max(tem,width*book[row][idx]);
}
return tem;
}
int maximalRectangle(vector<vector<char>>& matrix) {
a=matrix.size();b=matrix[0].size();
for(int i=0;i<a;i++){
for(int j=0;j<b;j++){
if(matrix[i][j]=='0')book[a][b]=0;
else if(matrix[i][j]=='1')book[i][j]=(i==0?1:book[i-1][j]+1);
}
}
for(int i=0;i<a;i++){
ans=max(ans,findmax(i));
}
return ans;
}
};1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
为了优化寻找过程,显然是需要引入哈希表的。但是,引入哈希表也是需要技巧的,比如[3,3]target是6就可以(0,1),[3]但target是6就不行
我们创建一个哈希表,对于每一个 x,我们首先查询哈希表中是否存在 target - x,然后将 x 插入到哈希表中,即可保证不会让 x 和自己匹配
——很常用的避免重复的技巧!!在哈希表的插入上面做文章
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hashtable;
for (int i = 0; i < nums.size(); ++i) {
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end()) {
return {it->second, i};
}
hashtable[nums[i]] = i;
}
return {};
}
};78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
输入:nums = [1,2,3] 输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
对递归的进一步理解和考查
注意这里是i+1而不是step+1 实际上就是只看第i个以后的
class Solution {
public:
vector<vector<int>>ans;vector<int>temp;
void trace(vector<int>&nums,int step){
ans.push_back(temp);//把当前子集加入
for(int i=step;i<nums.size();i++){
temp.push_back(nums[i]);
trace(nums,i+1);//如果选了第i个的话看下一个
temp.pop_back();
}
return;
}
vector<vector<int>> subsets(vector<int>& nums) {
sort(nums.begin(),nums.end());
trace(nums,0);
return ans;
}
};75.颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
必须在不使用库内置的 sort 函数的情况下解决这个问题。
输入:nums = [2,0,2,1,1,0] 输出:[0,0,1,1,2,2]
确实是非常巧妙的做法:
三个指针num1、num2、num3将数组nums分成了3个分区,从左往右依次存储0、1、2
三个指针分别指向各自分区的尾部。
从左到右遍历数组nums,(1)如果nums[i]=0,则1、2区都后移一个位置,给新来的0腾地方。
(2)如果是nums[i]=1,同样,2区后移一个位置,给新来的1腾地方。前面的0区无影响。
赋值不改变顺序,由2 1 0的赋值顺序决定。
class Solution {
public void sortColors(int[] nums) {
int num0 = 0, num1 = 0, num2 = 0;
for(int i = 0; i < nums.length; i++) {
if(nums[i] == 0) {
nums[num2++] = 2;
nums[num1++] = 1;
nums[num0++] = 0;
}else if(nums[i] == 1) {
nums[num2++] = 2;
nums[num1++] = 1;
}else {
nums[num2++] = 2;
}
}
}
}72.编辑距离
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
一眼dp,和最长公共子序列其实是有异曲同工之处的
“编辑距离算法被数据科学家广泛应用,是用作机器翻译和语音识别评价标准的基本算法”
情况1: 字符相等
如果 word1 的第 i 个字符(即 word1[i-1])等于 word2 的第 j 个字符(即 word2[j-1]),那么这两个字符之间不需要任何编辑操作,因此 dp[i][j] = dp[i-1][j-1]。
情况2: 字符不等
如果 word1[i-1] != word2[j-1],那么我们需要考虑三种编辑操作:
替换:我们可以将 word1[i-1] 替换为 word2[j-1],这样两个字符串的最后一个字符就相同了,然后问题就转化为了将 word1 的前 i-1 个字符转换成 word2 的前 j-1 个字符,所以需要的操作数是 dp[i-1][j-1] + 1。
插入:在 word1 中插入 word2[j-1],这相当于将 word1 的前 i 个字符转换成 word2 的前 j-1 个字符后,再插入一个字符,因此需要的操作数是 dp[i][j-1] + 1。(第i个字符与第j个字符不匹配,考虑在i后面填一个第j字符,然后同时把这个去掉)
删除:从 word1 中删除 word1[i-1],这就把问题转化为将 word1 的前 i-1 个字符转换成 word2 的前 j 个字符,所需的操作数是 dp[i-1][j] + 1。(不用考虑删除的第i个字符,即前i-1个字符转换为前j个字符)
最终,dp[i][j] 应该取这三种情况中的最小值,因为我们要找的是最少编辑操作次数。
贴个官解:
class Solution {
public:
int minDistance(string word1, string word2) {
int n = word1.length();
int m = word2.length();
// 有一个字符串为空串
if (n * m == 0) return n + m;
// DP 数组
vector<vector<int>> D(n + 1, vector<int>(m + 1));
// 边界状态初始化
for (int i = 0; i < n + 1; i++) {
D[i][0] = i;
}
for (int j = 0; j < m + 1; j++) {
D[0][j] = j;
}
// 计算所有 DP 值
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < m + 1; j++) {
int left = D[i - 1][j] + 1;
int down = D[i][j - 1] + 1;
int left_down = D[i - 1][j - 1];
if (word1[i - 1] != word2[j - 1]) left_down += 1;
D[i][j] = min(left, min(down, left_down));
}
}
return D[n][m];
}
};70.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
简单题。动态规划。
class Solution {
public:
int dp[50];
int climbStairs(int n) {
dp[1]=1;dp[2]=2;
for(int i=3;i<=n;i++)
dp[i]=dp[i-1]+dp[i-2];
return dp[n];
}
};581.最短无序连续子数组
给你一个整数数组 nums ,你需要找出一个 连续子数组 ,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
请你找出符合题意的 最短 子数组,并输出它的长度。
输入:nums = [2,6,4,8,10,9,15] 输出:5 解释:你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。
神秘的一题,也没有要求复杂度,可以sort一下,从头遍历和从尾遍历,找第一个不相等的地方
感觉不应该是中等难度。
注意一下数组的拷贝!
