




文章目录
Arbiter: Bridging the Static and Dynamic Divide in Vulnerability Discovery on Binary Programs
- 《Arbiter:弥合二进制程序漏洞发现中静态分析与动态分析的鸿沟》
- Jayakrishna Vadayath∗, Moritz Eckert†, Kyle Zeng∗, Nicolaas Weideman‡, Gokulkrishna Praveen Menon∗, Yanick Fratantonio+, Davide Balzarotti†, Adam Doupé∗, Tiffany Bao∗, Ruoyu Wang∗, Christophe Hauser‡, Yan Shoshitaishvili∗
- ∗Arizona State University, †EURECOM, ‡University of Southern California, +Cisco Systems Inc.
摘要
尽管当前最先进的二进制程序分析方法在漏洞发现方面表现出有效性,但其受到准确性和可扩展性之间固有权衡的限制。在本文中,我们识别出一组可辅助静态和动态漏洞检测技术的漏洞属性,从而提高前者的精度和后者的可扩展性。通过精心集成静态和动态技术,我们能够大规模检测现实程序中具有这些属性的漏洞。
我们实现了该技术,在二进制代码分析方面进行了多项改进,并创建了一个名为ARBITER的原型。我们通过对四种常见漏洞类型的大规模评估证明了该方法的有效性:CWE-131(缓冲区大小计算错误)、CWE-252(未检查返回值)、CWE-134(未控制的格式字符串)和CWE-337(伪随机数生成器中可预测的种子)。我们在Ubuntu存储库中的76,516个x86-64二进制文件上评估了我们的方法,并发现了新的漏洞,包括编译期间插入到程序中的缺陷。
1 引言
尽管编译器、操作系统和开发环境中引入的安全机制和防护措施在不断演进,但软件漏洞仍不断被发现。作为对此的部分缓解措施,开发后分析和测试过程已成为评估标准库、操作系统组件和嵌入式固件安全性的常规实践。
近年来,二进制漏洞发现的最新技术随着一系列新的动态方法(尤其是模糊测试技术)的出现而取得进展。尽管对模糊测试的重视已显著提升了现有技术的效果,并代表了一条有价值的前进路径,但这是以牺牲静态分析的投入为代价的。这种权衡存在缺点:“深层漏洞”(即“隐藏”在程序可能的执行路径深处或需要复杂约束的漏洞)由于动态覆盖问题,往往使动态技术面临挑战。另一种动态方法——动态符号执行(DSE)——通常用于穷举二进制代码小区域内的执行路径并寻找属性违反。DSE的高保真执行既是优点也是缺点:由于在现实二进制文件上的可扩展性较差,它也受到动态覆盖问题的影响。
尽管重新审视静态分析可以让研究人员避开动态覆盖问题,但当前针对二进制代码的静态分析技术缺乏有效识别漏洞所需的精度,且会产生大量误报,给人类分析师带来沉重负担。
