




 本文全面介绍了HTTP协议,包括其全称、用途、特点。阐述了URI、URL和URN的概念及区别,详细讲解了HTTP请求方法(如GET、POST等)和常用状态码。还介绍了HTTP报文格式,以及浏览器使用HTTP请求数据的流程,对请求和响应报文进行了解析。
本文全面介绍了HTTP协议,包括其全称、用途、特点。阐述了URI、URL和URN的概念及区别,详细讲解了HTTP请求方法(如GET、POST等)和常用状态码。还介绍了HTTP报文格式,以及浏览器使用HTTP请求数据的流程,对请求和响应报文进行了解析。
1、简介
http全称:超文本传输协议(Hyper Text Transfer Protocol)
用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。HTTP是一个基于TCP/IP通信协议来传递数据。能够传输HTML格式文本文档、ASCII文本文档、JPEG图片、GIF图片等类型的文件。
2、特点
- 简单快速:浏览器向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST、PUT、DELETE等。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完浏览器的请求,并收到浏览器的应答后,便断开连接。
- 无状态:无状态是指协议对于事务处理没有记忆能力。如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大,但服务器不需要先前信息时它的应答就较快。
- 支持C/S模式:有浏览器发起请求,服务端响应数据组成。
3、URI
每个web服务器资源都有一个名字,用于浏览器说明需要的web服务器资源是什么。服务器资源名称被称为统一资源标识符(Uniform Resource Identifiers, URI)URI在因特网上就像邮政地址一样,在世界范围内唯一标识并定位信息资源。
URI有个两种形式,分别是URL和URN。URL是通过描述资源的位置来标识资源的;而URN则是通过名字来标识资源的,与资源当前所处的位置无关。
4、URL
URL是统一资源定位符,是资源标识符中最常见的形式。URL描述了一台特定服务器上某个资源的位置。他们可以明确说明如何从一个精确、固定的位置获取资源。
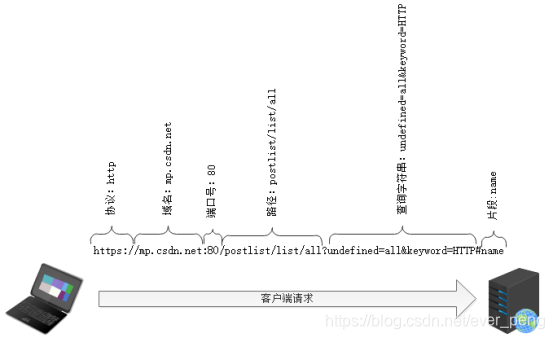
以下URL为例介绍各组成部分。
https://mp.youkuaiyun.com:80/postlist/list/all?undefined=all&keyword=HTTP#name
1、协议:指出使用什么协议解析URL。协议以一个字母开始,由第一个“:”将其与URL的其余部分分隔开。该URL的协议部分为“http”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等。
2、域名:该URL的域名部分为“mp.youkuaiyun.com”。一个URL中,也可以使用IP地址作为域名使用
3、端口号:域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口号,HTTP默认端口号是80。
4、路径:指明资源位于服务器的什么地方。本例中的路径是“postlist/list/all”。
5、查询字符串:从“?”开始到“#”为止的部分。本例中的查询字符串为“undefined=all&keyword=HTTP”。查询字符串中允许有多个参数,参数与参数之间用“&”作为分隔符。
6、片段:用来表示一个资源内部的片段。从“#”开始到最后,都是片段部分。本例中的片段部分是“name”。
5、URN
URI的第二种形式就是统一资源名URN,URN是作为特定内容的唯一名称使用的,与目前资源所在位置无关。使用URN就可以将资源随意移动。
例如无论因特网标准文档RFC2141位于何处都可以用以下URN命名:
Urn:ietf:rfc:2141