直接用等号就行了。 也可用迭代器,优点是还能拷贝区间。
| 赋值 | newnums = nums; | |
| 迭代器范围 | vector<int> newnums(nums.begin(), nums.end()); | 复制子区间 |
class Solution {
public:
int findUnsortedSubarray(vector<int>& nums) {
int ans=0;int k=nums.size();
vector<int>newnums=nums;int le=-1;int ri=-1;
sort(newnums.begin(),newnums.end());
for(int i=0;i<k;i++){
if(nums[i]==newnums[i])continue;
else{
le=i;break;
}
}
if(le==-1)return 0;
for(int i=k-1;i>=le;i--){
if(nums[i]==newnums[i])continue;
else{
ri=i;break;
}
}
if(ri==-1)return 0;
ans=ri-le+1;
return ans;
}
};至于O(n)的算法,两次遍历,第一次确定右边界:从左往右,比max小的,属于乱序区间,都要重排;第二次确定左边界:从右往左,比min大的,属于乱序区间,都要重排。
这个算法画个例子一看就明白了,很清晰。
64.最小路径和
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
老规矩,看到这种首先应该想到dp而不是dfs。
class Solution {
public:
int dp[210][210];
int minPathSum(vector<vector<int>>& grid) {
int m=grid.size();int n=grid[0].size();
dp[0][0]=grid[0][0];
for(int i=1;i<m;i++)dp[i][0]=dp[i-1][0]+grid[i][0];
for(int j=1;j<n;j++)dp[0][j]+=dp[0][j-1]+grid[0][j];
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
dp[i][j]=min(dp[i-1][j],dp[i][j-1])+grid[i][j];
}
}
return dp[m-1][n-1];
}
};62.不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。问总共有多少条不同的路径?
可以标准深搜——得到标准超时。DFS的时间复杂度为O(2^(min(m, n)))
class Solution {
public:
int ans;
int book[110][110];
void dfs(int& m,int& n,int x,int y){
if(x==m&&y==n){
ans++;return;
}
book[x][y]=1;
int dire[2][2]={{0,1},{1,0}};
int tx,ty;
for(int i=0;i<2;i++){
tx=x+dire[i][0];ty=y+dire[i][1];
if(tx<=0||tx>m||ty<=0||ty>n)continue;
if(book[tx][ty])continue;
dfs(m,n,tx,ty);
}
book[x][y]=0;
return;
}
int uniquePaths(int m, int n) {
ans=0;
dfs(m,n,1,1);
return ans;
}
};显然这种题都是用dp来做。
class Solution {
public:
int dp[110][110];
int uniquePaths(int m, int n) {
dp[1][1]=1;
for(int i=2;i<=m;i++)dp[i][1]=dp[i-1][1];
for(int i=2;i<=n;i++)dp[1][i]=dp[1][i-1];
for(int i=2;i<=m;i++){
for(int j=2;j<=n;j++)dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
return dp[m][n];
}
};56.合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
比较基础的题,这种首先要想到排序!
此外,注意会有[[1,4],[2,3]]样例,所以end部分需要调整:end=max(intervals[i+1][1],end);
取得是最大值
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),[](const vector<int>&a,const vector<int>&b){
if(a[0]<b[0])return true;
else if(a[0]==b[0]&&a[1]<b[1])return true;
return false;
});
vector<vector<int>>ans;int sta=intervals[0][0];int end=intervals[0][1];int k=intervals.size();
for(int i=0;i<k-1;i++){
if(intervals[i+1][0]<=end){
end=max(intervals[i+1][1],end);
continue;
}
else if(intervals[i+1][0]>end){
ans.push_back({sta,end});
sta=intervals[i+1][0];end=intervals[i+1][1];
}
}
ans.push_back({sta,end});
return ans;
}
};55.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
理清楚思路就行,用一个变量记录当前能到的最远距离。
输入:nums = [3,2,1,0,4] 输出:false 解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
class Solution {
public:
bool canJump(vector<int>& nums) {
int k=nums.size();int temp=nums[0];int i=0;
if(k==1)return true;
while(i<=temp&&i<k){
temp=max(temp,nums[i]+i);
if(temp>=k-1)return true;
i++;
}
return false;
}
};53.最大子数组
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组是数组中的一个连续部分。
经典错误代码:
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int k=nums.size();int a=INT_MIN;int b=0;
for(int i=0;i<k;i++){
if(b>=0){
b+=nums[i];a=max(a,b);
cout<<b<<" ";
}
else if(b<0)b=0;
}
return a;
}
};在b<0时将b置为0就结束了,压根就没处理当前元素。
正确的实现——经典的Kadane算法!
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int k = nums.size();
int a = nums[0]; // 初始化为第一个元素(确保至少包含一个元素)
int b = nums[0]; // 当前子数组和从第一个元素开始
for (int i = 1; i < k; i++) {
if (b > 0) { // 相当于 b + nums[i] > nums[i]
b += nums[i];
} else {
b = nums[i]; // 当前和小于等于0,重新开始
}
a = max(a, b); // 更新全局最大和
}
return a;
}
};将更新放在最后统一更新,b小于0直接从当前开始。
完结撒花~ ✿✿ヽ(°▽°)ノ✿

















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