如果漏洞发现技术能够以完全自动化的方式应用于广泛的程序,同时不引入大量误报,则其作用最为显著。结合静态和动态分析优势的混合方法——兼具高精度和高可扩展性——将成为强大的工具。
在本文中,我们描述了受模糊测试研究启发构建此类工具的努力。由于模糊测试器必须执行目标程序,因此单个技术需针对特定程序类的分析进行定制。我们意识到,静态分析中与此概念类似的是针对特定漏洞类型定制静态分析。通过利用这一见解,我们识别出一组漏洞属性,使我们能够同时保持可扩展(尽管不精确)的静态检测和精确(尽管可扩展性较低)的动态误报过滤。ARBITER是我们的混合分析技术,能够大规模分析大量二进制代码,同时即使在复杂漏洞(如复杂的整数溢出或权限提升漏洞)的情况下也能保持高精度。ARBITER具有可扩展性,支持对具有我们所识别属性的不同漏洞类型进行规范,新漏洞类型的规范仅需约75行代码。我们针对四种情况进行了示例分析:CWE-131(缓冲区大小计算错误)、CWE-252(未检查返回值)、CWE-337(伪随机数生成器中可预测的种子)和CWE-134(未控制的格式字符串)。
为实现ARBITER的混合分析,我们对多种二进制级分析技术进行了新颖的改进和组合,最终形成了自适应误报过滤步骤,该步骤使用静态和动态技术在精度和性能之间进行可配置的权衡。我们还展示了先前的方法(包括针对特定漏洞类别的方法)如何受到限制,这些限制阻碍了它们的精度和可扩展性。事实上,尽管人们可能认为检测这些漏洞是微不足道的,但我们表明,在复杂的现实场景中识别这些漏洞极具挑战性,即使在“玩具”代码中也并非易事。例如,在对合成的Juliet数据集进行的实验中,ARBITER识别出190个测试用例中的漏洞,经我们手动确认,这些漏洞被基准事实和先前分析错误地认为是安全的。
我们在从x86-64 Ubuntu 18.04软件存储库收集的76,516个二进制程序上对ARBITER进行了评估。我们还通过分析ARBITER在366个程序中引发的436个CWE131警报、126个程序中的159个CWE252警报、119个程序中的158个CWE-134警报以及370个程序中的377个CWE-337警报,证明了其精度。这些结果表明,ARBITER能够扩展到现实场景,并能在现实软件中检测漏洞,包括零日漏洞。例如,我们在Perl运行时中发现并报告了一个可利用的漏洞(CVE-2018-18311),以及一个影响所有由OCaml编译器编译的32位程序的堆错误。
贡献。我们的论文做出了以下贡献:
- 我们识别出一组特定的漏洞属性,这些属性允许静态分析和动态分析(尤其是DSE)的有效结合,从而在保持可扩展性的同时实现高精度。
- 我们开发了ARBITER框架,该框架结合静态分析和DSE来识别漏洞。ARBITER无需源代码或构建系统即可运行,并对静态和动态技术进行了新颖的改进。在ARBITER中创建新漏洞类型的规范成本低廉。
- 我们对ARBITER进行了大规模评估,分析了76,516个二进制文件中的四种漏洞类型。
为支持开放研究,ARBITER和相关数据已开源1。
2 相关工作与动机