URN尚未被大范围使用。为了更有效的工作,URN需要一个支撑架构来解析资源位置,而此架构缺乏也延缓了其被采用的进度。
6、HTTP请求方法及常用状态码
6.1、HTTP请求方法
HTTP请求方法有7种,具体请求方法如下:
GET:从服务器获取一份文本文档;
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
POST:向服务器发送需要处理的数据,常用于表单提交。
- POST 请求不会被缓存
- POST 请求不会保留在浏览器历史记录中
- POST 不能被收藏为书签
- POST 请求对数据长度没有要求
- POST 反复上传相同文本文档会创建多个文本文档
PUT:将请求的主体部分上传存储在服务器指定URI上。
- PUT 请求不会被缓存
- PUT 请求不会保留在浏览器历史记录中
- PUT 不能被收藏为书签
- PUT 请求对数据长度没有要求
- PUT 反复上传相同文本文档会覆盖上一个文本文档
DELETE:要求服务器执行删除指定的资源
HEAD:只从服务器获取文本文档的首部。
- HEAD 用于检查资源的有效性。
- HEAD 用于检查超链接的有效性。
- HEAD 用于检查网页是否被串改。
- HEAD 用于自动搜索机器人获取网页的标志信息,获取rss种子信息,或者传递安全认证信息等。
TRACE:对可能经过代理服务器传送到服务器上去的报文进行追踪。
- 实现沿通向目标资源的路径的消息环回(loop-back)测试 ,提供了一种实用的 debug 机制。
- 请求的最终接收者应当原样反射(reflect)它接收到的消息。
OPTIONS:获取服务器支持的HTTP请求方法
6.2、HTTP常用状态码
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
1**:指示信息,表示服务器收到请求,需要客户端继续执行操作
2**:成功。请求被成功接收并处理
3**:重定向。需要客户端进一步操作
4**:客户端错误,请求包含语法错误或无法完成请求
5**:服务器错误,服务器在处理请求的过程中发生了错误
常见的状态码有:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
7、HTTP报文
7.1、HTTP报文格式
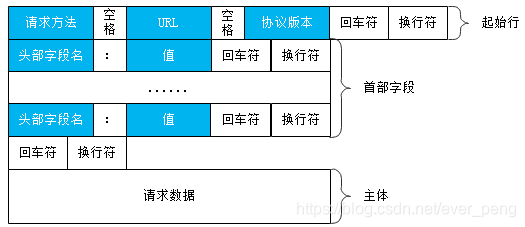
起始行:
报文第一行就是起始行,请求报文中用来说明要做什么,在响应报文中说明出现了什么情况。
首部字段:
起始行后面后零个或多个首部字段。每个首部字段包含一个名字和一个值,为便于解析两者之间用冒号分割。首部以空行为结束。
主体:
空行后是可选的报文主体,其包含了所有类型数据。请求主体中包含要发送给服务器的数据;响应主体中包含了返回给浏览器的数据。
起始行和首部字段都是文本形式,且结构化。主体可以包含任意二进制的数据(比如文本、视频、音频、软件程序)。
7.2、浏览器使用HTTP请求数据流程
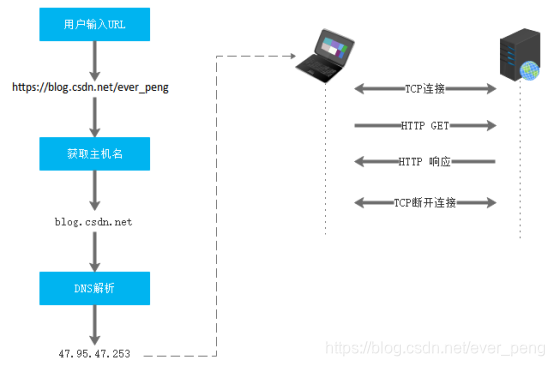
具体步骤如下:
- 从URL中解析服务器主机名
- 将主机名转换为IP地址
- 从URL中解析服务器端口号,如果没有则按照默认端口连接。
- 建立TCP连接
- 浏览器发送HTTP请求报文
- 服务端响应HTTP响应报文
- 关闭TCP连接
7.3、HTTP请求报文解析
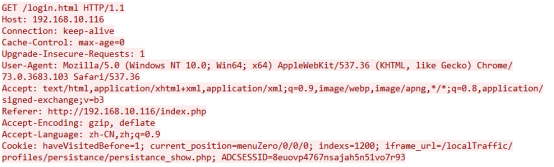
起始行:
GET
浏览器使用GET方法请求服务端资源
/login.html
请求服务端资源的URL路径
HTTP/1.1
浏览器使用HTTP1.1版本请求
首部字段:
Host: 192.168.10.116
请求的服务器IP地址
Connection: keep-alive
Connection表示的就是TCP建立连接的形式 ,keep-alive表示建立长连接,close表示关闭连接
Cache-Control: max-age=0
要求使用缓存前验证资源是否存在。
Upgrade-Insecure-Requests: 1
