




偏标记学习是一种新的弱监督机器学习框架
解决的问题:解决每个训练样本与其实际标签的候选集相关联的问题。
现存问题:训练数据的模糊性
解决办法:利用高斯过程模型,提出了一种新的概率核算法。
主要思想:假设一个不可观测的潜在函数,在每个类别标签的特征空间上具有高斯过程。然后定义一个新的似然函数,对训练数据传递的模糊标记信息进行消歧。通过引入聚合函数来逼近似然函数中的max函数,不仅定义了一个与maxloss函数等价的似然函数,并且证明了他比其他损失函数更紧,而且给出了一个可微凸目标函数。
困难:在PL框架中,无法直接观察每个训练样本的实际标签。可以获得的唯一信息是,实际标签位于候选集Yi中。
所谓以高斯过程作为先验,意思是在没有观察到任何数据的情况下,我们认定给定x,y服从分布
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/6768894d98ac8ee002657ddb7e7c2d73.png) 。其中
。其中![]()
接下来我们有训练数据x,y。回归问题就是希望我们通过x,y学习一个由x到y的映射函数f。然后给定一个x*,预测 ![]()
根据我们的高斯过程先验。训练数据y和y*联合条件分布p(Y,y*|x,x*)服从如下
根据以上y和y*的联合分布,可以得到条件分布
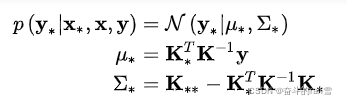
上述就是把高斯过程作为先验的一种非参数方法。可以看到,除了kernel里面的超参数,最后对 ![]() 的预测里面没有涉及到任何参数的估计。
的预测里面没有涉及到任何参数的估计。

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