表1列出了我们认为对于漏洞发现技术的实际应用至关重要的六个特性。尽管许多研究聚焦于漏洞发现,但尚未有研究提供自动化、可扩展且通用的解决方案,而这正是本研究的目标。我们首先讨论尝试(但未能)实现我们研究目标的相关工作,然后阐述促成ARBITER诞生的观察和见解。
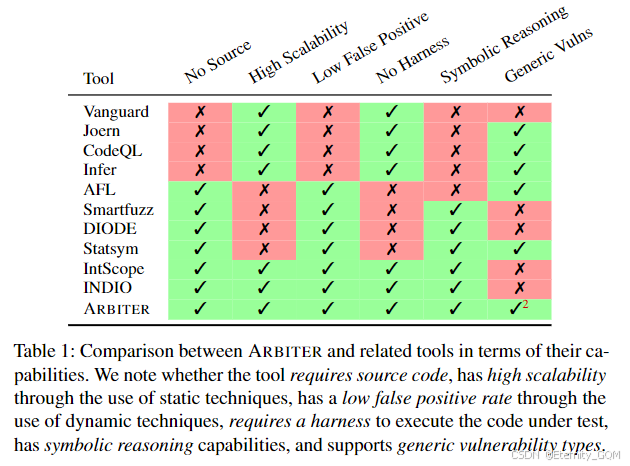
2.1 漏洞发现技术
我们将与ARBITER密切相关的现有漏洞发现技术(总结于表1)分为三个主要领域进行讨论,分析它们的优势和局限性,这些局限性使其未能被广泛采用。
白盒静态漏洞分析。存在许多用于在源代码中发现漏洞的技术。然而,静态分析与针对二进制代码的解决方案之间存在根本性挑战。因此,我们仅讨论与ARBITER更相关的方法。
基于图的漏洞发现方法(如Joern、Chucky和CodeQL)依赖于一组精心设计的查询,这些查询在程序源代码的图表示上表达模式[35,44,46]。其主要目标是将人类分析师的关注范围缩小到代码中可能存在漏洞的部分。因此,它们既不追求完全自动化,也不追求高精度。
一些静态工具旨在发现与ARBITER相同类型的错误。例如,Vanguard[40]试图通过结合静态代码分析和污点分析来识别缺失的安全敏感检查。除了需要源代码外,Vanguard明确专注于检查直接受用户输入影响的操作,并且无法检测到权限提升漏洞等(如3.2节所示)。
二进制动态分析。利用静态分析和DSE驱动模糊测试器中测试用例生成的研究非常丰富[1,2,7,27,30,37,41,49,50]。
SmartFuzz结合模糊测试和DSE来识别x86 Linux程序中的整数错误[25]。除了使用DSE生成新的测试用例外,SmartFuzz还使用约束求解器进一步识别整数操作中的断言错误,例如算术溢出、非值保留宽度转换和危险的有符号/无符号转换。然而,与其他动态技术类似,SmartFuzz的可扩展性受到从程序入口点开始的符号支持模糊探索的严重限制。此外,SmartFuzz仅限于整数错误,且尚不明确支持检测更多类型的错误需要多少努力。
其他解决方案采用污点分析或DSE来发现应用程序中的漏洞,例如使用统计引导DSE的Statsym[48],以及使用污点分析识别分配内存的代码位置并使用DSE检查这些分配的整数参数是否易受溢出影响的DIODE[39]。尽管这些解决方案可以发现ARBITER检测到的部分漏洞,但两者都需要触发目标程序中漏洞点的测试用例。在实践中,这通常需要进行广泛的模糊测试。
DSE增强的二进制静态分析。结合静态分析和DSE以验证结果并减少误报的方法并不新颖。INDIO[51]是一种模式匹配解决方案,用于识别潜在漏洞的代码位置并对其进行排序,然后使用带路径修剪的DSE来验证漏洞。INDIO在执行DSE时始终从程序的入口点开始,这极大地限制了其可扩展性。
IntScope[42]使用路径敏感的数据流分析来识别整数溢出,并使用污点分析和DSE来验证溢出约束是否满足。静态分析和DSE的结合以及以低误报率检测整数溢出的能力使这些方法与ARBITER相似。然而,这些技术是针对特定类型的错误定制的,而整数溢出只是ARBITER设计用于检测的漏洞类型之一。
