







1、估算一个大模型需要的显卡

以目前最流行的开源模型 QWQ-32B 满血版 大模型为例,你算算需要多少显卡?
查看hf主页: https://huggingface.co/Qwen/QwQ-32B

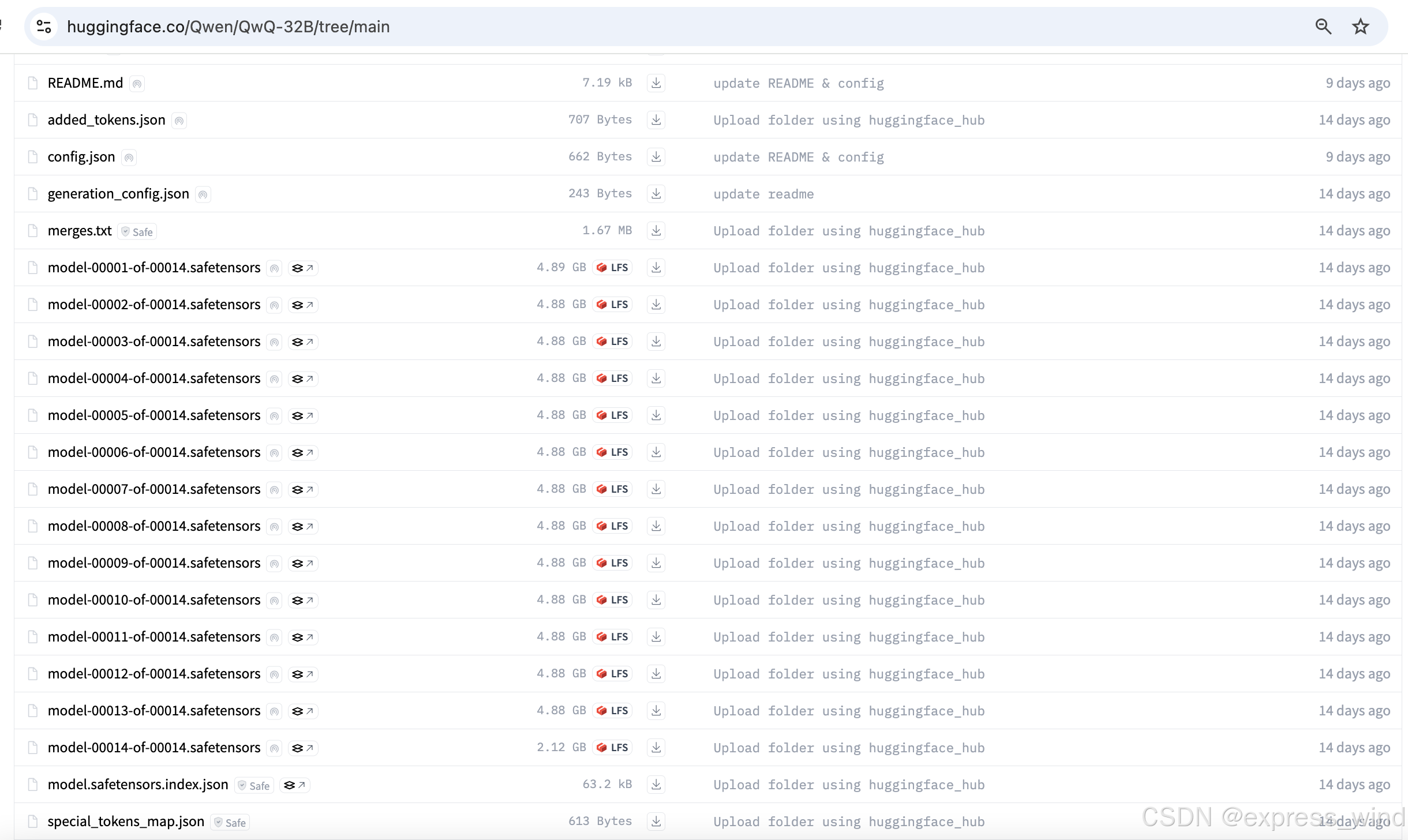
简单来说:32B代表需要32 billion的参数:
模型权重文件:就需要32 billion * 2字节 = 64G
装入显卡也就需要64G的显卡,另外还需要KV缓存,工作缓存等等
推论:如果你有A10【24GB的显卡规格】,那最少需要4张才能运行。
2、机器资源不够看看有没有量化版
hf找到GGUF文件 :https://huggingface.co/Qwen/QwQ-32B-GGUF