https的页面需要加载http的资源,那么浏览器就会报错或者提示。浏览器增加Upgrade-Insecure-Requests: 1用来告诉服务器浏览器可以处理https协议
User-Agent:
包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号。
Mozilla/5.0
以前想获得图文并茂的网页,就必须宣称自己是 Mozilla 浏览器。导致如今User-Agent里通常都带有Mozilla字样,出于对历史的尊重,大家都会默认填写该部分。
(Windows NT 10.0; Win64; x64)
由多个字符串组成,用英文半角分号分开。指使用的操作系统的版本。
AppleWebKit/537.36
引擎版本,谷歌浏览器表明自己使用的内核为blink内核。
Chrome/73.0.3683.103
谷歌浏览器版本
Accept: text/html
表示发送端(浏览器)希望接受的数据类型。Accept:text/html表示浏览器希望接受的数据类型是html类型。
Referer: http://192.168.10.116/index.php
告诉服务器我是从http://192.168.10.116/index.php这个页面链接过来的。服务器基此可以获得一些信息用于处理,比如防盗链、防止恶意请求。
Accept-Encoding: gzip, deflate
表示支持gzip,deflate压缩,Web服务器和浏览器之间压缩传输的”文本内容“的方法。 HTTP采用通用的压缩算法,比如gzip来压缩HTML,Javascript, CSS文件。 能大大减少网络传输的数据量,提高了用户显示网页的速度。
Accept-Language: zh-CN,zh;q=0.9
浏览器使用的语言是中文
Cookie:
储存再浏览器中,分为非持久Cookie和持久Cookie。用于二次请求时的HTTP认证。
主体:
由于使用的是GET方法的请求内容放在URL后,所以没有主体字段
7.4、HTTP响应报文解析
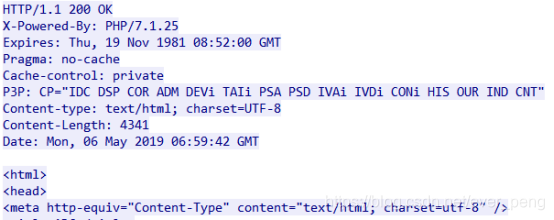
起始行:
HTTP/1.1
服务端使用HTTP1.1版本响应
200 OK
HTTP响应状态码,200表示请求成功
首部字段:
X-Powered-By: PHP/7.1.25
用于告知网站是用PHP语言或框架编写的。
Expires: Thu, 19 Nov 1981 08:52:00 GMT
网页或URL地址不再被浏览器缓存的时间,一旦超过了这个时间,浏览器都应该联系原始服务器。
Pragma: no-cache
用于客户端发送的请求中。客户端会要求所有的中间服务器不返回缓存的资源
Cache-control: private
内容只缓存到私有缓存中(仅客户端可以缓存,代理服务器不可缓存)
P3P: CP="IDC DSP COR ADM DEVi TAIi PSA PSD IVAi IVDi CONi HIS OUR IND CNT"
使用隐私参数优选策略
Content-type: text/html; charset=UTF-8
互联网媒体类型;也叫做MIME类型,Content-Type:text/html表示具体的类型信息为html。 charset=UTF-8表示编码格式是UTF-8
Content-Length: 4341
HTTP消息实体的传输长度。Content-Length必须和消息内容的传输长度完全一致。如果过短则会截断,过长则会导致超时。
Date: Mon, 06 May 2019 06:59:42 GMT
表示消息发送的时间为2019年5月6日。
主体:
HTTP服务器响应的数据内容。
如下:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />

















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