2.2 二进制分析:静态与动态对比
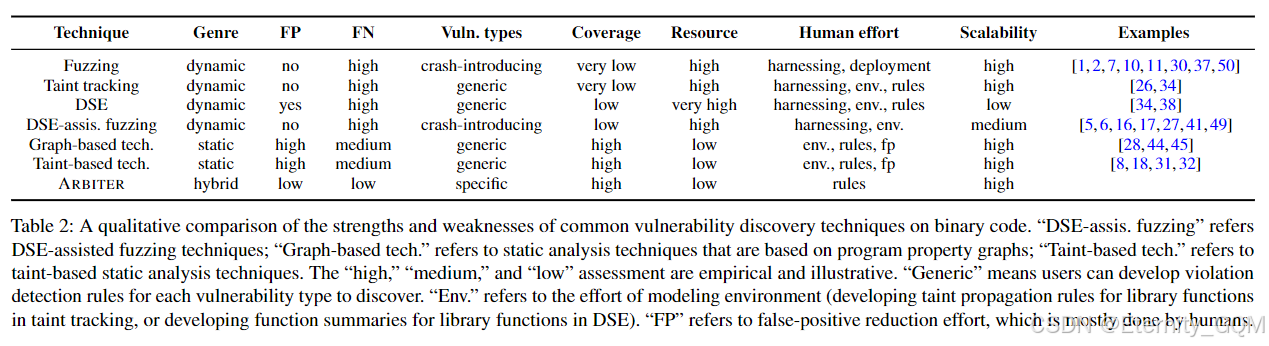
表2提供了二进制代码常见漏洞发现技术的定性比较。通常,动态技术和静态技术有不同的侧重点:前者牺牲代码覆盖率(由于动态覆盖问题,导致大量漏洞被遗漏),并严重依赖人工来构建harness和部署;而后者可以轻松实现高代码覆盖率,但代价是高误报率。资源需求、扩展能力、从报告的漏洞中过滤误报,以及在建模环境或创建harness方面的人工投入,都直接转化为应用这些技术的基本成本。这种成本导致人们不愿将这些技术应用于广泛的二进制文件。
重新审视表2可以发现这些漏洞发现技术之间存在一个有趣的空白:缺乏经济、可扩展且低人工干预、低误报率和漏报率的技术。具体而言,此类技术的缺失意味着现代漏洞发现技术的使用必须伴随着高成本,无论是大量的计算资源还是人工投入。这促使我们设计ARBITER,这是一种针对符合特定属性的漏洞类别的低成本二进制代码漏洞发现技术。
3 针对漏洞的静态分析
我们的核心见解是,通过精心选择在静态分析和动态分析中均可利用其属性的漏洞,我们能够合理限定漏洞检测方法的范围,以结合这两种范式,从而在保持可扩展性的同时实现高精度。为此,我们识别出一组漏洞“属性”,这些属性既易于静态分析,又为集成动态技术以提高精度提供了机会。我们确定了三个此类属性:
(P1)数据流敏感型漏洞。数据流敏感型漏洞可通过推理输入源与漏洞接收点(sink)之间的数据流来发现。需要注意的是,数据流敏感型漏洞的范围严格大于污点型漏洞,后者仅包括因未对污染的用户输入进行净化而导致的漏洞[45]。这些漏洞可通过静态技术处理,但存在典型的精度限制,不过也允许通过对数据流进行额外的动态验证来提高精度。
(P2)易于识别的源或接收点。在漏洞发现过程中,漏洞源决定了数据流跟踪的起点,而漏洞接收点决定了数据流跟踪的终点。对于许多漏洞类型,识别源和接收点需要整个二进制文件的精确别名信息,这已知是成本极高且不可扩展的。例如,如果源被定义为“从文件/tmp/secret读取的任何数据”,那么识别所有输入源需要正确分析每个打开文件的函数和系统调用的参数,以及文件指针、文件描述符和相关数据结构的传播。相反,有些漏洞的源或接收点可以通过检查计算成本低且可扩展的分析所生成的工件(如控制流图(CFG))来识别。此类接收点的一个示例是“库函数malloc()的所有调用站点”。
利用这种类型的源和接收点,从源到接收点对程序进行切片是一种经过充分研究的静态技术。尽管此属性通常在静态分析的上下文中考虑,但这些切片可由动态技术处理。这使得动态技术(如DSE)能够推理切片过程中的过度近似问题,修正此类过度近似,并提高整体系统精度。
(P3)控制流确定的别名。跟踪数据流几乎总是涉及恢复别名信息,这需要对目标进行昂贵的全二进制分析。然而,我们观察到,许多漏洞涉及的数据流根本不涉及指针解引用,或者当涉及指针解引用时,指针始终可以解析为控制流确定的单个对象(例如,通过栈指针访问的局部变量)。我们将此类别名情况称为控制流确定的别名,这是我们所针对漏洞的前提条件。