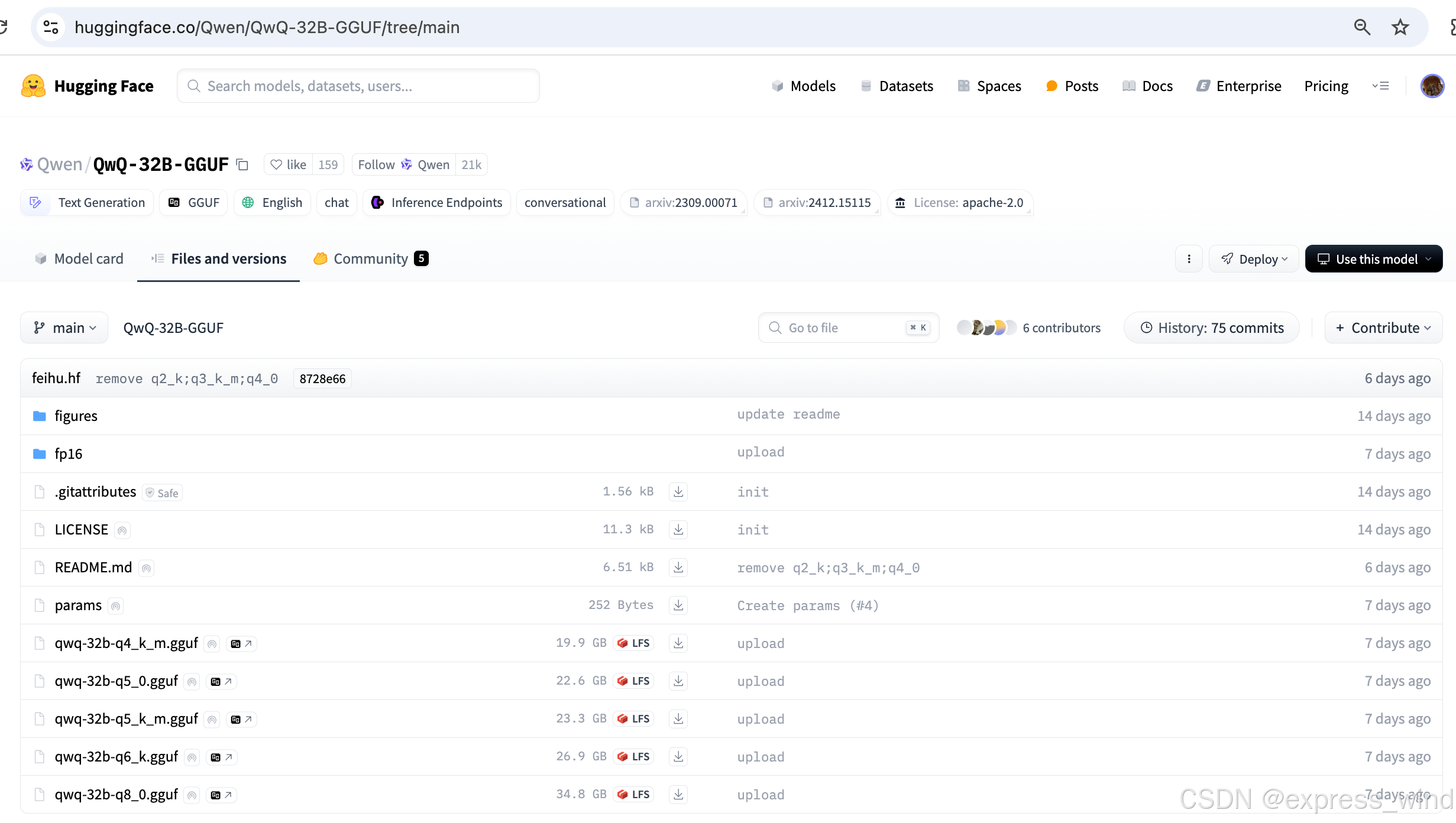
提供q4_K_M 量化版本,那就没啥问题了,19.9的文件大小,24G的显卡确实可以跑起来!
通过ollama本地运行
https://ollama.com/library/qwq
查看提供的版本:
