




 本文是关于零基础数据挖掘在金融风控领域的实践,主要介绍如何进行探索性数据分析(EDA),包括数据总览、数据分布分析,特别是对缺失值、数值型变量的处理和分布特征的探讨。
本文是关于零基础数据挖掘在金融风控领域的实践,主要介绍如何进行探索性数据分析(EDA),包括数据总览、数据分布分析,特别是对缺失值、数值型变量的处理和分布特征的探讨。
1、前言
在重看我的项目的过程中发现自己对于相关知识点理解并不透彻,希望能理论联系实际,加深自己对基础知识的理解。项目来源于阿里天池学习赛——零基础入门金融风控-贷款违约预测,感兴趣的小伙伴可以自己去原文了解。探索性数据分析(Exploratory Data Analysis, EDA)是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,从而帮助我们后期更好地进行特征工程和建立模型,是数据挖掘中十分重要的一步。
2、数据总览
2.1 导入数据和需要的packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno # 缺失值的可视化处理
data_train = pd.read_csv('D:/myP/financial_risk/train.csv')
data_testA = pd.read_csv('D:/myP/financial_risk/testA.csv')2.2 查看数据的样品数与特征值数
print('train_data_shape:', data_train.shape)
print('test_data_shape:', data_testA.shape)![]()
数据的维度很重要, 太多的行会导致花费大量时间来训练算法得到模型, 太少的数据会导致对算法训练不充分,得不到合适的模型 如果数据有太多的特征,会引起某些算法性能低下的问题。所以一定要先熟悉于心。
2.3 基本数据信息
查看数据集的样品数和特征值数,各特征值的非零值,数据类型,以及数据类型的分类统计(5个object,9个int64,33个float64,共47个,但是id不能算是特征值),内存占用286.9MB。
data_train.info()
2.4 连续型数据的统计信息概览
describe中有每列(数值列)的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以 及最大值 看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现 999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意下。
data_train.describe()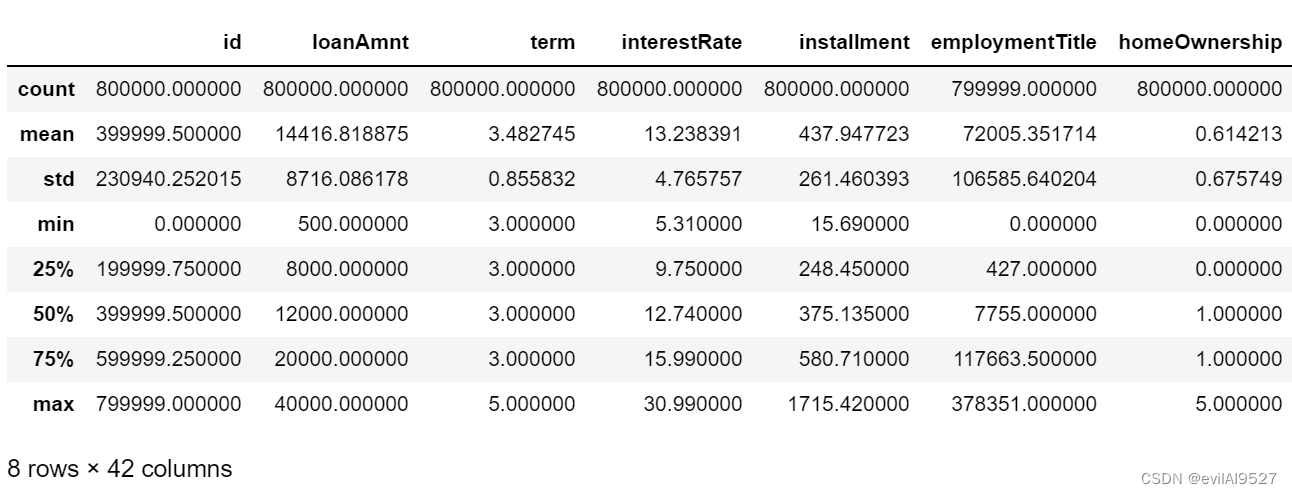
42列是因为47个特征值中有5个object变量
3、数据分布
3.1 缺失值的分布(缺失特征及缺失率)
missing = train.isnull().sum()/len(train)
missing = missing[missing > 0]
missing.sort_values(inplace=True) #排个序
missing.plot.bar() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