从静态角度看,此属性允许ARBITER在控制流图上自适应地前进或后退,而无需担心因错误别名信息导致的不精确性。从动态角度看,它极大地简化了由于动态状态未初始化而导致的别名问题。
技术选择。前面描述的三个关键属性使ARBITER能够有效集成静态技术和动态技术,这些技术专注于常见漏洞类别的子集,同时保持足够的通用性以适应各种现实漏洞。具体而言,我们使用数据流恢复和程序切片等静态技术(详见第5节)。我们对动态技术的选择由漏洞属性决定。P1定义了ARBITER可支持的漏洞范围,并建议使用DSE,因为DSE可以推理数据流中的复杂值关系。P2通过提供执行小程序切片的机会来定义实现高可扩展性的前提条件。这带来了一个挑战:这些切片通常缺少动态分析所需的状态信息。幸运的是,P3以及忽略大部分别名问题的能力使我们能够有效应用一种称为欠约束符号执行(UCSE)的DSE技术。如果没有P3,ARBITER要么需要在静态分析期间计算别名(这是一个不可判定的问题),要么接受由保守别名导致的高误报率。我们的动态技术将在第6节中讨论。
因此,ARBITER可以在静态和动态符号上下文中推理符合这些属性的漏洞。我们将这些漏洞称为属性兼容(PC)漏洞。为了让读者更好地了解我们方法的具体范围,我们在表3中列出了包含PC型漏洞的常见弱点枚举(CWE)条目,以及示例CVE条目和建议的源和接收点。在本文的其余部分,我们将重点关注CWE:131、134、252和337,即“缓冲区大小计算错误”、“未控制的格式字符串”、“未检查返回值”和“伪随机数生成器中可预测的种子”。
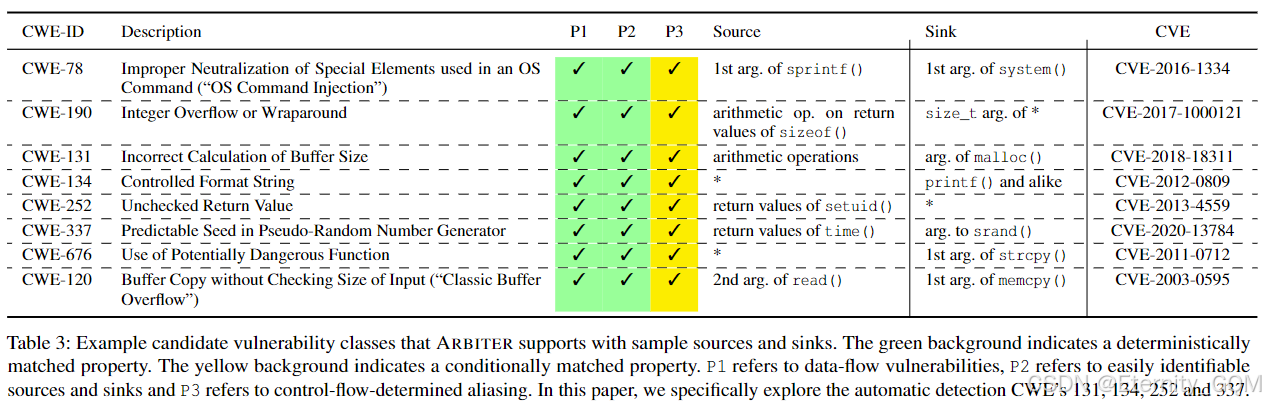
3.1 CWE-131:分配位点溢出
分配位点的整数溢出是一类严重的漏洞,可能为攻击者提供强大的攻击原语。此类漏洞会导致程序分配的内存块小于其应存储的数据量。当数据被复制到该内存中时,由此产生的越界内存访问可能被攻击者利用以获取代码执行权限。
发生场景:我们在现代软件中观察到一种常见模式,即通过自定义包装函数调用常见的libc函数(如malloc、realloc或calloc)来分配内存。该包装函数通常需要一个表示分配字节数的参数。在调用函数分配请求的字节数之前,该数值可能会增加以容纳特定于应用程序的元数据。当请求的大小非常大时,这种增加可能导致整数溢出,从而请求分配过小的内存块。
静态源和接收点:自然地,此CWE的接收点是分配函数(malloc、calloc、realloc)。相应地,源是调用已识别接收点的包装函数的参数。
静态数据流:此漏洞的数据流规范很简单:我们可以静态恢复从源到接收点的所有数据流,然后对其进行符号推
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9013
9013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