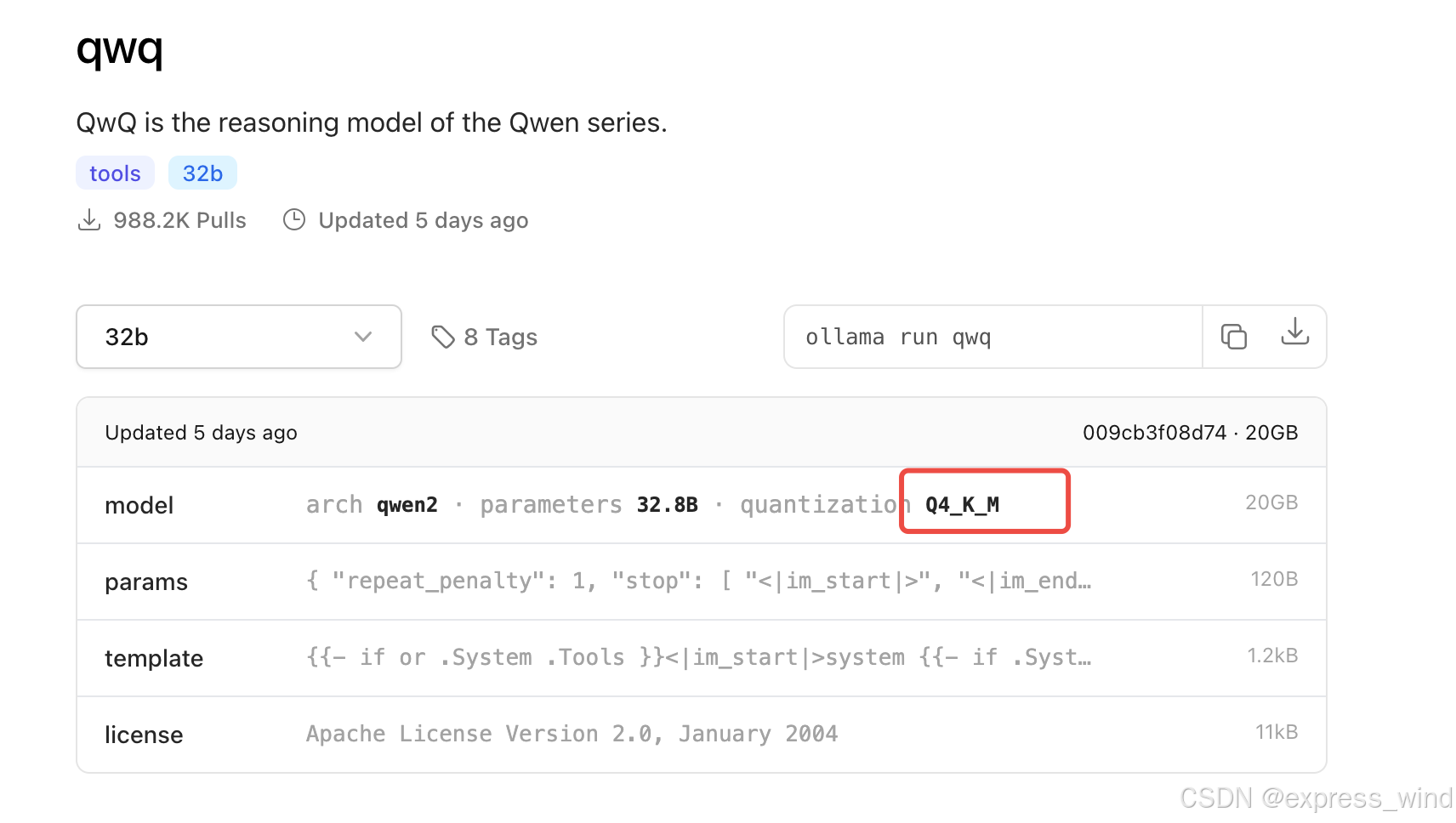
> ollama run qwq

默认运行的就是q4_K_M版本

















 7762
7762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









