




XML简单介绍及运行原理
XML简介
1.概念:可扩展标记语言
2.与HTML的区别:
最大的区别就是HTML元素固定,而XML的标签可以由用户自定义。
3.常见应用:
- 配置文件
- 存放数据
4.语法:
注意:
- 对大小写敏感
- 必须正确嵌套
- 必须有根元素
- 须有关闭标签
文档声明
<? version="1.0 encoding="UTF-8" standalone="yes">
- version:指定xml文档版本,必写属性
- encoding:指定当前文本的编码,可选属性,默认值为:utf-8
- standalone:定义外部定义的DTD文件的存在性,表示该文件是否呼叫其他外部文件,
- yes=没有呼叫(默认);no=有呼叫
注意:文档声明必须从0行0列开始元素:element–由开始标签,元素体,结束标签组成
<hello>你好</hello>属性:是元素的一部分,属性必须出现在元素的开始标签中
<web-app version="2.5">元素体内容</web-app>注释:
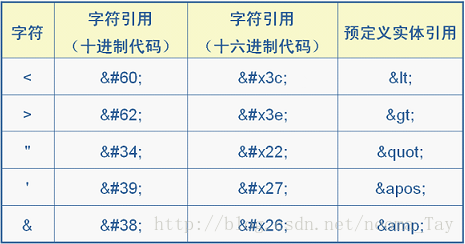
转义字符:
任意区域:
不需要使用转义字符的区域:<!CDATA[[任意内容]]>
5.常见约束(了解)
- DTD约束
- Schema约束
6.命名空间(了解)
类似java文件中的包
用来区别同名文件,处理元素和属性的名称冲突问题
例如:
<web-app xmlns="http://www.example.org/web-app_2_5"
:默认名称空间
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
:预定义名称空间
xsi:schemaLocation="http://www.example.org/web-app_2_5 web-app_2_5.xsd"
:名称空间 文件名
version="2.5">
:版本号
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
7.XML解析
常见解析方式:
I>domj4 :要求解析器把整个XML文档装载到内存,并解析成一个Document对象
- 优点:元素与元素之间保留结构关系,可以进行增删改查操作
- 缺点:XML文档过大可能会出现内存溢出显现
II>sax:逐行扫描文档,一边扫描一边解析。以事件驱动的方式进行具体解析。
- 优点:处理速度快
- 缺点:只能读
III>pull:Android内置的XML解析方式
XML解析原理
通过某种解析方式创建解析器对象获取XML文档的Document对象, 从该对象中获取根元素节点 再顺着根元素节点得到相应元素节点。
从而得到元素节点的文本内容 最终利用反射通过节点的文本内容得到类的字节码文件内容获取该类的属性方法进行响应操作。
//web.xml配置文件的内容
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://www.example.org/web-app_2_5"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/web-app_2_5 web-app_2_5.xsd"
version="2.5">
<servlet>
<servlet-name>myServlet</servlet-name>
<servlet-class>com.part03.webServlet.MyServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>myServlet</servlet-name>
<url-pattern>/myServlet</url-pattern>
</servlet-mapping>
</web-app>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
//xml解析过程
public class TestMyServlet {
@Test
public void testMyServlet1() throws Exception {
//1.创建解析器对象
SAXReader saxReader=new SAXReader();
//2.使用解析器加载web.xml文件得到document对象
Document doc=saxReader.read("src/com/webServletTest/web.xml");
//3.获取根节点元素
Element root=doc.getRootElement();
//4.根据元素名称获取子元素
Element servletElement=root.element("servlet");
//5.获取servlet子元素其中的子元素servlet-class节点
Element servletClassElement=servletElement.element("servlet-class");
//6.获取servlet-class元素的文本
String servletClass=servletClassElement.getText();
//7.通过类全名获取字节码文件
Class clazz=Class.forName(servletClass);
//8.创建一个实例对象
MyServlet myServlet=(MyServlet)clazz.newInstance();
//9.调用该实例方法
myServlet.init();
myServlet.service();
myServlet.destroy();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
以上是对xml文档的初步认识。

















 1511
1511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









